基于卷积神经网络的雷电临近预警模型*
2021-04-20张烨方冯真祯
张烨方 冯真祯 刘 冰
1 福建省灾害天气重点实验室,福州 350001 2 福建省气象灾害防御技术中心,福州 350001
提 要: 从研究人工智能雷电临近预警模型的目的出发,以卷积神经网络模型为基础,结合多个时间序列的雷达产品(组合反射率、液态水含量、回波顶高)与闪电数据,对雷电临近预报方法进行基于卷积神经网络结构的应用,以福建省2017—2018年雷达、闪电数据为样本完成了模型的训练与预测研究。训练结果显示,15~30 min模型训练样本测试集准确率为0.798 5;选取福建省2019年20个雷电过程验证分析表明,15~30 min模型对动力抬升型雷电过程预警TS评分为0.716,夏季局地热雷暴预警TS评分为0.694,与常规采用雷达、闪电阈值控制的雷电预警算法相比,准确率有一定的提高,具有一定的实践意义。
引 言
人工智能是近几年来发展特别迅速的一门科学技术,普遍被认为是下一场科技革命的生产力代表,2017年8月国务院印发《新一代人工智能发展规划》,提出了面向2030年我国新一代人工智能发展的战略目标。逐步推进气象业务工作与人工智能技术的对接,拓展未发掘的预报模式,满足多角度气象专业服务需求,是实现气象工作自动化、智能化、现代化的重要途径。
我国在20世纪90年代初已开始气象领域人工智能方面的预报研究,如中国气象局在“八五”期间就成立了《人工智能、模式识别在天气预报业务中的应用》课题项目,运用神经网络模式对暴雨预报进行试验(王宝荣,1993)。进入21世纪后,国内出现更多基于机器学习的气象人工智能研究,如贺佳佳等(2017)采用支持向量机(SVM)开展局部短时临近降雨预测研究;孙全德等(2019)对数值天气预报模式ECMWF预测的华北地区近地面10 m 风速进行订正,指出三种机器学习算法的订正效果均好于传统订正方法模式输出统计〈MOS〉的结果;熊亚军等(2015)利用KNN(KNearest Neighbor)数据挖掘算法构建等级预报分类器,开展霾等级客观识别实验;陈勇伟等(2013)、赵旭寰等(2009)使用BP(back propagation)神经网络模型,选用7个对流参数对雷暴活动进行潜势预报。
在雷电临近预警领域,目前主要是使用雷达组合反射率、液态水含量、回波顶高、闪电数据进行预警,如:张其林等(2010)对闪电发生进行高密度区域识别并外推,得出雷电预警产品;吕伟涛等(2009)借鉴美国NCAR的TITAN(Thunderstorm Identification,Tracking,Analysis,and Nowcasting)算法对雷达数据进行重点区域识别与外推,研究格点雷电发生概率;秦微等(2016)在深圳地区采用TITAN算法对某次强风暴过程中的强回波区进行分析,得出该算法识别效果理想的结果;刘维成等(2015)对甘肃中部雷达回波单体与雷电活动之间的对应关系进行分析,得出回波强度、回波顶高、垂直累积液态含水量与雷电发生的阈值关系,并根据该结论建立了雷电预警方案;常越等(2010)对湖南省闪电的发生和雷达关系进行研究,认为闪电发生与回波强度、回波顶高、速度场特征、垂直液态含水量等有着密切的关系;此外还有研究使用卫星、探空、大气电场等数据对雷电预警关系进行分析。国外在雷电临近预警研究方面,Hondl and Eilts(1994)根据雷暴发展到不同高度层的回波特征与阈值进行短时临近预报,Schmeits et al(2008)运用数理统计方法处理和开发雷电临近预报系统,Jacobson et al(2011)统计分析卫星、闪电定位系统等提供的雷电数据,计算雷电发生概率。近几年国外在雷电临近预报领域也有了一些新的成果,如Ivanova(2019)应用地面微波辐射计进行雷电预警;Baldini et al(2018)利用双偏振雷达识别graupel粒子,研究与雷电活动的相关性。在人工智能的气象应用上,还没有明确应用于雷电临近预警的成果,但在气象预报的其他领域已经有较多的人工智能应用产品,如:Andreev et al(2019)将卷积神经网络应用于云识别与检测,Saha et al(2016)采用自编码器对印度季风进行预测应用;Geng et al(2019)引入ConvLSTM建立包含不同编码器、预测解码器的LightNet模型对雷电进行预测等。探索一种新的雷电预警思路与当前人工智能技术的兴起不谋而合,利用人工智能技术来进行雷电临近预警具有很好的探索意义。
现行的雷电临近预警技术方案主要以线性或简单的非线性函数为主,非线性化程度低,以非变形外推为主,较少看到变形外推的应用模型,或者以中尺度分析技术中的“配料法”为基础,对雷达、闪电数据进行“配料”阈值控制预警,而实际雷电的发生与各影响要素之间不仅只存在线性的关系,可能还有我们未发掘的更为复杂的非线性规则,因此采用具有强非线性表征能力的神经网络技术来处理雷电临近预警问题是提升预警效果的有效途径。
本文选用卷积神经网络(convolutional neural network,CNN)为基础,构建基于CNN的雷电临近预警模型,将雷达组合反射率、液态水含量、回波顶高、云地闪电数据等指标按CNN所需求的“图片”模式进行网格“切片”化处理,对数据进行时间、空间维度上的延伸,建立相应的神经网络模型,采用谷歌公司人工智能线性代数编译器(TENSORFLOW)为计算工具,对该模型进行神经网络训练,将得到的结果进行实例的检验和应用。
1 模型设计
1.1 CNN概述
CNN是一种专门用来处理类似网格结构数据的神经网络,它采用具有一定大小、包含权重矩阵的格点网(卷积核,也称过滤器)对输入图像逐个位置进行扫描和卷积,利用卷积实变函数运算实现对图像局部特征的信息提取并保存在权重矩阵中,加上中间添加的非线性激活函数,使整个神经网络具有很强的学习和非线性处理能力,实践表明该计算方式可以很好地获取图片的总体与局部特征,其一般流程是对输入的多通道图像(可以把气象格点数据看成是图像)经过多次的卷积、池化操作,提取到图像深层次的高维特征,再将卷积、池化操作后的矩阵展开成神经网络层,经过一定层数的神经网络层计算后,根据需求输出对输入图像某一种类别属性的预测结论,例如判断输入的图像是哪一种动物、哪一个数字等。
尽管CNN已经在计算机视觉、图像分析等领域取得了积极的成果,但也存在着一定的不足和缺点,主要表现在对训练数据的需求量大、自身模型计算量庞大及训练时间长、硬件要求高、生物学基础支持不足、无法掌握其内部的计算机理、过多的参数设计使得模型设计的最优解难以精确得到,等等。尤其在气象预报应用领域,由于常规的CNN处理的是图片输入、有限类别输出的情形,而在格点化气象预报领域,则要求输入图片,针对图片的所有格点都要求有结果输出的情况,即图片输入、图片输出,在人工智能领域称这样的问题为像素级的预测模型,因此常规的CNN模型无法直接应用到气象格点预报中。为了解决气象预报这样像素级的人工智能CNN模型,本文提出了一种采用切片式的数据处理方法,将输入的气象格点图片根据像素预报点转换成多量的“小切片”,作为新的输入图片进行CNN预测;为了规避这种方法可能带来的大计算量,本文设计了适宜的数据压缩模型,有效降低了整个模型的计算量,使模型的预测计算可以在1~2 min内实现福建省区域内的格点化预警预报,保证预警产品的时效性,具体模型内容讨论如下。
1.2 参数选取
深度神经网络是一个封闭的黑盒子计算单元,目前在人工智能领域对于神经网络的工作原理尚不清楚,只知道“神经元+激活函数”可以实现复杂的非线性数学变换,本文根据目前雷电临近预警预报工作常用的思路与方法,结合雷电发生、发展的规律以及预报产品的时效、精度需求,选用下面几个参量作为神经网络的输入与输出单元。
(1)雷达产品数据,包括组合反射率、液态水含量、回波顶高三个参数。 这是目前雷电临近预警预报工作最常用的三个指标。国内多项研究也表明这三个参数可以很好地适配雷电临近预警工作,结合雷达数据质量控制与SWAN雷达拼图的处理等相关研究,如对有源干扰回波识别(黄小玉等,2019)、雷达CAPPI格点数据均一性处理(叶飞等,2020)、SWAN雷达拼图产品处理(张勇等,2019)。对所有雷达产品数据进行质量控制和处理,剔除可能存在误差或错误的雷达产品数据。
(2)云地闪数据。 闪电定位监测数据是目前表征雷电发生位置、时间最直接、精度最高的观测产品。利用不同时次地闪发生位置的变化来预测下一时次的雷电发生位置,是当前地闪数据在雷电临近预警工作中的主要应用思路。本文通过对云地闪数据按雷达时次(本文规定每个小时的第00、06、12、…、54 min,即雷达数据产生的时间为雷达时次,以下同)和设计的栅格大小进行每个栅格云地闪频数的统计(时间分辨率:6 min,空间分辨率:0.01°),实现将一条一条的云地闪数据转变成和雷达产品数据一样格式的格点化数据,应用到神经网络模型中,设待计算时刻为t1,计算t1往前6 min的时刻t0,获取[t0,t1]时间、栅格区域内所有发生的云地闪数据,计算其总频数作为该t1时刻、该栅格区域的标示值。
(3)预警输出标签设计。按二分类对预警输出结果进行标签编制,考虑到雷达、闪电数据的实际到达时间存在一定的延迟(SWAN拼图要等到所有单站雷达数据全到位才能拼图,因此延迟在10 min左右),加上模型计算、结果传输所消耗的时间,虽然也可以做到0~15 min的预警,但该预警结果基本失去其时效意义,因此预报结果设定为当前时刻之后15~30、30~45、45~60 min内雷电发生位置的网格化产品,限于篇幅关系,本文仅对15~30 min 内的预报模型进行讨论、介绍。具体规则:对于某一个预警格点,当该格点在15~30 min的时间区间里监测到有一次以上的云地闪数据时,即标记该预警格点标签值为1,否则则记为0。
1.3 数据切片处理
针对气象预报对预报结果的需求特点(大输入、大输出),本文把每个预报格点看成是一个实例,把一张300×300像素点的预报图片,看成是预报300×300个实例的样式;对每一个预报格点,分别向四个方向拓展指定的网格,形成以预报格点为中心,具有一定长、宽的网格切片,对每个时次、每个参数的网格图层进行一次切片,得到指定大小的网格矩阵,类比为图片的一个“通道”,这样每个时次的每个参数就可以得到一个通道,n个参数、m个时次就可以得到n×m个通道的输入层,再经过CNN的训练和计算后,就可以得到该网格(像素点)的预报结果了,具体思路如图1所示。

图1 单个格点的切片处理方法及雷电临近预警CNN模型示意图Fig.1 Slice processing method for single grid points and lightning nowcasting warning CNN model diagram
1.4 数据压缩
在上述采用切片提取与该网格预报结果有关参数的矩阵时,通过向四个方向分别拓展一定距离的网格来形成该参数一个“通道”的“图片”。经验表明,福建省内中小尺度天气系统移动速度最大在0.1°·6 min-1以内,也就是说,如果要做15~30 min预报的话,需要拓展网格的距离在0.25°~0.5°,保证对中心点有影响的数据包含在这个“图片”内,换算成0.01°的个数就是25~50个栅格,取40格来计算的话,那么按上述拓展方法得到的一个时次、一个指标的切片通道“图片”的分辨率是(40×2+1,40×2+1),即(81,81)。由于这个图片的大小比较大,为了降低计算量、提高预警速率,需要对原始网格化图片进行压缩、池化处理。原来网格单元为0.01°×0.01°,选取k×k个相邻的网格,将这k×k个网格的所有数值提取出来作为一个样本序列,取这个样本序列的最大值、中位数表征这个网格压缩后的信息。以本文所讨论15~30 min为例,对于15~30 min 预报模型,选取k=3,即把某参数、某通道切片的每9个网格压缩成1个网格,每个网格储存原9个网格数值的最大值、中位数两个数值信息,如图2所示,对雷达组合反射率、液态水含量、回波顶高提取这两个值,对于地闪参数则仅用这3×3个网格的总地闪个数表示,即实现了2/9的压缩、提取,大大减少了计算量,满足了临近预报对预报产品时效性的需求。
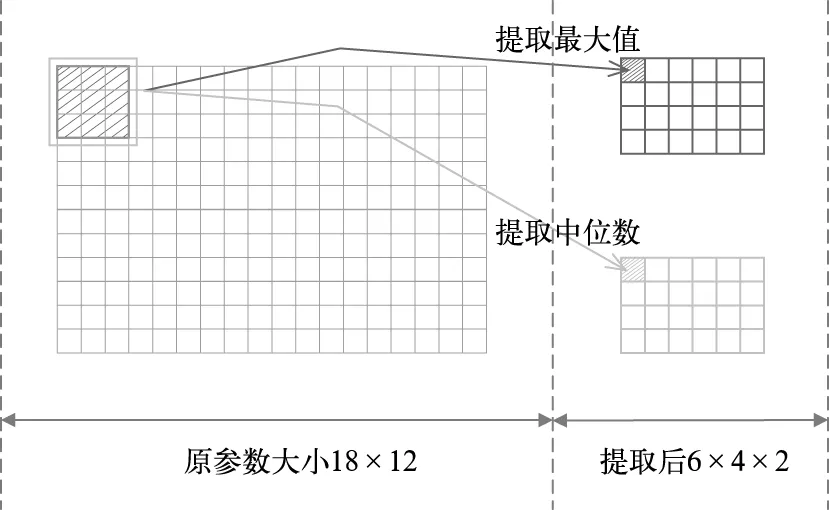
图2 某参数某通道数据3×3压缩方法示意图Fig.2 A diagram of a channel data 3×3 compression method for a parameter
本文实际模型中先对各指标按3×3网格进行格点压缩,对于每个预报格点按东10、西13、南8、北6个格点距离拓展进行切片处理,这样处理后每个参数通道的切片分辨率为(10+13+1,8+6+1),即24×15=360,对每个参数选取当前预报时刻往前2个雷达时次的值,最终本文设计模型的每个预报格点输入情况总结如下:
(1)预报格点基准大小为0.03°×0.03°;
(2)共包含雷达组合反射率、液态水含量、回波顶高以及云地闪4个参量;
(3)每个参量按0.03°×0.03°网格进行格点压缩,压缩后雷达组合反射率、液态水含量、回波顶高包含最大值、中位数值两个图片通道,云地闪包含总频次一个图片通道,4个参量合计有3×2+1×1=7个图片通道;
(4)每个参量包含当前时刻以及当前时刻往前6 min时刻的2个时间序列,即按上述处理后,共计有7×2=14个0.03°×0.03°大小的图片通道;
(5)每个待预报格点在每个通道上按东10、西13、南8、北6个格点距离拓展进行切片处理,每个切片大小为24×15,14个通道得到14个通道的24×15分辨率的小图片,实际输入大小为24×15×14=5040。
1.5 CNN模型设计
按上述方法对雷达、闪电数据进行切片及切片压缩处理后,对于每一个预报格点,可以得到14个通道、24×15分辨率的小图片,将这14个通道的图片作为神经网络模型的输入,按“两次卷积-池化-两次卷积-池化-展开-全连接层-全连接层-激活函数(sigmoid)激活输出”的流程建立深度学习模型,具体如图3所示,模型中各个处理单元设计如下:

图3 CNN设计模型示意图Fig.3 Diagram of the model design of convolutional neural network
(1)卷积层:选用2×2滤波器,移动步长为1,采用边界不填0的卷积处理方式。这主要是考虑使用的4个参数的数值存在较多0值的情况,如果采用0值填边的话会使神经网络在训练时以为边界没有天气活动,进而引起较大的误差。通道数按输入通道数的1.25倍数递增(取整),采用层标准化技术(batch normalization)对每层输入值进行规范化处理,最后按激活函数(relu)对卷积层做非线性激活,随意节点丢弃率(dropout)取值为0.15,防止模型的过拟合,将结果传递到下一层模型中。
(2)池化层:按最大池化(max pooling)模式进行池化操作,移动步长为2,采用边界不填0的卷积处理方式,理由同卷积层的设计。
(3)全连接层:在两次卷积-池化操作后,将输出的多通道图片按单列格点展开,进行全连接操作。全连接共两层,全连接节点设置为64、32,每个全连接层都采用层标准化技术对输入值进行规范化处理,选用激活函数(relu),随意节点丢弃率(dropout)取值为0.15,防止模型的过拟合,最后使用激活函数(sigmoid)对前面神经网络运算结果进行最后预测,定义最后的预测值>0.5为Y=1类标签,预测值≤0.5为Y=0类标签,得到0、1的二分类结果。
对于Y标签按如下规则确定:以本文讨论的15~30 min预报为例,若预报网格在预报时刻往后的15~30 min监测到云地闪,则不管该时段内发生多少次闪电,都标记为1,没有监测到云地闪即标记为0。
1.6 数据与模型训练
以2017年3—10月、2018年3—7月福建省雷达、闪电监测数据为样本,对每个月选取当月闪电定位监测数据文本文件大小最大的两个日期,对每个选取日期按每个小时、每个雷达时次、每个经纬度网格进行切片选取(X输入)与对应15~30 min后该经纬度网格雷电发生情况(Y二分类标签)进行提取。 由于Y=0且X大部分数据为0值(即各个网格的雷达、闪电数据基本为0,对应预报时效内没有闪电)的情况占所遴选样本的比例非常大,因此在数据提取时判定当X数据中雷达组合反射率的值大于20 dBz的个数占比小于10%时,本次样本提取放弃; 此外由于闪电定位监测数据存在一定的偏差,经常出现在同一时间段,某个闪电数据的发生位置与当时的闪电集中区域偏离较大的情况,为了使训练样本Y=1的标签降低噪声、干扰的情况,样本提取时剔除闪电定位方法为2站、雷电流幅值绝对值≤2 kA、某个闪电前后10 min内距离本次闪电0.5°范围内没有其他闪电监测记录的闪电数据。为了避免训练样本出现0、1标签个数差别太大的情况,对当前得到的所有训练样本进行随机遴选,根据计算机的计算负荷,设置总量为80 000个样本,遴选0、1样本个数各40 000个,进入后续的网络训练。 具体网络训练采用Adam优化器,即在梯度下降进行迭代求最优解的基础上,根据一阶梯度矩估计、二阶梯度矩估计计算更新步长的优化模型,设置初始学习率为0.001,模型学习率自动衰减为0.9,设置单次训练样本数(batch size)为120,选取10%的样本容量作为测试数据,选择二分类损失函数(binary crossentropy)为损失计算方式,设置最大训练次数为500次,将训练过程中准确率最好的参数矩阵保存为最终训练结果。
按上述方法与规则对模型进行训练,绘制整个训练过程的损失(losses)与准确率(accuracy)曲线(图4)。由图4可知,损失曲线下降的速度适均,说明模型设计的初始学习率可行;最终测试集损失控制在0.430 1,测试集准确率为0.798 5,测试集与训练集的损失、准确率曲线基本贴合,训练后期也没有出现明显的分开,表明模型没有出现明显的过拟合现象,也说明按本文设计的训练数据提取、遴选方法可行,保证了数据集数据质量的一致性与噪声的随机分布。整个训练模型在大概训练350个训练次数后开始趋于平稳,模型学习率经自动衰减100个训练次数仍没有明显下降和变化,可见模型在这时基本已训练到饱和,整个模型的训练过程合理、可行。
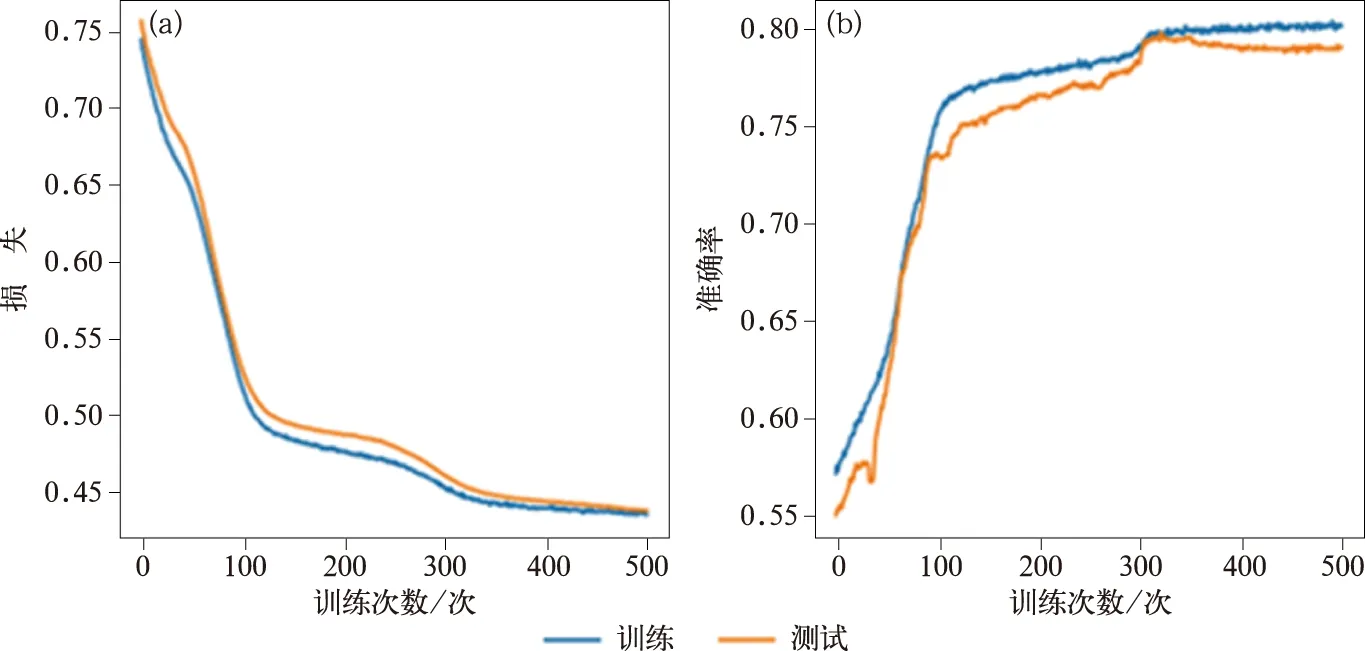
图4 模型训练损失曲线(a)和准确率曲线(b)Fig.4 Curves of model training losses (a) and accuracy (b)
2 应用与检验
本文所建立与训练的模型在福建省2019年的汛期工作(3—10月)中得到完整的应用。从总体上看本文讨论的15~30 min雷电预警效果总体表现稳定和良好,取2019年4月22日14时的预报、实况图(图5)为例,由图可见,模型预报的几个雷电发生区域在15~30 min后的都有闪电发生。需要说明的是,预报图中对预报格点按福建省边界外围一定距离做了裁剪,因此实况图中左下角的闪电并非没有预报出来,而是被裁剪。

图5 2019年4月22日14时的15~30 min雷电预报(a)、实况(b)对比Fig.5 The 15-30 min lightning nowcasting (a) and observation (b) at 14:00 BT 22 April 2019
为了更精确了解本模型的实际准确率情况,本文按系统动力抬升型雷电过程、副高边缘局地热雷暴过程这两种福建省主要雷电天气类别,选取了2019年主要雷电天气(两种类型各选取10 d)作为样本进行TS评分计算,结果表明:
动力抬升型雷电过程, TS平均评分为0.716,平均漏报率、空报率分别为0.095、0.190;
局地热雷暴型雷电过程,TS平均评分为0.694,平均漏报率、空报率分别为0.112、0.194。
检验结果表明,模型对前汛期动力抬升型的雷电过程预警效果略微好于夏季局地热雷暴的雷电过程,考虑到闪电定位系统本身存在的误差,且福建省多山地地形,这样的预报结果基本可以接受。有研究采用雷达与闪电阈值控制算法,对福建省进行格点化雷电临近预警应用,按雷达组合反射率37 dBz、垂直液态水含量1.5 kg·m-2、回波顶高11 km作为雷达预警控制的阈值,研究中直接闪电预警判定距离为10 km,间接闪电预警判定距离为15 km,闪电预警解除判定距离为15 km,最后分析得出其TS评分为0.671(张烨方等,2019)。相比之下,本文设计与训练的CNN模型的准确率有了一定提升。
3 结论与展望
本文以雷达产品(组合反射率、液态水含量、回波顶高)和闪电数据为指标,对CNN模型进行了适应雷电临近预警需求的改进和调整,对改进后的模型进行了训练、检验,得出以下结论:
(1)本文设计的切片式处理方法可以解决CNN在气象格点预报应用中遇到的像素级分类问题,设计的格点压缩算法可以在短时间、一般计算硬件的条件下,得到一个省范围内的格点预报产品,满足临近预警服务对时效性的要求。检验表明设计的模型在预警效果上比常规采用“配料法-阈值控制”的雷电临近预警模型有了一定的提高,模型对动力抬升型雷电过程的预警效果稍微好于副热带高压边缘局地热雷暴过程的预警效果。
(2)原始训练数据的质量对模型的训练效果有很大影响,原始数据噪声的大小、不同类别标签的数量比例遴选不合理甚至可能会使训练的模型矩阵出现预报结果全是0或1的“垃圾输出”;此外,在雷电临近预警领域,对闪电定位数据进行适宜的修订可以有效提高模型的训练准确率,本文按“剔除2站定位、雷电流幅值绝对值≤2 kA、某个闪电前后10 min 内距离本次闪电0.5°范围没有其他闪电监测记录的闪电数据”的条件对训练的闪电数据进行了剔除和修订后,模型的训练准确率提高了近0.10,是模型训练过程中各个环节、参数调整中准确率变化最大的地方。
(3)1~2 h预报思路展望。相较传统的雷达回波相关性跟踪(TREC)的外推算法,本文所建立基于切片式处理、CNN模型的雷电临近预警模型在预报区域的外推上,初步具有变形外推的效果,但在不少方面仍有改进和不足的地方。如:模型没有根据不同的天气系统进行分类训练、预警;模型在参数的选择上没有把高程、土壤、云闪及潜势预报的因子列入其中;限于计算硬件设备的影响,本文输入数据的时间序列时段、切片大小有限等。需要看到的是,单纯依靠上述模型只能满足15~60 min的雷电预警需求,要做1~2 h的预警产品,需要再引入其他强天气潜势预报涉及的物理量,但这些物理量在格点精度、时间序列点上与雷达、闪电的数据无法同步,这也是影响1~2 h临近预报格点产品效果的重要因素,本文研究项目也正尝试对这些物理量进行基于深度学习网络模型的处理,努力将其融入到本文所研究模型的1~2 h预报产品中,以更好地实现人工智能技术在雷电临近预警工作中的有效应用。
