基于Python的网页信息爬取技术研究
2021-04-22陈海燕朱庆华常莹
陈海燕 朱庆华 常莹


摘要:现在是信息时代,互联网为我们提供了丰富的信息资源。只要我们有需要就能通过网络得到。但是正因为网络上的资源太丰富了,如果想得到需要的内容,用户就要做大量筛选和甄别工作。网络信息筛选和抓取有很多方法,比如Java、Python等语言,还有一些专门的公司为用户提供网络爬虫程序做信息的定向抓取。目前使用较多的是Python语言,文章要研究的内容是:通过使用Python库中的Beautiful Soup库快速、简捷地抓取所需信息。
关键词:BeautifulSoup;Python;网络爬虫
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2021)08-0195-02
1 BeautifulSoup介绍
Beautiful Soup是一个可以从网页文件中提取信息的Python库,它包含在bs4库里。需要注意的是下载、安装bs4时需要联网,否则安装会出错,具体命令为:pip install bs4,如图1所示。
2 解析HTML流程说明
HTML文件是由一组尖括号构成的标签组织起来的,每一对尖括号形式一个标签,标签之间存在上下关系,形成一颗标签树。因此可以说Beautiful Soup是解析、遍历、维护“标签树”的功能库。众所周知:html由众多标签组成,如何精确定位标签,从标签中提取到需要的内容呢?
在找到对应标签位置后,熟悉html的人知道,信息一般会存储在两个位置中:
1)开始标签和结束标签中的内容;
2) 开始标签中的属性值。
例如下面这行标签:
。这个标签的含义是:一个段落中有一个超级链接,链接的地址是:www.baidu.com。我们要做的就是提取和之间的“美食网”文字,或者提取标签的属性值,即链接www.baidu.com内容。
3 使用python进行网页内容获取的方法
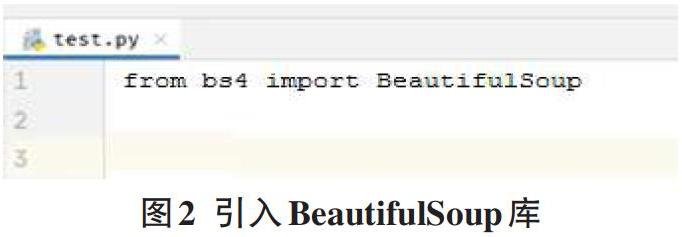
3.1引入BeautifulSoup库
程序开始的第1行需要引入BeautifulSoup库。如果bs4下出现波浪线表示安装路径有问题,需要检查。语句如图2所示。
3.2 html代码放入str
将html代码放入一个变量中,注意,由于html代码有换行,需要每一行都加上单引号,这样比较麻烦,可以把html整个代码用三个单引号里引起来,这样就简单多了,而且也增强了代码的可读性。如下所示:
str = '''
- 食材准备
- 制作过程
这道菜俺从小吃到大,它是我儿时的全部味觉记忆。
美食网免责声明。
- 制作步骤
- 注意事项
'''
3.3使用lxml解析器實例化BeautifulSoup对象
BeautifulSoup支持Python标准库中的HTML解析器(HTMLParser),还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml解析器更加强大,速度更快,推荐安装使用。具体的语句如图3所示。
3.4获取title标签里的内容
title标签的含义是为网页定义标题。需要说明的是:如果要提取“标题”,只需要使用title标签名来识别,因为整个html文档中,title标签只会出现一次。具体的语句如图4所示。
3.5获取p标签里的文字
P标签是段落标签,如果要提取p标签里的内容,不能像提取title标签一样只使用p标签,因为p标签可以有多个。因此p标签要和它的class属性联合起来使用,例如3.2中给出的标签,用'first'或'second'来识别p标签。要提取class属性是first的p标签,语句如图5所示。
3.6获取所有p标签里的文字
在进行信息抓取时,有时需要提取所有p标签里的内容,这时就可以使用循环获取。具体的语句如图6所示。
以3.2的标签为例,运行结果为:
这道菜俺从小吃到大,它是我儿时的全部味觉记忆。
美食网免责声明。
3.7查找ul标签里的li标签
ul是无序列表标签,它与li标签配合使用,一对ul标签里可以包含若干对li标签。因为ul标签也可以有多个,因此ul标签也要和它的class属性联合起来使用,查找class='list1'的ul标签里的所有li标签,可以使用图7的方法。
以3.2的標签为例,运行结果
同理,也可以先定位到
- 这个标签上,所获得的所有li就是我们想要的了。
- 和 标签也一起获取了。当有多个li标签时,又不想获取
- 和 标签时,可以使用图8的方法。
3.8查找ul标签里的li标签内的内容
3.7中的方法,在获取内容时,连同
运行结果
食材准备
制作过程
3.9 找到所有某类标签
如果要找到所有某标签,或者某几种标签及根据正则表达式提取,只能用find_all返回一个列表,具体方法为:
soup.find_all('h2')
4 结束语
Beautiful Soup提供一些python式的函数,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。Beautiful Soup已成为和lxml、html6lib一样出色的Python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
参考文献:
[1] 周德懋,李舟军.高性能网络爬虫:研究综述[J].计算机科学,2009,36(8):26-29,53.
[2] 霍柄良.基于Python的网络爬虫技术探析[J].数码世界,2020(4):73-74.
[3] 王鹏,郑贵省,郭强,等.基于网络爬虫的民用运力数据获取[J].军事交通学院学报,2020,22(1):87-90.
[4] 王晓楠,李杨,张海峰,张宇.面向网络爬虫的网站优化策略[J].农家参谋,2020(5).
[5] 钟机灵.基于Python网络爬虫技术的数据采集系统研究[J].信息通信,2020,33(4):96-98.
[6] 李杰秦.基于Python语言下网络爬虫的技术特点及应用设计[J].数字通信世界,2020(1):209-210.
[7] 陈丽娟,王科,李晨曦. 浅谈Python网络爬虫技术基础知识[J].计算机系统网络和电信,2019,1(2):46-49.
[8] 冯丹.基于网络爬虫的搜索引擎的研究[J].移动信息,2019(8):121-122.
【通联编辑:王力】