基于时间序列分析方法的 广州市月降水量分析
2021-04-17庄燕璇
庄燕璇


摘要:本文基于广州市1998年1月—2019年12月月度降水量数据,对序列进行建模分析和预测。基于AIC和BIC法则分别建立疏系数模型ARIMA((4,5,6,7,8),1,1)和综合分析模型Xt=StIt,两种模型对2018年数据的拟合情况为:疏系数模的预测相对误差小于50%的比例为33.33%;而综合分析模型为58.33%。因此采用综合分析模型对广州市2020年降水量数据进行预测,预测得出广州市2020年1月的降水量为54.686 mm,但随着预测期的延长,预测精度降低。
关键词:广州市降水量序列;AIC;BIC;ARIMA模型;综合分析方法
降水量是衡量地区干旱程度的一个重要指标,它直接反映了自然界的变化。降水量的多少直接影响农业生产,与现在农作物的生长周期和产量更是联系密切。同时,降水量的年际变化趋势直接制约着区域社会经济发展和生态生活环境,影响着区域水资源的调配管理。通过对数据拟合建立一个不错的模型进行短时间内较精确的预测,有助于安排农业生产,注意防范洪涝灾害以及对水资源进行调配,具有重大的现实意义。
张吉英[1]利用沈阳市2005年至2016年的降水量资料,建立了ARIMA(1,1,1)预测模型对沈阳市降水量进行分析预测。张改红[2]利用渭南市1953年至2013年的降水量资料,采用ARIMA模型对渭南市降水量趋势进行模拟分析,建立最优降水量预测模型,该模型优点为短期预测精度高。吕志涛[3]利用郑州市1971年至2013年降水量资料,分别采用了二次多项式拟合、谐波分析法以及自回归模型构建了郑州市降水量的预报模型,预报精度较高。
本文以广州市为研究区域,利用1998年1月至2019年12月的广州市降水量资料[4],分别建立ARIMA模型和综合分析模型对广州降水趋势进行分析,最后选择最优模型进行预测应用。
首先基于AIC和BIC法则分别建立疏系数模型ARIMA((4,5,6,7,8),1,1)和综合分析模型Xt=StIt。接着根据模型对2018年的拟合结果选择最优模型,发现此背景下综合分析方法优于ARIMA模型。最后采用综合分析模型对广州市2020年的降水量数据进行预测。
本文的创新点在于分别选取了ARIMA模型和综合分析模型对降水量数据进行分析,并通过对比预测效果挑选相对最优模型对2020年降水量进行预测。
1 研究方法与理论分析
本章分为三节,第一、二节分别简要介绍ARIMA和综合分析方法的一般形式和建模步骤;第三节则给出模型精度评估方法。
1.1 ARIMA模型
1.1.1 ARIMA模型的一般形式
(1.1)
1.1.2 ARIMA模型建模的大体步骤
一、对初始时间序列进行平稳性分析,利用ADF检验对序列的平稳性进行检验[5]。
若初始时间序列平稳,则接着进行白噪声检验;若初始时间序列不平稳,则对初始时间序列差分平稳化后进行白噪声检验。
若检验结果显示为非白噪声序列,则拟合ARMA模型。
对拟合后的残差序列进行白噪声检验,若残差序列为白噪声,则说明初始时间序列的信息被充分提取,即模型较好;若残差序列为非白噪声,则需要重新进行拟合。
若ARIMA(p,d,q)模型中有部分自相关函数或部分平滑系数为零,那么该模型成为疏系数模型,记为ARIMA((p1,...,pm),d,(q1,...qn))。
1.2 综合分析方法
1.2.1 将序列进行混合模式分解
(1.2)
其中,Tt为趋势效应拟合,St为季节效应拟合, It为随机波动。
1.2.2 求出季节效应拟合
假定时间序列 周期长度为m,则季节指数的计算公式如式(1.3)所示。
(1.3)
其中为每个周期内的平均值,为总体均值。
1.2.3 对趋势效应Tt进行拟合
对趋势效应常用以自变量为时间t的幂函数进行拟合,即
(1.4)
1.2.4 对残差序列拟合移动平均模型,以便充分提取相关信息
(1.5)
由(1.2)、(1.4)、(1.5)构造模型如下:
(1.6)
1.3 精度评估
本文用两个准则来评估预报模型的精度。
一、相对误差=,这是反映单个预测值精度的指标。
二、平均绝对百分比误差这是反映一组预测值精度的指标。
其中,是时刻t的预测值,yi是时刻t的原始值,n是预测数。
2 广州月度降水量时序模型
2.1 ARIMA模型的应用
2.1.1 序列观察
本文对1998年1月—2019年12月264个广州月度降水量进行分析。本文用前240个数据参与建模,并用2018、2019年的数据检验模型的拟合效果,最后对2020年进行预测。
首先作时序图如图1所示。
由图1可以看出该序列具有以下特点:有明显的非零均值,有一定的周期性,周期为12个月,说明该序列是非平稳的。
因为降水量时间序列是非平稳时间序列,因此,我们先对初始时间序列进行差分平稳化后。
2.1.2 进行1阶差分
首先对原序列χt做1阶差分,得到序列▽χt,接着进行单位根检验判断序列▽χt的平稳性。检验结果见图2。
由图2可以看出,该序列单位根检验的p值均小于0.0001。因此,在显著性水平0.05下认为序列▽χt是平穩的。
2.1.3 拟合ARMA模型
根据2.1.2得出:序列▽χt是平稳时间序列。因此可以采用ARMA模型来拟合序列▽χt。根据BIC准则,本文选择ARMA(8,1)模型来拟合序列▽χt。采用最小二乘法估计参数,因为模型ARMA(8,1)的一些参数不显著,所以需要重新估计。接着,逐步剔除掉模型中不显著的参数,直到模型剩下的参数均显著为止。剔除的过程不在此处赘述,最后采用了无常数项的疏系数模型ARMA((4,5,6,7,8),1)来拟合序列▽χt。参数估计见图3。
由图3可以看出,变量“MA1,1”、“AR1,1”、“AR1,2”、“AR1,3”和“AR1,4”的t检验的p值均小于0.05。因此,在显著性水平0.05下可以认为这5个参数显著非零。而变量“AR1,5”的t检验的p值为0.0537。因此在显著性水平0.05下认为该参数不显著而在显著性水平0.01下是显著的。权衡了拟合后残差的白噪声检验结果后决定将该参数加入模型中,即可用模型ARMA((4,5,6,7,8),1)来拟合序列 。
2.1.4 模型的检验
为了检验模型对序列 的拟合效果,我们首先对拟合后的残差序列进行白噪音检验,检验结果见图4。
由图4可以看出,白噪声检验的p值均大于0.05。因此,在显著性水平0.05下认为残差序列为白噪声,说明该模型的拟合效果好。
所以通过对1998年1月—2017年12月广州降水量月度数据进行拟合并优化得到的具体模型是:
(2.1)
接下来需要通过比较模型的生成数据与现实的测度数据来观察模型对广州降水量的拟合效果。利用模型对2018年及2019年的广州降水量月度数据做外推预报并计算相对误差见表1。
由表1可以看出广州市2018年实际降水量与预测值的相对误差的平均值为1.23,而2019年为14.07。2018年相对误差在30%以内的比例为33.33%,而2019年相对误差在30%以内的比例为25%。因此,可以看出该模型对2018年降水量的拟合效果比2019年的好,从而可以看出,该模型不适用于长期预测。
从预测结果可以得出以下结论:第一,疏系数模型模型作为广州市降水量预测模型是可行的;第二,该模型适合短期预测,随着预测的延长,预测的误差将逐渐增大。
2.2 综合分析方法的应用
2.2.1 求出季节效应拟合
一、计算季节指数
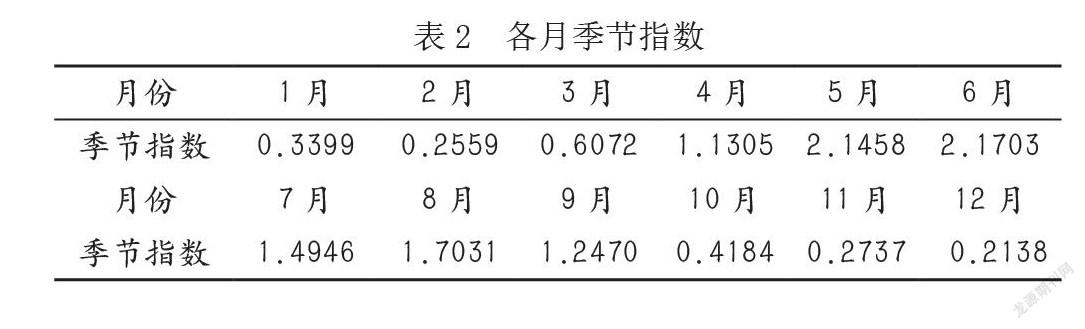
根据式(1.3)计算各月季节指数数据见表2。
由表2可看出,广州降水量1月与2月较平稳,且降水量较少,3月—5月急速上升,5月—6月较为平稳,7月至12月呈现下降趋势。其中1、2、3、10、11和12月的季节指数小于1,到12月时达到最低谷。4月—9月的季节指数均大于1,在六月达到最高峰。
3.2.2 对随机波动It进行拟合
2.2.1节已求出季节效应拟合,下面以原时间序列值除以对应的季节效应拟合,得到的不包含季节效应的随机波动的综合值,即:,图5为序列{Xt/St}的时序图。
由图5可以看出,序列{Xt/St}基本消除了季节性,且不具有趋势性,可以初步判定序列{Xt/St}是平稳时间序列。
为了进一步的判断序列{Xt/St}的平稳性,接着对其进行单位根检验,检验结果为在显著性水平0.05下认为该序列是平稳时间序列。
2.2.3 对随机波动 拟合ARMA模型
将随机波动作为一个新的序列,按照1.1.2节介绍的方法建立ARMA模型来进行拟合,根据BIC准则:本文选择ARMA(1,1)模型进行建模。
接着,我们采用无常数项ARMA(1,1)模型拟合随机波动序列{Xt/St},参数估计见图6。
图6 随机波动模型参数估计结果
由图6可以看出,变量“MA1,1”和变量“AR1,1”的t检验p值均小于0.0001。因此,在显著性水平0.05下认为该参数显著非零。
随机波动模型如下:
(2.2)
从而最终模型为:
(2.3)
2.2.4 模型检验
为了检验模型(2.3)的拟合效果,首先对拟合后的残差序列进行白噪音检验,检验结果为在显著性水平0.01下无法拒绝残差序列为白噪声。说明模型(2.3)提取信息充分,拟合效果较好。
为了对模型进行检验,下面利用模型对于2018年及2019年的广州降水量月度数据做外推预报,得到的预报值见表3。
由表3可以看出广州市2018年实际降水量与预测值的相对误差的平均值为0.50,而2019年为7.00。2018年预测相对误差在30%以内的比例为33.33%,而2019年预測相对误差在30%以内的比例为25%。因此,可以看出该模型对广州市2018年降水量的拟合效果比2019年的好,且该模型不适用于长期预测。
从预测结果可以得出以下结论:第一,综合分析方法作为广州市降水量预测模型是可行的;第二,该模型适合短期预测,随着预测的延长,预测的误差将逐渐增大。
2.3 两种模型的对比与预测
根据2.1和2.2的分析,两种模型均不适用于长期预测。因此,我们将根据两种模型的短期预测效果即对2018年降水量的预测效果来判断两种模型的好坏,并用相对较好的模型来对广州2020年的降水量进行预测。
2.3.1 两种模型的对比
本文通过两个角度来对比两种模型,其一是两种模型预测精度的比较;其二是预测结果的整体规律比较。
2.3.1.1 预测精度比较
由表1和表3可以看出,采用ARIMA模型拟合的2018年降水量的相对误差低于50%的占比33.33%;而采用综合分析方法预测的相对误差低于50%的占比为58.33%,比ARIMA模型高出25%。因此,从预测精度看,综合分析方法要优于ARIMA模型。
2.3.1.2 预测结果的整体规律比较
分别计算实际数据以及两种模型拟合2018年降水量的平均数、中位数、极差,见表4。
由表4可得疏系数模型拟合值的平均数、中位数和极差与实测值的平均数、中位数和极差的差值分别均大于综合分析方法。因此,从预测结果的整体规律看,综合分析方法要优于ARIMA模型。
综上所述,我们认为综合分析方法更适用于拟合广州市月降水量。
2.3.2 模型的预测
根据2018年1月—2019年12月观测的实际值进一步修正模型后,得到广州市2020年1—12月降水量预测值及其置信区间,见表5。
从对2020年的预测结果上看,广州市降水量仍然延续以往的发展规律。2020年1月—2月降水量小且平缓,3月—6月急速增长且在六月达到最高峰,然后6月—9月总体呈现急速下降的趋势,但是7月—8月降水量增加,在10月—12月降水量较小且变化平缓。
3 结论分析与建议
本文基于ARIMA((4,5,6,7,8),1,1)模型拟合广州市降水量序列,所得到的模型BIC值为3001.104,AIC值為2980.245,而综合分析模型为3048.52和3041.559。根据模型对2018年和2019年降水量数据的拟合结果得出两种模型均只适用于短期预测。
最后根据模型对2018年的拟合结果选择最优模型。两种模型对2018年数据的拟合情况为:疏系数模的预测相对误差小于50%的比例为33.33%;而综合分析模型为58.33%。疏系数模型拟合值的平均数、中位数和极差与实测值的差值均大于综合分析模型。因此,采用综合分析模型(2.3)对广州市2020的降水量数据进行预测,预测结果见表5。但随着预测期的延长,预测精度降低。建议在使用综合分析模型预测年降水量时,尽量保证数据序列足够的情况下,采用逐年实时校正的预测方法。然后参考预测的结果做出相应的水资源调配以及防洪措施。
参考文献
[1] 张吉英.基于ARIMA模型的沈阳市月降水量时间序列分析[J].内蒙古水利,2019(6):13-14.
[2] 张改红.基于ARIMA模型的渭南市降水量趋势分析与预测[J].价值工程,2019,38(34):197-199.
[3] 吕志涛.时间序列分析方法在郑州市降水量预报中的应用[J].南水北调与水利科技,2014,12(4):35-37,56.
[4] 国家统计局.中国统计年鉴(2020)[M].北京:中国统计出版社,2020.
[5] 王燕.应用时间序列分析[M].北京:中国人民大学出版社,2005.
