基于深度前编码卷积网络的汉越语音翻译方法
2021-04-12许树理余正涛王振晗梁仁凤
王 剑,许树理,余正涛,王振晗,梁仁凤
(昆明理工大学 信息工程与自动化学院,昆明 650500) (昆明理工大学 云南省人工智能重点实验室,昆明 650500)
1 引 言
随着中国和“一带一路”沿线国家的交流日益密切,在会议演讲、视频直播等应用场景现有文本到文本的机器翻译技术[1,2]已不能满足实际需求.因此出现了语音翻译技术,通过语音翻译能够将源语言的语音转化为目标语言的文本,缓解不同语言之间存在的交流障碍.
目前语音翻译主要有两种实现形式,一种是通过语音识别[3,4]和机器翻译构建级联系统,先将源语言语音转录为源语言文本再进行翻译,另一种是通过端到端的语音翻译技术,直接将源语言的语音转化为目标语言的文本,实现语音到文本的翻译.在汉越语音翻译中,语料的稀缺性加剧了不同系统间的错误传递,训练可用的级联系统十分困难[5],因此使用端到端系统进行语音翻译,更能满足实际应用需求,也是当前研究的热点.
端到端语音翻译系统一般由序列到序列模型实现[6-8],与基于纯粹文本的机器翻译不同,源语言语音会以频谱图的形式作为模型输入,频谱图由时域和频域两个维度的信息组成,有效地提取频谱图中的时频特征,成为提升模型质量的重要手段.另外,由于模型输入输出跨越模态,在表征相同语义时,音频序列远长于文本序列,往往多个音频帧对应一个文本标识.音频序列的这个特点,在基于多头注意力机制的Transformer的编码的过程中[9],会由于注意力计算的全局性,导致注意力被稀释在过长的序列中,分散模型对音频序列中重要的短距离依赖应有的注意,产生局部依赖建模能力不足的问题[10].同时,音频序列较长的特性还会造成模型参数规模过大,占用资源过多影响模型的训练速度.针对这些问题,本文提出基于深度前编码卷积网络的Transformer(Deep Residual Convolutional Transformer),利用卷积神经网络在音频下采样及局部特征提取的优势,增强模型对音频频谱时域和频域的综合表征能力及效率,辅助Transformer对于局部依赖的建模,同时引入距离惩罚机制强迫Transformer偏袒局部依赖等方式,提高了语音翻译的质量.
2 相关工作
近年来,国内外许多学者针对语音翻译相关技术开展了深入的研究,并取得了一定进展.其中,语音到文本的语料库是语音翻译的基础,在语音语料库构建方面,Bérard等人[8,11]利用语音合成技术生成语音语料的方式,使用法英双语语料库BTEC构建了法语语音到英语文本的语音语料库[8],并于2018年通过将英文有声书和其法语译文对齐的方式,构建了增强的LibriSpeech英法语音翻译语料库[11],这为语音翻译研究提供了支持,也为构建汉越语料库提供了一种思路.语音识别是级联语音翻译的基础,并且由于语音识别与语音翻译任务相似,同样是将音频序列并转化为文本的过程,语音识别的相关方法在端到端语音翻译有很多可以借鉴的地方,在语音识别方法研究方面,Chorowski等人[12]提出基于注意力机制的语音识别方法,使用基于注意力的循环序列生成器对音频序列进行编码解码,并通过卷积注意力机制进行注意力权重计算,使模型在解码时避免重复注意到相同特征,进而取得了良好的效果.Zhang等[13]提出基于深度卷积神经网络的语音识别方法,通过堆叠多层卷积神经网络、卷积长短时记忆网络及胶囊网络,增强编码器的表达能力,降低了语音识别的词错率.基于以上研究工作的支撑,在语音翻译模型研究方面,2016年Bérard等人[8]在Chorowski等人[12]提出的语音识别模型的基础上,使用层级LSTM编码器与带有卷积注意力机制的解码器,实现了端到端的语音到文本翻译,在与Google语音识别和统计机器翻译构成的级联翻译系统对比后,证明端到端的语音翻译系统能够获得相近的性能.2017年Weiss等人[14]提出一种基于深度循环神经网络的语音翻译方法,通过加深解码器神经网络层数,并采用多任务学习方法训练语音翻译模型,使端到端的语音翻译性能超过以往级联方式构建的语音翻译系统.2018年Bansal等人[5],在Weiss等人[14]的基础上,通过降低输入频谱的维度,缩减模型参数规模,使用词级文本解码器等方式,使模型在单张显卡的计算资源以及小规模数据集的条件下,表现出良好的性能.2019年Gangi等人[10]将Transformer模型引入语音翻译,通过使用对数距离惩罚机制,使模型偏袒编码序列中的局部依赖关系,取得了很好的效果.
3 模 型
端到端语音翻译技术取得了快速的进展,但在相关工作中,模型在编码阶段前,仅对音频进行下采样缓解编码器的计算压力[15],忽略了在编码阶段前对频谱图进行深层次的时频信息处理.另外,在使用Transformer构建语音翻译模型时,其全局注意力机制的计算方式会对局部依赖建模造成阻碍[10].卷积神经网络利用较小的卷积核,在二维的频谱图上进行卷积操作的方式,在频谱图中的时频信息提取以及局部依赖建模方面具有独特的优势[13].因此,本文基于深度卷积网络,增加音频深度前编码过程,在音频下采样及局部特征提取时,增强模型对音频频谱时域和频域的综合表征能力,同时引入距离惩罚机制强迫Transformer偏袒局部依赖等方式,解决局部依赖建模能力不足的问题,构建基于深度前编码卷积网络的汉越语音翻译模型结构如图1所示.
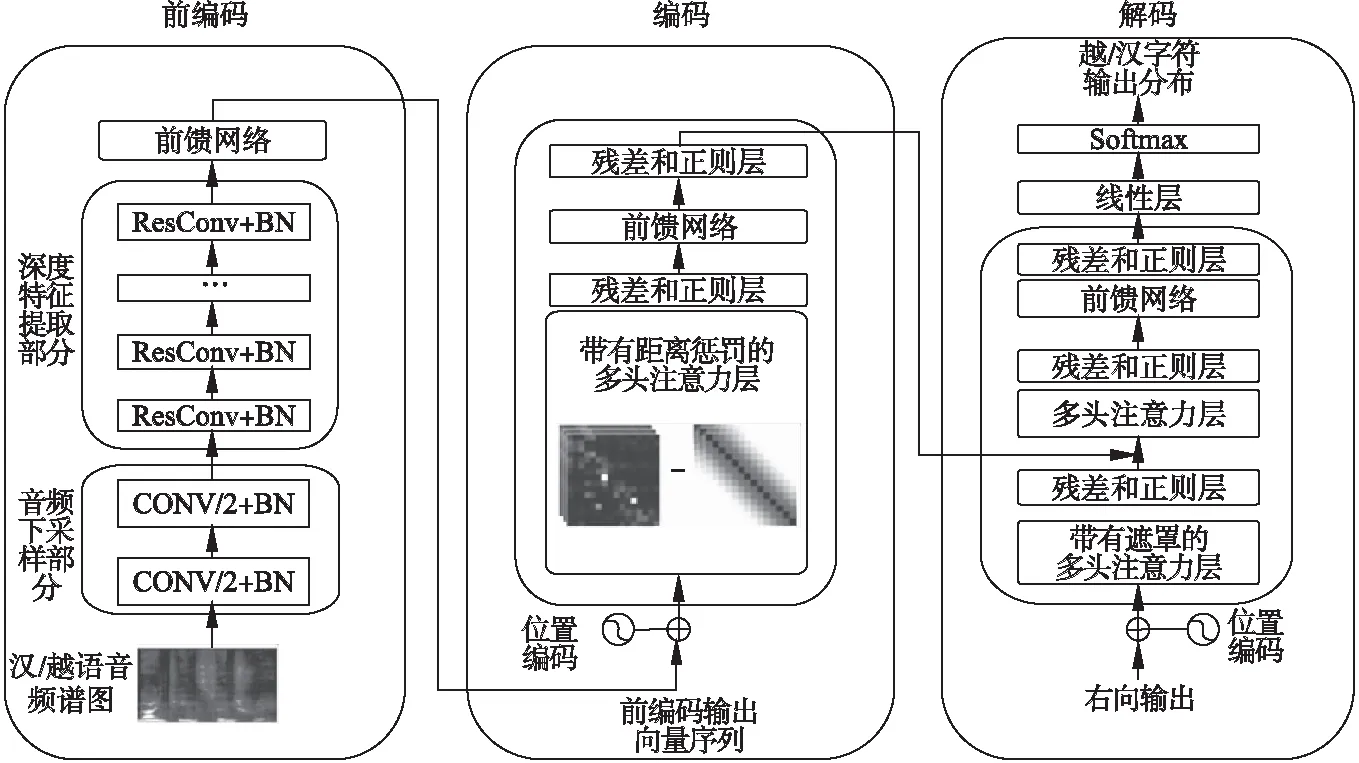
图1 模型结构图Fig.1 Architecture of the model
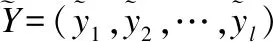
(1)
3.1 前编码
X′=BatchNorm(W*X)+X
(2)
3.2 编码与解码
(3)
Transformer通过多头注意力机制MHA(Q,K,V),将输入映射到h个不同子空间进行注意力计算.通过堆叠Nc层多头注意力子层,并在每个子层间引入残差和层规范化提升模型的泛化能力,对输入序列内部的依赖关系Hn=MHA(Hn-1,Hn-1,Hn-1)进行建模,其中H0为经过Position Embedding处理的前编码输出向量,HNc为编码器输出.
本文在编码器中使用对数距离惩罚机制对注意力函数中的相似性得分进行重新计算,使得编码器偏袒针对局部依赖的特征提取,将公式(3)改写为:
(4)
其中,D是以di,j为元素的距离矩阵,其中di,j=|i-j|,πlog是距离惩罚函数,如公式(5)所示:
(5)
在解码端,通过两组多头注意力,将目标序列内部的依赖关系Fn=MHA(Sn-1,Sn-1,Sn-1)和目标语言端与编码端的依赖关系Gn=MHA(F,HNc,HNc)进行建模,经全连接网络变换得到Sn=FFN(Gn)其中S0为初始目标端字符向量.将解码器顶层隐状态SNc映射到目标端词表空间,经SoftMax得到目标端词表上的概率分布作为模型输出分布,其中当音频输入为汉语时解码器生成字母级的越南语输出分布,当音频输入为越南语时解码器生成字符级的汉语输出分布.
4 实验与结果分析
4.1 数据准备
为了进行汉越语音翻译的对比试验,构建了13万汉越双语语音到文本语料库,具体设置见表1.
如表1所示,其中训练集包含12万对,验证集和测试集各包含5000对.由于语音翻译语料获取的难度,本文通过Google语音合成服务,将13万汉越文本转化为约220小时的汉越语音,包含男声和女声各两种音色,通过与音频文本对齐构建了汉越语音翻译语料库.在以上语料库中,语音语料均通过预处理,转化为步长为10毫秒,窗口大小为25毫秒,维度为40的梅尔倒频谱filter-banks频谱图.
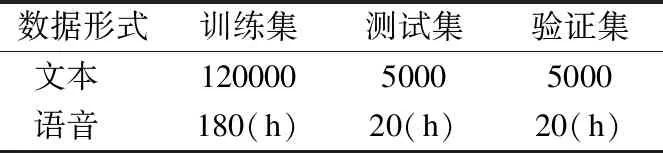
表1 实验数据规模Table 1 Scaleofexperimentdata
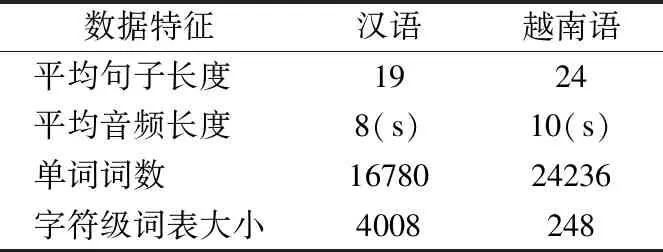
表2 实验数据特征Table 2 Featureofexperimentdata
为说明本文构建语料库的一般性,现对汉越双语构建的文本及合成音频进行分析,具体数据特征见表2.
汉越双语的在本语料库中的平均句子长度分别为19个词和24个词,生成的音频平均长度分别为8秒和10秒,文本中分别包含16780个词和24236个词.另外,由于本文采用了字符级的文本解码器,所以构建了以字符为单元的词表,其中汉语为字符文字而越南语字母文字,因此由汉语语料及越南语语料生成的词表大小相差很大,其中越南语的词表大小为248,汉语词表大小为4008.
4.2 实验环境及参数设置
本文使用PyTorch1.2搭建模型,使用标签平滑交叉熵损失作为目标函数,标签平滑率为0.1,梯度裁剪为20,编解码隐藏层向量为768维.训练时,通过Adam优化器进行优化,通过inverse sqrt动态调整学习率.
4.3 基线模型
为了证明提出方法的效果,选取以下几种最新方法进行对比实验:
1)级联系统,通过语音识别系统将源语言语音识别为源语言文本,然后再将源语言文本通过文本机器翻译模型翻译为目标语言文本,其中语音识别系统和文本机器翻译均基于Transformer在本文数据集上进行训练.
2)Bérard等人[8]提出的基于带有跨度的卷积神经网络进行下采样,然后通过BiLSTM进行序列建模的端到端语音翻译系统(以下简称CNN+BiLSTM).
4.4 实验与结果分析
为了验证本文方法的有效性,采用不同方法在构建的数据集上进行对比实验,不同方法语音翻译实验结果见表3.
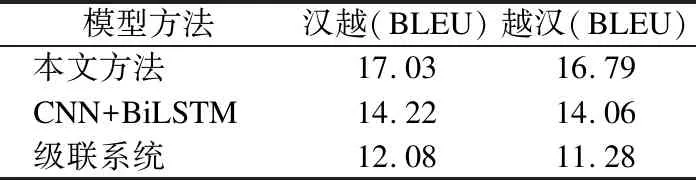
表3 不同方法的语音翻译实验结果Table 3 Results of different models
从表3数据可以看出,本文提出的方法与级联系统相比,不存在错误传播的问题,由于不需要大量语音识别语料训练语音识别器,本文方法采用的端到端网络架构更适合汉越双语这样的资源稀缺性的语言对,实验结果表现出了相较级联系统性能提升显著.相比CNN+BiLSTM,由于LSTM使用细胞状态向量表征上下文信息并带有一定的遗忘机制,其对于局部依赖的建模要优于进行全局相似度计算的Transformer,但是由于本文方法采用了深层次的前编码卷积网络和基于距离惩罚的Transformer网络,显著提高了模型对于局部依赖的建模能力以及对于音频频谱图的时频信息提取能力,使得Transformer对于序列的编解码能力获得了充分的发挥,实验结果证明本文方法相较CNN+BiLSTM在汉越和越汉语音翻译上性能均得到了19%的提高.
为验证提出模型各部分的有效性,分别将各层消去进行比较实验,得到对比实验结果见表4.

表4 消融实验结果Table 4 Results of ablation experiment
分析表4可知,本文方法的各个部分对于语音翻译具有实际作用,不使用前编码深度特征提取时,汉-越、越-汉语音翻译BLEU值均有显著降低,由此可见在前编码阶段采用更深层次的卷积模型对音频频谱图进行深层特征提取,对于后期Transformer进行序列建模的质量提升有明显效果.不使用距离惩罚时,由于Transformer基于全局的相似度计算存在的局部依赖建模问题阻碍了模型性能的发挥,导致模型性能降低了约1个BLEU值.由此可见,本文提出的方法在帮助Transformer进行更好的序列表征以及局部依赖建模方面具有良好的效果.
为验证卷积网络深度对于模型性能的影响,进行了不同前编码层次性能对比实验,实验结果见表5.

表5 前编码卷积网络深度性能对比Table 5 Results of different pre-encoder
从表5数据可以看出,前编码深度特征提取部分层数不同对模型会产生一定的影响,其中Conv/2代表跨度为2的卷积层,实验发现通过堆叠2层步长为2,4层步长为1的卷积层模型性能表现最佳,这可能由于第2组前编码结构的感受野,恰好可以使得前编码输出的单个表征向量的信息完整覆盖频谱图所有维度.而第3、4组前编码结构可能存在过拟合的问题导致未取得最佳性能.由此可见,前编码深度特征提取部分对于音频频谱图时域频域综合特征的提取,可以帮助模型得到更好的音频序列时频表征,进而提高模型性能.
5 总 结
本文基于深度前编码卷积网络和Transformer的端到端语音翻译模型,提出了在编码阶段前对音频频谱利用卷积神经网络进行深度处理,可以辅助Transformer对于频谱图中时频信息和局部依赖的建模.实验结果也证明了提出方法的有效性,可以有效提升模型效果.深度前编码对语音翻译有很好的支撑作用.下一步研究中,拟针对汉越语音翻译平行语料获取难度较大的问题,结合语音识别语料库相对丰富的特点,探索基于语音识别与机器翻译多任务联合学习方法,利用语音识别相关模型和语料,增强语音翻译模型性能.
