基于LightGBM 算法的能见度预测模型
2021-04-20余东昌赵文芳
余东昌,赵文芳*,聂 凯,张 舸
(1.北京城市气象研究院,北京 100089;2.北京市气象信息中心,北京 100089;3.北京市气象探测中心,北京 100176;4.信图智行(北京)科技有限公司,北京 100022)
0 引言
大气能见度是反映大气透明度的一个指标,具体定义为视力正常的人能从背景(天空或地面)中识别出具有一定大小的目标物的最大距离。影响能见度的因子主要有大气透明度、气溶胶的化学成分、气象因子等,当出现降雨、雾、霾、沙尘暴等天气过程时,大气透明度较低,因此能见度较差。能见度高低与人们日常生活息息相关,低能见度容易引发交通事故,带来严重的危害和经济损失。例如,长时间的低能见度天气不仅会造成大范围的航班延误和取消,对航空公司带来巨大损失,还会对公众出行造成影响。近年来,京津冀地区雾霾事件频发,低能见度已经成为衡量雾霾污染程度最重要的指标之一[1-2],能见度的相关研究受到大气、环境领域乃至社会的广泛关注,而能见度的预报也成为霾天气预报以及相关环境气象预报服务的重要基础之一。
目前,能见度的预报方法主要包括数值模式预报和统计预报。数值模式预报主要基于空气动力学理论和物理化学过程,使用各类气象数据和排放源数据,建立环境气象数值模式系统来模拟大气中的污染物、湿度、液态水含量等要素,依据大气光学理论,计算其对大气消光的贡献,诊断预报大气能见度[3-5]。广泛应用的模式包括美国环保署开发的通用多尺度空气质量模型(Community Multi-scale Air Quality model,CMAQ),美国国家大气研究中心、美国国家海洋和大气管理局等多家联合研发的气象-化学在线完全耦合的区域空气质量模式(Weather Research and Forecasting(WRF)model coupled with Chemistry,WRF-Chem)[6],中国气象科学研究院研发的城市空气污染数值预报系统(City Air Pollution Prediction System,CAPPS)[7]和雾霾数值预报模式CAUCE(CMA Unified Atmospheric Chemistry Environment)[8]等。部分省级气象部门也通过引进国外WRF-Chem化学模式进行本地化改来提升区域环境业务水平,例如,华北区域气象中心北基于北京地区快速更新循环同化预报系统、WRF-Chem 模式和优选的能见度参数化方案,建立了华北区域环境气象数值预报系统(Beijing Regional Environmental Meteorology Prediction System,RMAPS-CHEM)[9]。已有研究表明,这些模式的预报能力随能见度降低均逐渐下降,存在对于低能见度模拟偏高的问题,在能见度预报业务中需要预报员进行订正[10-11]。
传统的统计预报法是通过寻找气象要素对能见度的影响关系,构建预报量与预报因子之间的预报模型来实现。这种建模都是事先给定模式的因变量与自变量之间的函数关系,不能较好地描述因变量与自变量之间的联系,也无法预报历史数据中未出现过的天气,存在一定局限性。近年来,随着机器学习的发展,不少学者开始用机器学习算法进行能见度预报的研究,通过选取污染物浓度、温度、湿度、气压、风速、水汽压等影响因子,使用多元线性回归、支持向量机、神经网络等对能见度进行预测[12-17]。然而,除了气象条件,能见度还受到排放量、气溶胶化成分等因素的共同影响,应用单一模型和有限的气象因子建立模型,对预测精度产生了一定影响。
集成学习是目前机器学习领域最热门的研究方向之一,它的基本思想是把多个学习器通过一定方法进行组合,通过优势互补以获得比单一模型更好的拟合表现和更小的误差,从而达到最终效果的提升。目前主流的集成机器学习方法有:Boosting、Bagging 和Stacking。近年来许多机器学习竞赛的冠军均使用了集成学习,一些主流的互联网公司,例如腾讯、阿里巴巴都已经将集成学习用在推荐、搜索排序、用户行为预测、点击率预测、产品分类等业务中,并取得了良好效果。已有文献将集成学习应用在PM2.5预测[18-20]、温度预报订正[21]、O3浓度预测[22]和估算[23]中并达到了更加准确的预报效果,尚没有研究将集成学习应用至能见度预报中。因此,本文选择boosting集成学习方法建立能见度预测模型,有利于降低预报误差。
1 能见度特征分析
1.1 能见度逐年变化趋势
本文利用1980—2020 年北京地区国家级地面气象台站观测的大气水平能见度数据对北京地区大气能见度的逐年变化趋势进行分析,这些数据均经过“台站级—省级—国家级”三级质控。先计算每个站逐年能见度均值,再统计所有站的年平均能见度,结果如图1所示。可以看出,1980—2020年北京地区年均能见度整体呈下降趋势:1980—2006 年能见度呈波动式的变化,整体上呈现缓慢下降趋势;2007—2013 年能见度呈上升趋势;2014 年能见度最低,城区的能见度均值比北京地区年均值低25.14%;2015—2019 年能见度又呈现上升趋势,这从侧面反映了近几年空气污染治理取得了良好效果。余予等[24]分析北京地区能见度变化后指出,海淀和石景山站点观测的能见度整体呈下降趋势,这与本文的研究结果较为接近。

图1 北京地区能见度逐年变化趋势Fig.1 Annual change trend of visibility in Beijing area
1.2 低能见度的季节变化特征
参考雾霾等级标准划将能见度分为四个级别:0~2 km、2~5 km、5~10 km 和10 km 以上,分析1980—2020 年北京地区各个季节(春季3~5 月、夏季6~8 月、秋季9~11 月、冬季12 月至来年2 月)不同等级能见度出现的天数和所占百分比,低能见度<2 km在不同季节出现天数的结果如图2所示。从图2中可以看出,冬季出现能见度<2 km的天数最多,秋季次之,春季和夏季较少;1980—1999 年期间逐年能见度<2 km 出现的天数不超过15 d,2000—2012 年期能见度<2 km 出现的天数最少,2013—2016 年秋冬季节能见度<2 km 出现的天数明显增多,2017—2019 年能见度<2 km 出现的天数明显下降,不超过10 d 能见度在2~5 km 出现的天数随时间的变化特征如下:1980—1999 年呈波浪形变化,变化幅度不大;2000—2012 年呈现明显递减趋势;2013—2016 年又呈现上升趋势,最高达到80 d;2017 年之后下降至30 d 左右。能见度在2~5 km 出现的天数比较平均的分布在夏、秋、冬三个季节,春季最少。

图2 北京地区1980—2019年低能见度季节性的变化趋势Fig.2 Seasonal change trend of low-visibility in Beijing area from 1980 to 2019
1.3 不同季节能见度日内逐小时变化
对所有气象站的能见度观测数据按春、夏、秋、冬季分类,计算各季节0 点到23 点逐小时能见度平均值,结果如图3所示。

图3 北京地区不同季节能见度日内逐小时变化趋势Fig.3 Hour-by-hour change trend in one day of visibility in Beijing are in different seasons
可以看出,春夏秋三季,一日中能见度最低值出现在上午5时至7时,随着气温的升高,相对湿度减小,热力对流趋于旺盛,能见度逐渐转好,平均能见度最高值出现在下午15 时至16 时,到了傍晚随着热力对流条件减弱,相对湿度增加,能见度又持续变差。冬季,一日中能见度从凌晨开始呈现上升再下降趋势,最低值出现在上午8 时,随后又呈现上升趋势,下午15 时至16 时到达最大,到了傍晚能见度随时间推移缓慢下降。
1.4 气象要素与大气污染对能见度的影响
除了气象要素,以PM2.5为代表的颗粒物浓度对能见度也有影响,因此进行能见度与常规气象要素及大气成分观测数据的相关性分析,考虑到北京地区最早开始PM2.5观测是在2002 年,因此选择使用2002—2019 年北京地区能见度、气象要素及大气成分观测数据进行该项数据分析工作。其中,PM2.5浓度数据来自于PM2.5监测仪。该监测仪利用β 射线作为辐射源,采用恒定流量抽气,将PM2.5颗粒吸附在β 源和探测器之间的滤纸表面,然后根据抽气前后探测器对β 射线计数值的改变换算单位体积空气中PM2.5的浓度。
将能见度划分四个等级,计算每个等级下能见度和不同气象要素的平均值,结果如表1 所示。当能见度<2 km 时,平均相对湿度78%,平均PM2.5浓度达到了119 μg/m3;当能见度>10 km 时,平均相对湿度仅有43%,平均PM2.5浓度为28.7 μg/m3;随着能见度从好变差,气压、温度、风这三个气象要素的变化并不显著,相反PM2.5浓度变化最大,相对湿度变化次之。
对能见度的相关性按春夏秋冬四季和年两个尺度进行分析,结果如表2 所示。从中可看出,与能见度相关性较高的要素主要为PM2.5浓度、相对湿度、风向及风速,其中相对湿度、PM2.5浓度与能见度呈负相关关系,风速、风向与能见度呈正相关关系,这与以往研究结果一致[25]。相对湿度在春季与能见度相关性最高,而冬季最低;风速与能见度的相关性在春季表现最弱,夏季最强;风向与能见度相关性在冬季最强,春季最低;SO2浓度是北京地区供暖期间最主要的大气污染物之一,在冬季和夏季与能见度相关性较高;PM2.5浓度与能见度在四季都保持着较高的相关性;由此可见,不同气象要素对北京地区能见度的影响存在明显的季节性差异。

表1 2009—2019年能见度及气象要素的年平均值Tab.1 Annual mean values of visibility and meteorological factors from 2009 to 2019

表2 2009—2019年北京地区季、年平均能见度与各类要素间的相关系数Tab.2 Correlation coefficients between seasonal/annual average visibility with meteorological factors from 2009 to 2019
2 本文方法和模型
本文采用随机森林方法选择特征向量,使用LightGBM 建立能见度预测模型的方法。使用基于北京市空气质量历史数据集、气象和天气预报数据集构建的训练数据集开展模型训练。以过去24 h 的气象数据、能见度数据、PM2.5浓度测数据、当前时刻的气象要素实况数据和气象要素物理量数据等作为模型的输入,通过优化参数得到最佳模型并进行预测。
2.1 梯度提升决策树算法及LightGBM原理
梯度提决策升树(Gradient Boosting Decision Tree,GBDT)是一种基于迭代所构造的决策树算法,既可以做回归也可以做分类,它以分类回归树(Classification And Regression Trees,CART)模型作为弱学习器,将新学习器建立在之前学习器损失函数梯度下降的方向,通过不断迭代来训练模型。迭代过程中,每一轮预测值和实际值有残差,下一轮根据残差再进行预测,最后将所有预测相加作为最终结论。因此,GBDT 可以表示为决策树的加法模型,如式(1)所示:

其中:T(x;θm)表示决策树;θm为决策树参数;M为树的个数。根据向前分步算法,第m步的模型可以表示为式(2):
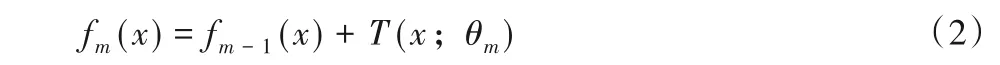
设定yi为第i个样本的真实值,fm(xi)为第i个样本的预测值,取损失函数为平方损失,那么损失函数可以表示为式(3):

根据式(4)极小化损失函数得到参数θm:

通过多次迭代,更新回归树可以得到最终模型。
LightGBM 是微软基于GBDT 框架提出的改进模型,使用基于直方图的分割算法取代了传统的预排序遍历算法,不仅在训练速度和空间效率上均优于GBDT,还能有效防止过拟合,更加适用于训练海量高维数据。
2.2 数据来源及预处理
本文实验数据来源于北京地区2015—2018 年逐小时的气象观测数据、空气质量观测数据以及气象要素格点预报数据。气象观测数据和空气质量观测数据来自于北京市气象局国家级地面观测站,包括逐小时气压、气温、相对湿度、降水量、风向、风速、PM2.5浓度、SO2浓度;气象要素格点预报数据来源于北京市气象局数值模式系统,主要包括不同高度层(1 000,975,925,850,700,500 hPa)的温度预报、相对湿度预报、风速风向预报等。气象要素格点预报数据完整性较好,观测数据大约有5.7%的缺失。
对于缺失的观测数据,进行缺失时长统计。缺失时长是指以小时为单位,将从最近一次观测到有效值,到当前时刻所经过的时间跨度。所有缺失数据里,87.6%数据缺失时长时长为不超过2 h,10.4%数据缺失时长为3~12 h,1.72%数据缺失时长为12~2 h,0.28%数据缺失时长为24 h 以上。考虑到不同季节中的小时平均能见度浓度变化存在较大差异,本文根据缺失时长设计了三种不同的缺失值处理方法。对于缺失时长≤2 h的,用上一时次和下一时次观测数据的平均值替代;对于2 h<缺失时长≤12 h 的,用最近的有效数据替代缺失值;对于12 h<缺失时长≤24 h 的,用过去24 h 的平均值替代;缺失时长超过24 h 的,用相同时间段的所有站的能见度均值和最近有效值作加权和替代缺失值。最近有效值和均值的结合,既考虑了长期稳定值又考虑了能见度突变状况,比单一用均值替代更接近能见度实际变化情况。
2.3 特征向量选择
数值模式系统中输出的气象要素格点预报多达几十种,若所有格点预报全部输入能见度预测模型进行训练,会使模型结构过于复杂,并产生过拟合现象,甚至导致模型泛化能力不足,因此,需要进行筛选。
随机森林是一种分类和回归技术,实现简单,计算开销小,不仅适用于非线性数据建模,还适用于对变量进行重要性分析,已有很多学者将随机森林方法用于特征选择,在卫星遥感数据反演、空气质量预测、林地动态预测、生态学预测等应用中取得了良好效果。本文采用随机森林法,从观测数据和气象要素格点预报数据中,选取对北京地区能见度有重要影响的观测要素或预报要素作为特征向量。图4 显示了不同气象要素及其重要性系数分布情况,排在前5 的分别是PM2.5浓度、相对湿度、海平面气压、850 hPa 和500 hPa 两个高度层的温度预报,按照重要性系数从高到低选取12 个气象要素作为能见度预测模型的特征向量。

图4 不同特征向量的重要性系数Fig.4 Importance coefficient of different feature vectors
2.4 逐小时能见度预测模型
能见度预报是一个典型的时序预测问题,不仅相邻时刻之间的能见度数值具有较强的相关性,而且各气象要素前几个时刻的变化速率和幅度也对当前时刻的能见度有重要影响,因此,选择当前小时气象观测数据和PM2.5浓度数据、过去24 h 能见度、过去24 h 的观测数据、当前小时气象要素格点预报数据作为模型的输入量,将下1 h能见度预测数据作为模型的输出量,进行模型训练。
对于观测数据,根据缺失时长选择不同的处理方法进行缺失值替换;对于预报数据,根据观测站点的经纬度信息,通过双线性插值法将气象要素格点预报数据插值到观测站点,即可得到观测站点的气象要素预报数据,从而生成关于观测站点的逐小时原始数据集,然后使用随机森林算法进行特征提取形成特征向量集合。根据模型对输入量要求,对向量集合进行转换,形成每个站点都包含当前小时和过去24 h 特征量的样本集合。基于样本集合应用LightGBM 建立预测模型,利用网络搜索法优化模型参数,对未来1 h能见度进行预报。
3 实验与结果分析
3.1 实验环境及数据
数据预处理后获得114 104个逐小时的连续样本,时间跨度为2015 年12 月—2018 年12 月,每个样本包含41 个特征向量。训练集的时间跨度为2016年1月—2018年12月;2015年12 月京津冀地区经历了多次重雾霾污染过程,低能见度天气现象发生频繁,因此选择测试集的时间为2015年12月。
使用python 和机器学习库scikit-learn 完成数据的预处理和基于LightGBM 的能见度预测模型建立。为了进一步将该模型与其他模型相比,还实现了多元线性回归(Multiple Linear Regression,MLR)、结合粒子群优化算法的支持向量机(Support Vector Machine,SVM)、人工神经网络(Artificial Neural Network,ANN)的建模,其中ANN 模型使用反向传播算法进行训练。
3.2 模型评估方法
为了评估模型的性能,将能见度按四个等级分别使用均方根误差(Root Mean Square Error,RMSE)、平均绝对误差(Mean Absolute Error,MAE)、相关系数(Relative coefficient,R)、预兆得分(Threat Score,TS)、漏报率和空报率作为评价指标。RMSE 和MAE 用于评估绝对误差,可以反映预测的极值效应和误差范围值,TS 评分是气象预报业务上常用的检验指标,用来全面评估预报准确性。TS评分公式为:

其中:NA为预报正确的站(次)数;NB为空报站(次)数;NC为漏报站(次)数。当预报等级与实况等级相同,则判定为预报正确;预报在某等级内而实况未出现在该等级内,则为空报;预报不在某等级内,而实况出现在该等级内,则为漏报。
3.3 模型参数调优
对于基于LightGBM 的能见度预测模型,本文采用Scikitlearn 提供的GridSearch(格网搜索)法进行4个主要参数调优:学习率、迭代次数、叶节点数以及树的深度。在训练数据集上,进行多次迭代,采用5 折交叉验证的方法来确定训练阶段的最佳参数来用于预测。该模型参数最终确定为:学习率learning_rate=0.1,迭代次数n_estimators=100,叶节点num_leaves=64,树的深度max_depth=8。
对于实验中其他模型,例如多元线性回归、支持向量机、神经网络等,则根据不同模型的算法特性和调数参经验进行参数的初始值设置,再采用GridSearch 进行参数优化。SVM构建模型时,核函数选“rbf”,初始化参数C为100,gamma参数为10,经过粒子群优化后最终参数确定为,kernel=′rbf′,C=23.250 4,gamma=14.298 0。ANN 模型设置隐含层为3层,每层10 个神经元,激活函数选“tanh”,学习率learning_rate=0.05,批量样本batch_size=64。MLR 模型参数设置为:fit_intercept=True,normalize=False,copy_X=True,n_jobs=None。
3.3.1 能见度分级检验
在能见度预报业务中,经常使用分级检验方法来评估不同数值模式预报系统的预报效果,预报员尤其关注低能见度的预报准确率,数值模式研究人员也尝试多种方法来提高低能见度的预报准确率。因此,本文也对能见度进行分级检验,按照4 个等级,分别计算各模型在不同等级上的TS 得分,其结果如图5 所示。由图5 可见,对于<2 km 的能见度,LightGBM TS 最高,预报效果最好,可达0.89,而SVM 模型TS最低,为0.65,ANN 和MLR 模型TS 比LightGBM 略低;对于2~5 km 能见度,LightGBM 和MLR 模型表现相不差上下;对于5~10 km 能见度,ANN 模型能见度的预报效果最好,LightGBM和MLR 模型的TS 均略低;对于当能见度≥10 km 时,各模型的预报均比较好,TS差别较小。LightGBM 在不同等级能见度上的TS 分别为0.89、0.51、0.41、0.58,低能见度预报效果最好。

图5 几个模型的TS得分Fig.5 TS scores of different models
3.3.2 几种模型预报效果比较
北京城区人口密集,是人们生活、生产、交通相对集中的地区,也是低能见度的高发地;郊区人口密度相对稀疏,地势开阔,因而发生低能见度的概率较少。因此,根据站点周边环境以及气候北京,从城区选择3 个代表性的观测站点,郊区选择1 个代表性的站点进行误差和预测结果的分析。对这4 个站点2015 年12 月24 日—31 日逐小时(共192 个时次)能见度进行预测,并分析平均绝对误差(Mean Absolute Error,MAE)、均方根误差(Root Mean Squared Error,RMSE)、R 等模型评价指标。几个模型的总体误差及在各站点的误差如表3 所示。四个模型中,LightGBM 的RMSE 最小,R 相关系数最高,RMSE的值越小,说明预测模型具有更好的精确度,站点3 在海拔较高的地区,偏北风发生概率较高而且风速大,因此低能见度发生概率偏小,而LightGBM 对低能见度预报TS 评分比高能见度要高,因此对站点3 的预报误差比其他三个站点误差略高;ANN 模型在四个站点上的预测效果差异不大,总体情况与MLR 模型类似,不过MLR 模型在站点1 和站点3 上的MAE 偏差最大,说明MLR 模型对能见度峰值的预测与实况偏差较大;SVM模型的预测效果是四个模型中最差的,相关系数低于其他几个模型。

表3 各模型在不同站点的误差比较Tab.3 Error comparison of different models over different stations
四个站点中,所有模型均在站点2 上有最佳预测效果,因此给出四种模型对该站的逐小时能见度预测曲线随时间的变化趋势,如图6所示,其中obs_value是能见度观测值。可以看出,对于192 个时次的能见度预报,各模型的表现差异比较明显。LightGBM 的预测曲线与观测曲线最为接近,尤其是在低能见度时的拟合非常好,表明该模型能较准确地对低能见度进行预测,随着预报时效的增加,该模型的预测效果并没有明显下降;ANN 模型对低能见度的预测比实况偏高,对能见度>10 km的预报比实况明显偏低,而且随着预报时间的推移偏差逐渐增大;MLR 模型对低能见度的预报比实况也偏高,在能见度>5 km时与实况的变化趋势保持一致,对能见度峰值的拟合较好;SVM模型的预测效果表现最差,预测值明显高于观测值。相比之下,LightGBM 整体预测效果最好。几个模型在其他站点的预测表现与观象台站相类似。

图6 不同模型对站点1的预报效果对比Fig.6 Comparison of forecast results of different models over station 1
4 结语
本文在分析北京地区不同等级能见度浓度随季节变化规律、逐日变化趋势的基础上,利用随机森林方法对气象要素、大气污染物浓度和能见度进行分析,选择了关联度最大的12个指标作为预测能见度的主要因素,并提出了一种使用集成学习LightGBM 预测能见度的方法。此外,针对数据缺测情况,设计了三种不同处理方法来替换缺失值,生成了2016—2018 年近三年逐小时的连续样本数据集。通过几个模型预测结果和误差的对比表明,LightGBM 预测效果良好,尤其是对低能见度的预测,与实况拟合非常接近。
PM2.5浓度与能见度相关性比较大,在本文实验中将它加入特征向量,取得了较好的预测效果。但是北京地区同时进行大气污染物和气象要素观测的站点不多,在后续的研究中,需要考虑使用PM2.5实况格点数据对站点进行插值,在模型中接入更多的站点数据,进一步提高模型的效率和精度。
