基于时态密集度特征的大数据高效迁移策略
2021-04-03刘金魁
刘金魁
(河南工业和信息化职业学院,河南 焦作 454003)
随着互联网科技的快速发展,大数据作为当代高科技的产物,在社会各个领域中得到广泛的应用。当今信息数据流通数量不断增多,互联网平台在日常运营中会生成和累计海量的实时数据,这些规模庞大的数据集合增加了平台服务器的数据存储、获取、搜索、管理与处理的难度。为有效解决大数据平台控制管理面临的难题,满足海量、高增长率和多样化的信息资源管理需求,需要进行数据迁移与服务器扩容的新处理模式[1]。数据迁移与数据转换或数据集成不同,并不是进行简单的内部数据位置的交换变化,而是把数据从源系统传输到目标系统,使移动数据填充到新环境中,实现信息数据的转换传输,提高数据库的访问和信息调度能力[2]。
数据迁移需要通过存储数据库、应用程序、云计算和业务流程来完成。由于大数据迁移存在一定的风险和难度,数据在存储设备、位置或系统之间进行移动时,不仅要保证数据的质量和完整度,还要制定合理完善的计划和实施步骤,避免发生灾难性数据丢失,确保数据迁移的顺利完成[3]。传统迁移方法采用统计信息特征的方法,进行经验模态分解的大数据迁移,该算法成本高、缺乏良好的数据库访问和调度的实时性。另一种基于粒子群滤波的多数据库环境下分布式大数据迁移方法,虽然降低了经济成本,并具有较高的访问实时性和准确性,但是,该算法在迁移过程中抗干扰能力差,容易出现迁移问题。因此,文章提出基于时态密集度特征的大数据高效迁移策略,并针对大数据时态密集度特征进行分析研究,实现大数据的高效迁移。
1. 时态密集度特征
大数据具有数据量大、类型繁多的特征,随着海量数据的不断堆积,微簇的聚类程度也会有所不同。对于微簇时态权重F:设 n表 示某一微簇,tn为数据点S到微簇 n的 时刻,则微簇n 的时态密度为所有到达微簇n的权重的总和:
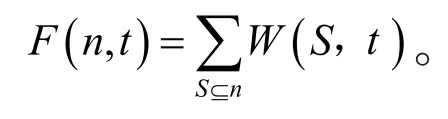
通过数据到达微簇时的速度的计算发现,当新的数据到达微簇时,时态密集度权重之和增加,随着数据运行时间的衰减推移变化,会影响整体微簇的产生。如果新的数据快速不断地推移到达微簇,那么时态密度就会越来越大,一旦新的数据不能尽快推移到达微簇,其时态密度就会逐渐减少。通过增量的计算反映出一个微簇推移时间的快慢对整体微簇产生的重要性,新的数据到达微簇的时间越快,就会增加微簇的时态密度,而当微簇一直未有新的数据到达,该微簇没有形成时态密度特征,就会通过更新信息将该微簇删除。这种针对微簇不同阶段点的时态密度分析计算的方式,不仅有效提高了计算的速度,还保证了计算的有效性和可靠性。
2. 大数据高效迁移策略
2.1 数据格式统一
数据会因类型不同而产生不同的存储记录方式,导致数据存储格式不统一。数据被迁移到新平台后,就会导致与新系统原始数据库中存储记录的信息出现重复、拼写不一致和空值不符等许多属性不兼容问题,无法实现数据的统一管理。为避免这一现象发生,在新的数据迁入环境中应采用统一化格式存储数据,以便于管理。
根据新平台的应用功能,采用设计语言查询数据库的特殊编程方式,以便更好地管理和控制数据库。设计 Java 语言服务方式,服务器对数据库迁移缓存ORM框架采用的是Hibernate。通过迁移数据库中的数据与新系统数据库中的数据,进行Hibernate语言对象访问形式,有效解决了数据重复混乱的问题,实现数据格式的统一转换管理。
2.2 数据分割
数据迁入平台应采用Stand_alone运行模式。由于庞大的数据量对平台系统造成推移接收困难,所以,迁入数据应先进行切分,再被多线程同时处理。这种分割并行处理方式不仅解决了数据移动接收问题,还有效提高了平台工作效率。在对迁移大数据进行分割前,首先要对迁入的总数据量进行预先估算,并根据系统硬件环境进行数据信息量的合理配置。数据切分模块负责把迁入的大数据切分成若干小量数据作业模式,然后进行多个线程并行处理,完成数据推动迁移。当数据切分完成后,应对生成的小数据进行信息记录,并提交至平台,实现统一迁移管理。数据切分记录表如表 1 所示。
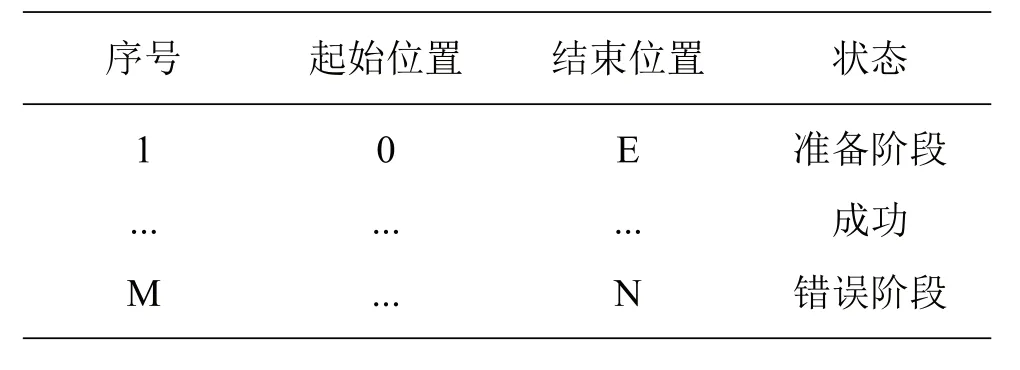
表1 数据分割记录表
表1中:N为数据总量,E为单个作业需要完成的迁移数据量,整个切分流程分为以下几
Step1:估算系统存储能力及任务处理能力;
Step2:针对预加载数据的迁移量进行预估计算;
Step3:当数据迁移量超出系统处理能力时,需要先将数据做切分处理;
Step4:如果数据切分出现问题,则应进行异常监测,并进行数据迁移量评估;
Step5:若数据切分成功,将切分完成的数据信息序列导入到数据迁入模块中。
2.3 数据迁移
基于时态密度特征的大数据迁入作业,采用的是多线程并行处理模式,数据迁入步骤如下。
Step1:加载要迁入数据队列的初始化信息;
Step2:检测数据源是否存在数据,如果存在数据,就要读入下一个单位量的数据,如果没有结束程序;
Step3:若检测队列已满,则等待;
Step4:当队列中数据读入缓冲区,表示为空时,则任务结束。
迁入缓冲队列技术和迁出缓冲队列技术有效解决了时态密集大数据在迁移过程中读入数据在格式上存在的差异和时率不匹配问题。通过对不同访问数据的访问率进行分别存储,把经常访问的数据存储到成本较高的存储空间,实现存储硬件的最大化使用价值,快速安全地完成大数据的迁移工作。
3. 对比实验
为了验证基于时态密集度特征的大数据高效迁移方法的有效性,进行对比实验分析。
3.1 实验环境
实验环境如表2所示。
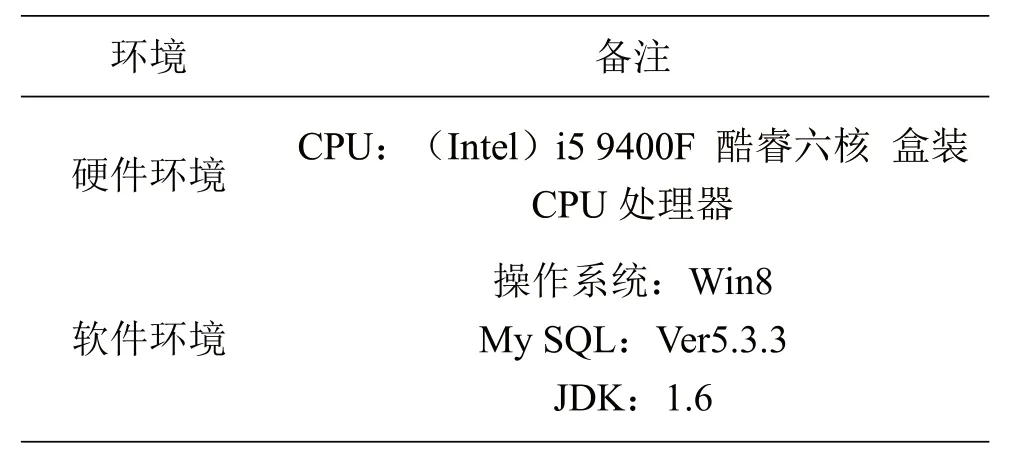
表2 实验仿真环境
3.2 实验数据分析
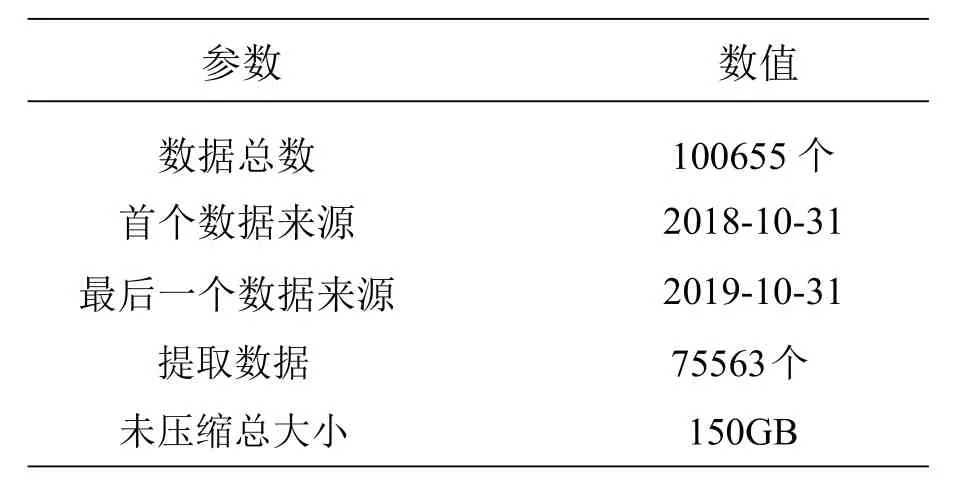
实验数据分析如表3所示。
images/BZ_101_1039_729_1075_765.pngimages/BZ_101_1013_936_1048_972.png
3.3 实验结果与分析
将经验模态分解大数据迁移方法、粒子群大数据迁移方法和基于时态密集度特征的大数据高效迁移方法的迁移效率进行对比分析,结果如图1所示。
由图1可知:在凌晨3点钟时,经验模态分解大数据迁移方法和粒子群大数据迁移方法的迁移效率分别为55%和71%,而基于时态密集度特征迁移方法的迁移效率为87%;在上午9点钟时,经验模态分解大数据迁移方法和粒子群大数据迁移方法的迁移效率分别为30%和58%,而基于时态密集度特征迁移方法的迁移效率为92%;在下午6点钟时,经验模态分解大数据迁移方法和粒子群大数据迁移方法的迁移效率分别为22%和48%,基于时态密集度特征迁移方法的迁移效率为93%。
综上所述,基于时态密集度特征的大数据高效迁移方法是有效性的。
4. 结束语
随着互联网、物联网和社会网络的快速发展,人们每时每刻都在产生大量的信息数据,这些海量大数据的产生增加了系统控制管理的难度。为有效解决堆积的大量数据,采用基于时态密集度特征的大数据高效迁移方法,使海量大数据从原始平台迁移到另一个新平台,不仅高效完成了大数据迁移,还提高了数据控制管理的统一性和安全性。基于时态密集度特征的大数据高效迁移策略,首先针对大量数据进行预估计算,采用科学合理的数据分割并行迁移方法,实现大数据的优化配置,具有良好的可行性和较强的适用性,同时,还弥补了传统数据迁移方法存在的不足,既节约了经济成本,又提高了运算的精准性,极大提高了时态密集度特征的大数据迁移的工作效率。随着计算机科学技术的不断发展,在软件、硬件和数据库技术及数据迁移等工具的创新开发中,一些大存储容量、高速运转和强功能的智能化系统得到了越来越多的应用,促进了大数据的可持续管理和应用。
