基于双线性卷积神经网络的车辆多属性分类算法设计
2021-04-01丁继文
丁继文
摘要:针对图像分类中背景信息太多容易误导分类结果的问题,提出一种筛选—识别网络架构,通过剔除与分类无关的背景信息、定位要分类的感兴趣区域及提高对车辆细粒度分类的准确率。用YOLOv3网络快速寻找需要分类的目标物体,消除背景中无关信息对分类的误导,将结果送入到双线性卷积神经网络进行训练和分类,结果在Cars196数据集中对车辆的车型、颜色和方向的分类精度为92.1%,92.7%,97.4%。利用监控视频自制数据集中对车型、颜色和方向的分类精度为71.3%,68%,85.6%。使用筛选—识别网络架构对车辆的细粒度分类有积极作用,可以剔除大部分对分类没有用的背景信息,更有利于网络学习分类的特征信息,从而避免背景信息对分类结果的误导,提升模型的分类精度。
关键词:细粒度图像分类;目标检测;双线性卷积神经网络;YOLOv3;篩选—识别网络架构
中图分类号:TP391文献标志码:A文章编号:1008-1739(2021)03-68-6

0引言
图像分类[1]在计算机视觉领域是一个经典课题,包括粗粒度图像分类和细粒度图像分类[2]。细粒度图像分类是对在同一个大类别下进行更细致的分类,如区分猫狗的品种、车的品牌或车型[3-4]及鸟的种类等,在很多情况下细粒度分类才更有实际意义。细粒度分类与粗粒度的分类不同使细粒度分类往往具有细微的类间差异,加上图像采集中存在光照、样式、角度、遮挡及背景干扰等因素影响,与普通的图像分类课题相比,细粒度图像分类的研究难度更大。
在深度学习[5]兴起之前,基于人工特征的细粒度图像分类算法,一般先从图像中提取SIFT[6]或HOG[7]等局部特征,然后利用VLAD[8]或Fisher vector[9-10]等编码模型进行特征编码。Berg等人[11]尝试利用局部区域信息的特征编码方法去提取POOF特征。但是由于人工提取特征的过程十分繁琐,表述能力不强,所以分类效果并不理想。随着深度学习的兴起,利用卷积神经网络[12]提取特征比人工提取特征表述能力更强,分类效果更好,大量基于卷积特征算法的提出促进了细粒度图像分类的发展。
按照模型训练时是否需要人工标注信息,基于深度学习的细粒度图像分类算法分为强监督和弱监督[13]2类。强监督的细粒度图像分类在模型训练时不仅需要图像的类别标签,还需要图像标注框和局部区域位置等人工标注信息,而弱监督的细粒度图像分类在模型训练时仅依赖于类别标签。然而,无论是强监督还是弱监督的细粒度图像分类算法,大多数细粒度图像分类算法的思路都是先找到前景对象和图像中的局部区域,之后利用卷积神经网络对这些区域分别提取特征,并将提取的特征连接完成分类器的训练和预测[14]。Zhang等人[15]提出了part-based R-CNN算法,先采用R-CNN算法对图像进行检测,得到局部区域,再分别对每一块区域提取卷积特征,并将这些区域的特征连接构成一个特征向量,最后用支持向量机(SVM)训练分类。然而,选择性搜索算法会产生大量无关的候选区域,造成运算上的浪费。Lin[16]等人提出了新颖的双线性卷积神经网络(B-CNN)的弱监督细粒度图像分类算法,在3个经典数据集上达到很高的分类精度,能够实现端到端的训练,且仅依赖类别标签,而无需借助其他的图像标注信息,提高了算法的实用性。
在一幅图像中有区分度的信息所占图像的比例越高,卷积网络提取的利于分类的特征就越多,分类效果就越好,与人类区分物体聚焦的过程相似。本文提出一种基于深度学习的筛选—识别的网络架构,使用YOLOv3快速找到物体,筛选图像中有区分度的区域,剔除对分类不利的背景信息,再使用B-CNN[17]模型对有区分度的区域进行特征提取和分类,从而降低了无关背景信息对分类结果的干扰,提高了分类的精度。
1筛选—识别的网络架构
1.1总体框架
利用YOLOv3算法检测网络寻找图片的目标区域,筛选去除与分类无关的信息,然后将得到的结果(YOLOv3的输出)输入B-CNN中得到最后的多属性分类结果,系统架构如图1所示。
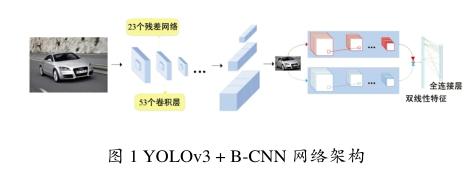
1.2基于YOLOv3的检测方法
1.2.1基于YOLOv3的网络筛选
YOLOv3算法是对YOLOv2目标检测算法的改进,将输入图像划分成×个栅格,更加细致的栅格划分使得模型对小物体的定位更加精准。经过YOLOv2检测网络,对每个栅格都预测个边界框,为平衡模型的复杂度和召回率,选择边界框的个数为5,最终会保留与物体真实边界框的交并比(IOU)最大的那个边界框,即:
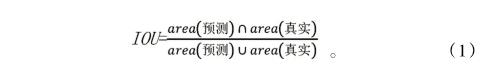
最后得到的边界框形状大多为细高型,扁平型居少。每个边界框预测5个回归值(,,,,),,表示边界框的中心坐标,,表示边界框的高度和宽度,为置信度。=×IOU,其中,的值为0或1,0表示图像中没有目标,1表示图像中有目标。置信度反映了是否包含目标以及包含目标情况下预测位置的准确性。为了更好的实验效果,设置阈值为0.3,得分小于0.3的边界框会被全部排除,剩下的是最后的预测边界框。
边界框预测调整:,经过回归函数处理后,范围固定在0~1,,表示栅格的坐标,比如某层的特征图大小是10×10,那么栅格就有10×10个,比如第0行第0列的栅格的坐标是0,就是0。最后的预测为:


1.2.2筛选区域的网络结构
YOLOv3算法提出了Darknet53[18]的分类网络,不同于YOLOv2提出的DarkNet19分类网络结构,有53个卷积层和5个最大池化层,比Darknet-19效果好很多。同时,Darknet53在效果更好的情况下,是Resnet-101效率的1.5倍,在与Resnet-152的效果几乎相同的情况下,效率是Resnet-152的2倍,DarkNet-53网络结构如图2所示。

YOLOv3的检测网络使用数据集训练Darknet-53,输入图像为416×416,然后在3种尺度上特征交互,分别是13×13,26×26,52×52,在每个尺度内,通过卷积核(3×3和1×1)的方式实现特征图之间的局部特征交互,作用类似于全连接层。
最小尺度YOLO层:输入13×13的特征图,一共1 024个通道。经过一系列的卷积操作,特征图的大小不变,但是通道数最后减少为75个,结果输出13×13大小的特征图,75个通道。
中尺度YOLO层:输入前面的13×13×512通道的特征图进行卷积操作,生成13×13×256通道的特征图,然后进行上采样,生成26×26×256通道的特征图,同时与61层的26×26×512通道的中尺度的特征图合并。再进行一系列卷积操作,特征图的大小不变,但是通道数最后减少为75个。结果输出26×26大小的特征图,75个通道。
大尺度的YOLO层:输入前面的26×26×256通道的特征图进行卷积操作,生成26×26×128通道的特征图,然后进行上采样生成52×52×128通道的特征图,同时与36层的52×52×256通道的中尺度的特征图合并。再进行一系列卷积操作,特征图的大小不变,但是通道数最后减少为75个。结果输出52×52大小的特征图,75个通道,最后在3个输出上进行分类和位置回归。
1.3基于B-CNN的特征提取和识别
1.3.1 B-CNN模型的结构
B-CNN是Tsungyu Lin等人提出的具有优异泛化性的B-CNN。B-CNN模型由一个四元组组成:M=( , , , ),其中,和为基于卷积神经网络A和B的特征提取函数,是一个池化函数,是分类函数。特征提取函数可以看成一个函数映射,将输入图像I与位置区域L映射为一个×维的特征。输入图像在某一位置I处的双线性特征可表示为:


2实验结果与分析
2.1数据集
为了验证方法的效果,采用标准细粒度图像分类数据集Cars196和利用监控视频截取图片自制数据集进行测试,数据集的若干样本如图4所示。Cars196数据集一共有16 185幅图像,提供196类不同品牌、年份、车型的车辆图像,分为训练集和测试集两部分,大小分别为8 144幅和8 041幅。
制作数据集,首先将不同时间段的监控视频按1帧/秒自动截图,获取到样本后再进行筛选,删除不符合要求的图片。采集到的图片中车辆来自不同方向使检测角度多样,不能仅仅局限在某个特定方向,颜色和车型要多样且尽量平衡,避免数据集集中在某一样中,提高数据集质量,共选取1 418张图片。按照COCO数据集的图像标注标准,将获取到的样本使用yolo mark进行标注,产生训练所需要的xml文件。

2.2实验结果和分析
使用YOLOv3预训练模型从Cars196数据集和自制数据集中分别筛选具有判别性的区域,并将图片分辨率归一化为448×448像素。然后对改进的B-CNN进行微调整:①将分类层的类别数替换为车型、颜色和方向的类别数;②对最后一层的参数初始化,且只训练最后一层。设置较小的学习率数值为0.001,使用隨机梯度下降法通过反向传播微调整个模型,迭代次数在50~100之间。本实验中完成了车辆的车型、颜色以及方向的识别与分类。车型分为大客车、轿车、卡车及运动型实用、汽车等8种类别,车辆的颜色设置了黑色、白色及蓝色等9种类别,车头方向设置前和后2种类别。用准确率和召回率来评估方法的性能,准确率和召回率的定义如下:

[11] BERG T, BELHUMEUR P.Poof:Part-based One-vs-One Features for Fine-grained Categorization, Face Vereification, And Attribute Estimatioin[C]//IEEE Conference on Computer Vision and Pattern Recognition.Sydney: IEEE,2013:955-962.
[12]周飛燕,金林鹏,董军.卷积神经网络研究综述[J].计算机学报,2017,40(6):1229-1251.
[13] XIAO TJ,XU YC,YANG KY,et al.The Application of Two-level Attention Models in Deep Convolutional Neural Network for Fine-Grained Image Classification [C]//2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston:IEEE,2015:1-10.
[14]翁雨辰,田野,路敦民,等.深度区域网络方法的细粒度图像分类[J].中国图象图形学报,2017,22(11):1521-1531.
[15] ZHANG N,DONAHUE J,GIRSHICK R,et al.Part-based R-CNNs for Fine-grained Category Detection[C]// Proceedings of the 13th European Conference on Computer Vision-ECCV 2014.Zurich:Springer,2014:834-849.
[16] LIN T Y, CHOWDHURY R A,MAJI S.Bilinear Convolutional Neural Networks for Fine-Grained Visual Recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2018,40(6):1309-1322.
[17] LIN T Y, CHOWDHURY R A,MAJI S.Bilinear CNN Models for Fine-grained Visual Recognition[C]// 2015 IEEE International Conference on Computer Vision (ICCV). Santiago: IEEE,2015: 1449-1457.
[18] HUANG G,LIU Z,WEINBERGER K Q,et al.Densely Connected Convolutional Networks[C]//CVPR 2017.Hawaii: IEEE,2017:2261-2269.
