稠密特征编码的遥感场景分类算法
2021-04-12李国祥马文斌王继军
李国祥,马文斌,王继军
1(广西财经学院 教务处,南宁 530003) 2(广西师范大学 广西多源信息挖掘与安全重点实验室,广西 桂林 541004) 3(广西财经学院 信息与统计学院,南宁 530003)
1 引 言
遥感图像分类作为遥感图像处理的重要研究方向,是遥感技术开展广泛应用的一个重要技术支撑.随着遥感技术的发展,遥感影像的空间分辨率不断提高,其中所包含的几何、纹理、结构,以及丰富的内容场景信息,为目标精准识别和检索任务提供了重要参考,也为遥感分类提出了更大的挑战.有效提高图像解译的性能,提取能够有效代表图像内容的特征,实现精准的特征表达,是下一步遥感图像检索,目标识别的重要前提.
近年来,众多特征提取算法用于遥感图像的分类与检索,特征呈现出多样化、精细化和深度化的特点,研究者也对遥感图像场景分类中不同特征提取策略进行分类总结和定量评估[1].目前根据特征所表达的低中高层次的图像语义,普遍将遥感图像的特征分为3类:1)代表图像底层语义的原始图像基本特征,如一些能够代表图像全局或局部特征的描述子,如HU矩、纹理特征、经典描述子SIFT[2]、LBP等,以及众多在原有特征描述子的基础上开展的优化,SURF、Affine-SIFT[3]、HOG[4]、BRIEF.这些特征作为初始特征可以直接输入分类器中进行分类.赵理君等[5]对遥感数据分类中的经典分类方法K近邻、随机森林、支持向量机和稀疏表达分类器做了细致的对比研究;2)代表图像中层语义的编码特征.这些是在图像原始特征的基础上通过编码等方式形成更为细腻的图像特征.其中BoVW模型作为该类特征的典型代表,自提出以来在图像检索、分类等领域得到了广泛应用,它的主要思想是将特征描述子聚类成为若干个“词袋”,根据各特征点聚类的归属形成一定维度的统计直方图,该直方图替代特征描述子作为分类器的特征输入.以及其他对词袋模型进行的改进编码,例如,对每一个统计词袋进行加权的TF~IDF[6],对图像进行多尺度划分的SPM[7],保存每一个特征点与最近聚类中心距离的VLAD[8]等等;3)特征则是基于卷积神经网络的深度学习特征.随着卷积神经网络被大量引入遥感图像处理领域,其全连接层的高维向量在遥感图像分类中效果优异.一般将经过大规模图像训练的Alexnet、VGG16等CNN模型迁移至遥感数据集中进行参数精细调整,并提取某一全连接层作为深度特征,或者进一步编码融合.龚希等[9]分别提取了VGG19的全连接层特征和卷积层特征,并将卷积层特征采用BOVW编码,与全连接层特征共同形成新的特征向量.李亚飞等[10]在Alexnet基础上修改了网络结构,去掉了一部分卷积层和池化层,使用光谱特征向量、纹理特征矩阵、亮度、绿度和湿度等形成混合特征,作为CNN的输入.张晓男等[11]将多种主流卷积神经网络集成,通过使用BP神经网络进行图像复杂度度量,确定对于该类图像所采用的卷积神经网络,进而提高分类精确度、减少分类时间.同时,越来越多深度学习特征融合的方法应用在遥感图像分类中.刘异等[12]将Fisher核编码和CaffeNet全连接层特征结合到一起形成新的特征向量.FAN等[13]提取最后一层卷积层特征作为特征向量并进行BOW等编码.
从目前的对于图像检索分类的研究来看,代表高层语义特征的深度学习方法较其他方法分类精度高,但是对于计算环境要求苛刻,即便是在高性能GPU运算的情况下,在大样本数据集中所需要的时间也是动辄计算几天,计算成本和时间成本在一定程度上限制了适用范围.为此,本文以中低层语义特征为基础,通过不同尺度稠密特征的提取和编码,提升特征提取策略的表征能力,在一定程度上兼顾图像分类速度和分类精确度的平衡.
2 DenseSIFT
传统SIFT特征通常采用高斯差分函数构建图像的多尺度空间结构,然后在高斯差分空间中检测极值点并从中筛选出有效的特征采样点,计算方式复杂.Dense SIFT 特征则不需要在高斯尺度空间上提取特征点,通过对图像高斯平滑,建立一定尺寸和步长采样窗口在图像采集域内滑动均匀采样,提取采样窗口中心点坐标和窗口内每个像素8个方向上的梯度,形成与SIFT同等维度特征向量.稠密特征广泛的应用于视频追踪[14]、人脸识别等[15]领域.为了进一步提升特征应对场景复杂变换的能力,我们对原图进行尺度变换,在原图与四倍下采样之间对数等分生成5个不同尺度图像,提取不同尺度下的稠密特征并将其合并成为特征阵列,最后利用Hellinger kernel实现原始特征在新的RootSift空间映射[16].
设x,y为不同尺度下稠密特征合并后的特征向量,且‖x‖=1,‖y‖=1,则二者的欧式距离可以表示为:
(1)
通过Hellinger映射:
(2)
对特征向量x,y取平方根,从而将相似性测量的欧氏距离映射至Hellinger距离:
(3)
最后将映射后的特征向量进行主成分分析,形成新的低维度的稠密稳健特征.这里我们将特征前两个主分量可视化,如图1所示,可见主分量可以有效的表达遥感图像不同场景语义特征.

图1 特征向量的可视化Fig.1 Visualization of feature vectors
3 稠密特征编码的遥感图像特征提取
3.1 Fisher核编码
Fisher 核编码是利用Fisher kernel形成图像紧凑特征的表示,其本质是用似然函数的梯度向量来表达一幅图像,即用高斯混合模型(GMM)输出的向量表示一幅图像.设图像有T个描述子,则图像可表示为X={xt,t=1…T}.因图像特征独立同分布,图像的概率分布可表示为所有特征概率分布的乘积:
(4)
式中,λ={ωi,μi,σi,i=1…N},是GMM的模型参数,ωi是GMM第i个成分的权重,μi,σi是其均值和协方差.取对数后可表示为对数概率之和:
(5)
图像特征xt的概率分布函数可表示为:
(6)
式中,pi是GMM中第i个成分的概率分布函数,该概率分布函数是多元高斯函数,ωi是其权重,公式如下:
(7)
此外,定义特征xt由第i个高斯分布生成的概率为:
(8)
根据上述公式,对公式(5)求导,其偏导数即可作为编码后的特征向量:
(9)
式中,i表示GMM的第i个成分,d表示特征xt的第d维.因偏导计算涉及每个成分和特征的每个维度,所以UX的维度是(2D+1)*N-1.偏导计算公式如下:
(10)
(11)
(12)
引入3个Fisher矩阵对其归一化:
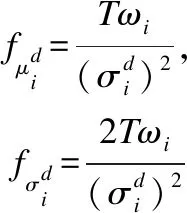
(13)
归一化后的特征向量Fisher Vector为:
(14)
经过不同Gaussians数量编码后的特征在分类效果上相对稳定,小数量Gaussians的编码即可得到稳定特征,非常适合于简单的线性核分类器,进一步降低样本分类的计算时间.同时在编码过程中一方面通过金子塔模型提取空间特征信息、编码特征的L2 Normalization和Power normalization提升Fisher编码效果[17],另一方面有效的特征降维和白化,同样能够明显提升类分类精确度[18].
3.2 稠密特征编码的特征提取算法
提取遥感图像不同尺度下的稠密特征,对其映射变换并进行主成分降维和白化,形成低维度的非压缩特征.在此之上利用Fisher编码压缩量化,形成紧凑的编码特征,最后将其归一化作为线性支持向量机的输入,完成遥感影像的场景分类.算法流程如图2所示.

图2 算法流程图Fig.2 Algorithm flow chart
4 实 验
4.1 实验数据集
为了验证本文方法的有效性,本实验在3个通用的遥感数据集上进行测试分析.第1个数据集为UC Merced Land Use Dataset[19],该数据集于2010年发布,每张图片像素大小为256×256,21类不同的遥感场景,每一类100张,共计2100张.第2个数据集为WHU-RS19 Data Set[20],该数据集由武汉大学Yang等人提供,整个数据集包含19类场景,每一类约为50张,每个图像尺寸为600×600,总共1005张.第3个数据集是NWPU-RESISC45数据集[21],于2017年发布,包含飞机、机场、棒球场等45个场景类别,每个场景类别包含700幅大小为256×256的图像,共包含31500幅遥感图像,场景类别丰富,类内多样性和类间相似性较高,对遥感图像场景分类方法具有更高的挑战性.对于以上3个数据集每类场景分别随机选取50%的图像作为训练数据集,剩余的图像作为测试数据集,且数据集未通过旋转、缩放、移位、翻转等手段进行数据增强.
这里分别将本文算法(DRFV)与传统特征编码方法BOW,BOW+SPM,BOW+PCA,VLAD,也与深度学习的Alexnet[22],VGG16[21],INceptionresnetv2[23]方法做了对比.为保证实验的可靠性,每一种算法随机进行10次.深度学习方法设置训练周期5,学习率0.0003,验证频率10.试验硬件环境为:Xeon(R)CPU Gold-6128;软件环境为Matlab 2019a.
4.2 实验结果与分析
4.2.1 Gaussians数量对于精确度的影响分析
虽然不同的GMM数量所带来的分类效果略有不同,但小数量的Gaussians即可得到较为稳定特征,一方面小数量GMM可以降低特征维度,另一方面整个算法减少参数选择调优的过程.实验中我们采用32-1024间6类Gaussians数量来编码,表1显示了不同Gaussians数量的分类效果,在不同的数据集中,随着高斯模型数量的增加,分类精度有着不同程度的提高,但基本在256左右趋于稳定,当Gaussians数量提高至512时,3个数据集分类精度平均仅提高0.63%,而在增加至1024,UCM数据集的分类精度反而下降,WHU和NWPU数据集的分类精度也没有明显增加.同时Fisher编码的特征维度是与Gaussians数量息息相关的,过为精细的特征,在数据样本有限的情况下,反而容易引起不同图像间的混淆.

表1 不同Gaussians数量的分类精确度Table 1 Classification accuracy of different Gaussians numbers
4.2.2 主成分分量对于分类的影响
众多文献都对主成分分量对于检索或分类的影响进行了研究[24-26],其中SáNCHEZ[26]在PASCAL VOC 2007数据集中验证了不同维度特征对于提高Fisher编码分类准确度的有效性.鉴于遥感图像不同于普通图像,这里我们分别以图1的前两幅图像为例,对其进行了主成分分量的贡献度分析,并在3个实验集中,对不同维度PCA特征的分类精度做了验证,如图3所示,可见遥感图像前50维的特征分量贡献度已经超过90%,结合3个实验集中不同维度特征的分类精度可知,主成分分量在60-80左右时整体的分类精度已经趋于稳定,分量的继续增加并没有带来分类精确度质的提升.因此,充分考虑在不同数据集图像中实现较高的贡献度和分类精度,我们的分类实验采用80维特征.

图3 不同主成分分量的分类精确度Fig.3 Classification accuracy of different principal components
4.2.3 运行时间对比
算法的时效性也是决定能否在大规模遥感图像分类广泛应用的重要因素.虽然深度学习在精度上略优于编码算法,但是高昂的计算成本使得时间复杂度较大.由于计算时间是与数据集中图像数量和分辨率成正比,所以这里我们仅选用UC Merced数据集为代表,在没有GPU加速和并行优化处理的情况下,我们分别使用30%和50%作为训练样本比较不同算法的时间复杂度.深度学习方法中VGG16和InceptionResNetv2,30%训练样本耗时近10000秒,50%训练样本InceptionResNetv2高达25000秒,虽然在3种深度学习方法中Alexnet耗时最短,但也要1200秒左右,且都随着训练样本的增加,计算时间增幅较大.本文算法则对两个训练集上时间相差不多,均为500秒左右,运算时间与其他编码算法相近.

表2 不同算法在UC Merced 中运算时间(单位:秒)Table 2 Operation time of different algorithms in UC Merced
4.2.4 分类精度对比
这里分别在3个数据集中进行分类精度对比.本文采用平均分类精度、Kappa系数、混淆矩阵和运算箱型图评价场景分类性能.总体分类精度的定义为:
(15)
式中,N代表总体样本数,Z代表所有分类正确的样本数.
混淆矩阵用于定量评估各类之间的混淆程度,矩阵的行和列分别代表真实和预测场景,矩阵中任意元素xij代表将第i种场景预测为第j种场景类别的图像数:
Kappa系数由混淆矩阵计算得:
(16)
式中,N代表总体样本数,K代表类别数,xij是混淆矩阵的对角元素,ai是混淆矩阵第i行元素总和,bi是混淆矩阵第i列元素总和.
表3显示了不同算法的平均分类精度和Kappa值,在3个数据集中,本文算法的平均分类精确度远远超出传统BOW系列算法和VLAD,尤其是在样本规模较大的NWPU数据集中,超出BOW系列接近40%,超出VLAD近20%左右.与深度学习算法相比,在UCM中平均分类精度与其他3个深度学习算法分别相差1.26%、3.56%和1.06%,在WHU数据集,本文算法则超过了深度学习算法,达到最优分类精度91.12%.在NWPU数据集,限于样本数量和硬件计算能力,InceptionresnetV2已无法在有效时间算出结果,VGG16在众多算法中,分类精度最高,达到89.64%,本文算法则与Alexnet相近,达到了81.06%.因此,综合不同数据集的平均分类效果来看,VGG16效果最好,其次是Alexnet和本文算法,二者仅相差0.74%,最后是其他算法.InceptionresnetV2对计算环境要求苛刻,限制了其在大数据集的应用范围.

表3 不同数据集平均分类精度和Kappa值Table 3 Average classification accuracy and Kappa value of different data sets
多次随机实验的稳定性如图4所示,在UCM和WHU数据集Alexnet和DRFV整体效果表现稳定,最大值都在90%以上.VGG16不同实验结果偏离较大,其中WHU数据集的分类精度最大最小值相差近10%,且平均精度不高.InResNetV2表现一般,同样存在分类稳定性的问题,还存在两个异常偏低值.NWPU数据集中,VGG16和本文算法表现稳定,Alexnet不同的实验有一定程度的偏差.其他算法在3个数据集的实验表现一般,个别存在异常偏低值.因此,从多次随机实验结果的稳定角度来看,本文算法和Alexnet是明显优于其他算法的.
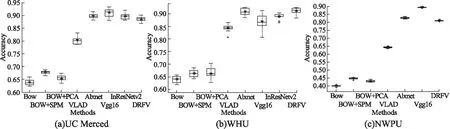
图4 不同算法在不同数据集上的分类精度箱型图Fig.4 Box graph of classification accuracy for different algorithms on different data sets
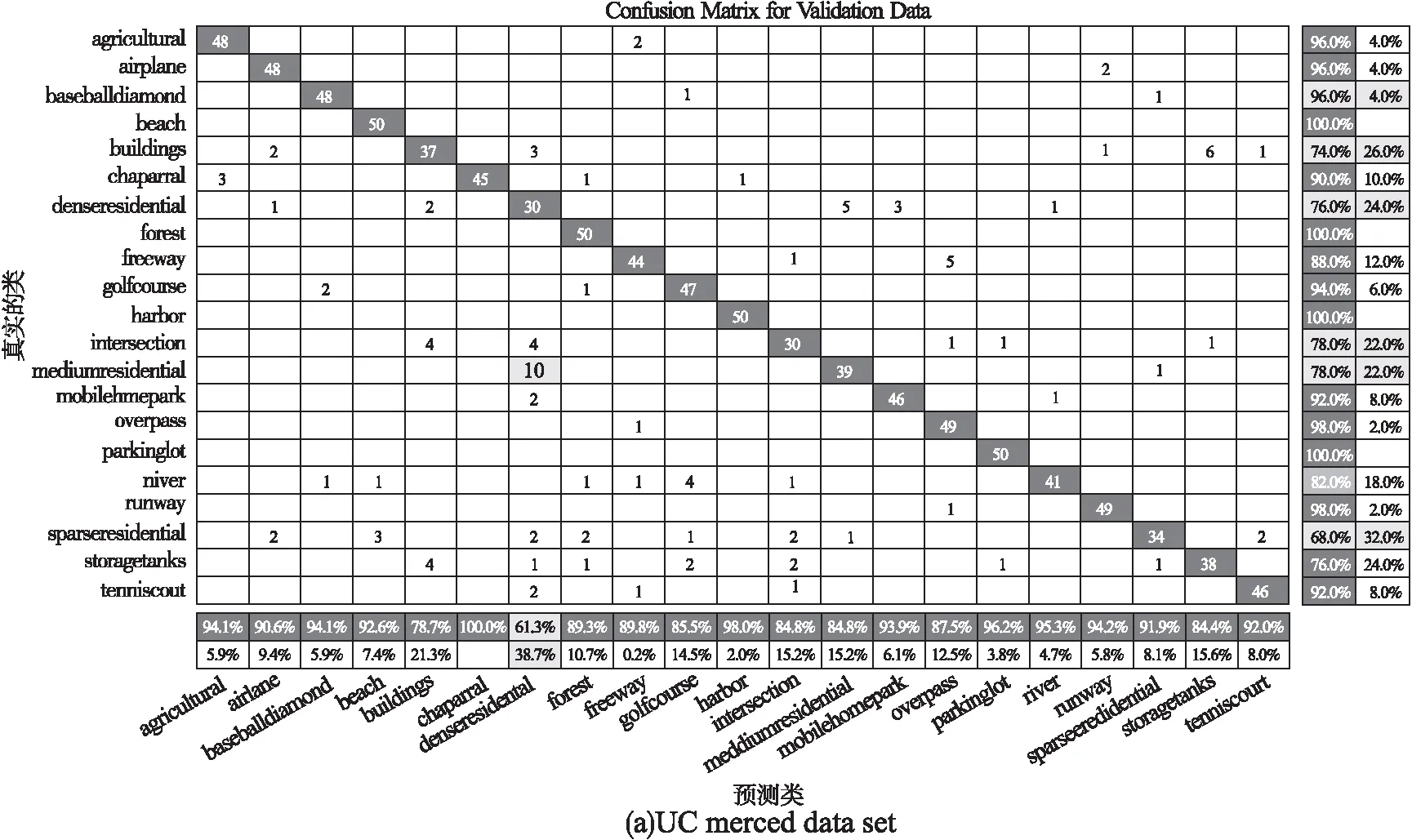
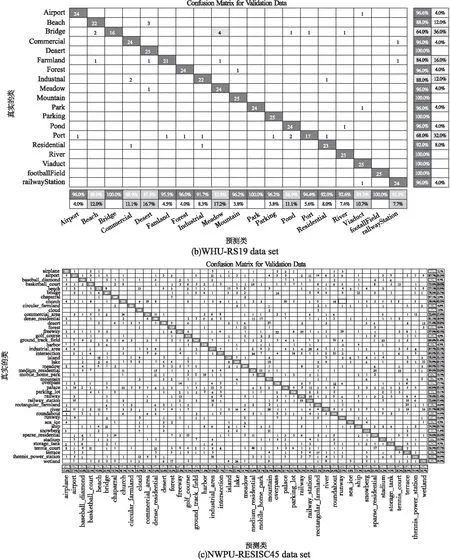
图5 本文算法在不同数据集的混淆矩阵Fig.5 Confusion matrix of the algorithm in this paper on different data sets
图5显示了本文算法在3个数据集上的混淆矩阵,总体来看各类场景的分类准确率和召回率效果良好.但由于部分场景与其他场景有着高度的相似性,导致个别类召回率偏低.如UCM数据集的Bulidings、SparseResidential与DenseResidential、Forest等,WHU数据集Bridge、Port与Medow、Airport等,NWPU数据集的Palace、River、Tennis_court与Mountain、MediumResidential等,这几类场景间的高度相似,容易造成分类时的混淆.
5 结 论
本文提出了一种低维度稠密特征编码的场景分类算法,用于实现遥感图像分类过程中计算复杂度和精确度之间的有效平衡.算法优势在于通过一系列的尺度变换,特征空间映射、主成分降维和特征编码,将中低层语义特征有效的结合在一起,既保持了中低层语义特征的高效稳定,也具有与高层语义特征相近的分类精度,实现在普通运算环境中遥感场景的高效准确分类.
