基于逻辑回归函数的加权K-means聚类算法
2021-04-29林丽,薛芳
林 丽,薛 芳
(1.集美大学计算机学院,福建 厦门 361021;2.集美大学信息化中心,福建 厦门 361021)
0 引言
聚类分析在数据挖掘、文本摘要、图像识别领域有广泛应用,它是一种非常重要的机器学习算法。聚类算法能自动把数据对象划分成不同类别,每个类别中数据具有相似特征。通过聚类算法,可以在茫茫数据中挖出数据的规律。K-means算法是一种基于划分的硬聚类算法,其运算速度快,尤其适用于高维数据、大规模及文本数据的聚类,是目前比较常用的一种聚类算法。
K-means算法的做法是随机选择K个聚类中心,通过欧式距离计算各个样本和聚类中心的相似度。将样本分配给距离最近的类。K-means算法存在2个问题:1)聚类结果不稳定;2)用欧式距离计算样本相似度。所有特征参与欧式距离计算且贡献度都一样,这往往带有大小不等的随机波动。针对问题1),文献[1-3]提出K-means++算法,其采用概率来选择初始聚类中心,极大改善了传统K-means算法随机选择聚类中心的不确定性,提高聚类准确率。但是K-means++算法只考虑优化聚类中心,并没有考虑特征的不同贡献。关于问题2)存在如下例子:如有二维样本(身高,体重),其中身高数值范围是150~190,体重数值范围是50~60,现有三个样本:a(180,50),b(190,50),c(180,60)。按照欧式距离计算样本相似度,Dist(a,b)=Dist(a,c),那么身高10 cm真的等价于体重10 kg么?显然不是。而根据不同特征贡献加权的欧式距离去计算,样本的相似度才更准确。关于特征加权,文献[4-5]提出通过特征的总方差、均值来表示特征权重,但是方差并不能准确表示特征的差异情况。文献[6]提出的特征赋权主要基于同类内特征权重计算及学习。文献[7]提出采用Pearso相关系数来对数据对象间的距离进行加权,考虑样本和类中心的特征关联计算特征权重。文献[6]和文献[7]的特征赋权考虑是样本间的关联,但是并没有考虑特征本身的差异对特征权重的影响。
Softmax函数可以凸显特征差异,Sigmoid函数平滑极大极小特征差。本文提出一种特征赋权算法,它结合归一化指数函数Softmax和激活函数Sigmoid计算特征权重,特征差异低的特征属性贡献少则赋予较低权重,差异大的特征贡献大则赋予较大权重,以此尝试更好地解决K-means算法的两个问题。
1 相关知识
待聚类样本集X={xi|xi∈X,i=1,2,…,n},每个样本都有m个特征xi={xi1,xi2,…,xim}。
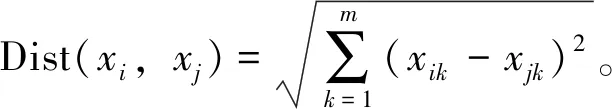
定义2 聚类的准确率r=(m/n)×100%。其中m为正确聚类的样本个数,n为总样本个数。

2 基于逻辑回归函数赋权的LWK-means算法
相对于传统K-means算法,本文提出的基于逻辑回归函数赋权的LWK-means算法改进了2个方面内容:一是聚类初始中心点优化,选择尽量远离样本作为初始聚类中心;二是设计特征权重计算方法,改进欧式距离计算公式。
2.1 初始聚类中心优化
聚类中心的优化策略为:先随机选一个样本做聚类中心,从第二类开始,计算每个数据对象x与已选聚类中心的最小距离minDist(x)。其中:在minDist(x)中选择最大值所在样本j作为下一个聚类中心;每一个聚类中心的确定都保证是和已有聚类中心的距离是较大的;可以让选择的聚类中心更贴近数据分布。实验表明,尽量远离聚类中心的做法,可以提高聚类算法的准确率。
InitCenter(X,k)具体做法:
1)选择第一个样本作为第一个聚类中心C1,k′为当前类数量,k′=1。
2)根据定义2计算样本集X和已有类中心的距离Dist(X,C)。
3)在Dist(X,C)中选择离现有类的最小距离作为样本和目前类Ck的距离值,
min Dist(X)=min(Dist(X,Ck))(k=1,2,…,k′)。
4)min Dist(X)中找出最大值所属的样本j,作为下一个聚类中心Ck′,k′=k′+1,Ck′=arg max(min Dist(X))。
5)重复步骤2),直到选完k个聚类中心。
2.2 特征赋权
特征权重是改进算法中重要的步骤。特征权重计算主要是观察各个特征的差异情况。如果某个特征数据变化少,这个特征的差异度就少,该特征在分类中贡献度也少,赋低权重;如果某个特征数据变化大,该特征情况显著,对分类贡献大,赋高权重。特征差异度是在原始数据集上,即数据集未标准化前计算。保证特征差异度符合数据原始分布。
定义4 特征差异度p={p1,p2,…,pm},表示每一列特征变化情况。是个一维向量。
特征差异度一般都用方差表示特征整体误差情况。由于各个特征取值范围不同,某些特征即使差异较大,若取值较小,也会导致方差较小。本文提出一个新的计算差异度公式衡量特征差异情况。令
pi=(max(xi)-min(xi))/avg(xi),
(1)
其中:xi表示某一列的数据;max(xi)表示该列的最大值;min(xi)表示该列最小值;avg(xi)表示该列平均值。极大极小差表示该列数据最大差异度,其与平均值比例可以从整体了解该列数据差异情况。p值越大,特征差异度越大,该特征数据变化大。
定义5 特征差异度的最大比值maxr=max(pi/pj)。pi,pj分别表示第i列与第j列的特征差异度。主要通过这个参数了解是否存在极大极小特征差异度。
定义6 特征权值w={w1,w2,…,wm},表示m个特征在欧式距离计算的不同贡献度。使用逻辑回归函数Softmax计算,公式为:
(2)
其中pi为每个特征差异度。pi越小,其贡献度越小;反之,则贡献度越大。
使用Softmax函数可以凸显最大值,抑制低于最大值的其他分量。但是Softmax函数会出现特征权重极大极小情况,当maxr值超过10,wi会完全偏向某一个特征。如某个数据集有3个特征权重分别为[0.070,0.012,0.910],第三个特征值比前2个大很多,特征权重计算会出现极大极小情况。由于特征值的取值范围不同,导致权重值完全失衡。Sigmoid函数有很强的鲁棒性,各个特征权重值可以映射到(0,1)区间,平衡特征权重间的差异,故公式(2)也可以用Sigmoid函数设计:
(3)
每个特征赋权后,欧式距离及类误差平方和SSE也改为加权欧式距离及加权的SSE(S)。
(4)
2.3 LWK-means算法
基于逻辑回归函数赋权的LWK-means算法流程为:
ⅰ)输入 样本数据集X,聚类个数K
输出K个聚类数
ⅱ)步骤
1)根据函数InitCenter(X,k),选择k个初始聚类中心Ci。
2)根据公式(1)计算数据集的特征差异度Pi。
3)根据定义5计算最大特征比值maxr。若maxr>10,说明存在极大极小特征权重问题,则选择公式(3)计算特征权重wi;若maxr<10,则选择公式(2)计算特征权重wi。
4)根据公式(4),计算样本和中心点的相似度Dist(x,C),取最小相似度作为样本归属类别。将样本分配至类别Li。
5)根据Li划分的样本,计算同类样本在每一个特征的平均值,更新聚类中心Ci。
6)加入特征权重计算误差平方和SSE(公式(4)),重复步骤2)→3)→4)→5),直至SSE不变或达到指定的迭代次数。
3 实验结果与分析
3.1 数据集
为了验证LWK-means算法的有效性及合理性。选用UCI数据库中的6个数据集作为仿真数据测试。表1为数据集说明。针对每个数据集,运行各算法100次。以算法的迭代次数、误差平方和、准确率作为有效性数据分析依据。并分别与K-means、SWK-means、LWK-means的聚类结果进行对比。其中:K-means算法的聚类中心是随机选择,欧式距离不带权重;SWK-means和LWK-means初始聚类中心的选择策略一样;SWK-means算法的欧式距离权重值为各列的方差;LWK-means算法的欧式距离权重值是基于特征差异度及逻辑回归函数计算的结果。数据预处理方面,采用Z-Score标准处理原始数据,保证不同维度数据的标准化。

表1 UCI数据集及说明
3.2 数据集特征权重
特征权重是衡量各个特征贡献的指标。如Iris数据集,类别划分主要依据第3、4特征的数据,由于第3、4特征的数据差异度比第1、2特征大,故第3、4特征贡献大。使用Softmax函数凸显第3、4特征,根据公式(1)、(2)计算各特征权重后,对第3、4特征在欧式距离测量中赋予较高权重[0.29,0.45](见表2)。

表2 数据集的特征权重
从表3的实验结果可看到,Iris数据经过特征赋权后,聚类正确率高达95%。Haberman和Glass数据集中特征差异度出现极大极小情况,使用Sigmoid回归函数平滑特征权重,即改善特征权重间的不平衡问题,也能按照特征的不同贡献对特征赋权(见表2)。Balance数据集每个特征都为离散型数据,列取值区间为[1,5],各个特征变化情况一致,故各个特征权重一样(见表2)。
3.3 实验结果及分析
运行K-means、SWK-means、LWK-means算法各100次,再取平均值。各算法在迭代次数、类误差平方和SSE、类划分准确率的比较结果见表3和图1~图3。

表3 迭代次数、类误差平方和SSE、类划分准确率指标对比结果
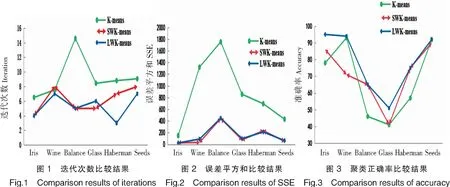
从表3及图1可以看到,在迭代次数方面,LWK-means算法迭代次数均少于传统K-means、SWK-means算法。聚类中心优化后,LWK-means算法的迭代次数在数据集Haberman中表现出更快的收敛,运行速度更优。类误差平方和SSE是聚类效果的一个重要衡量标准。SSE越小,说明类内的误差越小,类越紧凑,聚类效果也越好。表3及图2显示加权后的LWK-means和SWK-means算法的SSE更小,加快了算法的收敛。Iris数据集中,欧式距离经过特征加权后,LWK-mans及SWK-means算法的准确率明显高于K-means;其他数据集中,LWK-means算法平均准确率也高于K-means、SWK-means算法。
准确率是一个很直观的评价指标,但是准确率高并没有反映出模型真正的能力,并不能代表某个算法就好。因此,引入另外两个指标:精确率(Precision)P和召回率(Recall)R,P=类别正确归类的样本数量/聚类后新类别的样本数量,R=类别正确归类的样本数量/该类别原始的样本数量。精准确率用于检验聚类结果的有效性,召回率用于检查聚类结果的完整性。表4展示2个数据集中每个类别的精确率和召回率。图4和图5是6个数据集的精确率和召回率取均值后的柱状图。
由表4、图4、图5可以看出,LWK-means在6个数据集中的精确率、召回率都优于其他2个算法;Balance、Haberman、Glass数据集中,LWK-means算法特征加权后的精确率和召回率都明显比未加权的K-means算法高。表5是对6个数据集的精确率、召回率、准确率取均值的比较结果:LWK-means算法的精确率较未加入权重的K-means算法提高7.6%,较方差加权的SWK-means算法提高1.7%;其召回率较K-means算法提高4.2%,较SWK-means算法提高1.7%;其准确率较K-means算法提高12.4%,较SWK-mean算法提高3.3%。这3个指标再次证明LWK-means算法的有效性及稳定性。
K-means算法采用欧式距离计算样本相似度,适用于球形数据分布,对非球形数据及离群点不敏感。从实验中看到,关于Glass和Balance等非球形数据集,3种算法准确率较低。需要引入监督算法训练权重值。但从表3及图3可看到LWK-means算法平均准确率还是高于传统的K-means及SWK-means算法。
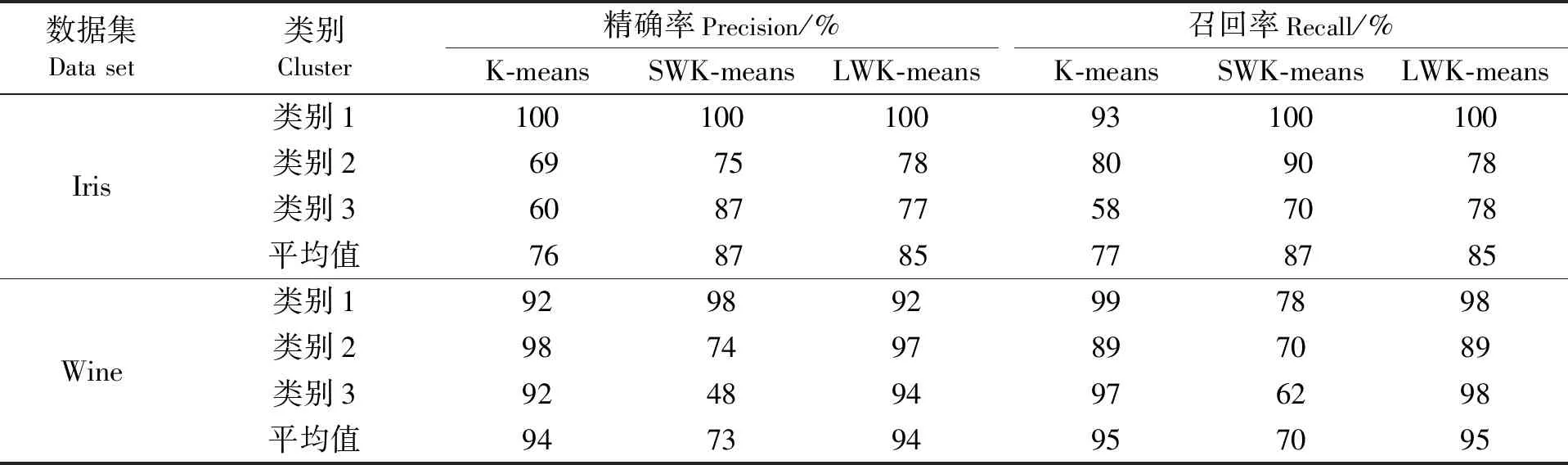
表4 各算法精确率和召回率的比较结果
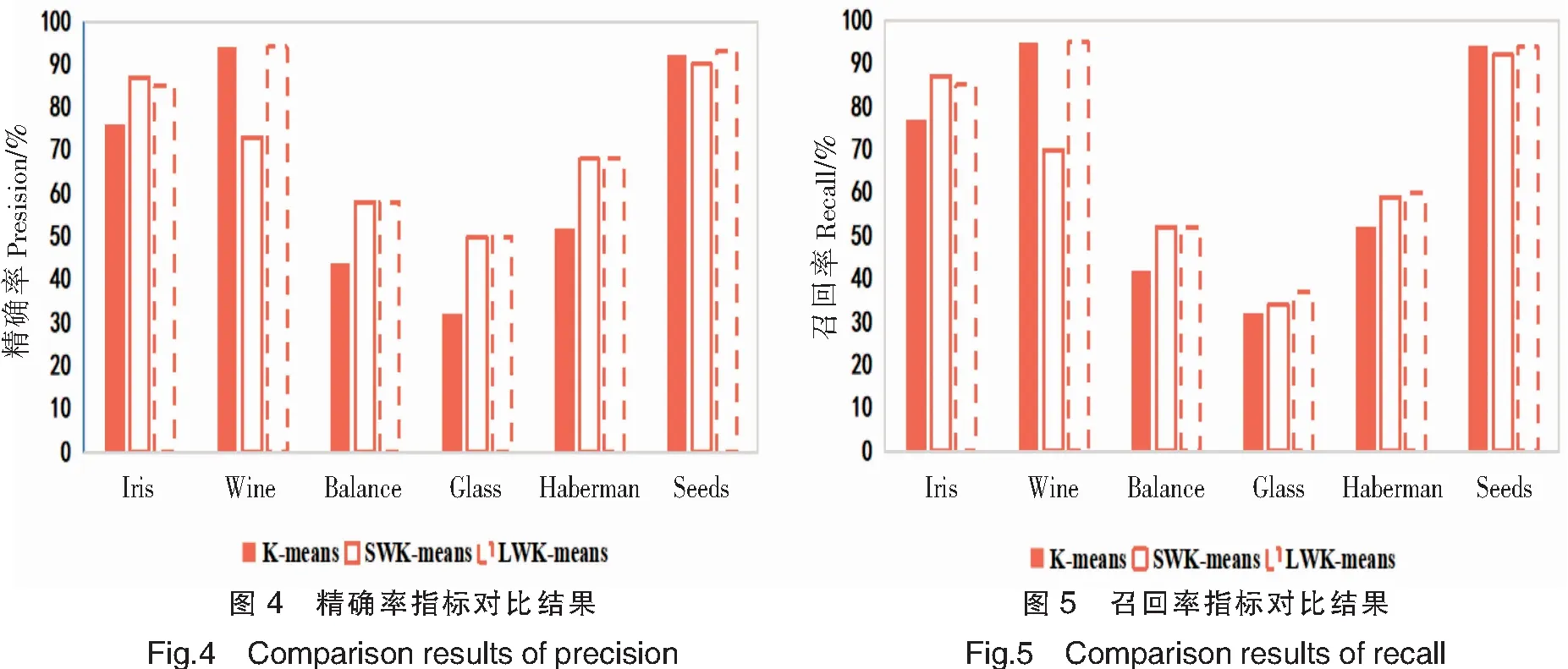

表5 各算法精确率、召回率、准确率指标对比结果
4 结论
传统的K-means算法存在随机选择聚类中心、特征权重均等情况,导致聚类结果不稳定、样本相似度计算不准确的问题。本文针对K-means算法的不足,提出基于逻辑回归函数赋权的LWK-means算法。首先,优化聚类中心。选择距离较大的K个样本作为聚类中心,解决了传统K-means聚类中心不稳定问题,初始中心点尽量贴近类别本身。然后,根据每个特征差异度,使用Softmax和Sigmoid回归函数计算特征权重,为特征分配不同贡献度。经过加权的欧式距离计算方法可以提高样本相似度的计算准确率。实验选择了UCI数据库中的6个数据集,通过与K-means、SWK-means算法比较,LWK-mean算法在迭代次数、误差平方和、准确率、精确率、召回率方面都表现更优性能。但是,在实验中也发现,欧式距离的计算方法并不适用所有数据集,后续研究工作中,可以引入监督学习方法改进样本相似度计算方法,提高聚类准确率。
