国家食品安全标准图谱的构建及关联性分析
2021-04-20郝志刚李国亮
秦 丽,郝志刚,李国亮*
(1.华中农业大学信息学院,武汉 430070;2.湖北省农业大数据工程技术研究中心(华中农业大学),武汉 430070)
0 引言
食品标准的重要性不言而喻。在众多的食品标准中,最重要的当属食品安全标准,它是唯一强制执行的食品标准。食品安全标准分为国家标准和地方标准两大类,其中食品安全国家标准又包括通用标准、产品标准、生产经营规范、检验方法与规程四种,主要涵盖了8 个方面的内容:食品、食品添加剂、食品相关产品中的致病性微生物、农药残留、兽药残留、生物毒素、重金属等污染物质以及其他危害人体健康物质的限量规定。从农田到餐桌,食品安全标准既是食品生产经营者必须遵循的最低要求,也是食品能够合法生产、消费的通行证,更是政府监管部门执法时的依据准则。但食品安全标准内容庞杂,数量繁多,覆盖内容广泛,并且相互引用形式多样,普通人难以理清其中的关系,阅读起来非常困难。虽然国家对于食品安全问题的研究也从未间断过,但是对于食品安全标准的系统性分析和结构研究却几乎没有。本文针对食品安全标准的内容与彼此之间的引用关系,借助知识图谱技术进行内容抽取与相关性分析,实现食品安全标准的图谱化,并在此基础之上构建一个问答系统,完成基于自然语言的食品安全标准的知识检索与推理。
1 相关工作
自从Google 在2012 年提出知识图谱(Knowledge Graph,KG)这一新的技术以来,知识图谱以及相关技术的研究取得了长足的发展。在统计学、计量学、信息科学等方面知识图谱这一技术有着广泛的应用。知识图谱本质上是一种称为语义网络的知识库[1],旨在描述客观世界的概念、实体、事件及其间的关系[2]。
目前,对于知识图谱的研究和应用多为知识图谱的构建和存储。国内现有的知识图谱资源有Zhishi.me[3]等,国外资源有DBpedia[4-5]、Yago[6-7]、Wikidata[8]等;国内的图数据库有北京大学的gStore[9],国外的有neo4j[10]、jena[11]、GraphDB(Simple graph API for SQL Server)等。而知识图谱的应用则相当广泛,但是为食品安全国家标准建立知识图谱的研究却少有涉及,其中的主要原因是食品安全标准数量繁多,既有国家标准,又有地方标准,还有行业标准,且标准间的形式与定义规则皆不统一,特别是不同部门对基础食品的分类与名称定义也有较大的出入,这对采用自动化技术进行概念与关系识别带来很大困难。目前,学术上无论是食品领域还是农业领域都没有可以参考的专业词库,少量的农业与食品方面的词汇库也都是从公共网络上采集的,实体名与关系名称既不准确也不完备,且存在相互不一致的地方很多,让人无法处理,这也给需要大量准确训练数据的自动化知识抽取技术带来很大困难,所以目前的研究需要更多地从专业文档入手,梳理标准文档之间的关系,建立统一的食品分类方式或者编码方式以及适用于食品安全领域的专业本体,从而达到使用更先进的自动化技术来进一步完善相关知识图谱的目的。但在本体完善之前,还需要使用一些传统的方法来追求概念与关系抽取的准确性与专业性。本文主要研究如何将知识图谱技术应用到食品安全国家标准的内容抽取与关系挖掘上。本文收集了截至2019 年8 月的1 263 项食品安全国家标准,并对这些标准按照文本结构与语法特点进行分类,针对每类标准制定不同抽取策略与算法,以实现它们的知识图谱化。
2 食品安全标准知识图谱构建
本文对食品安全国家标准进行知识与关系抽取,主要包括食品标准之间的引用关系与食品安全标准中的食品安全规定与限定内容。在抽取知识时,主要采用基于句法分析与关键字匹配的方法进行,因为食品安全标准文件种类繁多,且各个部门对食品安全相关概念及食品名称没有统一的描述与分类,尤其农业部门、食品生产与检验部门在食品分类与名称上的描述差异比较明显,所以到现在为止也没有食品相关的专业词库与本体可以使用,这使得在使用一些被广泛研究的新文本分析技术时,会因为缺乏准确而统一的训练集而失去准确性与专业性要求,这对于食品安全领域来说,是十分重要的,所以在针对食品安全标准进行知识提取时,还是采取了抽取结果比较准确的传统方法来实现,而一些文献中所提出的基于机器学习和深度学习[12-14]的方法经过实验,在知识抽取上还有较大的不足,所以没有采用,本文关于食品安全国家标准的知识抽取与关系挖掘过程如图1所示。

图1 知识图谱构建流程Fig.1 Knowledge graph construction process
2.1 数据采集
从网上收集的1 263项食品安全国家标准,经过整理与筛选后,去除一部分加密文档以及一些图片形式的文档,得到1 142 个食品安全标准文本文件作为实验初始数据集。这些食品安全国家标准分为通用限量标准、检验标准、生产经营规范标准与食品产品标准,针对不同的标准类型采用不同策略进行三元组提取。
2.2 三元组抽取
三元组(s,p,o)表示的是一个事实陈述句,其中,s是主语,p是谓语,o是宾语。(s,p,o)表示s 与o之间具有联系p,或者s具有属性p且取值为o。对于这样一句陈述“小明获得了学位证书”,可以用〈小明〉〈获得〉〈学位证书〉来进行表示。在工作中,将抽取三类三元组:引用关系三元组、标准规定内容三元组、其他内容三元组等。
2.2.1 引用关系三元组抽取
引用关系在食品产品标准和通用限量标准、食品产品标准和生产经营规范标准之间较为常见,所以主要对这些标准进行引用三元组的提取。提取方式是常见的基于规则与正则表达式的匹配。引用关系三元组中的两个实体皆是食品安全国家标准的名称,其形式多为“GB”“SN”以及数字组合而成,采用正则表达式可以较为准确地得到食品标准名称。实体之间的关系则是这两个标准之间的参考项目名称。比如,食品产品标准与通用限量标准之间的参考项目多为“污染物限量”“真菌毒素限量”“食品添加剂”“农药残留量”等,可以将这些常见的参考项目构建成一个关键词库。三元组的抽取依据是判断两个实体之间是否有对应的关键词,如果有,则将其抽取成三元组进行输出。如:在对标准文档中的各级标题进行提取后得到文本“GB 2713—2015 食品安全国家标准淀粉制品1 范围……3.3 污染物限量污染物限量应符合GB 2762 的规定。3.4 微生物限量3.4.1 即食淀粉制品的致病菌限量应符合GB 29921 中粮食制品类的规定……”,从这段文本中提取出的三元组为:〈GB2713—2015〉〈污染物限量〉〈GB2762〉,〈GB2713—2015〉〈微生物限量〉〈GB29921〉。
2.2.2 标准规定内容三元组抽取
食品安全标准中的通用限量标准规定了各类食品在食品添加剂、农药残留等方面的具体限值,因此本文主要对这一部分限值及内容进行三元组抽取。由于这部分标准的内容多以表格的形式展示,而目前对于PDF表格的处理并不十分理想,故这部分三元组数据的提取主要依靠自动化表格字符提取技术加上人工校验的方式进行。其中,将食品类型作为三元组的头实体,把检测项目名称作为实体关系,而检测项目的限值作为三元组的尾实体。
2.2.3 其他三元组抽取
除了上面所提到的三元组,本文还对食品安全标准文件名称进行了三元组提取。如《GB2713—2015 食品安全国家标准淀粉制品》,利用正则表达式将“GB2713—2015”和“淀粉食品”提取出来作为三元组的头实体和尾实体,实体间关系为“标准内容”。
2.3 三元组质量评估
为了保证所抽取的三元组数据的准确性,本文对抽取的实体与关系进行质量评估,评价方法为将一部分自动抽取的三元组与通过人工阅读所抽取的数据进行比较,查看自动抽取三元组的准确率。其中,70 个“食品产品标准”经过人工抽取后有235 条三元组,而自动抽取三元组为194 条,三元组的缺失率为17.4%,正确率为100%,这表明这种基于规则的三元组抽取有着极高的准确率,但是由于提取规则数量不足以及提取规则内容不完善导致所提取的三元组数量有限,这只能通过不断完善提取规则来提升三元组提取数量与质量。另外对1 142 个国家食品安全标准文件名进行三元组提取与人工读取的三元组数目一致,准确率为100%,这表明目前的抽取方法对于特征明确的三元组抽取在数量上与质量上都有保证。
2.4 基于HACCP标准的食品生产过程本体
危害分析关键控制点(Hazard Analysis Critical Control Point,HACCP)[15]作为食品生产过程的重要参考依据,与食品安全标准紧密相连。因此,对HACCP 中的概念及其关系进行本体构建[16]可以将食品安全标准与生产过程进行关联,可用于项目后期的知识推理,其建立方法与流程在本项目之前的研究文献[17]中已经讨论。HACCP 中最为重要的类是“关键控制点”和“危害分析”,其中危害分析包括“化学危害”“物理危害”和“生物危害”,这些内容与食品安全标准的联系较为紧密,基于HACCP 的食品生产过程本体也主要围绕这些内容进行构建。本体结构如图2所示。
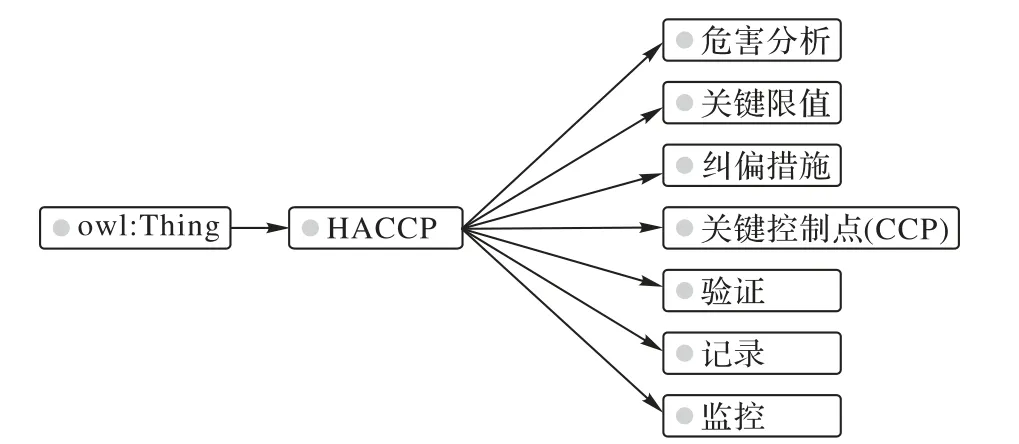
图2 基于HACCP的食品生产过程本体Fig.2 Food production process ontology based on HACCP
在构建图2 本体的过程中,需要对HACCP 规范文档以及国家食品安全标准文档中的术语、概念与关系进行抽取,特别是对国家食品安全标准文档中的各种检验项目名称、食品分类以及各种检测项限量进行三元组抽取。由于文档中存在大量的不规则表格,本文融合了多种抽取方式,包括基于标题格式的实体抽取、基于句法分析与关键词匹配的关系抽取;此外为了保证本体的准确性,还结合了部分的人工抽取。目前本文实验系统已完成对HACCP 规范文档以及部分涉及危害分析的国家食品安全标准文档的抽取工作,其中国家食品安全标准文档主要涉及《GB2761 食品安全国家标准食品中真菌毒素限量》《GB2762 食品安全国家标准食品中污染物限量》《GB2763 食品安全国家标准食品中农药最大残留限量》和《GB2760 食品安全国家标准食品添加剂使用标准》。根据前面的工作,已完成的本体有2 400 多个实体,6 大类不同的关系,这还有待进一步完善。
2.5 实体对齐
在实体抽取过程中,来自来不同文件的实体会有表达形式不一致的问题。如“山梨酸钾”与“山梨酸及其钾盐”意思相近,但表达形式不完全一致,这时需要进行实体对齐。进行大规模实体对齐的常用方法有词向量分析法[18]和embedding[19]等方法。本文尝试将食品安全标准文档转换后的文本数据作为Word2Vec的训练集来实现实体的词向量化,但由于转换后的训练集不够,所以得到的结果不理想。embedding方法则需要较多的实体以及属性来进行训练,由于目前尚无合适的训练集可以使用,且本文所涉及的“食品添加剂”类实体的属性单一,因此也无法完成训练工作。基于上述的尝试效果皆不理想,所以目前本文通过人工建立同义词库的方式解决这个问题,但未来随着本体中的实体数量的增加,应该可以通过现有实体的训练完成新实体的对齐。
2.6 数据存储
知识图谱的存储工具多为图数据库,本文使用gStore 存储三元组数据。gStore 是北京大学研发的面向资源描述框架(Resource Description Framework,RDF)知识图谱的开源图数据库系统,支持SPARQL(SPARQL Protocol and RDF Query Language)1.1 标准,单机可以支持5 Blilion 三元组规模的数据管理任务,支持有效的“增删改查”操作。现将已抽取出的所有三元组以nt格式保存,使用gStore系统中的gbuild命令建立知识库,命令格式如下:bin/gbuild+知识库名称+数据文件路径。知识库构建完成后,可以通过命令终端或者利用应用程序接口(Application Programming Interface,API)编写相应程序来访问管理知识库,整个管理流程如图3所示。

图3 gStore数据管理Fig.3 gStore data management
利用SPARQL 语言[20-22]对食品安全标准GB2760 的被引关系进行查询得到如表1所示数据。

表1 三元组数据表(部分)Tab.1 Triplet data table(part)
表1 中:Subject 是三元组的主语,Object 是宾语,Predicate是它们之间的关系。如第1条数据表示的含义是:GB10136—2015在食品添加剂方面引用了GB2760。
3 食品安全标准社区发现
本文将所有食品安全国家标准的引用数据进行数字编码,使用Louvain 算法[23]进行社区划分,然后结合节点入度与出度的统计,试图找出这些食品安全标准间引用关系的中心点。
3.1 Louvain社区划分算法
3.1.1 算法原理
Louvain 算法将所有初始节点独立为一个社区,连边权重为0,接下来的工作分为两个步骤:1)扫描所有节点,针对每个节点遍历该节点的所有邻居节点,计算将其加入的邻居节点所在社区后的模块度增益值,选择其中最大值所对应的邻居节点,将该节点加入到相应社区中,迭代这一过程直到每个节点的归属不再发生变化;2)将每个社区当作一个节点,并计算新社区之间的连边权重,以及社区内所有节点之间的连边权重之和,完成后重新回到1)。
3.1.2 相对增益
在第一个步骤中要判断一个节点所加入的社区需要根据相对增益ΔQ值,当节点与某一个社区之间的ΔQ为最大时,该节点加入到相应的社区中。ΔQ的计算公式如式(1)所示:

其中:ki,in代表由节点i连接社区C中所有边权重之和;代表所有节点连接社区C的总权重(包括社区C内边的总权重);ki代表连接节点i的所有边的总权重;m是所有边的权值之和。
3.1.3 模块度
迭代结束的条件取决于模块度Q,其计算公式为:

其中:Aij代表节点i和节点j之间边的权重;ki是所有与节点i相连的边的权重之和;ci是节点i的社区编号;δ(ci,cj)函数表示若节点i和j在同一个社区内则返回值为1,否则返回0。在一轮迭代后若Q没有变化,则停止迭代。
3.1.4 算法实现


3.2 社区划分结果
在对边的权重进行赋值时,不同的节点关系所获得的权重不同。设食品产品类标准与通用限量标准之间的边权值为3,食品产品类标准与检测类标准之间的边权值为2,其余的边权值为1。这样设的含义是权值越高的边代表的关系在进行抽取时人工参与的程度越高,可信度也越高,在进行社区划分时占据的比重也更大。经过对1 142 个文档中的三元组进行读取(去除了少量不完整的内容),得到引用关系图如图4所示,共有1 105 个节点和2 593 条边,划分后共得到66 个社区。其中,同一社区的节点被标记为同一种颜色(若社区内节点数目占比太小,该社区内节点全部设为灰色),并且依据连接该节点的其他节点数目,调整节点标签的显示大小。连接数目较大的节点,其显示的标签则越大;反之,则越小。

图4 国家食品安全标准引用关系图Fig.4 Reference relationship diagram of national food safety standards
通过对这一食品标准引用关系图谱(图4)的观察发现,GB5009.12、GB/T14454、GB2763、GB/T11540 等这些食品安全国家标准的节点显示较为清晰,其中GB5009这类标准属于理化检验方法标准,规定了检测食品中化学物质的检测方法和达标量;GB/T14454、GB/T11540 这类标准规定了香料的测定方法;GB2763 属于通用限量标准,规定了食品中的农药最大残留限量。这些信息表明,在所有食品安全标准中,被引用次数较多的标准多为各种检测标准以及规定了食品常见不合格项目的通用限量标准。同时,这些标准之间又存在着相互引用关系,是所有标准中影响力较大的食品安全标准。
4 问答系统
为了方便利用知识图谱进行检索与推理,本文在此基础上构建了基于自然语言的问答系统。问答系统可以根据用户提供的食品类别、食品添加剂名称以及使用者类别(检测机构、食品生产企业以及消费者)检索食品安全国家标准的内容及其引用关系。针对不同的关键词,系统可根据预先设定好的推理机制,完成图谱内的推理,并将结果以图表的形式展示在网页上。问答系统结构如图5所示。
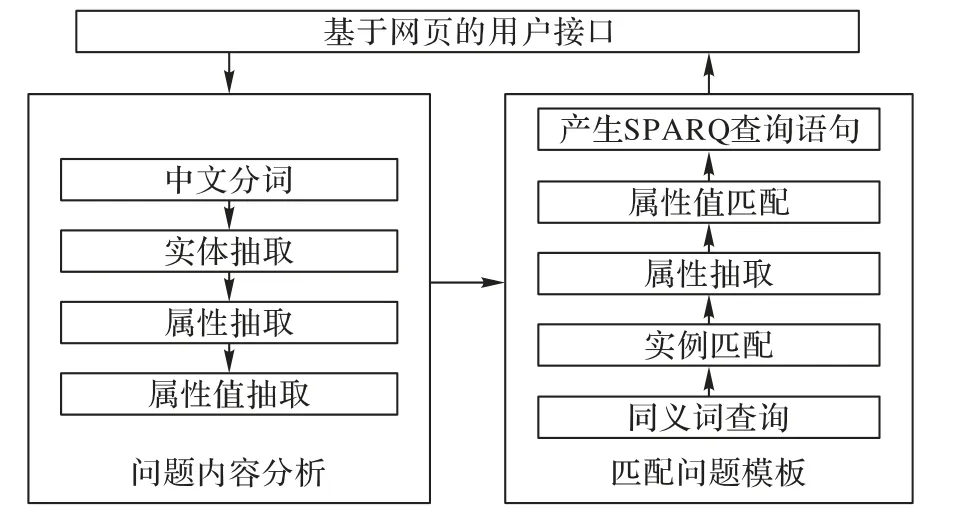
图5 问答系统处理流程Fig.5 Processing flowchart of question answering system
4.1 基于自然语言的检索
4.1.1 食品类型
在检索栏输入“食品分类:食品类型”,如“膨化食品”“面筋制品”“淀粉制品”。此类检索主要涉及食品产品标准以及通用限量标准。如对“膨化食品”进行检索,返回结果如图6所示。其中第1排的“DB17401-2014”为“膨化食品”的食品安全标准,而其后内容则是此标准引用的食品安全标准,具体内容包括“DB17401-2014”所引的参考项目、标准名称与参考项目的限量值,相应的知识图谱如图7所示。
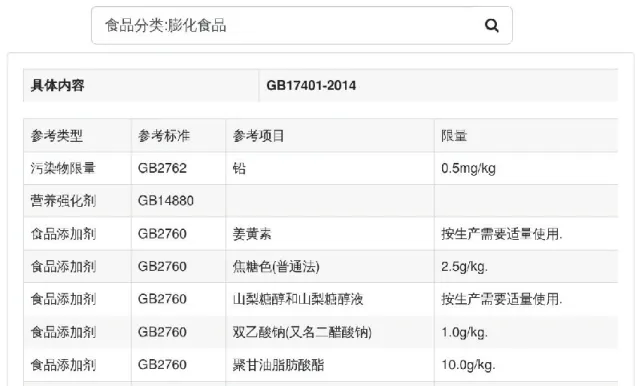
图6 “膨化食品”查询结果(部分)Fig.6 “Puffed food”query results(part)

图7 “膨化食品”知识图谱Fig.7 “Puffed food”knowledge graph
结合图表数据来看,“膨化食品”在生产过程中主要是使用多种添加剂,针对不同的添加剂,食品安全标准GB2760 对其限量都有相应的规定,而食品安全标准GB17401—2014 的主要内容就是有关“膨化食品”的所有规定,GB17401—2014除了参考食品安全标准GB2760 外,还参考了GB14880 以及GB2762,因此,对于“膨化食品”来说,与之相关的较为重要的食品安全标准包括GB17401—2014、GB2760、GB2762 和GB14880。
4.1.2 添加剂类型
以常见的添加剂“氢氧化钙”为例进行检索。此类查询涉及食品产品标准、食品添加剂相关标准、检测标准以及基于HACCP的食品生产过程本体。结果如图8所示。首先给出了“氢氧化钙”所属的添加剂类型-“酸度调节剂”,然后还给出了会使用“氢氧化钙”作为添加剂的食品名称及其所对应的食品安全标准,生成的相应知识图谱如图9 所示。结合图表数据,“氢氧化钙”作为食品添加剂在食品生产过程中主要用于酸度调节,与之相关的重要食品安全标准有GB25191—2010、GB25572—2010等。

图8 “氢氧化钙”查询结果Fig.8 “Calcium hydroxide”query results

图9 “氢氧化钙”知识图谱Fig.9 “Calcium Hydroxide”knowledge graph
4.1.3 用户类型
以“食品生产企业”作为用户类型进行检索,这里主要涉及食品经营规范标准。系统首先会检索所有生产经营规范标准,如GB31646—2018 是速冻食品生产和经营卫生规范,GB20799—2016 是肉和肉制品经营卫生规范等。选择“GB20799—2016”继续查询,结果如图10所示。

图10 “GB20799—2016”查询结果Fig.10 “GB20799-2016”query results
图10给出了“GB20799—2016”参考的项目名称以及所对应的参考标准名称,相应的知识图谱如图11所示。

图11 “GB20799—2016”知识图谱Fig.11 “GB20799-2016”knowledge graph
结合图表数据,食品生产企业的食品经营规范主要参考食品安全标准GB14881—2013,其内容主要包括食品生产企业在生产过程中的各项规定,包括管理制度和人员、卫生管理等,因此,对于食品生产企业的生产经营规范来说,GB20799—2016是其重要的食品安全标准。
4.2 推理方法
本文的推理方法主要采用基于规则方法实现,即通过不同的需求设计相应的检索模板,检索模板包括需要的条件、检索的方式与结果的反馈方式。在获得用户需要后,将检索模板所需要条件通过“:”的方式放入本次检索中,由系统识别,并分别读取,针对多跳检索,会将上次的检索的结果与本次检索的结果进行自动匹配。如搜索“膨化食品”的相关信息时,会将“食品分类”作为检索类型,获取食品分类检索模板,并将其后的内容作为检索关键字。如果有多个条件,多个条件通过“:”进行拆解,并利用食品分类检索模板生成SPARQL 检索语句。如对于“膨化食品”的检索,系统根据“食品分类”检索模板生成的SPARQL语句是通过下面的步骤实现的。
1)对关键字内容进行分割,得到part1“食品分类”与part2“膨化食品”。
2)对part1进行判断,选择相应的推理模板,并将part2作为参数进行传递。
3)SPARQL 根据推理模板生成搜索语句:如对SELECT*WHERE{?s?p?o.?s <食品分类>obj.}中的obj进行替换,将得到最终的查询语句:
SELECT*WHERE
{?s?p?o.?s <食品分类><膨化食品>.}
该SPARQL 语句限制了?s 的属性为“食品分类”,相应的属性值为“膨化食品”,同时又查询与?s 相关的其他三元组作为结果返回。
基于“添加剂类型”与“用户类型”的检索模板,是通过下面的步骤实现的。
对于“氢氧化钙”的检索,系统会检查该关键词的分类,将“添加剂分类:氢氧化钙”作为本次检索的类型,找出所有涉及“氢氧化钙”这一实体的相关三元组数据,其SPARQL 生成的步骤如下:
1)对关键字内容进行分割,得到part1“添加剂分类”与part2“氢氧化钙”。
2)对part1进行判断,选择相应的推理模板,并将part2作为参数进行传递。
3)SPARQL 根据推理模板生成搜索语句:如对SELECT*WHERE{?s?p?o.?x?p2?s.?s <添加剂分类>obj.}中的obj进行替换,将得到最终的查询语句:
SELECT*WHERE
{?s?p?o.?x?p2?s.?s <添加剂分类><氢氧化钙>.}
该SPARQL 语句限制了?s 的属性为“添加剂分类”,相应的属性值为“氢氧化钙”,同时又查询与?s相关的其他三元组,其中?s作为头实体或尾实体。
而对于“食品生产企业”的检索,系统会检查该关键词的分类,将“用户分类:食品生产企业”作为本次检索的类型,找出所有的生产经营规范标准返回给用户,当用户从这些标准中选取“GB20799—2016”时,系统会将该标准的相关信息与“用户分类:食品生产企业”合并成新的检索“用户分类:食品生产企业:肉和肉制品经营卫生规范:GB20799—2016”,其SPARQL生成的算法如下:
1)对关键字内容进行分割,得到part1“用户分类”,part2“食品生产企业”,part3“肉和肉制品经营卫生规范”,part4“GB20799—2016”。
2)对part1 进行判断,选择相应的推理模板,并将part2、part3、part4作为参数进行传递。
3)SPARQL 根据推理模板生成搜索语句:由于参数中给出了标准的名称,而标准实体名称是独一无二的,可以忽略其他限制条件,对SELECT*WHERE{?s?p?o.?s <标准名称>obj.}中的obj进行替换,将得到最终的查询语句:
SELECT*WHERE
{?s?p?o.?s <标准名称><GB20799-2016>.}
该SPARQL 语句限制了?s 的属性为“标准名称”,相应的属性值为“GB20799—2016”,同时又查询与?s 相关的其他三元组作为结果返回。
本系统的检索模板是通过用户的需求人为定义的,所以随着需要的增加和改变,检索模板的定义也会有变更,但随着项目的进展,会根据用户需要设计自动生成检索模板的方法。
4.3 问答系统结果评价
问答系统的目的是站在不同任务的角度,根据用户的需要,发现对用户来说比较重要的标准以及与该标准关联比较紧密的其他标准,这对于标准使用者或者制定者来说,能帮助他们迅速得关注到标准的核心点及与其他标准之间的关联关系,能起到指导使用与优化建设的辅助功能。从目前问答系统得到的检索与推理结果来看,所有的结论在常识上与专业上都是可以解释的,符合食品安全与食品检验的基本规律,所以本文的食品安全标准图谱与问答推理系统能有效地反映标准间的引用关系并发掘不同任务、不同需要下重点标准与相关标准间的关系。但由于目前考虑到的任务与需求还比较少,所以推理方式也较单调,后期的实验与系统也会考虑到更多、更复杂的情况。
5 结语
本文通过对现有收集到的食品安全国家标准进行内容实体与引用关系的抽取,构建了食品安全国家标准图谱,整个图谱包括1 105 个节点和2 593 边,其中如“GB2763”这类通用限量食品安全标准以及“GB5009”这类检测标准所生成的节点连接度最高,表明这些标准在所有标准中重要程度更高。本项目建立了基于HACCP 的食品生产过程本体并完成了实体对齐,本体使得图谱间知识的联系更加清晰与完整,并为未来的更自动化的知识抽取提供基础与依据。然后基于知识图谱搭建了基于自然语言的问答系统,对图谱进行检索与推理,以此来挖掘不同标准间的相关性,找出不同需求下最具影响力的食品安全国家标准。实验结果表明,这种方式具有可行性,能实现“核心”标准的发现,对于研究食品安全国家标准的结构与内容分布有较好的指导作用。但是,未来还存在一些待优化的问题:一方面,由于缺乏可用的专业词库,知识抽取的自动化程度有待提高,未来随着项目自建的本体的完善,可以通过对其中实体与关系的训练来使用更快速、更新的技术来优化知识抽取的方法;另一方面,推理规则的生成还不能实现自动化,现在还需要通过人的分析来生成推理模板,未来将研究规则的自动生成方法。
