一种基于不确定数据的高效剪枝挖掘算法
2021-03-30李峰
李 峰
(湖南工程学院 计算机与通信学院,湘潭411104)
当今数据挖掘已经被广泛地应用在各领域大型知识库信息检索和发现中.在各种各样的数据挖掘实践中发展了很多数据挖掘方法,特别是频繁模式挖掘.频繁模式挖掘既可以分析项目之间的重复关系,又可以在用户给定的最小频繁阈值上发现重复出现的特定模式.
1 频繁模式挖掘
1.1 确定频繁模式挖掘
根据挖掘的数据属性不同,频繁模式挖掘可分为确定频繁模式挖掘和不确定频繁模式挖掘.Apriori[1]和FP-Growth[2]就是典型的确定频繁模式挖掘算法.在确定频繁模式挖掘中人们设置紧凑的树结构,例如FP-tree和LP-tree[3],这样可以有效地将信息存储在搜索树中.在实际研究中,人们对确定频繁模式挖掘采用了很多方法.例如,高效用模式挖掘[4]在销售数据中考虑了利润和产品数量,Top-k频繁模式挖掘[5]采用了挖掘k个极大频繁模式.因此,通过考虑现实世界中的特定情况,不同挖掘算法可以在特定领域挖掘更多有价值的知识.
1.2 不确定频繁模式挖掘
现实世界由于测量的不精确、传输的不稳定,获得的数据一般是不确定的,所以基于不确定图进行挖掘才更有实际意义.人们研究了大量不确定子图挖掘算法.如Zhang[6]给出了不确定图中的子图分离和判定方法;LI等[7]提出一种高效子图挖掘算法;张硕等[8]探讨不确定图数据库中高效查询处理方法;Zou等[9]提出一种新颖的不确定图子图挖掘算法.
1.3 剪枝挖掘算法
剪枝模式挖掘最早是由Gadelha等[10]提出,后来Deng等[11]提出了MERIT剪枝模式挖掘算法.该方法使用WPPC-tree的树结构将项目名、收益和订单信息都保存到每个节点,并在扫描树节点时根据包含在节点中的项目名称对节点信息依次进行分组,生成中间检索集.当生成的检索集长度为K时,使用等价类检查每个子集是否为剪枝挖掘模式.由于在挖掘过程中检测过频,该算法无法发现所有剪枝挖掘模式.
后来Le Tuong等提出了DMERIT算法,该算法在进行模式挖掘过程时不使用模式等价关系,只为每个模式设置一个检测集,因此它可以挖掘所有剪枝模式.通过剪枝挖掘算法能有效地解决生产中的产品生产和管理问题.
但传统剪枝模式挖掘算法不能完全智能化执行制造业管理者的决策,因为传统的剪枝挖掘算法只考虑产品利润,不涉及组件成本.因此传统的剪枝挖掘算法在产品可靠性不高的情况下,只会采用模糊方法挖掘频繁模式,所以需要大量的时间,效率相对较低,不能快速获取制造业管理者所需要的决策树.
但在现实中,当生产过程发生变化时,工厂管理者不仅需要考虑组件与产品利润的关系,还要考虑组件成本.为了解决传统剪枝挖掘算法低效和可靠性不高的问题,提出了一种基于加权剪枝模式挖掘算法,该方法在以组件成本为权重的情况下,采用基于低估值约束的有效剪枝方法,并通过基于组件权重的挖掘索引器来发现频繁模式.通过这种方法,不仅获得了可靠的结果,而且提高了资源的可用性.
本文的贡献主要包括以下两个方面:
(1)提供了一种新颖的基于低估值约束的有效剪枝方法,该方法能有效地挖掘频繁模式.
(2)算法使用了权重因子,通过基于组件权重的挖掘索引器来剪枝,大大缩短了计算时间,而且不会影响利润计算的准确性.
2 基于剪枝模式的挖掘
2.1 剪枝模式
假设D={p1,p2,p3,…,pn}是基于权重的产品数据库.I={i1,i2,i3,…,im}是D中所有不同项的集合.每个产品pk(1≤k≤n)由唯一的PID键值确定.PID键值是数据库I中包含的项和产品利润的集合.表1是一个产品数据库的示例,其中包括产品及其利润.例如p3产品由G项和D项组成,其利润为130万元.
定义1(收益模式)若X={i1,i2,i3,…,im}表示项目,pk表示产品.X增益就是产品利润之和,表示如下:
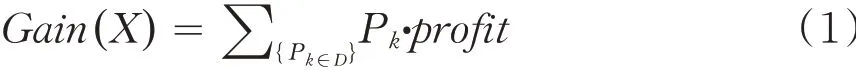
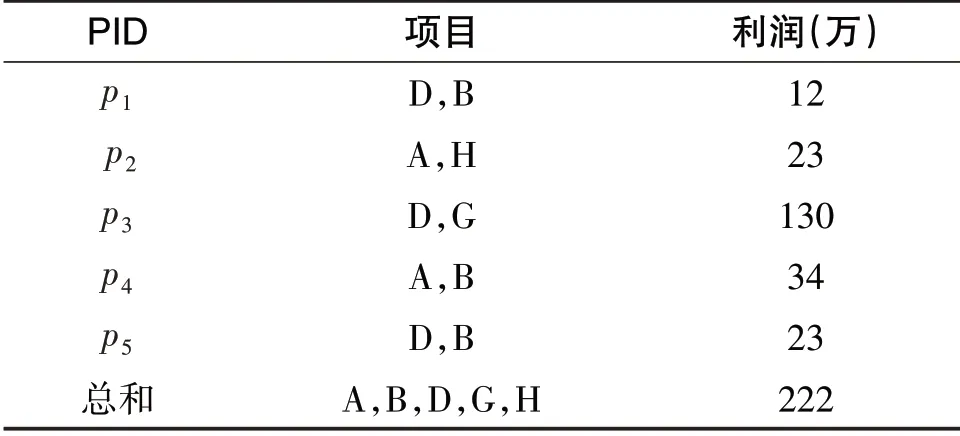
表1 产品利润表
定义2(最大收益阈值)给定用户设定收益百分比θ,最大收益MaxGain就是数据库中所有产品最大收益百分比,表示如下:
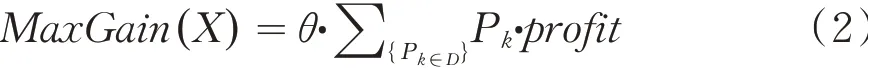
例如在表1中若θ是40%,MaxGain则是0.4×0.08=3.2%.
基于定义2能得出剪枝模式,若X的收益小于等于MaxGain,模式X就是剪枝模式,也就是说,X满足下面公式

2.2 剪枝模式算法描述
为了从product数据库中发现加权剪枝挖掘模式,依次执行以下过程.第一步,通过扫描一次数据库,提取长度为1的剪枝挖掘模式的候选模式集合.第二步,使用数据库和候选对象生成剪枝树,并让候选对象按频率降序排序,创建低估值约束.最后根据剪枝树的信息建立基于组件权重的挖掘索引器,挖掘频繁模式.
2.3 详细的算法
2.3.1 基于树结构剪枝挖掘模式算法
下面是基于树结构剪枝挖掘模式算法.
输入:产品库D,项目WI,最大利润阈值MGT输出:剪枝挖掘模式


3 实验结果
实验采用Inter i5-5200 3.00 GHz的CPU,4 GB内存,win7操作系统,所有程序使用C++语言编程.可从2个大数据库,UCI数据库和FIMI数据库,获得初始实验数据.在UCI数据库中选取Churn数据集,在FIMI数据库中选取Mush和Pums数据集.
三个数据集都是多元数据集,其中Churn包含3150个产品项和402组数据项,而Mush和Pums的产品项和组数据项分别为8124、120和49046、7117.在数据集中,每件产品的利润设置从100到1500,由一个随机函数RAND(800,50)产生,这里800是平均利润,50是每次变动幅度.为了更加真实,让利润满足正态分布函数N(800,1600).在三个数据集的实验中用PM和MERIT、DMERIT相比较,结果如图1、图2、图3、图4所示.
图1、图2分别表示在Pums和Mush数据集中候选模式的数量(PATTERNS)和最大收益百分比(Max Gain)之间的关系.可以看到挖掘出的候选模式的数量随着MaxGain的增加而增加.MERIT和DMERIT有相似的挖掘结果,挖掘效率都不高.特别当MaxGain的值大于4.05%的时候,挖掘出的候选模式的数量都明显增加.我们的方法(PM)相对前2种算法生成的候选模式更少,因此可以更快更有效地进行频繁模式挖掘,而且不会随MaxGain增加急速增加,算法稳定有效.
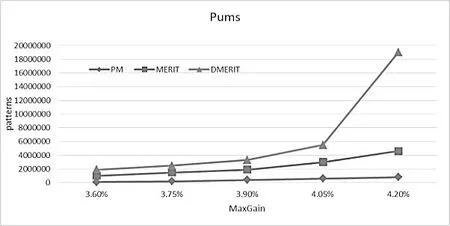
图1 在Pums中候选模式随着MaxGain变化
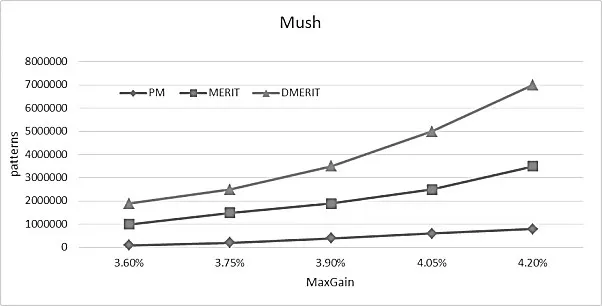
图2 在Mush中候选模式随着MaxGain变化
图3、图4分别表示在Churn和Mush数据集中,运行时间随着MaxGain的增加而增加.在图中不难发现当MaxGain超过3.9%时,MERIT和DMERIT运行时间急剧增加,运行效率大幅降低.在图中可以看到相对其他2种算法,本方法(PM)有着更少的运行时间,且时间消耗不会随着MaxGain增加突然增加,变化明显相对平稳.所以说算法更加快捷、稳定.
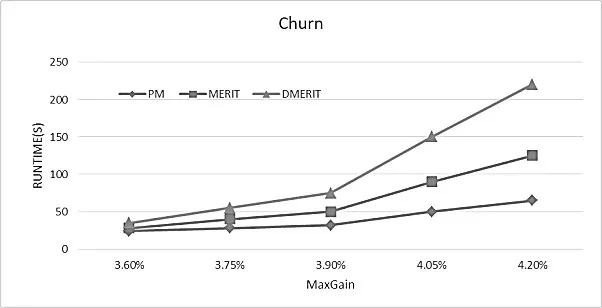
图3 在Churn中运行时间随着MaxGain变化
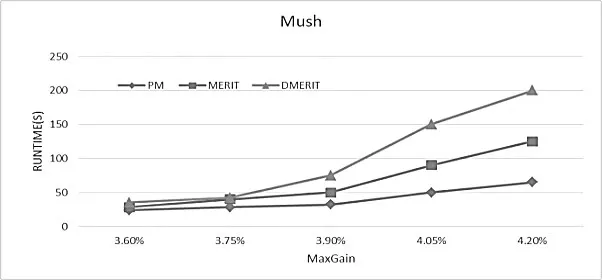
图4 在Mush中运行时间随着MaxGain变化
4 结论
本文提出了一种基于不确定数据高效剪枝挖掘算法,通过使用基于低估值的约束和基于组件权重的挖掘索引器进行的有效剪枝挖掘,不但考虑了利润信息,而且考虑了权重信息.实验证明本文算法在挖掘不确定数据库的频繁模式时相对于现有算法耗时更少,效率更高.
