基于CUDA的SKINNY加密算法并行实现与分析
2021-04-20解文博韦永壮刘争红
解文博,韦永壮*,刘争红
(1.广西密码学与信息安全重点实验室(桂林电子科技大学),广西桂林 541004;2.广西无线宽带通信与信号处理重点实验室(桂林电子科技大学),广西桂林 541004)
0 引言
图形处理器(Graphic Processing Unit,GPU)的架构与中央处理器(Central Processing Unit,CPU)不同,相对于CPU 来说,GPU 的线程更多,带宽更高,延迟更低,更适合并行计算,并且计算速度也要明显高于CPU 的计算速度。GPU 设计之初是用于图形图像处理,但随着GPU 的发展,它被不断地用于大数据、多并行的计算。计算统一设备架构(Compute Unified Device Architecture,CUDA)是NVDIA 发布的并行计算平台和接口模型,支持C、C++等多种编程语言,使得GPU并行计算变得更为容易,是目前最受欢迎的应用编程接口之一。
利用GPU 解决密码学问题的最早工作是Kedem 等[1]和Olano 等[2]使用Pixel Flow 图像引擎快速破解了UNIX 系统的密钥,这使得原本用于解决图像处理问题的GPU 开始用于密码学问题。Cook等[3]第一次尝试对对称密码算法使用GPU进行优化,于2006 年利用OpenGL 实现了高级加密标准(Advanced Encryption Standard,AES);但由于软件的不足和硬件的限制,GPU 比CPU 的性能提升仅有2.3%。2007 年Manavski等[4]第一次利用CUDA进行AES算法的加速,在显卡NVIDIA Geforce 8800GTX 上实现了128 位的AES 算法,加密8 MB 的数据,加密吞吐量可以达到8.28 Gb/s。2009 年Chu等[5]利用GPU 的强大计算能力来降低网络编码和同态哈希的计算成本,他们通过在GPU 上实现网络编码和同态哈希函数(Homomorphic Hashing Function,HHF),所得结果比CPU 上计算速度提高显著,这种实现方式可以为防御分布式系统中的污染攻击提供解决方案。Li 等[6]于2012 年提出在GPU 上AES 的电子密码本(Electronic CodeBook,ECB)模式和密文分组链接(Cipher Block Chaining,CBC)模式的实现,通过将T 盒分配在共享存储器上并采用每个线程处理16 字节的粒度,使得GPU 运行速度比CPU 快50 倍。Cheong 等[7]在2015 年在具有Kepler 架构的NVIDIA GTX 690 上提出加速分组密码IDEA(International Data Encryption Algorithm)、Blowfish 和Threefish的技术,对于三个算法分别实现了90.3 Gb/s、50.82 Gb/s 和83.71 Gb/s 的加密吞吐量。2017 年,Abdelrahman 等[8]提出了使用不同粒度值在三种不同的GPU 架构上的AES-128 算法(ECB 模式)实现。他们的实验结果表明,使用NVIDIA GTX 1080(Pascal)、NVIDIA GTX TITAN X(Maxwell)和GTX 780(Kepler)GPU 架构,吞吐率分别达到277 Gb/s、201 Gb/s 和78 Gb/s。同年,Ma 等[9]在CBC 模式下实现了AES解密,他们对基于GPU 的不同参数设置下的实现进行了全面分析,这些参数包括:输入数据的大小、每个块的线程数、内存分配的方式和并行粒度。最终GPU 上的最优性能是CPU 上的112 倍。2020 年,Yeoh 等[10]提出一种基于GPU 的快速搜索密码学算法差分特性的分支定界算法,文章针对TRIFLE-BC-128 算法,利用中间相遇方法与GPU 相结合,所得结果与基于CPU 的方法相比,搜索效率提高了约58 倍。综上可知,关于分组密码在GPU 上的快速实现研究较多的是对AES 的优化,作为Beierle 等[11]新推出的分组密码算法SKINNY 虽与AES结构类似,都是代换-置换网络(Substitution-Permutation Network,SPN)结构,但由于采用新型设计理念,具有安全性好、使用灵活等优点,特别适合在微控制器和软件上快速实现,备受业界广泛关注,所以对其快速并行实现是目前亟待解决的问题。
本文基于Linux 系统下的CUDA 平台,通过分析SKINNY算法的特性,对该算法的ECB 和计数器(Counter,CTR)模式进行并行加速,在数据量达到64 MB 的加密环境下分析测试了GPU 并行算法的性能,并对基于CPU 实现和基于GPU 实现的SKINNY 算法进行了时间、加速效率、加速比和吞吐量的分析。
1 SKINNY算法
1.1 算法简介
SKINNY 算法是一种新的轻量级密码算法,该算法加密分组为64 和128 位的明文数据,可以使用64、128、192、256 和384 位的密钥来加密。本文快速实现的算法是数据分组长度为128 位、密钥长度为256 位的SKINNY 算法,简记为SKINNY-256。SKINNY 算法的操作是在二维数组上执行的,该数组的初始状态如式(1)所示:
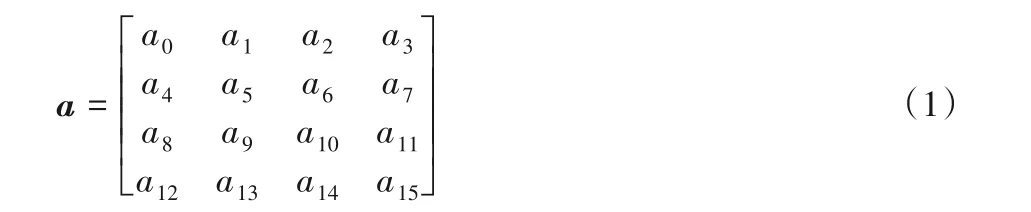
SKINNY-256的轮函数由以下5个操作组成,分别是:
1)字节替换(SubCells,SC):通过S 盒将一个字节替换为另一个字节。
2)轮加常数(AddConstants,AC):状态矩阵异或轮常数。
3)轮加密钥(AddRoundTweakey,ART):轮密钥的第一行、第二行和状态矩阵相应的位置异或。
4)行移位(ShiftRows,SR):简单的位移。矩阵从第0 行到第3行,依次循环移动0、1、2、3个字节。
5)列混淆(MixColumns,MC):状态矩阵与二进制矩阵相乘。
SKINNY 的加密轮函数过程如图1 所示,由48 个轮函数迭代而成,解密过程相似。密钥编排算法可参考文献[11]。

图1 SKINNY算法加密轮函数Fig.1 Encryption round function of SKINNY algorithm
1.2 SKINNY加密模式的选择
分组密码常用的工作模式有5 种[12-14],分别是:电子密码本(ECB)模式、计数器(CTR)模式、密码块链接(CBC)模式和密码反馈(Cipher FeedBack,CFB)模式及输出反馈(Output FeedBack,OFB)模式。
1.2.1 模式比较
表1列出了5种加密模式的并行特性[6]:ECB、CTR模式都支持并行计算,因为它们的每个单个分组都可以独立加密;而其他三种模式不支持,因为它们的分组输入都与前一段的输出有一定关系,具有串行特性。本文SKINNY 算法实现选择的是可以并行实现的ECB 模式和CTR 模式。接下来对ECB和CTR这两种模式进行简单介绍。

表1 加密模式比较[6]Tab.1 Comparison of encryption modes[6]
1.2.2 电子密码本(ECB)模式
在ECB 模式下,数据会被分组独立进行加密。这种加密模式加密方便,应用广泛。此模式的表达式如式(2)所示:

其中:i=1,2,…,n;P表示输入的明文;C表示输出的密文。
1.2.3 计数器(CTR)模式
计数器模式有一个自增的连续值,将这个自增值用密钥进行加密,加密之后的中间值与明文进行异或,得到密文,相当于一次一密。此模式的加密方式快速简单,可靠安全,但它容易遭受攻击者的攻击。此模式的表达式如式(3)所示:

其中:R={0,1,…,2(|P|-1)};i=1,2,…,n。
2 CUDA加速SKINNY
2.1 SKINNY的并行优化
SKINNY 的每一轮的操作如图2 所示,ai,j表示输入明文,TKk,j表示轮密钥。

图2 SKINNY算法的轮变换Fig.2 Round transformation of SKINNY algorithm
为了得到更好的实现性能,本文将5 个步骤进行化简合并成为一个公式,如式(4)所示,然后将其前4 个表分别定义为T表,两组轮密钥矩阵合并定义为TK,轮常数矩阵定义为C。

最终的表达式化简为4 个T表和5 个异或运算,如式(5)所示,这样可以避免大量的逻辑计算。

其中:i,j=0,1,2,3;k=0,1。轮常数C只影响输入矩阵的第一列;轮密钥TK只影响输入矩阵的前两行。
2.2 并行粒度
并行粒度的设计会影响算法的实现效果,所以在设计并行粒度时要遵循两个原则:1)提高分配线程的利用率;2)减少各线程间的通信开销[15]。并行粒度的设计一般分为两种:一种为细粒度,一个GPU 线程处理16 字节分组中的4 字节,如图3所示;另一种称为粗粒度处理,一个线程处理16个字节的分组,如图4 所示。在细粒度实现中,它可以调度更多线程增大吞吐量,但是线程之间的通信开销也随之增大。在粗粒度实现中,单个线程处理一个独立的SKINNY 分组,GPU 上的线程无须同步,并且每个线程都独立运行,从而减少了通信时间。通过实验对比发现,粗粒度的设计方式要优于细粒度。
基于以上分析,将SKINNY 的并行粒度设计为“每个线程一个分组”,也就是说每个线程处理16 字节的数据。数据被分为多个16字节矩阵,这些矩阵由GPU 同步执行。在这种情况下,每个GPU 线程可以独立完成,因为不同线程的矩阵不具有相互依赖性,线程间不用相互等待。

图3 细粒度并行方案Fig.3 Fine-grained parallel scheme

图4 粗粒度并行方案Fig.4 Coarse-grained parallel scheme
2.3 内存分配
CUDA 的内存分配策略非常重要,因为CUDA 具有5种不同的内存[16],每种内存的特性在一定程度上相互不同。内存分配策略的不同会对性能带来明显的影响。
2.3.1 明文内存分配
输入明文被分为几个互相独立的块进行加密。本文使用的是一个线程处理一个分组,例如,当处理1 000个分组,就需要1 000个GPU线程。因为明文数量较大,所以将整体明文存储到全局内存中。每个线程获得16 个字节的数据后,将会暂存在线程的寄存器中,寄存器对于各个线程是私有的,即彼此无法互相访问。所有线程完加密后,再将数据从GPU 内存中取回。
2.3.2T表内存分配
T表本质上是查找表,在线程间是只读数据,用户可以通过它们快速实现部分加密操作。每个线程在每一轮加密操作中都需要随机访问T表。因此,本文需要将T表提前加载到GPU 的内存中。根据这些属性,将T表分配到CUDA 常量内存中。另一种分配方案是将T表分配到共享内存中,但是此种分配方式会存在一些问题,即存储体冲突,如果多个地址请求落在相同的内存存储体时,就会发生存储体冲突,导致请求被重复执行。
2.3.3 轮密钥内存分配
密钥的保密性和密钥的长度是保证密码的安全性的基础。在SKINNY 算法的实现中,每一轮加密都需要密钥异或操作。CUDA 的每个线程都需要输入不同的轮密钥。在这种情况下,本文将轮密钥放入常量存储器中,所有线程在常量内存中共享轮密钥。
2.4 线程数的分配
每个GPU 块中线程数的数量也会影响运行性能。每个块的线程数如何分配,存在一些原则。在分配时一个块的线程数最好是32的倍数,因为连续的线程会以32个为一组组成一个线程束(warp),同一warp 里的线程会对不同的数据执行相同的指令。而如果线程数不是32的倍数,GPU 会将不足32的线程的warp 补全,造成资源的浪费。本文使用的设备的一个块最大线程数为1 024,设置线程数不能超过其最大值,虽然说一个块中的线程越多越能隐藏延迟,但是这样会使每个线程可以使用的资源变少,考虑到所用的其他资源:共享内存、寄存器等,为了达到更好的性能,决定每块分配512 个线程。
综上所述,最终的分配方案如表2 所示。基于GPU 实现的SKINNY 算法加密部分流程如图5 所示,解密部分与加密相似。

图5 SKINNY算法并行流程Fig.5 Parallel flowchart of SKINNY algorithm

表2 GPU变量分配方案Tab.2 GPU variable allocation scheme
3 实验与结果分析
3.1 实验环境
本实验所使用的CPU 为:Inter Xeon E5-2643 v4 @3.40 GHz;GPU:GeForce GTX TITAN X,内存为32 GB,全局内存为12 GB;操作系统为:Ubuntu 18.04.2 LTS,64 bit;编程环境为:CUDA 10.1,GCC 7.5.0。本实验的CPU 代码用的C 语言编写,GPU代码用CUDA C编写。
3.2 实验结果
实验操作是对相同大小的明文分别进行基于CPU 和GPU 的加密运算,明文大小从16 B 开始二倍递增到64 MB,记录运行的时间和吞吐量。为了降低实验误差,每种规格的明文均运行10 次,取平均值。用加速效率和加速比来作为衡量算法性能提升的指标,加速效率表示并行程序的运行效率的提升情况,加速效率S的定义如式(6)所示;加速比表示并行程序对比串行程序的性能提升,加速比E的定义如式(7)所示。

其中:TC表示CPU串行加密时间;TG表示GPU并行加密时间。
3.2.1 SKINNY算法ECB模式的实验结果与分析
SKINNY 算法的ECB 模式在CPU 和GPU 上运行的效果的对比以及吞吐量的变化趋势如表3和图6所示。从表3和图6可以看出:随着输入数据的倍速增长,基于CPU 的SKINNY 算法的运行时间也倍速增长,而基于GPU 的该算法的运行时间却以缓慢的速度增长。随着明文数据增到16 MB 左右,加速比和加速效率达到峰值。并且随着输入数据的增大,基于GPU 的吞吐量增幅明显,而CPU 吞吐量相对稳定,增幅不大。GPU 吞吐量的峰值出现在明文大小在16 MB 左右时,此后吞吐量趋于稳定。对于ECB 模式来说,加速比峰值可达671,加速效率峰值可达99.85%。

图6 SKINNY_ECB加密串行和并行吞吐量对比Fig.6 Throughput of SKINNY_ECB(CPU vs.GPU)

表3 SKINNY_ECB实现性能比较(CPU对比GPU)Tab.3 SKINNY_ECB implementation performance comparison(CPU vs.GPU)
3.2.2 SKINNY算法CTR模式的实验结果与分析
SKINNY 算法的CTR 模式在CPU 和GPU 上运行的效果的对比以及吞吐量的变化趋势如表4和图7所示。

表4 SKINNY_CTR实现性能比较(CPU对比GPU)Tab.4 SKINNY_CTR implementation performance comparison(CPU vs GPU)

图7 SKINNY_CTR加密串行和并行吞吐量对比Fig.7 Throughput of SKINNY_CTR(CPU vs.GPU)
它的增长与变化曲线与ECB 模式类似,但CTR 模式的实现速度要稍快于ECB 模式的实现速度。CTR 和ECB 模式最大的区别在于CTR 有一个16字节的计数器counter,每次加密counter 加1,所以加密速度更快。它的加速比和加速效率峰值也都出现在明文数据输入为16 MB 左右,其中加速比最高可达765,加速效率最高可达99.87%。
3.3 实验讨论
综合两种加密模式的分析,发现当输入明文大小在16 B~64 B 时,加速比要小于1,说明基于CPU 的性能要优于GPU。因为数据量太小,GPU开启的线程数少,无法通过线程级并行来隐藏延迟;也说明一个线程的GPU 并行运算的时间效果远没有单线程CPU 好。但是,当输入明文变大,例如16 MB,基于GPU 的性能要明显优于CPU,当处理大量数据时,GPU 可以通过多个线程之间的乱序执行和多个线程间的灵活切换来隐藏延迟,从而提高吞吐量。
也就是说:当输入明文大小较小(小于64 B)时,基于CPU的性能要好于GPU 性能;但是,当输入明文大小变大(64 B 及以上)时,GPU 的性能要比CPU 好得多,GPU 在性能方面比CPU 优势显著。虽然当可并行化数据的大小越来越大时,GPU 的性能就可以得到充分利用,但GPU 的性能并不能无限得到提升,由于受到GPU 自身硬件条件的限制,它的速度提升也是有边界的,比如当输入明文超过2 MB 时,吞吐量增长趋于平稳,执行时间开始呈线性增长。由图4~5可以得出,并行GPU的吞吐量变化大致分为三个阶段:16 B~128 KB吞吐量为指数增长,128 KB~4 MB 吞吐量为线性增加,4 MB 及以上吞吐量增加趋于稳定。
3.4 实验结果对比
文献[17]报告了ECB 模式下SKINNY 不同版本的在OpenCL 中的并行实现,他们的优化方法是分别对加密算法的分布操作进行优化,但是没有提及线程块的配置、存储方式选择等问题。相较于文献[17]的ECB 模式下的SKINNY-256 并行实现,本文基于GPU 实现并行算法的最高吞吐量是其1.29倍。并且由于AES 是目前主流的密码算法,且AES-256 和SKINNY-256具有相同的明文分组和密钥分组长度,还将本文的实验结果与文献[18]关于ECB模式下的AES-256加速的并行算法进行对比,对比结果表明:本文的结果有2.55 倍的性能提升。具体比较如表5 所示。这说明,本文采用的方法对SKINNY 的ECB 模式在GPU 下能有效地发挥其并行计算能力。本文通过将SKINNY 的5 个加解密步骤进行组合形成1个整体表达式,使得SKINNY 的实现只需要4 个T表查找和5个XOR 运算,减少了代码数量、降低了内存占用面积,提高了并行性;采用粗粒度的并行方式即“每个线程一个分组”用于线程调度,避免了线程间的频繁数据交互;线程块数的设置非定值而是随明文大小和线程数个数变化,其计算公式为:明文总数/每块线程数/分组大小,有助于提高并行性能。同时本文还对CTR 模式在GPU 下的实现方法进行了探究,针对CTR 模式与ECB 模式的不同,将CTR 模式特有的计数器初始值存储到寄存器中,其他操作与ECB 模式基本相似,结果发现CTR模式的并行也可以在GPU上充分发挥其并行计算能力。

表5 不同算法的吞吐量比较Tab.5 Throughput comparison of different algorithms
4 结语
本文基于GPU 下的CUDA 编程模型,利用SKINNY-256算法的结构和特点,提出其ECB 和CTR 模式的并行优化方案。实验结果表明,对于SKINNY 算法的ECB 和CTR 模式,当处理数据在16 MB 及以上时,GPU 加速效率可以达到99.85%和99.87%,加速比分别可达到671 和765。进一步的研究工作可以考虑对其他分组密码算法如国密SM4 进行GPU 下的并行加速。
