不同特征集的红葡萄酒品质计算机预测分析研究
2021-04-10姚娅川
杨 洋,姚娅川,郑 婷
(1.四川轻化工大学人工智能四川省重点实验室,四川宜宾 644000;2.四川轻化工大学自动化与信息工程学院,四川宜宾 644000)
葡萄酒行业处在飞速发展的阶段,人们对葡萄酒的品质越来越重视[1]。不同类型的葡萄酒中的大多数化学物质是一致的,但是不同类型的葡萄酒中化学物质的含量却有不一样的浓度。随着葡萄酒相关检测技术的不断改善,对不同的葡萄酒进行分类以确保其质量就显得尤为重要。
人们使用了不同的机器学习方法和特征选择技术对葡萄酒数据集进行处理。Er和Atasoy[2]提出了使用支持向量机(SVM)、随机森林(Random forest)和k-近邻(KNN)3种不同分类器对葡萄酒质量进行分类。其中随机森林算法对葡萄酒的分类得到了很好的效果。Chen 等[3]提出了利用人的品评来预测葡萄酒级别的方法。他们使用关联规则算法来处理评论和预测葡萄酒等级,发现在预测等级时,准确率为85.25%。Appalasamy等[4]提出了理化测试数据预测葡萄酒质量的方法。指出在生产过程中,分类方法有助于提高葡萄酒的质量。Beltran等[5]提出了香气色谱对葡萄酒进行分类的方法,利用PCA 降维,再用小波变换特征提取和分类器特征提取,如神经网络,线性判别分析和SVM,发现SVM和小波变换执行比其他分类器的效果要好。Thakkar 等[6]应用层次分析法(AHP)先对属性进行排序,再用支持向量机分类器和随机森林这两种分类器,发现应用随机森林的准确率为70.33 %,应用支持向量机的准确率为66.54%。Reddy 和Govindarajulu[7]应用了以用户为中心的集群方法来推荐该产品。他们将红葡萄酒数据集进行调查,在理论的基础上对属性进行了基础的分类,然后利用高斯分布的方法对属性进行权重分配,根据用户的偏好来判断质量的好坏。以上研究促使我们尝试不同的特征选择算法和不同的分类器来比较性能指标。还提出了遗传算法和SA 的特征选择方法,并利用Part、Bagging、C5.0、Random-forest、支持向量机、LDA、Naive Bayes 等不同的分类器对红葡萄酒质量进行预测。
1 方法流程图(图1)
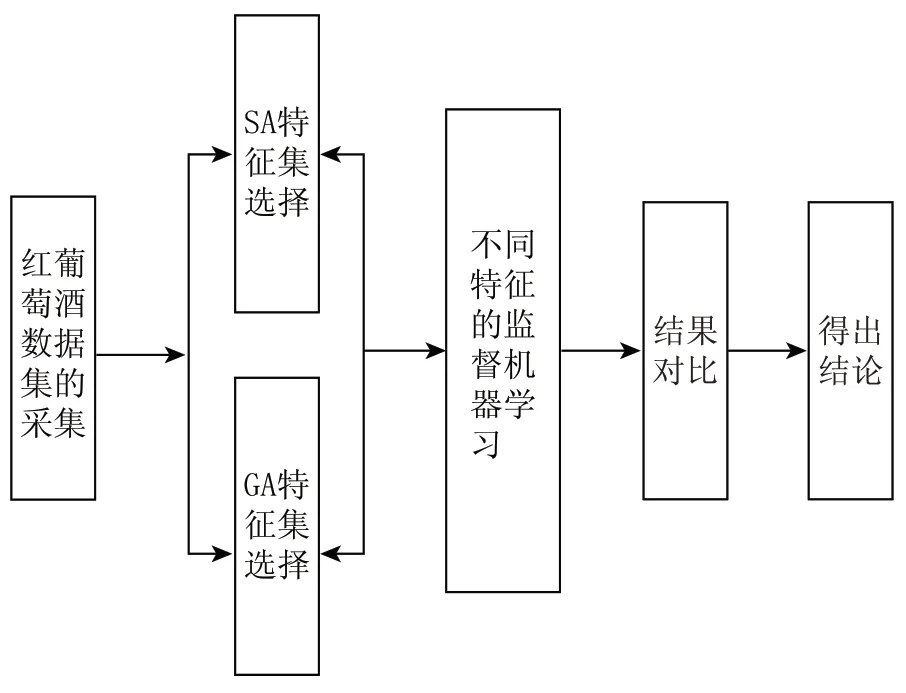
图1 方法流程图
1.1 数据特征选择
本文运用遗传算法(GA)的特征集进行特征选择。其中葡萄酒数据集在UCI 的数据库中是公开化的。这个数据集包括物理化学变量和感觉变量,总共有12 个属性[8]。Pledsoe 首先提出了一种被称为遗传算法的自适应优化算法,随之,Holland 从达尔文的进化论中得到灵感,从数学上提出了遗传算法。初始化是利用染色体的种群随机进行的。染色体的质量是根据一个预处理的适应度函数来决定的,适应度越高的染色体就会被用来产生后代。遗传操作如变异和交叉操作就会产生后代。在这个过程中,染色体互相竞争,最适者最终存活下来。经过一系列的迭代计算,得到了最优解[9-10]。同时也使用模拟退火的特征集进行特征选择。模拟退火是广泛应用的组合优化方法,也是最流行的搜索算法之一。该方法利用概率技术寻找局部最优解,最终找到更好的解[11]。模拟退火仿真算法步骤:它根据类的数量运行,如果类的数量为n,则运行n 次。在每一次运行中,找到第j 个类的特征子集。在计算当前字符串时,所有第j 个类模式都会被纳入一个类,其他模式属于另一个类。这个过程有助于给出将模式划分为属于类j 或不属于类j 的特征[12]。利用模拟退火算法和遗传算法对特征进行选择之后,再将数据集导入到不同的分类器,然后对分类器的性能参数进行比较。
1.2 性能分类的指标
用于比较分类器性能和验证的标准有:敏感性、阳性预测值(PPV)、精确度、特异性、阴性预测值(NPV)。灵敏性是指真阳性与真阳性和假阴性总和的比值。特异性是指真阴性与假阳性和真阴性和的比值。在本文中,使用了PPV 和NPV 两种指标来检验某一种葡萄酒是否存在。其中PPV 表示在测试结果为阳性的情况下某一种葡萄酒出现的概率,NPV则表示在测试结果为阴性的情况下某一种葡萄酒不出现的概率[13]。准确度的含义就是正确预测的次数与总预测次数的比值。
2 结果对比与分析
采用训练数据和测试数据两组数据。先在训练数据的基础上对分类器进行训练,然后对测试数据进行分类器的能力预测。因此,每个分类器都能够显示基于测试数据的所有性能指标,如PPV、敏感性、特异性、精确度和NPV。我们将已有的一些分类技术分别应用在遗传算法的特征集和SA 的特征集,从而得到每个分类器的性能数据。再根据GA和SA集分离每个性能数据,并绘制柱图。最后分离的性能数据的结果如图2、图3、图4、图5 和图6所示。
2.1 红葡萄酒精确度的比较(图2)
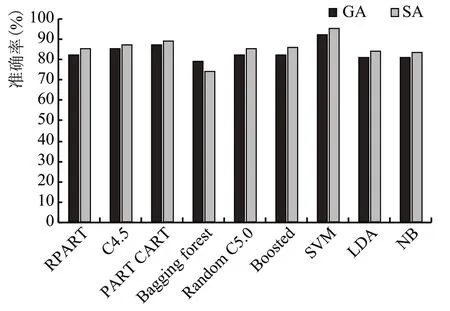
图2 红葡萄酒数据的精确度比较
从图2 可以看出,在所有的分类器中,SVM 分类器的准确率为最高的。使用SA 的特征集的效果好于SA 的特征集。SA 特征集的SVM 分类器的准确率为95.4%。
2.2 红葡萄酒敏感性的比较(图3)
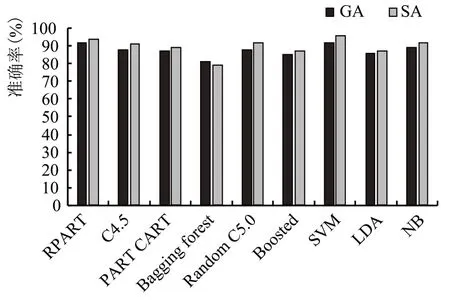
图3 红葡萄酒数据的敏感性比较
从图3 可以看出,SVM 分类器的灵敏性最高,使用SA 特征集的效果优于GA 特征集,SA 的特征集的SVM分类器灵敏性为96.3%。
2.3 红葡萄酒特异性的比较(图4)
从图4 可以看出,SVM 分类器的特异性相比其他分类器的特异性要大。使用SA 的特征集性能更好。SA 特征集SVM 分类器的特异性准确率为98.5%。
2.4 红葡萄酒PPV的比较(图5)
从图5 可以看出,所有分类器中SVM 分类器的PPV 最高,使用SA 的特征集效果更优,SA 特征集SVM分类器的PPV为98.9%。
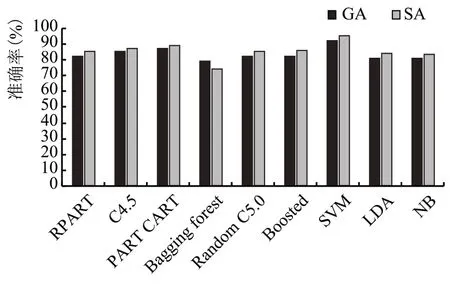
图4 红葡萄酒数据的特异性比较
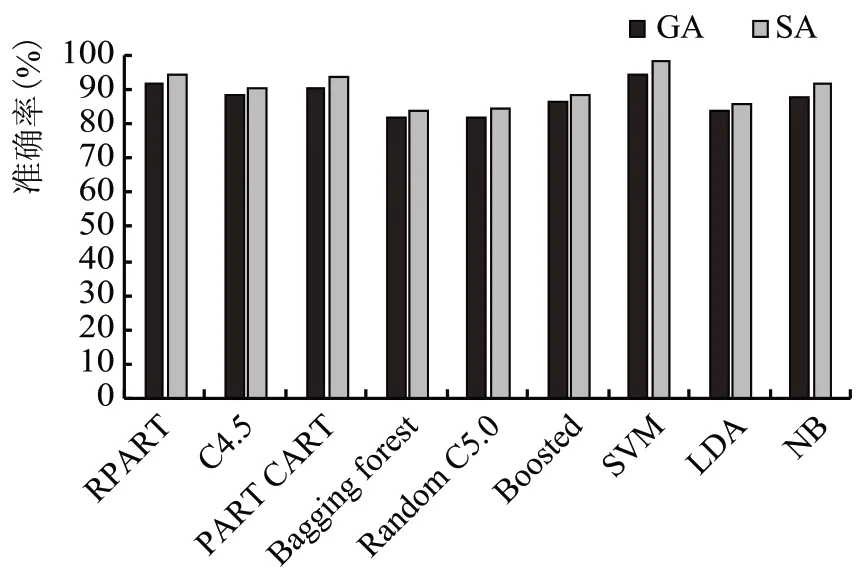
图5 红葡萄酒数据PPV的比较
2.5 红葡萄酒的NPV比较(图6)
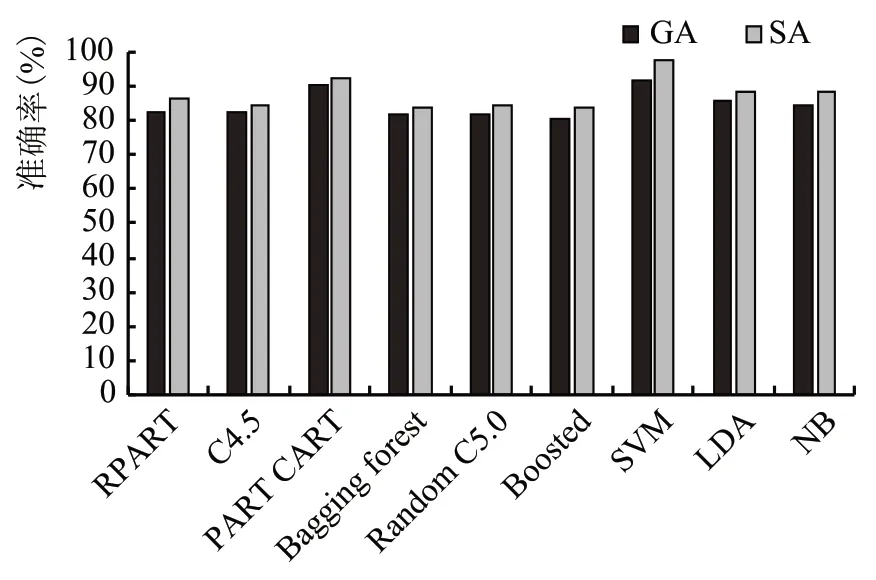
图6 红葡萄酒的NPV比较
由图6 可以看出,SVM 分类器的NPV 最大。SA 的特征集性能更好。SA 特征集的SVM 分类器的NPV为0.9812。
通过上面的5 个显基于两个不同特征集的指标参数对红葡萄酒的性能的比较图分析得知,SVM 分类器对这两种不同算法的数据集都有较好的分类效果。特别是在SA 的特征集中的总体性能更好。虽然从结果中很容易看出SA 算法的特征选择效果更好,但事实上可能还有其他的不同的数据集,这是以后需要作进一步研究的内容。不过,根据现有研究可以得出,支持向量机分类器的分类效果是要优于其他分类器。
3 结论
本文主要研究了模拟退火(SA)算法和遗传(GA)算法这两种算法在特征选择中的效果,以及基于新特征集的分类器准确预测的效果,同时还比较了线性、非线性和概率分类器的性能。结果表明,SA的特征集性能优于GA特征集的总体性能,支持向量机分类器优于其他分类器,不同特征集的准确率在95.4%~98.9%之内。不过,还可以尝试其他性能指标和其他机器学习技术进行更好的比较,以更好地对葡萄酒品质进行预测。
