基于局部对抗训练的命名实体识别方法研究
2021-04-08程芃森许丽丹刘嘉勇
李 静, 程芃森, 许丽丹, 刘嘉勇
(四川大学网络空间安全学院, 成都 610065)
1 引 言
命名实体识别旨在文本数据中划分实体边界、检测实体类别,是自然语言处理任务中的基础研究之一.当前命名实体识别研究已取得很多优秀成果[1-5],但多侧重于改进模型结构与特征工程,较少关注命名实体识别数据集中边界样本混淆问题.如图1所示,边界样本混淆是指分类器通过类别标记划分类边界,在类边界的某一范围内邻近类样本交错分布的情况.混淆的边界样本比远离边界的内部样本更易识别错误,故模型正确识别边界样本的程度对整体识别性能有着至关重要的意义.
传统分类问题研究中常采用基于统计学习的样本筛选方法提高模型边界样本的学习能力.张莉等人[6]通过聚类方法分析样本离散度挑选出边界样本,剔除了对效果影响不大的冗余样本;周玉等人[7]提出了一种基于最优模糊矩阵诱导的阴影集筛选核心数据与边界数据的方法,可保证分类器的泛化能力;Chen等人[8]提出多类实例选择(Multiple Class Instances Select, MCIS)方法选出最接近边界的实例,用来提高支持向量机的边界划分速度.这些方法虽减少了冗余数据,提高识别速度,但也牺牲了原始文本数据的完整性,存在破坏文本结构,可能丢失重要特征的问题.
近年来,深度学习结合对抗训练的方式在文本处理领域表现突出,成为文本研究的新趋势.Miyato等人[9]深度学习基础上,首次在词向量层面添加扰动,用于半监督文本分类.Zhou等人[10]在词嵌入层添加扰动提升了低资源命名实体识别模型的泛化能力.这类方法虽然可以处理更庞大更复杂的特征,但也因对所有文本数据添加扰动合成对抗样本而极大增加了训练数据数量与计算代价.
为解决上述问题,本文在深度学习模型可处理更多特征的基础上,提出基于局部对抗训练的命名实体识别方法.利用对抗训练既保留原始数据特征,又以对抗攻击的方式提升模型鲁棒性与泛化能力的特点,提升模型识别混淆边界样本的能力.在困难样本挖掘思想的启发下,仅对数据中易分类错误的困难样本添加扰动,减少冗余对抗样本.实验表明,本文方法保留对抗训练效果,增强命名实体识别任务性能的同时提高了对抗样本质量.
2 相关工作
深度学习可处理更庞大复杂特征的优势,在命名实体识别领域获得了蓬勃的发展.Graves[11]提出了长短时记忆模型LSTM解决经典文本处理模型RNN的长句依赖问题.Hammerton[12]结合CRF的优点,提出的LSTM+CRF模型在命名实体任务中表现优异,F1值比基线模型提升了5%.Huang等人[13]提出的双向LSTM结构比起单向LSTM可以更好地捕捉前后文的双向语义特征,这种BiLSTM+CRF的组合在序列标注问题中表现出了极高的性能,使其逐渐成为命名实体识别中最常见的架构.
对抗训练由对抗生成网络发展而来,最初应用于提升图像处理模型的鲁棒性[14].随着具有连续特征的词向量的发展,对抗训练逐渐在文本处理任务中广泛应用.Alzantot等[15]提出了一种基于种群的优化算法,通过重复随机选择相近的目标标签类的样本,从而找到最近替换词以生成扰动.Li等[16]捕获对分类有意义的重要单词,再对这些单词添加微小扰动生成对抗样本引导深度学习分类器进行误分类.Gong等[17]采用梯度下降的方法将词向量扰动为目标类,以此提高对抗文本的质量.
困难样本挖掘思想是将数据分为简单样本与困难样本,在训练过程中选择损失值较大的错误样本送入模型再训练,以提升网络分类性能.Shrivastava等人[18]提出了一种在线困难样本挖掘(Online Hard Example Mining, OHEM)算法动态选择困难样本,用于解决图像中对象检测调参成本较高的问题.Li等人[19]考虑了训练过程不同损失分布的影响,提出根据错误分布抽样训练样本,使困难样本的再训练更有针对性.
针对命名实体识别数据集中存在边界样本混淆的问题,本文基于BiLSTM-CRF模型,结合对抗训练与困难样本的思想,筛选数据中损失值较大的困难样本,仅对这部分样本添加目标攻击扰动生成对抗样本;再将对抗样本与原始数据混合进行对抗训练,使模型充分学习类别边界周围困难样本的特征,提高命名实体识别效果.
3 局部对抗训练模型
3.1 基本概念
3.1.1 非目标与目标攻击 对抗训练是基于对抗攻击的训练方式,在训练过程中对模型进行对抗攻击从而提升模型的鲁棒性.对抗攻击按照目的的不同可分为非目标攻击与目标攻击.如图2(a)所示,非目标攻击是使对抗样本能让模型分错,不指定具体类别.如图2(b)所示,目标攻击是使生成的对抗样本被模型错分到某个特定的类别上.
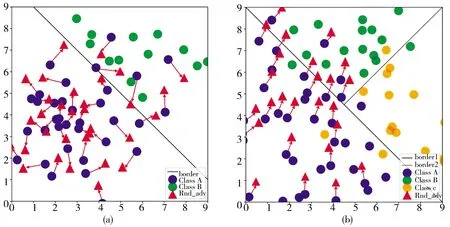
图2 非目标攻击与目标攻击对比图Fig.2 Comparison of non-target and target attack
若设原始样本集为X,ytrue为样本真实类别;ytarget为目标攻击的目标类别;F为采用的攻击方法;控制扰动大小,非目标攻击的扰动计算为
rn_adv=∈·F(X,ytrue)
(1)
目标攻击的扰动计算为
rt_adv=∈·F(X,ytarget)
(2)
根据不同攻击方式对应的对抗样本生成原则[20],非目标攻击方法生成对抗样本公式为
Xn_adv=X+rn_adv
(3)
目标攻击方法生成对抗样本公式为
Xt_adv=X-rt_adv
(4)
非目标攻击不需要计算扰动方向故而可以快速生成对抗扰动,但在攻击中成功率较低.有明确指向的目标攻击命中率更高,可以生成更多的使模型分类错误的样本.模型的反向传播机制决定了分类错误、损失较大的样本对参数权重的调整有更大的价值,故本文选择定向扰动的目标攻击方式生成对抗样本.
3.1.2 全局与局部对抗训练 从样本数据本身来说,若以样本在添加扰动后是否会被分类错误为标准,样本可分为不易被扰动的、处于类边界内部的简单样本,与容易被扰动的、位于边界周围或远离正确类边界的困难样本.如图3(a)所示,不进行样本筛选,直接对所有原始样本添加对抗扰动的训练为全局对抗训练;如图3(b)所示,剔除简单样本,仅对困难样本添加扰动的训练为局部对抗训练.
设Xadv为对抗样本集,ATK为生成对抗样本的攻击方法;g,l作为下标分别表示全局与局部的方法.全局对抗训练中所有训练样本集合可表示为
Xg=X+Xg_adv
(5)
其中,Xg_adv=ATKg(X).设Hard为困难样本筛选方法,从原始数据中筛选出困难样本,再对困难样本添加扰动生成对抗样本,局部对抗样本集可表示为
Xl_adv=ATKl(Hard(X))
(6)
局部对抗训练中的所有训练样本集合为
Xl=X+Xl_adv
(7)
对抗训练过程中,如果直接对所有样本添加扰动,大量简单样本添加扰动后仍位于类别内部,这些处于类别内部的对抗样本因对反向传播没有贡献而变得冗余.因此,仅对筛选出的困难样本添加扰动生成对抗样本用于梯度回传,可避免生成大量冗余对抗样本,极大减少训练的计算量.
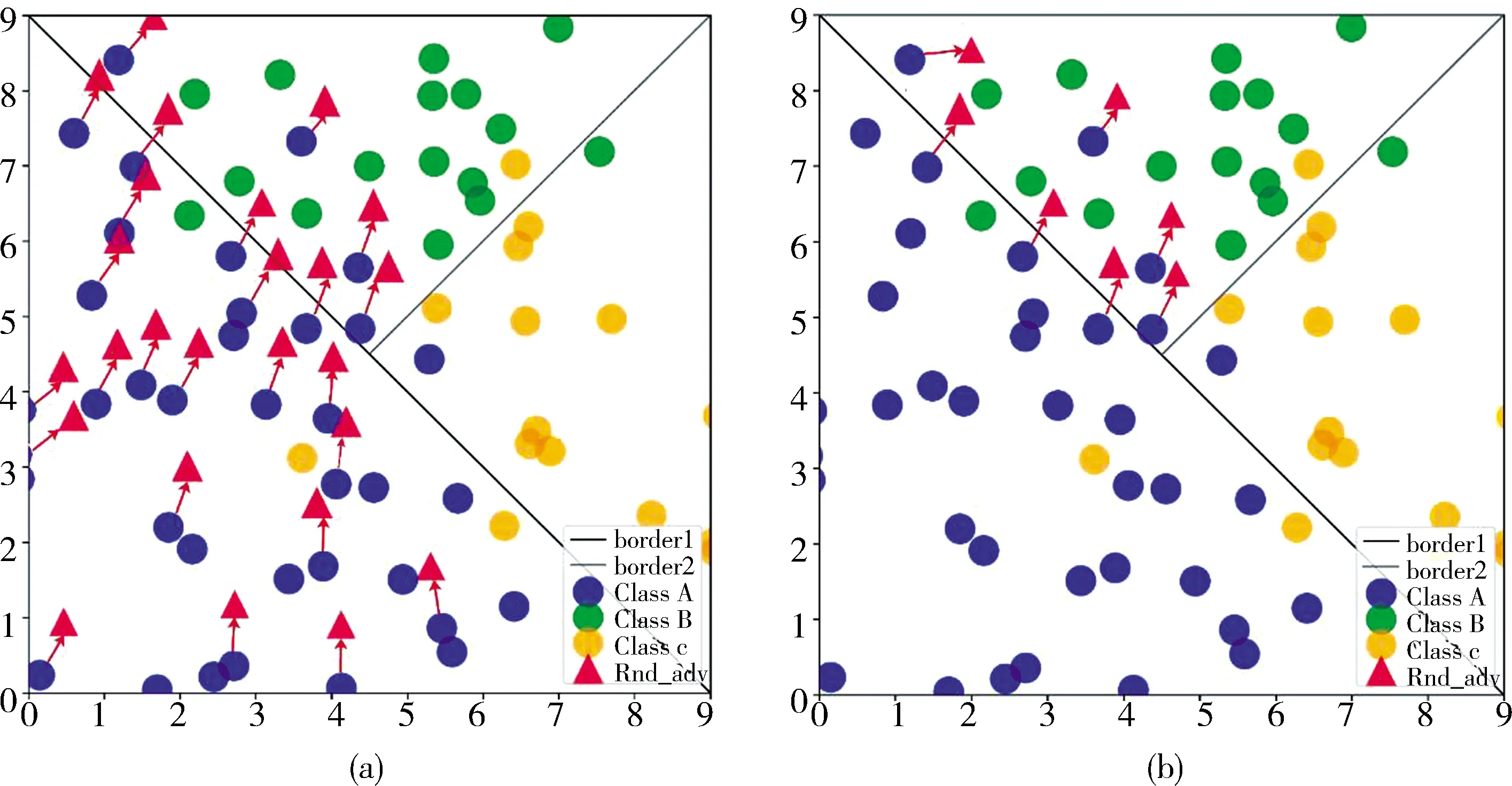
图3 全局对抗训练与局部对抗训练对比图Fig.3 Comparison of global and local adversarial training
3.2 局部对抗训练框架
本文提出的局部对抗训练框架见图4.原始数据进入深度学习模型前,需将文本中的单词预处理为词向量;再对原始词向量进行损失值大小的评估,以评估结果选择与原始数据识别率相匹配的困难样本筛选比例;然后,根据混淆矩阵错误概率分布按类对困难样本计算目标攻击扰动,添加扰动后生成对抗样本;最后,将对抗样本与原始语料一起用于对抗训练,增强模型识别性能与泛化能力.

图4 局部对抗训练模型框架图Fig.4 Local adversarial training model
添加扰动的神经网络结构见图5,x代表输入文本序列;w为单词对应的词向量表示;r为词向量层的扰动;y为结果序列. Embedding为词嵌入层,用于预处理文本数据使其向量化;BiLSTM层同时学习过去与未来的信息,通过前向与反向传播两个隐藏状态的单元获取句子特征;CRF层学习句子级标签的上下文信息,语句进行序列标注.
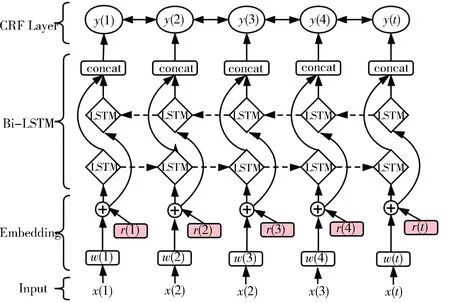
图5 添加扰动的神经网络结构图Fig.5 Neural models with perturbation

(8)

(9)
(10)
3.2.2 生成对抗样本 本文提出了一种基于混淆矩阵的目标攻击方式生成对抗样本,简称为CTR方法,该方法利用混淆矩阵可反应样本的分类错误占比的特点,对每类样本中的困难样本进行指向错误类的攻击.设同类别困难样本集合为C,样本数量为S,C={c(1),c(2),…,c(S)}.其中,每个样本都对应共同的真实标签ltrue,L对应真实标签集合,标签类别的总数量为N.L与C共同组成训练集,具体表示如下.
(11)
(12)
设C对应的对抗攻击标签序列为Ltar,使用conf(L)表示按混淆矩阵的错误概率分布排列的标签集合,其关系如下.
Ltar={ltar|ltar∈L,ltar≠ltrue}=conf(L)
(13)
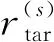
(14)
(15)

(16)
3.2.3 对抗训练 训练的最终目的找到最大化真实标签的预测概率,使数据总损失值最小的参数集合.
对抗样本的损失函数计算公式为
(17)
α用于控制原始语料与对抗样本损失值比例,对抗训练总损失为
(18)
对抗训练最优参数计算为
(19)
4 实验结果与分析
4.1 数据集
为了验证本文方法的性能,选择3个专业领域的公开数据集进行了实验.其中JNLPBA[21]为生物领域的数据集,标注了分子生物领域的专业实体,该数据集样本数量相对较多,可用于对比本文方法在不同规模数据集的表现.MalwareTextDB[22]为恶意软件领域的数据集,其中数据来源于恶意软件报告,数据集中标记了APT攻击和恶意软件等实体.Drugbank为医药领域的数据集[23].该数据集收集了大量医药信息,标注了各种药物数据,是医药领域最详细的数据集之一.实验中对3个数据集划分训练集/验证集/测试集.各数据集的统计信息如表1.

表1 数据集统计信息
4.2 评价指标
本文采用准确率(Precision)、召回率(Recall)和F1值评估各个数据集的学习情况,计算公式如下.
(10)
(11)
(12)
4.3 实验设置
4.3.1 实验环境 本文实验基于Tensorflow深度学习框架设计,采用Python 语言实现,实验运行平台为Ubuntu16.04(64位),显存为8 GB,GPU为 GTX 1070.
4.3.2 参数设置 本文采用GLOVE方法[24]训练所得的100维预训练词向量glove.6B.100d对文本数据进行预处理.为更好学习数据特征,批量大小的设置根据数据集的数据量变化,Drugbank、MalwareTextDB批量大小设置为64,JNLPBA的批量大小设置为128.设置LSTM隐藏层数为100,参数优化由Adam优化器[25]执行.根据Srivastava等人[26]的经验,设置初始学习率为0.01,梯度裁剪率为5.0;为防止过拟合,在嵌入层与LSTM输出层设置dropout为0.5.在对抗样本生成过程中,ρ表示困难样本筛选比例,根据的3个数据集在基线方法的效果,ρ在JNLPBA,MalwareTextDB,Drugbank数据集中分别设置为30%,50%,20%;根据Zhou等人[10]的经验,α依次从0.1至0.9中取值,用于平衡原始语料与对抗样本的损失值影响;ε从0.01至1中取值用于控制扰动大小.最终可从测试集不同参数的训练效果中选出最合适的α,ε参数组合.
4.3.3 对比实验 本文以BiLSTM-CRF模型为基线方法的同时,设置3个对比实验用于证明局部目标对抗训练方法于提升命名实体识别效果的优越性.快速梯度符号下降(Fast Gradient Sign Method, FGSM)方法[17]为最常用的非目标攻击算法,故3组对比实验分别为基于FGSM的全局对抗训练、基于FGSM的局部对抗训练,基于CTR方法的全局对抗训练.基线方法可用于对比本文方法与其余对抗训练方法在命名实体识别任务的提升效果;全局与局部方法的对比用于证明局部对抗训练是否保持了全局对抗训练的效果,并展示识别率的损失情况.不同攻击方式的对比用于展现本文中CTR攻击方法与局部对抗训练结合的优越性.
4.4 结果与分析
4.4.1 实验结果 表2展示了基线方法与各种对抗训练方法的实验结果,Baseline表示基线方法,FGSM_GOL表示采用FGSM方法的全局对抗训练,FGSM_LOC表示采用FGSM方法的局部对抗训练,CTR_GOL表示采用CTR方法的全局对抗训练,CTR_LOC表示采用CTR方法的局部对抗训练.
(1) 表2显示,较于基线方法,基于FGSM方法与基于CTR方法的对抗训练都显著地提升了实体识别F1值.同时,表3~表5中表现出3个数据集的准确率与召回率都有明显的提升,证明了对抗训练对增强命名实体识别效果的有效性.在3个数据集的表现中,最优识别率均出现在运用了CTR方法的对抗训练方法.JNLPBA数据集中,CTR_GOL方法F1值比基线方法高1.63%;MalwareTextDB数据集中,CTR_LOC 方法的F1值比基线方法高6.03%;Drugbank数据集中,CTR_LOC 方法的F1值比基线方法高3.65%.其中CTR_LOC方法在3个数据集的召回率分别提升0.88%、8.23%、3.74%.召回率与F1值的明显提高,说明了该方法有效缓解了边界样本因混淆而难以识别的问题,增强了模型的泛化能力.
(2) 不同攻击方式的对抗训练方法之间具有差异.在采用FGSM方法的两个实验中,JNLPBA、MalwareTextDB和Drugbank等3个数据集的局部对抗训练F1值均低于全局模式的效果,分别降低0.49%,0.15%和0.55%.在采用CTR方法的两个实验中,MalwareTextDB和Drugbank数据集的局部对抗训练效果较于全局对抗训练分别增加2.40%和0.47%,JNLPBA数据集在局部对抗训练的效果较全局对抗训练降低0.29%.局部对抗训练相比于全局对抗训练的识别效果虽然具有细小的波动,但基本维持了全局对抗训练的效果,并且在3个数据集中分别减少了70%,50%,80%(困难样本筛选中的简单样本淘汰比例为1-ρ)的生成对抗样本的计算量,极大地减少了冗余对抗样本的生成,提升了对抗训练的质量.

表2 实验结果比较(F1值)
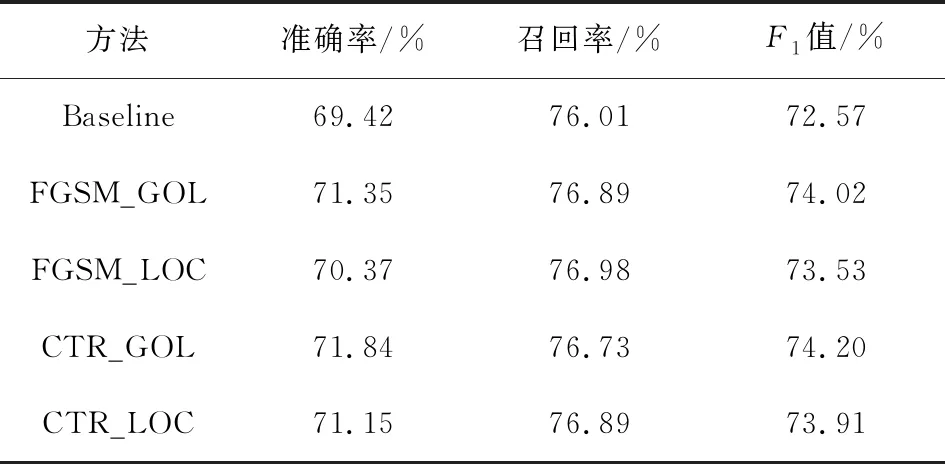
表3 JNLPBA数据集上不同实验结果

表4 MalwareTextDB数据集上不同实验结果

表5 Drugbank数据集上不同实验结果
4.4.2 结果分析 (1) JNLPBA数据集在对抗训练中的提升低于其数据集,分析原因应为JNLPBA数据集中样本数量更大,为模型学习提供了更加充足的特征,故对抗训练在此类大样本数据中不能发挥最优作用;而样本数量相对较少的MalwareTextDB与Drugbank数据集在合成对抗样本的环节中变相扩充了语料数据,仅添加微小扰动的对抗样本分布在原始样本周围,对模型充分学习样本特征具有积极的意义. 除此之外,在MalwareTextDB数据集的全局对抗训练中,FGSM方法高出CTR方法2.20%.这种明显的差异可能源于该数据集中原始样本的识别率较低,使指向错误分类的目标攻击对抗样本超过最合适的对抗训练比例,导致效果明显低于其他对抗训练方法.
(2) FGSM为非目标攻击方法,训练效果的提升主要依赖于大量随机方向的对抗样本对模型充分学习样本特征,故采用局部对抗训练时,对抗样本的减少与非目标攻击成功率低的双重作用下,造成识别效果的损失.CTR是基于目标攻击思想的方法,效果提升主要依赖于错误分类样本在模型参数优化机制上的重要性.与困难样本筛选结合后不影响分类错误的对抗样本的生成,反而降低类别内部的对抗样本对训练效果的影响,从而能出现对抗训练效果不降反升的情况.从实验中可得出,对抗训练是提升命名实体识别模型性能的有效手段,困难样本筛选是提高对抗训练质量的辅助办法.
5 结 论
本文从边界样本的角度出发,提出了一种基于混淆矩阵错误概率分布的目标攻击方法,并结合困难样本的思想提出了局部对抗训练方案,用于命名实体识别研究.该方法以BiLSTM-CRF模型为基线模型,采用困难样本筛选的思想,筛选出对模型性能有关键影响的,包含大量边界样本的困难样本;利用边界样本易被扰动的特性,结合基于混淆矩阵错误概率分布的目标攻击方法生成对抗样本用于对抗训练.实验结果证明了CTR方法在对抗训练的有效性,也证明了本文提出的CTR结合困难样本的局部对抗训练方法的优异性.该方案不仅有效缓解了边界样本混淆限制命名实体识别性能的问题,极大提升命名实体识别效果,而且减少了常规对抗训练中增加计算成本的冗余对抗样本,保留了对抗训练效果的同时提高了对抗样本质量.下一步工作将考虑进一步优化对抗攻击方法,使对抗样本在对抗训练中发挥更积极的作用.
