融合网络结构信息及文本内容的标签推荐方法
2021-04-20车冰倩
车冰倩,周 栋
(湖南科技大学计算机科学与工程学院,湖南湘潭 411201)
0 引言
随着数字资源的快速增长,标签推荐越来越受到人们的关注。最新的研究表明,除标题、描述和用户评论等其他文本功能外,标签能够对资源进行分类和建立索引,是组织和检索内容的有效方式[1],被广泛应用于各种自然语言处理任务中,例如情感分类[2]、内容推荐[3]等为在线内容推荐合适的标签是自然语言处理中的一项重要任务。从内容创建者的角度来看,标签推荐有助于为创建者提高所选标签质量和用户体验;从内容消费者角度来看,标签推荐有助于为消费者的搜索和检索请求提供更好的服务[4]。然而,手动标记通常既费时又费力。因此,为了提高数据管理效率和简化标注过程,有必要用到自动标签推荐系统。
目前已有研究者提出了许多自动标签推荐方法。一些研究利用传统的方法(如词频-逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF)、N-grams 等)人工提取文本内容特征进行标签推荐[5-6]。此外,潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)模型[7-8]或其扩展的主题模型[9-10]用于从文本内容中提取隐含的主题信息,基于这些主题信息计算文本之间的相似性,再通过文本间的语义相似度进行标签推荐。近年来,使用深度学习模型对文本内容中的隐藏信息建模(如词序信息、上下文信息等)后,进行标签推荐也成为了当下研究热点之一[11]。常用的模型包括卷积神经网络(Convolutional Neural Network,CNN)[12]和循环神经网络(Recurrent Neural Network,RNN)[13]等。但是这些方法主要是通过挖掘文本的内容信息,从资源本体的角度来设计标签推荐方法。实际上,很多文本并非独立存在。例如,文本数据可通过文本间的词共现关系而联系到一起,文本中的词与文本之间具有隐含的网络结构信息。研究表明,文本内容层面的信息和网络结构层面的信息独立存在,但又相互关联和影响,从不同的角度共同对一个文本的语义特征进行概括会得到更好的结果[14]。尤其在某方面信息缺乏时,内容和结构两方面信息可以互为补充,从而改进推荐的效果[15]。因此,需要充分利用文本之间的网络结构信息和文本内容信息进一步提高推荐的准确性。
基于上述分析,本文提出一种融合网络结构信息和文本内容、基于G-RNN(Graph Attention-Based Recurrent Neural Network)模型的标签推荐方法。该方法首先将文档与词汇作为节点构建异构网络图;然后,基于图卷积神经网络(Graph Convolutional neural Network,GCN)[16]建立基于这些节点的文本异构图,捕获高阶邻域信息,获取文本间的网络结构信息;接下来基于RNN 模型获取文本的内容信息;最后通过注意力机制对文本网络结构信息和文本内容信息进行交互建模。在三个真实数据集上的实验结果表明,本文方法明显优于对比的基线方法。本文的主要工作如下:
1)提出了一种基于注意力机制的混合标签推荐模型。该模型融合了文本间网络结构信息和文本内容信息,可以提取更好的文本语义特征,解决现有标签推荐模型中文本语义特征提取不充分的问题。
2)同时考虑到RNN 的四种变体对提取文本内容信息的影响,并用实验进行了对比验证。实验结果表明,与现有的几种基线方法相比,本文提出的融合网络结构信息和文本内容信息的标签推荐方法具有更好的性能。
1 相关工作
标签推荐技术已经引起了学者的广泛关注和研究,并根据具体问题提出了多种推荐方法。总的来说可以将这些推荐方法分为基于传统语义的方法和基于深度语义的方法。其中基于传统语义的方法主要分为两类[17]:基于协同过滤的方法和基于内容的方法。
基于协同过滤的方法核心思想是利用历史评分信息进行标签推荐;Feng 等[18]将社会标签系统建模为多类型图,通过学习图中节点和边的权重来推荐标签;Fang 等[19]提出了一种新的个性化标签推荐方法,该方法可视为典型张量分解的非线性扩展;Zhao 等[20]将标签数据中的关系建模为异构图,并提出了一个标签推荐的排序算法框架。
与基于协同过滤的方法相比,基于内容的方法是将内容作为输入,因此可以用于为新内容推荐标签,从而避免基于协同过滤方法的冷启动问题。典型的基于内容的标签推荐技术是使用主题模型推荐标签。Krestel 等[7]使用LDA,利用主题分布找出与目标资源具有相同主题的资源的标签作为扩展标签集;Si 等[21]提出了一种基于扩展LDA 的标签推荐方法,该模型通过在生成过程中添加标签变量来扩展LDA 模型;Ding等[22]提出了一种针对微博推荐标签的主题翻译模型,该模型将标签推荐建模为从内容到标签的翻译过程;Godin等[23]设计和实现了基于朴素贝叶斯技术的二进制分类器,该分类器区分英语和非英语推文来推荐标签。
基于深度语义的方法通过基于深度神经网络的模型学习文本表示以捕获文本内容,然后将该文本表示分类给不同的标签用来实现标签推荐。Weston 等[12]提出了一种基于CNN的推荐模型,该模型将单词以及整个文本内容表示嵌入在CNN 体系结构的中间层中以学习语义嵌入;Gong 等[24]采用了具有注意力机制的CNN 模型来执行标签推荐任务;Li 等[25]利用基于主题注意力的长短时记忆(Topical attention-based Long Short-Term Memory,TLSTM)神经网络进行标签推荐;Huang 等[26]在文献[24]和文献[25]的基础上,提出了一种基于注意力机制的记忆网络的标签推荐模型,用记忆网络代替CNN 和LSTM 进行标签推荐;Li 等[27]提出了一种将CNN 和长短时记忆(Long Short-Term Memory,LSTM)网络相结合的标签推荐模型;Tang 等[28]采用了具有注意力机制的门控循环单元(Gated Recurrent Unit,GRU)模型,同时建模文本内容和标签进行标签推荐;Shi等[29]提出了一种基于注意力机制的双向长短时记忆网络(Bi-directional LSTM,Bi-LSTM)标签推荐模型。从这些研究结果来看,更准确地获取文本隐含语义信息有助于促进标签推荐的准确性。然而,许多真实数据集是以图或者网络形式出现的。图是一种特殊的数据格式,可以用来表示现实世界中的各种网络信息。在图中,节点由边连接,通过深度学习模型可以将图中的节点映射到向量空间中,充分挖掘向量空间中的节点进行分类。然而,到目前为止,很少有研究关注将图卷积神经网络应用于标签推荐,以充分挖掘文本中的词与文本本身之间的隐含网络结构信息,进一步提升标签推荐的性能。
最近,Yao 等[30]利用图卷积神经网络进行文本分类。受此启发,本文提出了一种融合文本间网络结构信息和文本内容的方法,该方法采用的标签推荐模型为G-RNN 模型。与以往的工作相比,G-RNN 模型在RNN 提取文本内容信息的基础上通过注意力机制结合了使用GCN 提取的文本间的网络结构信息,使用更丰富的文本信息挖掘标签,能够有效提升推荐标签的准确度。
2 自动标签推荐方法
图1 为本文提出的自动标签推荐方法采用的标签推荐模型G-RNN,表1为本文常用符号及其说明。
2.1 问题定义
本文将标签推荐任务作为多分类问题进行处理。为更好地提取特征进行文本表示,本文考虑了注意力机制,并提出了一种融合网络结构信息和文本内容信息的标签推荐方法。
通常,语料库中全部文本可以表示为D={d1,d2,…,di,…,d|D|},其中|D|指语料库中包含的文本数量;语料库中全部词汇可以表示为W={w1,w2,…,wi,…,w|W|},其中|W|语料库中包含的词汇数量;单个文本内容可以表示为其中wi指文本的第i个词汇,|di|指文本包含的词汇数目。对于一个新文本,标签推荐的任务是为这个新文本推荐功能语义相近的标签。本文提出的标签推荐模型由三部分组成:1)文本间网络结构信息提取。本文首先将文档与词汇作为节点构建文本异构图,使用GCN 捕获高阶邻域信息,从而获取文本间网络结构信息。2)文本内容信息提取。本文使用四种不同的RNN 变体对文本内容中的隐藏信息(如词序信息、上下文信息等)进行编码提取特征。3)注意力机制。本文使用注意力机制将文本网络结构信息与文本内容信息相融合,通过softmax层获取最终的推荐标签。
这三个部分的基础是每个单词都被表示为低维、连续的实值向量,也称为单词嵌入[31-32]。所有词向量都堆叠在词嵌入矩阵其中R 表示实数集向量空间,dim是词向量的维数,xi是wi对应的词向量。使用嵌入学习算法对来自文本语料库的单词向量的值进行预训练,以更好地利用单词的语义和语法关联信息[32]。给定文本内容,对文本中每个词进行嵌入,得到输入层向量。为保证文本向量输入长度一致,设定单个文本最长文本长度为N,文本di可用(x1,x2,…,xN)表示。

图1 G-RNN模型Fig.1 G-RNN model

表1 常用符号及其含义Tab.1 Common symbols and their meanings
2.2 文本间网络结构信息提取
语料库中文本间网络结构信息的提取主要是基于文档及文档间词共现信息构建异构文本图,通过GCN 实现建模。本节将分为两步介绍该过程:第一步,构建异构文本图;第二步,使用GCN对异构文本图进行建模计算获取文档嵌入向量。
2.2.1 异构文本图构建
该部分将介绍如何从语料库中构建异构文本图。具体任务为,给定语料库D,构建异构图G=(V,E),其中V是图的节点集合,E是图的边集合。节点指文档以及语料库中去重后的全部词汇,边是基于文本间词的共现和整个语料库中词的共现来构建的,其中文档与共现词进行连接,共现词与共现词之间进行连接。文档节点和单词节点之间的边的权重是文档中该词的TF-IDF 值,其中词频(TF)为单词在文档中出现的次数,逆文档频率(IDF)是包含该词的文档数量的倒数的对数。为了更好地收集全局词共现信息,本文对语料库中的所有文档使用固定大小的滑动窗口收集信息。单词节点与单词节点之间的边的权重使用点互信息(Point-wise Mutual Information,PMI)来计算。任意节点i与节点j之间的边的权值定义为:

其中:#S(i)是语料库中包含单词i的滑动窗口的数量;#S(i,j)是包含单词i和j的滑动窗口的数量;#S是语料库中滑动窗口的总数。正PMI 值意味着语料库中单词的高语义相关性,而负PMI 值表示语料库中很少或没有语义相关性。因此,本文仅在PMI为正值的词对之间添加边。
2.2.2 图编码器
Kipf等[16]在2017 年提出的GCN 是一个多层神经网络,它是对图形结构数据的传统卷积算法的变体。它直接对图进行操作,并根据节点的邻域属性归纳出节点的嵌入向量。
在构建了异构文本图后,可获取到异构图的邻接矩阵A及其度矩阵M,其中由于节点自循环,A的对角线元素为1。同时本文将特征矩阵设置为单位矩阵I。将邻接矩阵A与特征矩阵送入两层GCN 中进行建模和卷积运算,形成词和文档的嵌入表示向量,第二层的节点嵌入与标签集的大小相同。

2.3 文本内容信息提取
一般而言,局部序列特征的提取是对文本进行编码,将文本中嵌入的一系列单词转换成固定的二维向量的过程。有许多研究使用RNN 的变体[13,27-29]来进行文本编码。GCN 可以有效地提取全局特征,而RNN 的变体(如LSTM、Bi-LSTM、GRU、Bi-GRU)适合对文本进行编码提取局部序列特征。因此,本文将使用RNN 的四个变体对文本进行编码提取局部序列特征。
本文首先通过预训练得到给定文本(x1,x2,…,xN),使用三层RNN 的变体按顺序进行序列建模。RNN 的变体按顺序对其进行处理,获取到所有的隐藏向量[h1,h2,…,hN]。
1)基于LSTM的序列编码器。
LSTM[33]在每个单元使用输入门、遗忘门和输出门来控制信息沿着序列的传递。文本中每个单词按序列分别输入到一个LSTM 单元。对于t时刻LSTM 单元的输入xt,给定t-1 时刻的输出ht-1和单元状态ct-1,LSTM 单元使用输入门gt,遗忘门ft,输出门ot和描述当前输入的单元状态获取到t时刻的输出ht和单元状态ct。在对文本进行编码时,t时刻的LSTM单元的更新公式如下所示:

其中:σ为sigmoid函数;Wg、Wf、Wc和Wo是加权矩阵,而bg、bf、bc和bo是偏移量。
2)基于Bi-LSTM的序列编码器。
Bi-LSTM 是基于众所周知的LSTM 模型[33]开发的双向神经网络。一个Bi-LSTM单元包含两个LSTM单元,用于捕获文本中的前向和后向信息。在本文中,t-1 时刻的前向LSTM单元的输出记为,t-1 时刻的后向LSTM 单元的输出记为。因此,t时刻的Bi-LSTM单元的更新公式如下所示:

3)基于GRU的序列编码器。
GRU[34]在每个单元使用重置门、更新门来控制信息沿着序列的传递。同LSTM 的序列编码器一样,文本中每个单词分别输入到一个GRU 单元。对于t时刻GRU 单元的输入xt,给定t-1 时刻的输出ht-1,GRU 使用重置门rt,更新门zt和当前时刻待输入的隐藏状态信息获取到t时刻的输出ht。在对文本进行编码时,t时刻的GRU的更新公式如下所示:

其中:σ为sigmoid 函数;Wr、Wz、Wh~是加权矩阵,而br、bz、bh~是偏移量。
4)基于Bi-GRU的序列编码器。
Bi-GRU 是基于众所周知的GRU 模型[34]开发的双向神经网络。一个Bi-GRU 单元包含两个GRU 单元,用于捕获文本中的前向和后向信息。在本文中,t-1 时刻的前向GRU 单元的输出记为时刻的后向GRU 单元的输出记为因此,t时刻的Bi-GRU单元的更新公式如下所示:

综上所述,RNN 层可得到文本序列隐藏向量序列[h1,h2,…,hN]。
2.4 注意力机制
本文引入了注意力机制对网络结构信息和文本内容信息进行整合。给定文本di,使用GCN 获取到矩阵F2中对应文本di的文档嵌入向量θdi∈RK×1,K为语料库中标签数量,使用RNN 按顺序对文本di进行处理,获取到所有的隐藏向量[h1,h2,…,hN]。注意力层将为每个文本连续输出向量vec∈Rμ×1。输出向量为每个隐藏状态hj的加权和:

其中:μ为RNN 隐藏层维数;Wa∈Rμ×K,Ua∈Rμ×μ和la∈Rμ×1是权重矩阵;aj∈[0,1]是hj的注意力权重且1。
接下来将输出向量vec=[v1,v2,…,vK]馈送到线性层,该线性层的输出长度为所有标签的数量。通过softmax 层输出选出概率高标签作为推荐标签:

本文将标签推荐建模为多分类任务,通过最小化标签分类的交叉熵误差,以监督的方式训练模型。损失函数如下:

其中:Y是训练集;y和T是训练集文档及其对应标签集;Ti是正在预测的当前标签;p(Ti|y)是为输入文档y选择标签Ti的概率。
3 实验与结果分析
将本文方法中的标签模型G-RNN 应用于标签推荐任务以评估性能。
3.1 数据集
本文实验使用了三个数据集:Math(Mathematics Stack Exchange)、AU(Ask Ubuntu)和SO(Stack Overflow)。所有数据集均已正式发布并公开可用(https://archive.org/details/stackexchange)。每个数据集包含多个帖子,每个帖子包含一段文本内容(标题和正文)以及相应的标签。实验对数据集执行以下预处理步骤。首先,删除所有标点符号,然后将其余的字符串拆分为单个单词,进行去除停用词和词干还原处理。其次,删除文本内容中的一些低频词以减少噪声,计算每个单词的频率并将词汇表中每个数据集的最频繁出现的单词保留在词汇表中。最后,由于很少使用低频标签,因此同时对标签的频率进行计数,并保留最常用的标签。本文随机选择AU数据集和SO 数据集的一个子集,AU、SO、Math 分别包含65 653、57 984、64 983 篇帖子,18 508、22 730、26 214 个去重词汇,71 030、69 117、78 200 个节点,600、200、717 个标签。对于每个真实数据集,随机选择80%的数据作为训练集,并在训练集中随机选择10%的数据作为验证集,其余的20%作为测试集,详细数据集信息汇总如表2所示。

表2 数据集详细信息Tab.2 Detail information of datasets
3.2 评测标准
本文采用准确率、召回率以及F1值对本文方法的效果进行评估。
准确率表示推荐的标签集中相关标签所占的比例,其计算如下所示:

其中:@k表示推荐的标签个数;tagλk表示推荐的标签集合;tagλdi表示文本di真实标签集合。
召回率表示推荐的相关标签占所有相关标签的比例,其计算如下所示:

F1 值融合了召回率和准确率,是它们两者的调和平均值,其计算如下所示:

3.3 基线和实验设置
3.3.1 基线方法
实验选择以下基线方法进行比较:
1)Maxide[35]。该方法使用传统的矩阵补齐模型对文本内容进行建模推荐标签,是一种传统的标签推荐多标签学习方法。
2)TagSpace[12]。该方法使用CNN 对文本内容信息建模得到文本的嵌入表示,通过标签得分函数对候选标签进行排序得到推荐标签。
3)LSTM[25]。该方法使用LSTM 对文本内容信息进行建模得到隐藏向量,添加softmax 层以输出所有候选标签的推荐概率分布。
4)TLSTM[25]。该方法将LSTM模型的隐藏向量与LDA模型得到的主题向量通过注意力机制进行结合,添加softmax 层以输出所有候选标签的推荐概率分布。
5)GCN[30]。该模型直接使用GCN 进行标签推荐,将文档节点的特征向量视为文档向量,添加softmax 层以输出所有候选标签的推荐概率分布。注意,该模型并未对文本内容进行建模。
6)G-LSTM。本文提出的G-RNN 模型的第一个变体,本文将GCN 层的文档嵌入向量与LSTM 最后一层的隐藏向量通过注意力机制进行结合,添加softmax 层以输出所有候选标签的推荐概率分布。
7)G-BiLSTM。本文将GCN 层的文档嵌入向量与Bi-LSTM 最后一层的隐藏向量通过注意力机制进行结合,添加softmax层以输出所有候选标签的推荐概率分布。
8)G-GRU。本文将GCN 层的文档嵌入向量与GRU 最后一层的隐藏向量通过注意力机制进行结合,添加softmax 层以输出所有候选标签的推荐概率分布。
9)G-BiGRU。本文将GCN 层的文档嵌入向量与Bi-GRU最后一层的隐藏向量通过注意力机制进行结合,添加softmax层以输出所有候选标签的推荐概率分布。
3.3.2 实验设置
本文使用了两层GCN[16]和三层RNN[28]。对于GCN部分,设置第一个卷积层的嵌入大小为300,滑动窗口大小为20。对于RNN 部分,将最大文本长度设置为40,使用词向量模型Word2Vec 对单词进行预训练,单词嵌入维数设置为100。对于LSTM/GRU的神经元,其隐藏状态的维数设置为500。在训练模型时,采用Adam 优化器[36]进行模型训练。为了防止过度拟合,将学习率设置为0.02,dropout 为0.5,损失权重为0,并在损失不再减少时停止训练过程。
实验平台为Windows 10 系统下的PyCharm Community 2019,所有跟踪实验均在配置为Intel Core i7-9750CPU,显卡为NVIDIA GeForce GTX 1650Ti,内存为16 GB 的计算机上完成,采用Keras深度学习框架。
3.4 性能评估
表3为不同模型在不同评价指标下的性能比较,图2~4对比显示了使用GCN 和RNN 变体同时获取网络结构信息和内容信息进行推荐的性能。

表3 不同模型在top-1、top-3、top-5下在三个数据集上的性能比较Tab.3 Performance comparison on three datasets by different models with top-1,top-3,top-5

图2 各模型在三个数据集上的准确率比较Fig.2 Precision comparison of different models on three datasets

图3 各模型在三个数据集上的召回率比较Fig.3 Recall comparison of different models on three datasets

图4 各模型在三个数据集上的F1值比较Fig.4 F1 comparison of different models on three datasets
从图2~4 可以看出:本文提出的方法上在三个数据集上的总体性能优于基线方法。在召回率指标上,G-BiGRU 模型基于三个数据集较最优基线方法平均提高了5.5%;在F1 值指标上,G-BiGRU 模型基于三个数据集较最优基线方法平均提高了5.2%。与三种评价标准最优的基线进行比较,在Math 数据集上,G-BiGRU 模型准确率平均提高2.3%,召回率平均提高3.8%,F1 值平均提高7.0%;在AU 数据集上,G-BiGRU 模型召回率平均提高8.4%,F1 值平均提高3.8%;在SO数据集上,G-BiGRU模型召回率平均提高4.2%,F1值平均提高4.8%。总体上,G-BiGRU 模型的准确率提高有限,原因是Math 数据集文本较长,可获取更多的文本内容信息,而其他两个数据集文本较短,对文本信息的提取效果较差。G-BiGRU 模型的召回率提高较多,G-BiGRU 模型的F1 值较其他基线方法也都有提升。
从图2~4还可看出:使用GCN 和Bi-GRU 结合的G-BiGRU模型整体性能最高。GCN和LSTM、GRU结合的G-LSTM 和GGRU 模型在融合文本间网络结构信息基础上同时考虑了文本内容信息,所以比单纯使用GCN效果好。GCN和Bi-LSTM、Bi-GRU结合的G-BiLSTM 和G-BiGRU模型在融合网络结构信息基础上同时考虑了文本内容上下文信息,所以效果较好。由于Bi-GRU 单元较Bi-LSTM 单元更加简洁、高效和收敛速度更快,较GRU 单元更全面提取了文本的内容信息,所以使用RNN 变体中的Bi-GRU 模型与GCN 模型相结合是推荐标签的理想选择。
综上所述,对于本文采用的3 种评估标准,本文方法比其他基线方法效果好,原因是该方法同时使用了文本间网络结构信息和文本内容信息,可以推荐更加准确的标签。虽然TLSTM 使用LSTM 和LDA 同时提取文本的内容的隐藏信息和主题信息来推荐标签,但是仍没有考虑到文本与文本之前隐含的网络结构信息,而这些信息可以用来提高推荐的性能。虽然GCN 通过提取文本间网络结构信息来推荐标签,但是没有考虑到文本内容信息,而这些信息对于推荐性能的提高也是必不可少的。当推荐标签个数逐渐增加时,所有方法的召回率都不断增加,这是因为推荐的真确标签数目越来越多,同时,由于文本的真实标签数目有限,可以预测召回率随着推荐标签个数的增多逐渐趋于稳定。与此相反,基本上所有方法随着标签个数的增加准确率逐渐变小,这是因为推荐了越来越多的不准确的标签。尽管本文模型在AU、SO 数据集上准确率没有超过每个基线模型,但是总体性能仍然非常令人满意。这验证了融合网络结构信息和文本内容信息在标签推荐中的有效性。
3.5 实例
为了更加清晰地体现实验的效果,首先,在测试数据集中随机挑选一篇帖子,该帖子的题目为“Implementing and Enforcing Coding Standards”,正确标签为“c#,standards,coding-style”,使用具有代表性的基线TLSTM 模型和GCN 模型与本文最优的变体模型G-BiGRU 模型分别对该帖子进行标签推荐。
从表4 可以看出使用G-BiGRU 模型推荐出3 个正确标签,而TLSTM 模型和GCN 模型仅推荐出2 个正确标签。G-BiGRU 模型比TLSTM 模型和GCN 模型的效果好是因为G-BiGRU 模型不仅使用了文本间的单词共现信息,还同时使用了文本内容信息。
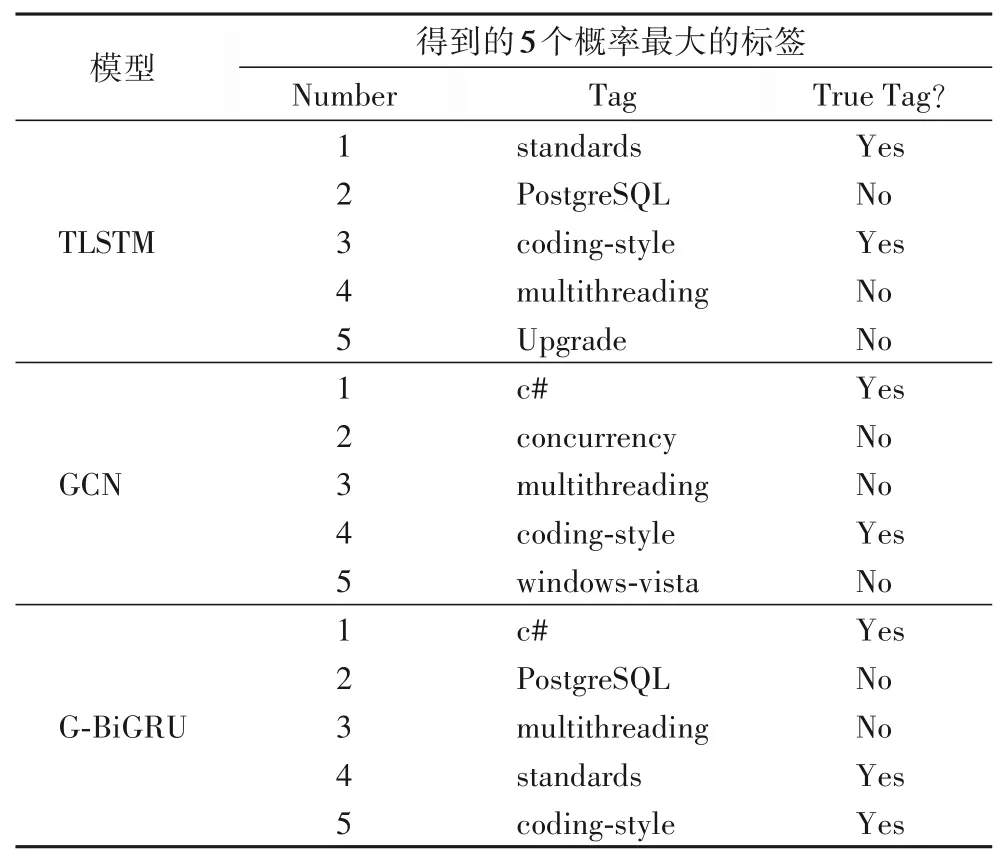
表4 对帖子推荐标签实例Tab.4 Examples of tag recommendation for a post
4 结语
本文提出了一种融合网络结构信息和文本内容信息的标签推荐方法,该方法同时考虑了文本与文本之间的通过单词共现信息可获取到的隐藏网络结构信息和文本内容的隐藏信息,并使用注意力机制结合两种信息将标签推荐问题转化为一个多分类问题。实验结果表明,同时考虑文本的网络结构信息和内容信息可以有效地提高标签推荐的效果。目前的工作没有考虑到标签与标签之间的语义联系,因此,在未来将通过引入标签与标签之间的语义联系或其他有用的辅助信息来进行模型改进。
