YOLOv3在安全帽佩戴检测中的应用
2021-05-07唐勇巫思敏
唐勇 巫思敏








摘 要:在工地现场的安全管理中,施工人员的安全帽佩戴与否关系到其生命安全。传统的人工方式检测施工人员安全帽佩戴与否的效率较低。文章提出一种基于YOLOv3目标检测算法,可以实时地自动检测施工人员是否佩戴安全帽:首先收集安全帽数据集和标注处理,把数据集分为训练集、验证集和测试集;然后使用YOLOv3对训练集和验证集进行训练,并对测试集进行测试,最终结果显示检测准确率达到0.78、召回率0.914、mAP达到0.91、F1指数0.842、FPS为161,可满足安全帽实时检测的要求。
关键词:YOLOv3;目标检测;安全帽
中图分类号:TP391 文献标识码:A文章编号:2096-4706(2021)23-0088-05
Application of YOLOv3 in Safety Helmet Wearing Detection
TANG Yong1, WU Simin2
(1.Guangdong University of Technology, Guangzhou 510006, China; 2.School of Computer Science and Engineering, North Minzu University, Yinchuan 750021, China)
Abstract: Whether constructors wear safety helmets or not is related to their life safety in the safety management of the construction site. It is inefficient to detect whether the safety helmet of construction personnel is worn by traditional manual inspection. This paper proposes a target detection algorithm based on YOLOv3 to detect automatically whether the construction personnel wear safety helmets in real time. Firstly, collect the data set of safety helmets and label processing, divide the data set into training set, verification set and test set; then use YOLOv3 to train the training set and verification set, and test the test set. The final results show that the accuracy rate of detection reaches 0.78, the recall rate is 0.914, mAP reaches 0.91, F1 index is 0.842, and FPS is 161, which can meet the real-time detection requirements of safety helmet.
Keywords: YOLOv3; target detection; safety helmet
0 引 言
施工人员在工地施工过程中,经常存在各种各样的作业风险,威胁着施工人员的人身安全。经常可以在新闻报道中看到物体打击、高处坠落、起重、坍塌等危害出现在施工过程中[1]。因此,施工人员在施工过程中必须正确佩戴安全帽,以保护人身安全。目前,对于安全帽佩戴的检测方法是以人工检测为主,人工检测费时费力,而且检测精度较为低下,存在较多的错检、漏检现象。针对以上的问题,需要寻找一种更加高效可行的方式或方法来代替人工检测,减少施工人员在施工过程中受伤和死亡的事件的出现。
目标检测应用较多,包括安全帽检测、行人检测[2]、口罩检测、车辆识别[3]等等,本文主要研究安全帽检测。据统计,为了提高了安全帽检测的准确性及效率,相关学者使用了传统机器学习算法进行研究,如冯国臣等人探索安全帽检测时通过机器视觉先确定目标图像为人体[4],再定位到人体头部;但传统的机器学习方法应用于目标检测,结果极其容易受施工环境的影响,检测结果往往都是很低的準确率,检测时延较长,不利于实际应用。Joseph Redmon在2016年提出了提出You Only Look Once(YOLO)[5],同年提出了YOLO的改进版YOLOv2算法[6],并对其改进提出了YOLOv3算法[7],不仅运算速度快,还得到了达到RetinaNet水平的mAP值。因此本文实现了基于YOLOv3的安全帽检测,并得到了较好的精度和效率。
1 YOLOv3算法
1.1 YOLOv3网络结构
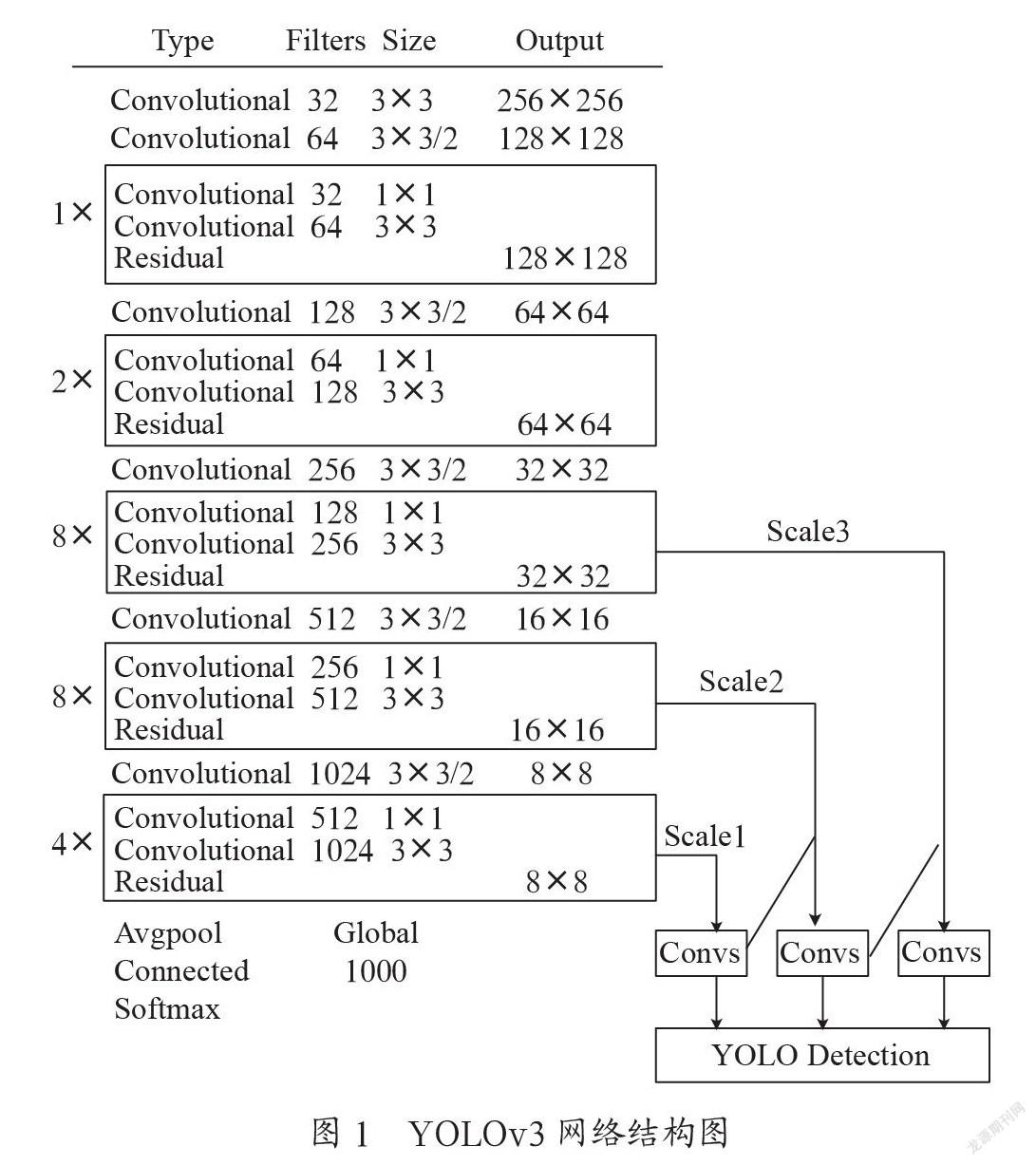
YOLOv3是指通过特征提取网络,提取输入图像的相关特征,从而得到特定大小的特征图。比如现有一张输入图像,第一步是处理为一个13×13的网格单元;第二步是判断这些网格单元中是否存在真实框中的目标的中心坐标,若存在那么可以利用这个网格单元来预测这个目标;最后利用RPN网络来进行3×3边框预测,需要注意的是部分边框不会去进行预测,只有交并比值的边框真正在预测目标。YOLOv3网络的结构图如图1所示。
其中Darknet-53是YOLOv3的主干网络,由53个卷积层和若干的residual层组成,是一种提取特征的网络结构。Darknet-53不仅结合了残差网络(ResNet)的优点,还包含了5个残差块,分别进行5次的降采样工作,在最后的三次降采样过程中获得3个尺度检测的特征图,并最终实现了目标预测。大特征图和小特征图存在较大的差异,大特征图包含检测目标的基本位置信息,小特征图包含着层次的语义信息,但是这两个特征图能够互相融合,从而能够检测大小目标。
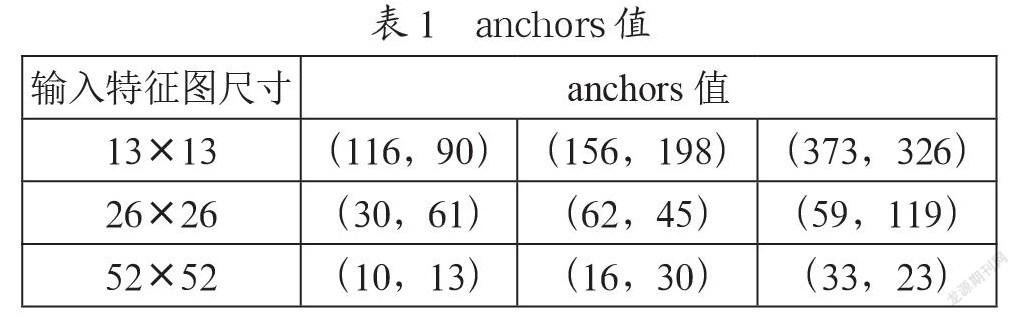
YOLOv3相对于YOLOv2而言,能够利用3个特征尺度进行多尺度特征融合,对目标进行预测,尤其使得小目标检测更加精准化。其中各个特征尺度与之对应的先验框(anchors值)如表1所示。
1.2 模型损失函数
在YOLO算法模型中,第一步把图片划分成单元格,以每一个单元格为单位进行目标的预测和分类,每个单元格负责检测目标真实框中心,判断其是否落在本网格内。第二步工作是所有的单元格必须预测预测框和真实框的大小与坐标,并且对所有预测框生成一个预测置信度分数。第三步,根据数据集的类别数目,确定每个单元格就需要预测多少个类别的条件概率值。在这个预测过程中与真实值所产生的偏差就组成了本文算法模型YOLOv3的损失函数,Loss这个偏差由三部分组成:目标置信度损失、目标分类损失和边界框位置回归损失;Loss的计算公式为:
Loss=LBBox+Lconfidence+Lclass (1)
其中目标置信度损失中的置信度主要有两个评价指标,首先是单元格内是否存在目标,然后是候选框的准确程度。将置信度用confidence表示,Pobj表示检测目标是否在这个单元格内,其计算公式为:
confidence=Pobj×(2)
其中,当单元格内没有包含目标物体,Pobj的值为0,否则Pobj值为1。即,当单元格存在目标物体时,置信度的取值就为IoU的取值。下面对IoU的相关知识做一个简单说明,指出其优点与缺陷。
1.3 交并比
交并比(Intersection of Union, IoU)是从数学的集合引入到目标检测算法处理过程中的,间接作为YOLO的优化损失指标。数学上,它描述了集合A和集合B两者之间存在的关系,但在目标检测中它被用来用于衡量真实框(ground truth)与预测框(predict box)的差距,也包括用来描述真实框与预测框的重合度,具体计算公式为:
IoU= (3)
这个指标能够快速地直观反映真实框与预测框的检测效果,具备着尺度不变性特点。
1.4 NMS处理目标重复检测
YOLOv3删除了一些目标可能性较低的窗口框,通过非极大抑制(NMS)算法[8],将置信度偏低的重复预测框剔除,然后输出置信分数较高的预测框。其次NMS处理目标重复检测时,先根据置信度的分数值对预测排序;然后按照分数值高到低的顺序进行检查是否存在与之前的预测相同类别,同时满足条件阈值(预先设置)小于当前预测的IoU时,那么可以之间忽略这个预测;最后不断重复地执行上一个步骤,一直到所有预测检查都完成。
2 实验过程
2.1 数据集搜集和处理
本次实验所用到的安全帽数据集是从网上搜索得到,总共分为两类,分别为“hat”和“person”,其中未佩戴安全帽的人使用“person”来表示,而佩戴安全帽的人用“hat”标记。本次实验总共搜集了7 581张图片,然后利用开源软件LabelImg标注所有的已收集到的图片,其中一张图片的标注过程界面图,如图2所示。由图可见,绿框表示安全帽的真实框(ground truth),右上角的小框表示类别,依此类推对所有图片进行了标注操作。
7 581张图片对应生成7 581个xml文件。目标真实框(ground truth)的標签信息保存至每一个xml文件,并且包括输入图像的大小以及目标的类别和位置信息,如图3所示。
本文将数据集进行划分为训练集、验证集和测试集的数目是5 458、1 517、606.
2.2 训练过程
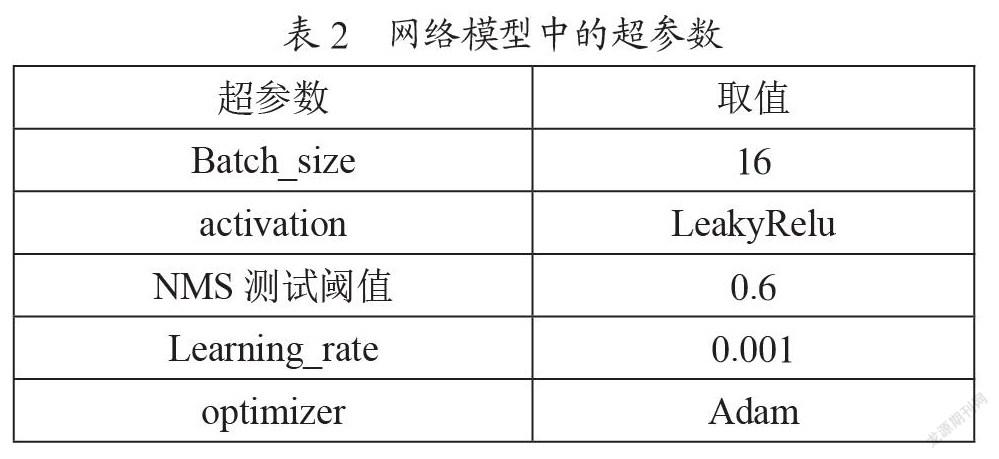
实验主要在PC端完成,PC的主要配置为CPU:Intel(R)Xeon(R)Platinum 8369B CPU @ 2.90 GHz 8核16线程,内存:64 GB,显卡:NVIDIA A10 GPU 24 GB ,Ubuntu:Ubuntu 20.04.3 LTS,框架:pytorch 1.10.1,语言:Python3.9.7,实验过程中使用网络的重要超参数,如表2所示。
2.3 评估标准
在本次目标检测实验中,当IoU取值大于等于0.5时,若检测框中有一个目标,标记为TP,反之则标记为FP,当IoU取值小于0.5时,若检测框内中有一个目标,标记为FN,反之则标记为TN。由这4项可求得训练样本的召回率(Recall)与准确率(Precision),其中计算公式为:
Precision== (4)
Recall== (5)
通过设置目标的置信度阈值,得到数组满足条件的Precision值和Recall值。由Precision值和Recall值组合而成的准确率-召回率曲线(即P-R曲线)的面积,代表训练样本中各类目标的平均精度(AP),mAP则指所有类别的平均精度求和除以类别数目,目标检测网络的检测效果常以mAP作为主要的评估指标,公式为:
(6)
其中,
(7)
(8)
除此之外,本文在进行算法性能评价时还采用F1指数,F1是P-R的调和平均,能很好地区别算法的优劣,F1值越高,物体识别算法就越好,计算公式为:
(9)
2.4 实验结果
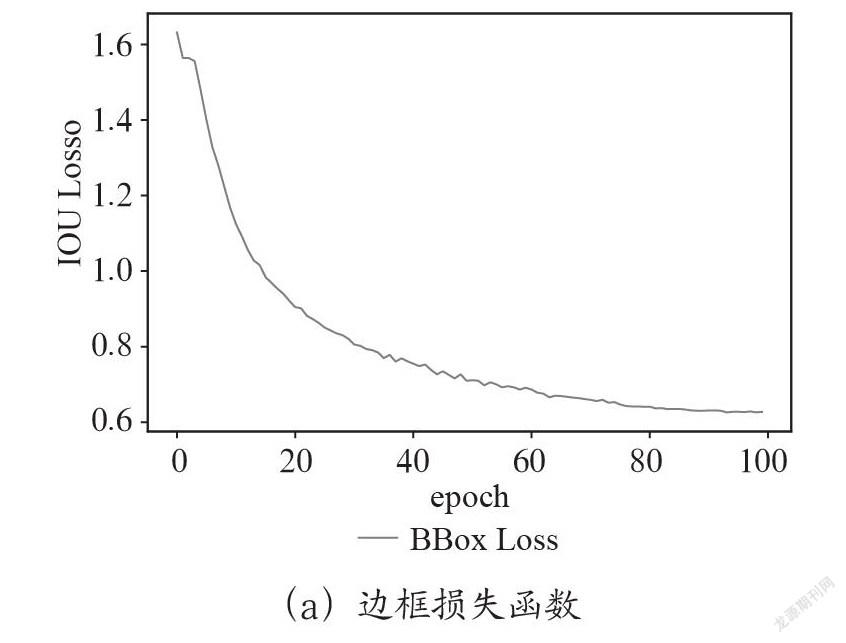
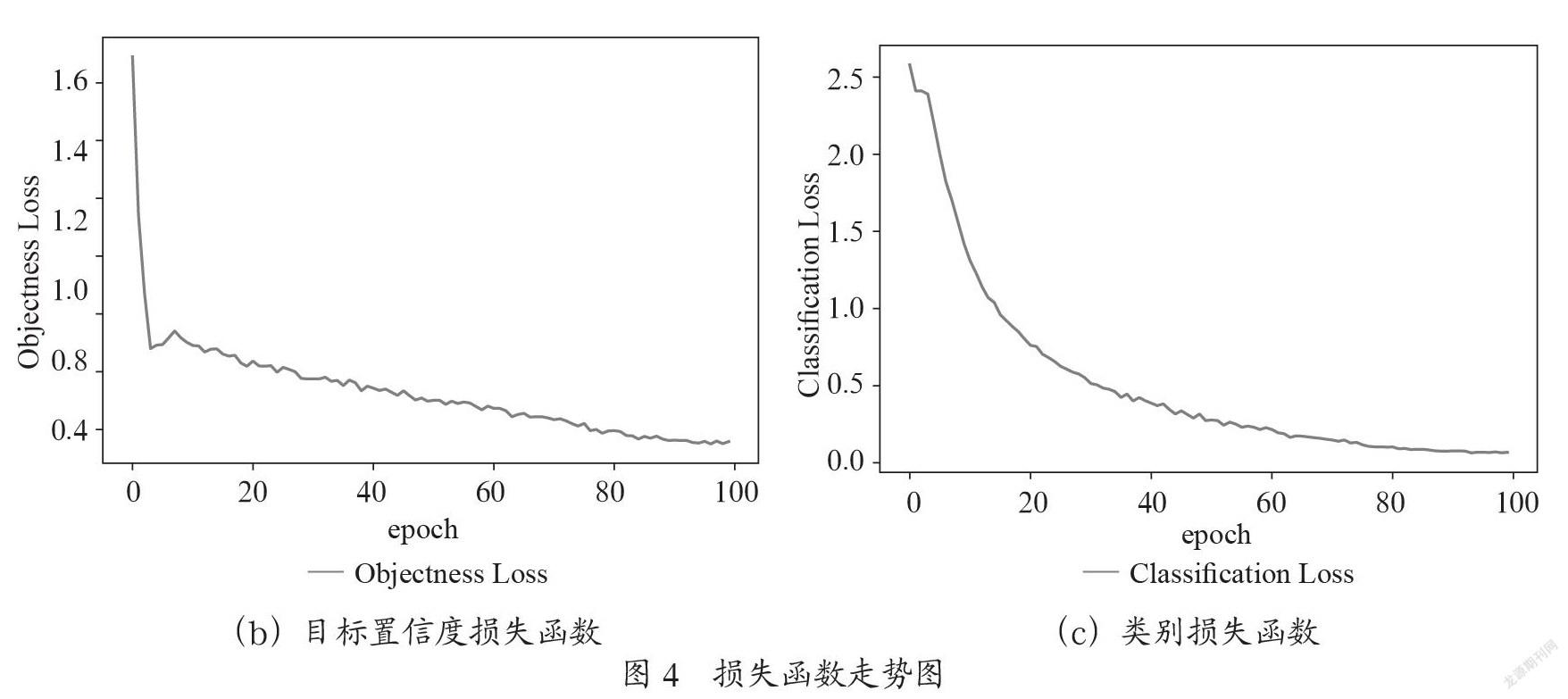
迭代100个epoch之后,训练趋于稳定,所得到的损失函数走势图如图4所示,其中(a)所示的IoU Loss是通过训练集训练得到的边框损失函数;(b)所示的Objectness Loss是通过训练集得到的目标置信度损失函数;(c)所示的Classification Loss是通过训练集得到的类别损失函数。
最后通过测试集的测试,得到各个种类和总的数值,其中安全帽的准确率为0.777,未戴安全帽的准确率为0.782,平均类别准确率为0.78;其中安全帽的召回率为0.898,未戴安全帽的召回率为0.93,平均类别召回率为0.914;AP50表示IoU取值为0.5时的精度,其中安全帽的精度为0.9,未戴安全帽的精度为0.92,平均类别精度为0.91;其中安全帽的F1指数为0.833,未戴安全帽的F1指数为0.85,平均类别F1指数为0.842;在该平台下,当设置测试batch size为16,并且把测试的图片resize成512×512的大小的情况下,所得到的FPS为161。得到的结果如表3所示,测试效果如图5所示。
3 结 论
本文提出了一种通过YOLOv3的目标检测算法来检查施工人员在施工过程中安全帽的佩戴与否。首先确定从众多的目标检测算法模型中,挑选出综合性能较好的YOLOv3算法模型。然后开始收集并标注制作整个实验所需要的数据集,对制作好的数据进行合理的划分。最后将训练集和验证集用于训练,测试集用于测试评估指标,调整YOLOv3中的参数。通过这一系列的操作,得到一个安全帽佩戴检测的YOLOv3算法模型,该模型具有较高的准确率、召回率和均值平均精度,并且在该模型下所测的结果满足安全帽佩戴是实时检测要求,可以很好地代替目前的人工检测,更好地保障施工人员在施工过程中的人生安全。
参考文献:
[1] 唐凯,陈陆,张洲境,等.我国建筑施工行业生产安全事故统计分析及对策 [J].建筑安全,2020,35(9):40-43.
[2] 谢林江,季桂树,彭清,等.改进的卷积神经网络在行人检测中的应用 [J].计算机科学与探索,2018,12(5):708-718.
[3] 彭清,季桂树,谢林江,等.卷积神经网络在车辆识别中的应用 [J].计算机科学与探索,2018,12(2):282-291.
[4] 冯国臣,陈艳艳,陈宁,等.基于机器视觉的安全帽自动识别技术研究 [J].机械设计与制造工程,2015,44(10):39-42.
[5] REDMON J,DIVVALA S,GIRSHICK R,et al. You Only Look Once:Unified,Real-Time Object Detection [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Las Vegas:IEEE,2016:779-788.
[6] REDMON J,FARHADI A. YOLO9000:Better,Faster,Stronger [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu:IEEE,2017:6517-6525.
[7] REDMON J,FARHADI A. YOLOv3:An Incremental Improvement [J/OL].arXiv:1804.02767 [cs.CV].[2021-11-02].https://arxiv.org/abs/1804.02767.
[8] NEUBECK A,GOOL L V. Efficient Non-Maximum Suppression [C]//8th International Conference on PatternRecognition(ICPR06).Hong Kong:IEEE,2006:850-855.
作者簡介:唐勇(1993—)男,汉族,广东河源人,硕士研究生在读,主要研究方向:深度学习与目标检测;通信作者:巫思敏(1993—)女,汉族,广东信宜人,硕士研究生,高级工程师,主要研究方向:数据挖掘与知识发现。
