基于半监督方法的脑梗死图像识别
2021-04-20欧莉莉邵峰晶孙仁诚
欧莉莉,邵峰晶*,孙仁诚,2,隋 毅
(1.青岛大学计算机科学技术学院,山东青岛 266071;2.青岛大学附属医院,山东青岛 266071)
0 引言
近年来,随着医学成像技术不断提高,各种医学设备产生的大量医学图像,为医学图像识别研究提供了充分的数据来源。然而,由于医学图像数据具有多模态性、多维性和不确定性等特点[1],给医学图像识别带来了很大挑战。传统的医学图像识别是由医生对患者的超声影像进行肉眼观察诊断,其识别率低、耗时比较长,诊断结果也往往具有主观性和低可靠性,难以满足当下的医学需求,而深度学习(Deep Learning)的出现促进了医学图像识别的进一步发展。深度学习作为机器学习的一个重要分支,其原理是模仿人脑的机制,自动学习数据的内在规律,利用分层网络模型逐层地提取特征,这些特征能准确地反映数据信息,从而提高图像识别的准确性。
生成对抗网络(Generative Adversarial Network,GAN)是由Goodfellow 等[2]在2014 年提出的,并且在深度学习领域引起广泛的研究热潮。由于GAN 的生成能力比较强,人们逐渐将其应用于图像领域,例如图像合成[3]、图像修复[4]、图像识别、视频检索[5]、根据文字生成图片[6]、图像超分辨率[7]、灰度图像上色[8]及X光图像的生成[9]等方面。在图像识别领域中,虽然基于GAN 的方法[10]具有很高的识别率,但是与监督学习方法一样,在训练时需要大量的标签数据。当标签数据不足时,会影响一些特定问题的识别效果。如:在对医学图像分析时,采集到的样本需要先由经验丰富的医生进行标注,然后才能进行分析,但是这个过程要耗费大量的时间和人力,还会浪费无标签样本中的一些重要信息[11]。
本文针对这个问题,将半监督生成对抗网络(Semi-Supervised GAN,SSGAN)[12]与深度卷积生成对抗网络(Deep Convolutional GAN,DCGAN)[13]的特点相结合,构建半监督深度卷积生成对抗网络(Semi-Supervised DCGAN,SS-DCGAN)模型,在该模型中将具有特征提取功能的卷积神经网络加入到生成器与判别器中,用来提取图片的特征信息。本文实验中选用的是脑部磁共振(Magnetic Resonance,MR)图像数据,其中只有少量的标签数据,通过对比不同模型在该数据集上的实验结果,证明半监督深度卷积生成对抗网络具有一定的鲁棒性。
1 生成对抗网络
GAN 是一种深度学习模型,主要由生成器和判别器组成,生成器G与判别器D是一种博弈对抗关系。GAN 网络中生成器与判别器是一种对抗关系,在模型训练时需要对两个网络同时进行训练[14],生成对抗网络的基本框架如图1所示。

图1 GAN基本框架Fig.1 Base framework of GAN
生成器负责最大化地拟合服从某种简单分布的随机噪声,使其尽可能地服从真实数据的分布,并生成伪样本;判别器负责判断输入的数据是否为真实数据,若为真则输出为1,否则为0。训练时,生成器与判别器相互博弈,前者生成的伪样本慢慢接近真实数据,后者的判断能力慢慢增强。当判别器无法确定数据是真实数据还是生成数据时,生成器已经很好地学习到了真实数据的分布规律,即D(G(z))=0.5。式(1)为GAN模型的优化函数[2],由前后两部分组成:
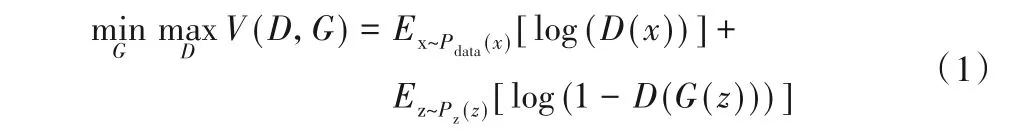
其中:x为真实数据,服从真实数据分布Pdata(x);z为随机噪声,服从先验分布Pz(z);G(z)是将随机噪声z输入到生成器所产生的伪样本;D(x)和D(G(z))分别为判别器判断x和G(z)为“真”的概率。
在判别器中,要提高判断是真实数据还是生成数据的能力,需要对判别器的参数进行更新。对于真实数据就是要最大化D(x),即最大化log(D(x));对于生成数据G(z),要最小化D(G(x)),即最大化log(1-D(G(z)))。由此可以得出判别器的目标函数,如式(2)所示:

在生成器中,通过欺骗判别器来提高自身生成伪样本的能力,就要对生成器的参数进行更新。要想使判别器判断不出输入的数据是否是伪样本,就要使D(G(z))最大,即最小化log(1-D(G(z)))。因此,生成器的目标函数如式(3)所示:
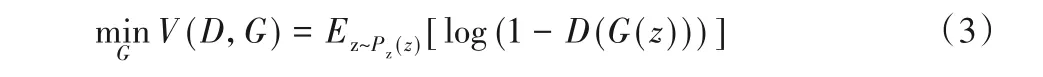
2 半监督生成对抗网络
2016 年OpenAI 提出了GAN 的改进模型——半监督生成对抗网络(Semi-Supervised GAN,SSGAN)[10]。本文将该网络模型应用到脑部MR 图像的识别上。相较于GAN 模型,SSGAN 使用标签数据和无标签数据共同训练有类别信息的样本。
SSGAN 模型的基本框架如图2 所示。将随机噪声z输入到生成器,并输出生成样本G(z);G(z)与有标签、无标签的脑部MR数据一同输入到判别器中。假定对于一个K分类问题,将生成器生成的伪样本记为y=K+1类,判别器最后将输出K+1 维的分类结果。在SSGAN 训练过程中,其损失函数采用监督学习与无监督学习相结合的方式,这种做法有助于提高半监督分类的准确率[15]。

图2 SSGAN基本框架Fig.2 Base framework of SSGAN
为了能够更好地获取脑部MR 图像的特征信息,本文还采用了将传统的监督学习方法卷积神经网络(Convolutional Neural Network,CNN)与无监督的GAN 相结合的深度卷积生成对抗网络(Deep Convolutional GAN,DCGAN)[11]。该模型是由Alec Radford 于2015 年提出的,并首次将卷积神经网络与生成对抗网络结合在一起,利用卷积神经网络的特征提取功能[16],来提高GAN模型训练过程的稳定性。
DCGAN的主要贡献表现在下列三个主要方面:
1)改变了普通卷积神经网络在卷积之后接一层池化的结构,去掉池化层。判别器中池化层换成步长为1 的卷积层,而生成器中的池化层换为反卷积层。
2)删除网络中的全连接层,将卷积神经网络连接到生成器判别器的输入输出层。
3)在生成器和判别器输入层、中间层都使用批量归一化(Batch Normalization,BN)。
除此之外,因为GAN 中使用的是不适合高分辨率生成的maxout[17]激活函数,而DCGAN 在生成器的输出层使用Tanh激活函数,其他层均使用ReLU(Rectified Linear Unit)[18]激活函数;在判别器的每层都使用LeakyReLU[19]激活函数。
3 半监督深度卷积生成对抗网络
半监督深度卷积生成对抗网络(SS-DCGAN)的主要思想是:结合了SSGAN 和DCGAN 的特点,建立图像识别模型SSDCGAN。在模型中将深度卷积神经网络引入到生成器与判别器中。在训练时,判别器作为分类器进行训练。在该模型中不仅使用了标签数据,还使用了大量的无标签数据,主要是为了利用无标签数据来提高标签数据的分类精度。在训练时,虽然无标签数据不带有类别信息,但却有助于学习数据的整体分布,同时能够提高模型的分类准确率。
在生成器中,首先,将服从某种特定分布的100 维随机噪声输入到生成器中,经过Reshape 操作,得到一个三维张量,大小为4×4×1 024;然后将该三维张量经过6 次反卷积和上采样,生成与真实数据大小及分布一致的样本图像。最后在输出层输出大小为128×128×3 的伪样本图像,其中128×128 代表图像的分辨率,3 代表图像通道数。在反卷积过程中,卷积核ω的大小为5×5,步长stride 为2,完成一次反卷积操作,都要进行批量归一化处理。网络的输出层采用的是Tanh 激活函数,其余层采用的是ReLU激活函数。其结构如图3所示。
在判别器中,采用的了17 层卷积神经网络和3 个全连接层。首先,通过17 层卷积层对128×128×3 的图像进行特征提取,再利用全连接层对特征信息进行整合,最后输出分类结果。每完成一次卷积操作就要进行批量归一化,在卷积过程中采用的是LeakyReLU 激活函数。它与ReLU 函数的不同之处在于,LeakyReLU 函数在负半轴保留了数值为0.2 的斜率,作用是:在训练过程中,避免因出现梯度消失,模型无法收敛的情况。网络的输出层是全连接层,并通过Softmax 输出归一化类别概率。其结构如图4所示。

图3 SS-DCGAN生成器结构Fig.3 Generator structure of SS-DCGAN

图4 SS-DCGAN的判别网络Fig.4 Discriminator network of SS-DCGAN
4 基于SS-DCGAN的脑部MR图像识别
基于上述模型结构,针对脑部MR 图像识别中有标签数据稀缺的问题,采用了一种基于GAN 模型的半监督方法来实现脑部MR 图像的识别。该方法对网络参数的更新是通过监督损失和无监督损失共同训练,在生成器中,利用特征匹配来提高GAN 的学习能力,通过对抗训练来提高图像识别的准确率。
4.1 数据及预处理
本文所用数据来自青岛大学附属医院神经科,是在有经验临床医生的指导下选取的脑部MR 图像,并将其分为正常(不患脑梗)和异常(患脑梗)两种类别的图像,在异常图像中又根据其患脑梗病变的面积将其分为:腔隙性脑梗死(病变面积<1.5 cm)、小梗死(病变面积1.5~3 cm)、大梗死(病变面积>3 cm)。正常图像的脑组织区域呈灰黑色,而异常图像的脑组织会有部分灰白色区域,如图5所示,图5(b)中框中部分即为病灶区域。
为了使输入图像尺寸与模型相匹配,在输入模型之前需要将裁剪后大小不一的图像设置成相同的大小。考虑到模型训练速度以及计算机性能等原因,选择128×128 像素作为输入图像的尺寸大小。通过对初始样本中的少量图片进行数据增强,将它们以不同的角度逆时针翻转(如10°、15°、20°、25°),从而使数据扩充到6 744 张,并将数据集的80%作为训练集,20%作为测试集,即训练集5 396 张,测试集1 348 张。其中训练集分为标签数据与无标签数据,并且无标签数据要远多于标签数据。

图5 脑部MR图像Fig.5 MR images of brain
4.2 SS-DCGAN模型训练
在SS-DCGAN 中,对于一个K分类问题,将生成器生成的伪样本添加到真实数据中,并记为第K+1 类,将数据x作为判别器的输入,并输出一个K+1 维的逻辑向量(l1,l2,…,lK+1),再通过softmax函数得出归一化类别概率:

其中:Pmodel的最大值对应类别的预测标签。
SS-DCGAN 模型的训练过程就是损失函数的优化过程。在判别器中,要输入三种类别的数据(有标签数据、无标签数据、生成数据),且都有其相应的损失函数,即有标签数据损失Llabel、无标签数据损失Lunlabel、生成样本损失Lgen。
有标签数据损失,即真实类标签分布和预测类标签的交叉熵损失,此表达式为:

无标签数据损失,即无标签数据来自真实数据,此时y≠K+1,该表达式为:
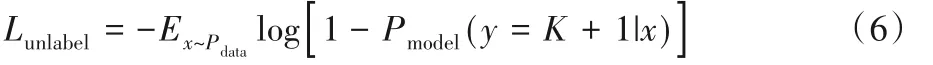
生成样本的损失,即生成器生成的伪样本被判别器判断为假样本的损失,此时y=K+1,该表达式为:

其中:x为数据图像;y为有标签数据的标签,即y∈{1,2,…,K,K+1};x,y~Pdata表示输入带有标签y的真实数据图像x;x~Pdata表示x是真实数据分布中的无标签数据;x~G表示x来自生成器生成的伪样本;Pmodel(·|·)表示预测类概率。
在判别器的损失函数中:
1)有标签样本的损失Llabel,相当于一个标准的监督分类任务的训练过程,对于一个K分类,优化网络参数需要通过最小化标签数据样本和模型预测分布Pmodel(y|x)之间的交叉熵。
2)无标签样本损失Lunlabel,在训练时就是要尽可能最大化无标签数据来自真实数据的概率。
3)生成样本损失Lgen,在训练时就是要尽可能地最大化样本来自生成样本的概率。
判别器的训练过程就是优化损失函数的过程。其中,对有标签数据进行监督学习,对无标签数据和生成样本进行无监督学习。即,判别器的总损失函数LD是由监督损失函数Lsupervised和无监督损失函数Lunsupervised组成,公式如下:
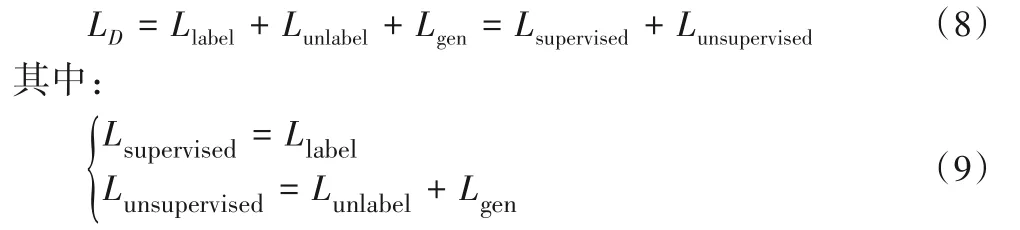
判别器会将生成样本判别为假样本,为了欺骗判别器,达到扩充样本的目的,就需要生成器生成的伪样本近似拟合真实数据。在本文并没有采用原始GAN 中的方法来定义生成器的损失函数LG,而是采用特征匹配的方法[10],即:训练过程中,G的损失函数为生成样本与真实样本特征匹配的结果,通过最小化损失函数,生成器实现最大化拟合真实数据的分布。其定义为:
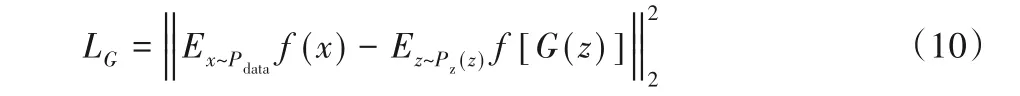
其中:f(·)表示判别器中间层的特征值;||·||2表示2-范数。
本文为了提高模型的学习能力,将监督和无监督损失相结合,共同来对判别器的参数进行调整,过程为:训练时,判别器与生成器交替训练,如果要更新一方的参数,就要固定另一方的参数。对判别器训练时,参数的更新通过最小化标签数据和模型预测分布之间的交叉熵,无标签的真实数据和伪样本需要通过GAN 的对抗训练原理来进行参数的更新。训练生成器时,采用的是特征匹配方法来拟合真实数据的分布。SS-DCGAN 模型是通过监督与无监督的联合训练来实现半监督分类功能。
SS-DCGAN模型的训练过程如下:
1)将服从某种简单分布的随机噪声z输入到生成器,得到伪样本G(z)。
2)判别器中输入真实样本x(有标签、无标签)和伪样本G(z),并通过softmax输出归一化概率值D(x)和D(G(z))。
3)使生成器的参数不变,如果图像为有标签的真实数据图像,则将Llabel作为损失函数;若真实图像为无标签数据图像,则Lunlabel作为损失函数;若输入图像为生成器生成的伪样本图像,则Lgen作为损失函数。判别器的参数调整采用Adam梯度下降法。
4)保持判别器的参数不变,全连接层的输出为中间层特征,生成器参数的调整是通过真实图像与伪样本的特征匹配。
5)以上4个步骤重复执行,当达到设定的epoch结束。
6)模型训练完成后,将测试集输入到判别器中,输出图像类别。
5 实验与结果分析
本文实验环境为Windows 10 系统,CPU 3.60 GHz,RAM 32.0 GB,Python版本为3.7。
实验中数据加载方式为批处理,大小为16,epoch 为1 500。采用全局学习率为0.000 3、动量大小为0.5 的Adam优化器来优化损失函数[14]。为了充分验证SS-DCGAN 模型图像识别的有效性,在脑部MR 图像上进行实验。模型没有对输入的图像进行预处理,只是将图像做归一化处理,再映射到[-1,1]的范围上[14]。
将脑部MR 图像在SS-DCGAN 模型上训练1 500轮后判别器与生成器损失函数(D_loss 和G_loss)的变化曲线图如图6所示。

图6 模型损失变化趋势Fig.6 Loss trend of model
从图6 可看出,随着训练次数的增加,判别器与生成器的损失都呈下降趋势。在D_loss 损失图中,在训练初期出现急剧下降的趋势,后期部分损失函数出现震荡现象。而在G_loss 损失图中,训练时会出现大幅震荡现象。原因是:两个网络训练时进行博弈对抗,并不断学习图像的特征,后期两个网络的学习能力都逐渐增强,就会出现图中所显示的此消彼长的震荡现象[9]。
图7 为训练情况下模型的分类准确率结果,其训练情况下的平均准确率达到95.05%。
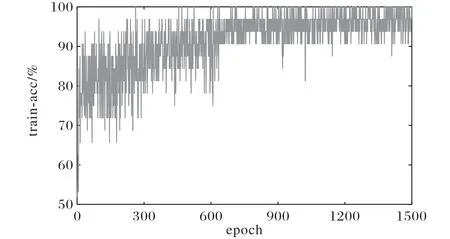
图7 脑部MR图像上训练准确率变化趋势Fig.7 Change trend of train_acc on MR images of brain
训练结果表明,脑部MR图像在SS-DCGAN模型上进行训练时得到了较高的训练准确率。为了测试SS-DCGAN 在标签数据较少时的分类性能,将本文模型与监督学习的卷积神经网络(CNN)[20]、半监督梯度网络(Ladder Network)[21]以及ResNet32(Residual Network 32)进行对比实验。将有标签数据的数量依次分为25、50、100、250、600、1 200,在这6 种不同标注数量的样本中采用的数据集都是来自训练集。表1 为上述4 种方法在这6 种不同标注数量样本下的平均准确率,表2为不同标注数量样本的测试时间,图8 为平均准确率的变化趋势图。
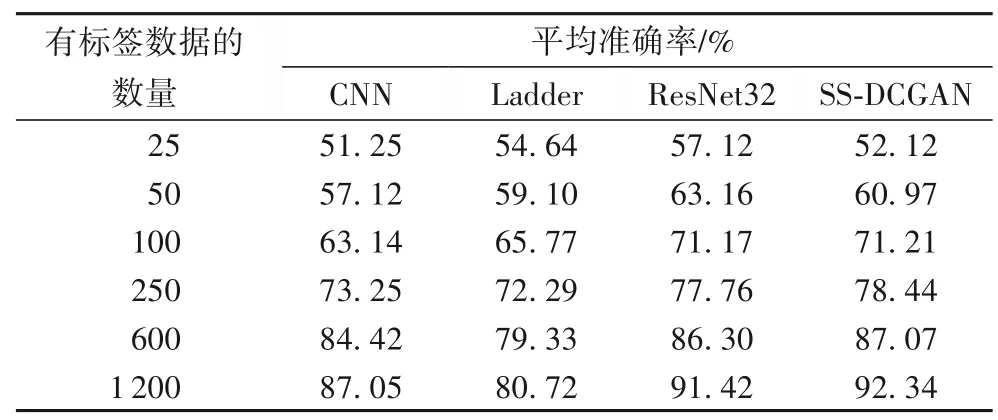
表1 不同标注数量样本的平均准确率Tab.1 Average classification accuracy of samples with different numbers of labeled data

表2 不同标注数量样本的测试时间Tab.2 Test time of samples with different number of labeled data
表1 中的数据是每个模型在相同数据集、epoch 为1 500的情况下经过6 次实验得出的平均准确率,从中可以看出,SS-DCGAN 在有标签数据较少时就能达到相较于其他方法不错的准确率。例如:SS-DCGAN 在只有50 个标注样本时就可以达到60.97%的平均准确率,但CNN想要达到与SS-DCGAN相当的准确率就需要50~100个标注样本。SS-DCGAN相较于其他两种模型,即半监督梯度网络和ResNet32,都表现出优越的性能。但是尽管在相同数据集下,经过多次实验,SSDCGAN 比ResNet32 的准确率高得并不是很多。所以为了排除实验结果具有偶然性,同时也为了验证SS-DCGAN 在同等条件下是否一直比ResNet32 优越,对Mnist、Cifar10、SVHN(Street View House Number)三个公开的数据集在SS-DCGAN和ResNet32 上都进行epoch 为1 000 的实验,实验结果如表3所示。通过对这三次实验的结果分析可得:在不同的数据集上进行实验,SS-DCGAN 对图片的识别准确率要优于ResNet32,并且获得更少的时间损耗。
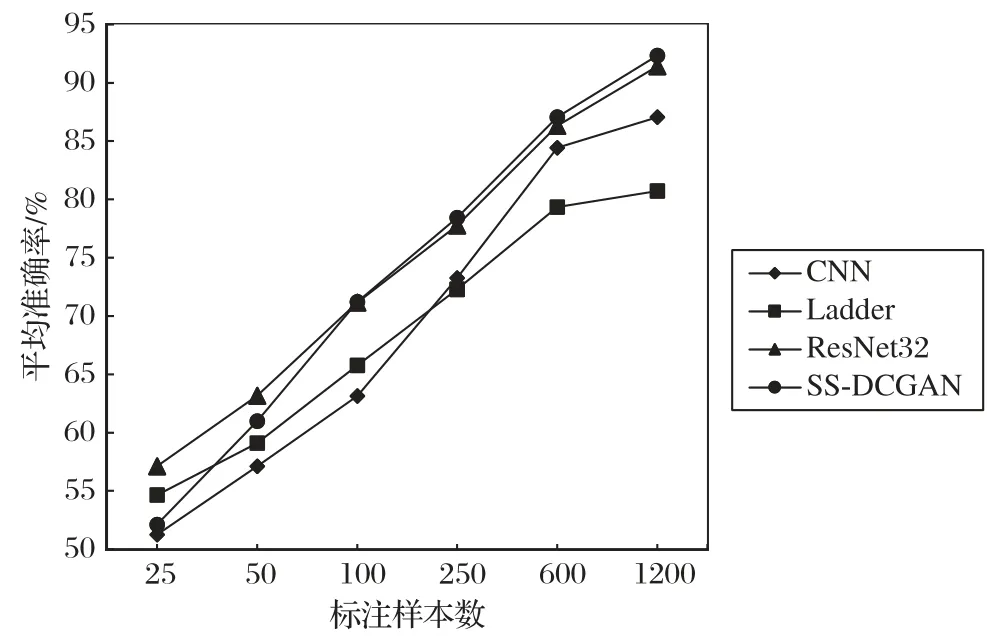
图8 不同标注数量样本分类结果Fig.8 Classification result of samples with different numbers of labeled data

表3 不同数据的准确率与训练时间Tab.3 Accuracy and training time of different data
为了验证本文所提模型的优越性,使用脑梗死数据集在多个改进的GAN 网络模型上进行实验,并且对每个模型分别进行了5 次实验,对实验结果求得平均值。实验的最终结果如表4所示。

表4 不同模型的实验结果对比Tab.4 Comparison of experimental results of different models
分析表4 可以得出,SS-DCGAN 模型的运行时间与GAN、CatGAN(Categorical GAN)、DCGAN 模型相差无几,但准确率要高很多。
通过分析上述的实验结果:SS-DCGAN 模型可以在脑部MR 图像上获得较好的识别效果;同时,在其他数据集上也验证了该方法的有效性且准确率更高,表明本文所提模型具有一定的鲁棒性与有效性。
6 结语
为了解决医学图像识别中有标签数据不足的问题,结合了SSGAN 和DCGAN 的优点,建立半监督深度卷积生成对抗网络模型。通过定义半监督损失函数,以及监督与无监督学习的联合训练,利用模型的判别器来识别脑部MR 图像。在脑部MR 图像数据集下,实验结果表明,SS-DCGAN 在标签数据不足时,能表现出比其他监督、无监督模型更好的性能,且比其他改进的GAN 模型实现效果要好。未来,我们将进一步优化网络结构,使模型的运算更加高效,识别效果更加精准,并将其应用于其他医学图像识别中。
