基于强化学习的特征提取方法在攻击识别中的应用
2021-04-06李晓明王文晖任琳琳陈兆玉刘学君
李晓明 王文晖 任琳琳 晏 涌 陈兆玉 沙 芸 刘学君
1(中国航空油料集团有限公司信息技术和网络安全研发中心 北京 100089)
2(北京石油化工学院信息工程学院 北京 102600)
(lixm@cnaf.com)
伴随着网络技术的不断发展,网络安全所面临的挑战愈发严峻,网络攻击逐渐呈现多阶段、分布式和智能化的特性[1-3].虽然异常检测系统(anomaaly detection system, ADS)能有效地对工控中的异常进行检测,但随着攻击技术的不断发展,一些组合的逃逸技术仍可以逃脱检测,从而对网络发起攻击[4].
神经网络( neural network, NN)具有检测准确度高且有良好的非线性映射和学习能力、建模简单、容错性强等优点[5].支持向量机(support vector machines, SVM)是在统计学习理论基础上提出的一种学习方法,其将输入向量映射到一个高维空间,在这个高维空间中构造最优分类平面[6].神经网络和SVM在攻击识别领域都有广泛的应用.但随着工控数据愈发庞大,使用神经网络和SVM来进行训练时所需要的时间越来越长,准确率也受到影响.Hotelling[7]提出了一种使用在维度间找到近似线性关系对高维特征进行降维的方法,称为主成分分析(principal component analysis, PCA).PCA通过析取主成分显出最大的个别差异,用来减少样本集中特征的数量.但噪声对PCA的分析结果影响很大.
因此,在特征相对独立的数据集上为了解决噪声对特征提取的干扰,本文提出了一种使用强化学习进行特征提取的方法.
1 算法实现
1.1 强化学习过程
强化学习是机器学习的范式和方法论之一,用于描述和解决智能体在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题[8].本算法中的强化学习过程如图1所示.
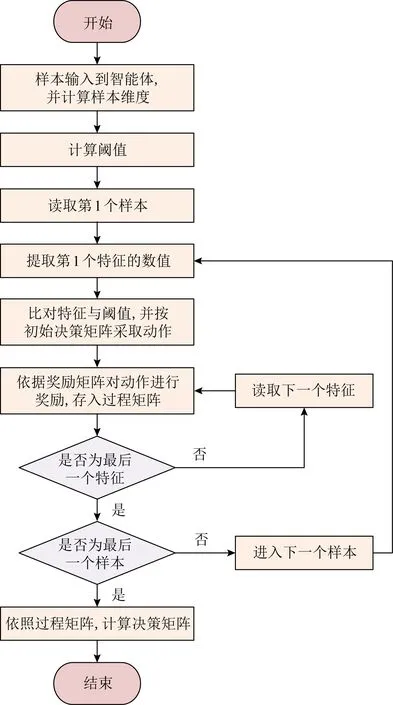
图1 强化学习流程图
首先创建一个智能体模块,其能够读取信息并作出动作.之后将样本输入到智能体中,智能体首先计算出样本维度(特征个数),再根据每一个特征,计算相应的阈值.阈值为所有样本该特征的均值.
计算完阈值后,智能体读取第1个样本的第1个特征,与前面计算出的该特征的阈值相比较,并按初始决策矩阵采取动作.初始决策矩阵内有2种动作,分别是发出报警和不发出报警.2种动作采取的概率均为50%.
采取动作之后,即可依照奖励矩阵对动作进行奖励.奖励矩阵的设定需视情形而定[9].在某些特定问题下,假阴性要比假阳性的危害大得多(例如疾病),此时假阴性所得到的惩罚就要比假阳性大得多.在本算法中,为简化计算过程,设定奖励矩阵如表1所示:
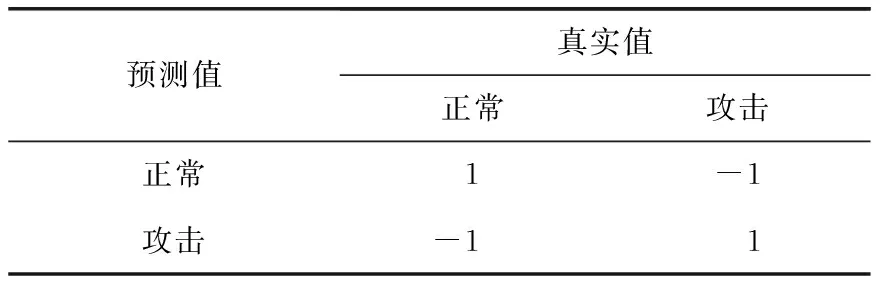
表1 奖励矩阵
智能体每次得到奖励,都会累积到一个过程矩阵Q中.矩阵Q为n行4列(列标为0~3),其中n为特征数.Q[0],Q[1]列为当读取特征大于阈值时智能体不发出和发出警报所累积的奖励矩阵数值;Q[2],Q[3]列为当读取特征大于阈值时,智能体不发出或发出警报所累积的奖励矩阵数值.
对动作进行奖励并存储之后,智能体读取该样本的下一个特征,并按照初始决策矩阵采取动作,获得奖励.对每一个样本的每一个特征执行上述操作,最终得到了过程矩阵Q.
依照矩阵Q,可计算决策矩阵D.D为n行2列的矩阵,计算公式如下:
(1)
(2)
其中,D[0],D[1]为决策矩阵的第1,2列.
按照决策矩阵对原数据集进行特征提取,提取过程如图2所示:

图2 特征提取流程图
决策矩阵共有n行,n为特征数量.其按行求和后,得到每一个特征所对应的概率和.通过经验设定一个概率阈值,概率和小于该阈值的特征被视为冗余特征.去除所有冗余特征后,得到新的数据集,即为原数据集经过强化学习预处理后的数据集.
1.2 训练过程
将经过强化学习修正后的数据集放入神经网络和SVM中进行训练并分类.
1.2.1 神经网络训练过程
将经过强化学习修正后的样本放入神经网络,训练网络内的参数,最终建立可以识别工控攻击的神经网络.本文采用了梯度下降法对神经网络的参数进行训练.
神经网络隐藏层和输出层的公式如下:
y=WTx+b,
(3)
(4)
其中,x是经过智能体优化后,输入到神经网络输入层的值,y是输出层的值,a是输出值.
使用如下方法定义损失函数和每次迭代后权重矩阵的更新值:
(5)
(6)
其中,η为学习率.为保证算法能够快速收敛,多次实验后取0.001.
1.2.2 SVM训练过程
利用SVM进行分类时,决策函数为1对多,并且使用RBF函数作为核函数,公式如下:
(7)
其中,σ为径向基宽度,经过多次实验取0.2.
1.3 评价指标
神经网络训练之后的分类评估可有以下几个指标,包括准确率(accuracy)、精确率(precision)、召回率(recall)、F1值等[10].TP是原本为正判定为正的样本数,FP代表原本为负判定为正的样本数,FN代表原本为正判定为负的样本数,TN代表原本为负被判定为负的样本数,相应的计算公式如下:
(8)
(9)
(10)
(11)
2 实验结果与分析
本算法的实验环境为Windows10,调试环境为python3.8.3,tensorflow2.3.0.
分别对NSL-KDD数据集、自建数据集、密西西比数据集的原始数据集、PCA以及强化学习处理后的数据集用神经网络和SVM进行训练,比较训练结果及运行时间.
2.1 NSL-KDD数据集
NSL-KDD数据集是从模拟的美国空军局域网上采集的9个星期的网络连接数据,分为训练集和测试集,训练集具有125 973条数据,其中有46.54%的正常样本,其余为不同类型的攻击样本(标签均为“1”).训练集中有22 544条数据.
对NSL-KDD数据集采用原始数据集和PCA、强化学习2种预处理方式处理后的数据集,用神经网络和SVM训练后的分类结果如表2、表3所示:

表2 NSL-KDD数据集3种预处理方式神经网络分类结果

表3 NSL-KDD数据集3种预处理方式SVM分类结果
由表2可以看出,在NSL-KDD数据集上,使用神经网络训练时,强化学习预处理后的数据集准确率相较于处理前提升了1.6%,运行时间降低了0.3 s;相较于PCA方法,准确率提升了0.6%,运行时间大致不变.
由表3可以看出,在NSL-KDD数据集上,使用SVM训练时,强化学习预处理后的数据集准确率相较于处理前略微降低,和PCA方法基本持平,但花费时间更长.
2.2 自建数据集
该数据集是根据某油库正常行为时的工控数据,采用偏差攻击得到的自建数据集.
该数据集为8 281行,132列,其中最后一列为标签(1为攻击,0为正常),其余列为特征(包括温度、液位、压力等数据).该数据集包括4 141个正常样本和4 140个攻击样本.
对自建数据集也分别采用3种数据样本以及2种处理方式,得到的分类结果如表4、表5所示:

表4 自建数据集3种预处理方式神经网络分类结果

表5 自建数据集3种预处理方式SVM分类结果
由表4可以看出,使用神经网络训练时,在自建数据集上,准确率相较于处理前提高了0.12%,这意味着判断错误的样本个数从3个减少到了1个,同时训练时间几乎不变;准确率和运行时间都优于PCA方法.
由表5可以看出,在自建数据集上,使用SVM训练时,3种方法在准确率上并无差别,0.03%的错误率意味着每种方法都只有1个误判.但在运行时间上,PCA和强化学习预处理方法比处理前都提升了0.3 s.
2.3 密西西比数据集
密西西比数据集,是密西西比州立大学提出的用于工控系统入侵检测评估的数据集,收集的信息是天然气管道中远程终端单元与主控制单元之间的网络事务,用于模拟天然气管道上的实际攻击和操作员活动,包括了61 156个正常样本和35 863个异常样本[11].
对密西西比数据集也分别采用3种数据样本以及2种处理方式得到的分类结果如表6、表7所示:

表6 密西西比数据集3种预处理方式神经网络分类结果

表7 密西西比数据集3种预处理方式SVM分类结果
由表6可以看出,在密西西比数据集上,使用神经网络训练时,尽管运行时间提高了0.1 s,但准确率下降了10%,在运行时间上也并无太大差别.这表明强化学习预处理方法依旧有其不足之处.
由表7可以看出,在密西西比数据集上,使用SVM训练时,从准确率上看,强化学习预处理方法和处理前几乎无差别,但PCA的准确率大幅下降.从运行时间上看,相较于处理前,PCA方法缩短了325 s,强化学习预处理方法缩短了258 s,效率提升了41%.
综上所述,从神经网络的分类结果看,在NSL-KDD和自建数据集上,强化学习预处理后的数据集比其余2种方法的效果都有所提高,并且训练时间要快于处理前,但在密西西比数据集上强化学习预处理后的数据集准确率远小于另外2种方式,并且运行时间差别不大.从SVM的分类结果看,强化学习预处理的方法在NSL-KDD上的准确率略微下降,其余2个数据集上的准确率基本持平.从运行时间上看,强化学习预处理的方法在密西西比数据集上较处理前有大幅提升,在其余2个数据集上差别不大.
从上述结果可以看出,强化学习的数据预处理方法对神经网络进行分类时,效果有所提升,但采用SVM进行分类时,效果不明显.这是因为神经网络的神经元结构意味着每一个输入维度都对结果有影响,而SVM中少数支持向量决定了最终的分类结果,因此维度的增加对其准确率影响很小,但由于其需要计算高维空间的欧氏距离,因此运行时间大大增加.
为了探寻强化学习预处理方法的适用性,本文使用克鲁斯卡尔[12]方法处理了3个数据集.克鲁斯卡尔方法可以寻找数据集的最小生成树,从而找出特征间的关联.在NSL-KDD和偏差攻击数据集上,特征都被分为了多组;而在密西西比数据集上,特征仅被分为了1组.这代表着前两者都具有多棵决策树,而密西西比数据集只有1棵决策树.对于只有1棵决策树的数据集,可以认为其没有冗余特征,所有的特征都影响着最终的决策,此时去除特征就会降低准确率.
2.4 概率阈值优化
除了上述结果外,决策矩阵中概率阈值的选取也对结果有一定的影响.在丢弃特征时,需要设定一个概率阈值,丢弃概率和小于概率阈值的特征.概率阈值的设定可通过实验确定,概率阈值和准确率间的关系如图3所示:
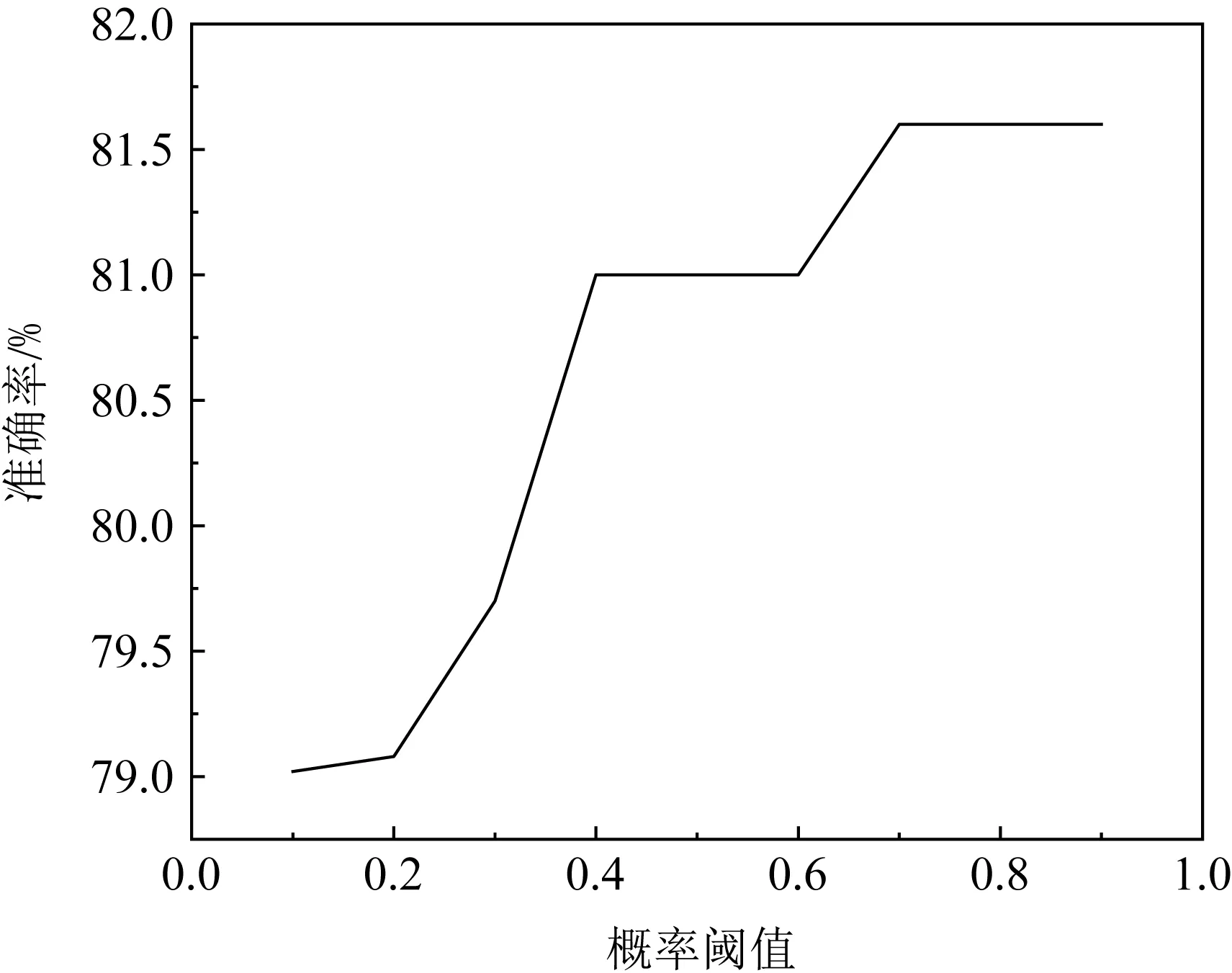
图3 不同概率阈值时样本的准确率
可以看出,随着概率阈值的不断提高,准确率也在不断提高.这是因为丢弃了更多把握不大的特征之后,保留了有助于判断结果的特征,从而减少了无效特征的干扰.
3 结 论
综上研究表明,强化学习预处理方法在特征间关联性较弱的数据集上表现很好,可以有效筛选出关键特征,减少无效特征的分类干扰.但在特征间关联性很强的数据集上表现欠佳.因此,可以结合克鲁斯卡尔方法,先找到最小生成树,再判断是否进行提取.此外,下一步的工作中可以将多个特征视为一个特征,在强化学习时将多个特征视为一个整体进行判断,从而减少特征间关联性强对强化学习预处理方法的影响.
