参数化模型数据库在早期碰撞性能预研中的应用及优势
2021-03-30邓文字吴健余冯明松罗慧娟黄炎
邓文字,吴健余,冯明松,罗慧娟,黄炎
(上汽通用五菱汽车股份有限公司,广西柳州 545007)
0 引言
随着社会经济的高速发展,汽车的需求量逐年增加,交通事故频发使汽车安全受到广泛关注,考虑汽车的安全性能在人们选购汽车时越发重视。汽车发生碰撞时,白车身作为主要吸能部分,对其研究具有重要意义。在传统汽车的早期概念车身开发设计流程中,提升车身综合性能和缩短整体开发周期一直是很难兼顾的矛盾。
在早期车身结果优化设计时,参数化模型可实现尺寸、材料、料厚、等多变量的一体式优化,在车型早期概念开发阶段得到广泛应用[1-2]。
本文作者针对早期碰撞性能开发提出先使用SFE车身数据库搭建车身碰撞仿真模型,再利用SFE模型的隐式参数特性结合Isight DOE实验方法验证大量方案。这种方法旨在车身早期概念开发阶段就积极参与白车身的相关性能验证,改变传统CAE分析落后于早期开发设计的流程,在缩短早期研发周期的同时提升车身碰撞性能。
在某新车型预研项目中首先利用SFE车身数据库和初始输入概念参考数据搭建了车身碰撞模型,根据项目需求和研究重点分别选取材料牌号变量9个、厚度参数变量29个、截面参数变量26个作为碰撞性能的设计变量,以侵入量、回弹时刻、吸能比、加速度作为优化目标。选取230个样本点搭建Isight DOE,实现车身系统结构优化设计的自动循环运算。
这套白车身碰撞安全性能正向开发流程在白车身概念开发阶段就进行大量CAE碰撞性能仿真分析,可以使工程师在车身概念设计阶段有较大的设计空间寻求多种设计方案,从中筛选出性价比最好的综合方案,在较短开发周期内提升碰撞性能以达到目标要求,为后续车身设计提供优化指导性建议和方案。从而极大程度地提高研发质量和效率,保证后期研发顺利,有效降低研发成本。
1 基于参数化数据库搭建碰撞仿真模型
1.1 隐式参数化技术
参数化数据库搭建的模型是基于隐式参数化建模技术建立的数据集合。
在隐式参数化技术描述中,单个模型的几何形状由3种类型参数控制:基点坐标位置、基线曲率、基础截面形状。系统级模型可以通过控制上叙述参数和描述单个模型之间拓扑关系来自动生成。因为所有系统级模型是拓扑关系相连接,一旦上述任一参数修改,与其相关联的所有几何体都会产生相应变化[3-4]。这种模型具有两个功能:(1)模型结构具有全参数化功能,几何结构的位置、尺寸和形状等可以任意改变,能记录改变的过程并保存为设计变量;(2)几何结构发生改变的参数化模型可以自动生成几何结构相同并满足网格质量要求的有限元模型。基于上述功能,隐式参数化技术成为车身结构设计优化的有利工具[5]。
1.2 SFE参数化数据库
不同于传统SFE建模,建立SFE参数化模型数据库时,前期需要花费一定时间,对SFE参数化模型数据库建模,进行相应的规划。通过对国内外多款车型的主要截面和接头的拓扑结构进行分析,可以发现其拓扑结构都是“大同小异”,主要差异就是尺寸大小的不同。就是说,主要截面和接头在各个车型之间通过尺寸调整可以做到有效互换以断面和接头的通用性为基准,灵活地处理各种拓扑连接的数据库。利用SFE模块化技术,将整车分解到截面与接头层面,这是实现数据库的技术基础。以截面和接头拓扑结构为主导的数据库适用于每一个企业。不在整车宏观层面上考虑模块的通用性问题(如前舱、侧围、前/后地板总成是否通用等等),而将着眼点放在截面和接头拓扑结构的通用性上面,在这个微观层面上,各种迥异的车型都能体现出通用性。
数据库的最大特点是充分发挥模块化的优势,可以高效地衍生不同拓扑结构的各种车型。数据库对一个企业的平台规划要求不高,不局限于特定的车身架构,可以在“局部模块”的层面上快速完成各种整车结构的拼接和组合。
为保证通用性和灵活性,该数据库搭建的整体思路可概括为:化繁为简,有效拆分,干净灵活。
综上所述,数据库的两大特点是:
(1)不局限于工程平台且兼容工程平台,不受零件结构朿缚,可通过核心车型及局部拓扑模块完成大批量车型衍生,即以最少的数据量覆盖企业的全部车型。
(2)无重复建模工作,即所有新建模型均以数据库原则建立并存储到数据库中,后续开发中遇到类似的拓扑结构可以直接调用数据库模型。
1.3 利用SFE数据库搭建碰撞模型
1.3.1 白车身拼装
根据项目开发需求和车型定义,在已建立的SFE数据库中挑选各个模块拓扑形式一致或能快速修改符合需求的结构进行拼装。如果数据库中没有相似或能快速修改的模块选择,则需要少部分重建(重建的部分可以归纳进数据库中以扩展数据库模块类型)。
初步拼装完成的白车身模型需要利用SFE模型隐式参数化的特性,根据CAS数据、门洞线以及截面数据、车身尺寸信息以及总布置数据等概念参考数据以及相关约束条件进行调整。
1.3.2 SFE碰撞网格的输出
SEF碰撞仿真模型不同于刚度模态仿真模型,输出的车身网格需要与车身之外的其他总成组合成整车进行碰撞仿真实验。SFE输出的白车身碰撞模型通过PATCH与整车其他总成连接。在对应连接位置建立相关PATCH,并且PATCH ID与整车其他总成保持一致。以防SFE输出白车身碰撞网格节点号与其他总成网格节点号相同。相关设置完成以后SFE可以快速自动划分碰撞模型。
SFE白车身模型搭建完成,划分出网格数据后,替换原白车身数据,与其他总成数据拼接,即可完成碰撞数据的搭建,如图1所示。

图1 白车身模型搭建
1.4 基于SFE数据库搭建碰撞仿真模型的优势
1.4.1 时间效益
不同于传统参数化建模方式,数据库模块有直接替换和快速修改的特点,这直接改变了在早期开发中传统参数化模型修改方案的方式。利用SFE数据库搭建车身模型平均为20个工作日,相比SFE逆向建模平均40个工作日(图2),提高了一倍工作效率,同时提前了CAE分析时间节点。

图2 建模时间统计
1.4.2 性能效益
与常规CAE分析对比,利用SFE数据库搭建车身碰撞仿真模型能在早期CAD数据不足的情况下将有限元分析提前介入到概念开发阶段,及时了解整车性能表现,早发现问题早解决,有效把控进度,采用SFE数据库介入早期车身碰撞性能开发会使得早期模型具有较高的性能,可以为后续的详细开发提供指向性的优化建议及方案。
SFE车身数据库可以永久性更新,重复性使用。少量新建的模型可以扩充进数据库,丰富数据库模块类型,数据库越丰富建模效率越高,开发车型选择更广。
2 多学科多目标参数优化
通过SFE参数化模型进行Isight DOE实验方法找到白车身几何尺寸、材料牌号、零件厚度等各参数之间的最佳组合,以满足碰撞安全性能验证。确定完参数变量后,生成网格数据开始运算并提取结果。运用结果搭建近似模型,并进行误差分析,满足要求后,基于近似模型,进行仿真和优化。具体流程图如图3所示。
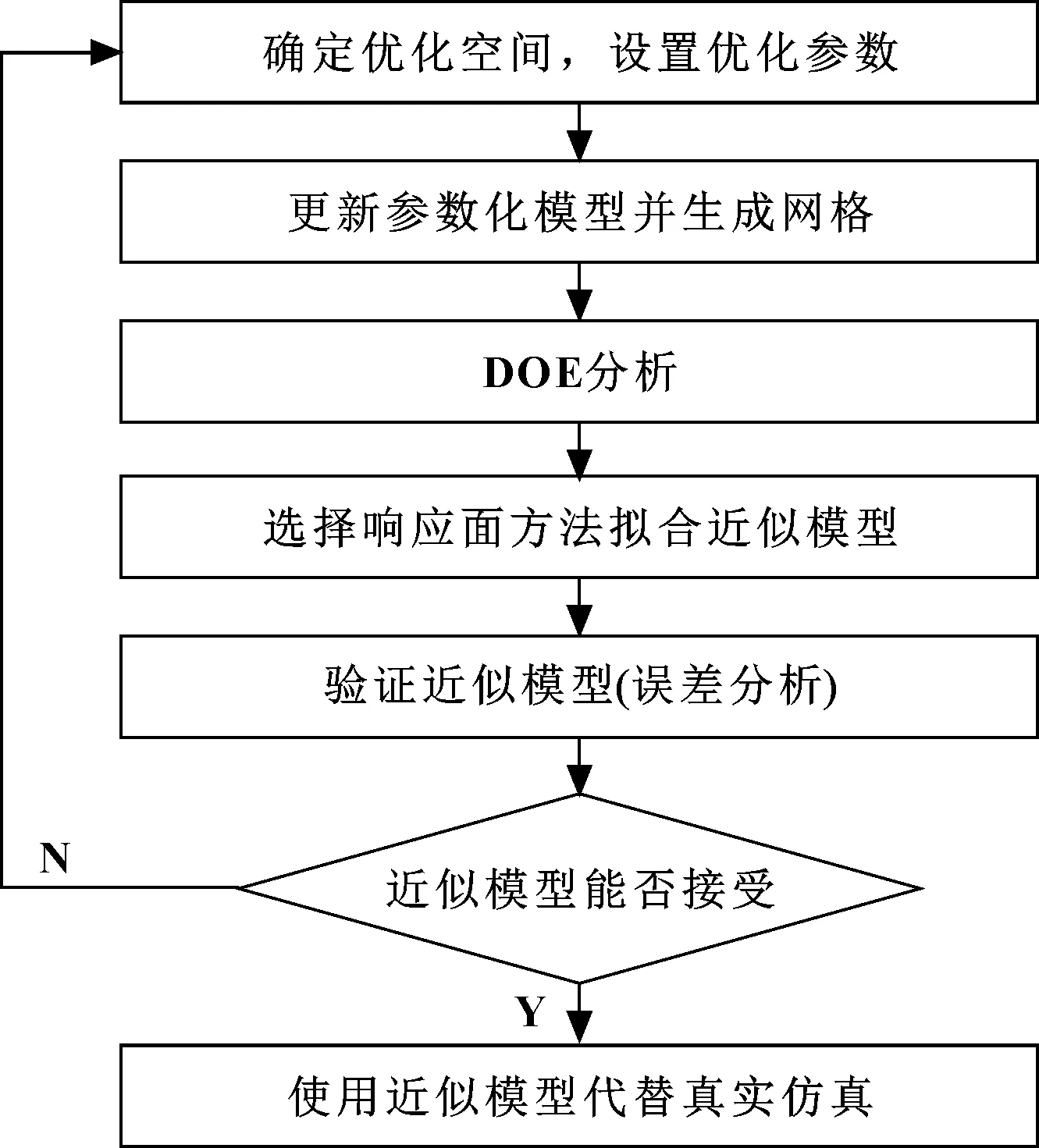
图3 参数优化流程图
2.1 优化参数
在优化前与设计部门确认相关参数优化空间,避免优化计算后发现参数不可调整,优化无效、反复。定义碰撞仿真需要验证的相关参数变量空间:几何尺寸、材料牌号、零件厚度等。
将白车身前端结构尺寸以及一些零部件的材料和料厚作为设计变量。涉及防撞梁、吸能盒、前大梁、SHOTGUN、前大梁加强板、前地板纵梁、前围板加强板、前围板横梁、中通道、前地板、上边梁和门槛梁。共材料牌号变量9个、厚度参数变量29个、截面参数变量26个。图4为录制厚度参数的部分板件;图5为部分录制的截面参数。

图4 录制厚度参数的部分板件
图5 部分录制的截面参数
2.2 试验设计方法
以概率论和数理统计原理为基础,在设计空间上选取合理有效的有限个样本点,使之能最好地反映设计空间的特性,这种方法就叫做试验设计(Design of Experiment,DOE)[6]。运行DOE共分3个步骤:试验计划、执行试验、结构分析。
试验计划需确定变量的水平和类型,研究因素的主效应、交互效应,挑选合理的试验设计方法,生成样本点,确定所需响应。
试验设计方法决定了样本点的数量与空间分布,若选取的样本点的分布并不合理或者数量不足,会导致再多的样本点也得不到精度更高的近似模型。因此在众多设计试验方法中,挑选出最合理最高效的设计试验方法尤为重要。常见的设计试验方法包括:Box-Behnken试验设计、中心组合试验设计(Central Composite Design,CCD)、拉丁超立方试验设计(Latin Hypercube)、正交矩阵试验方法(Orthogonal Arrays)、Parameter Study试验方法等。
DOE样本点选取主旨为相关参数进行相关性能优化,以节约计算量,提高优化效率。优化拉丁超立方试验设计(Optimal Latin Hypercube,OLHD)具有均衡分散性和整齐可比性的特点,能够快速生成样本点并能均匀地填充设计空间[7-8]。与中心组合相比,大大减少了试验次数,与正交矩阵相比,样本点分布更加均衡。此方法生成的样本点能更好反映出试验指标与试验范围内各因素的关系。适用于车身结构优化样本点的选取。
故选取拉丁超立方生成样本点,通过ISIGHT软件调用SFE Concept软件,根据预先设定的参数变量,自动生成240个ODB有限元模型后,提交到服务器上计算。
运用基于Hyperworks二次开发的脚本,自动读取240版碰撞模型的各种性能指标。
2.3 近似模型方法
近似模型方法通过数学模型的方法,模拟众多输入参数与输出参数之间的响应关系。用近似模型替代实际工程问题,能够避免高强度仿真计算,减少迭代时间,并预测最优解[9]。
与传统对比如图6所示。预估输入输出参数间的响应关系,有效地避免局部优化解,找到全局最优解,可与DOE组成更好的优化策略。

图6 优化策略
近似模型原理:基于试验设计方法,抽样获得大量样本数据,用回归、拟合、插值等方法创建安全仿真的近似模型。
拟合近似模型的常用方法有:多项式响应面方法(Response Surface Methodology,RSM)、克里格方法(Kriging)和径向基神经网络方法(Radial Basis Functions,RBF)等。
多项式响应面方法(Response Surface Methodology,RSM)是响应面方法中最为常用的方法,在结构分析与优化中用于近似分析,其基本原理是根据已知设计点信息,构建多项式拟合模型,一般常用的为二阶多项式[10]。二阶多项式响应面近似模型具有相当高的近似精度,在多学科优化中,可替代耗时的有限元计算。
文中为了在较短时间内得到较为准确的结构,选用二阶多项式响应面方法拟合近似模型,并基于近似模型得到了各参数变量对于各性能指标的相关性以及贡献量。同时对近似模型的精度进行误差分析,前围板侵入量的误差结果如图7所示,大部分介于-3~3之间。
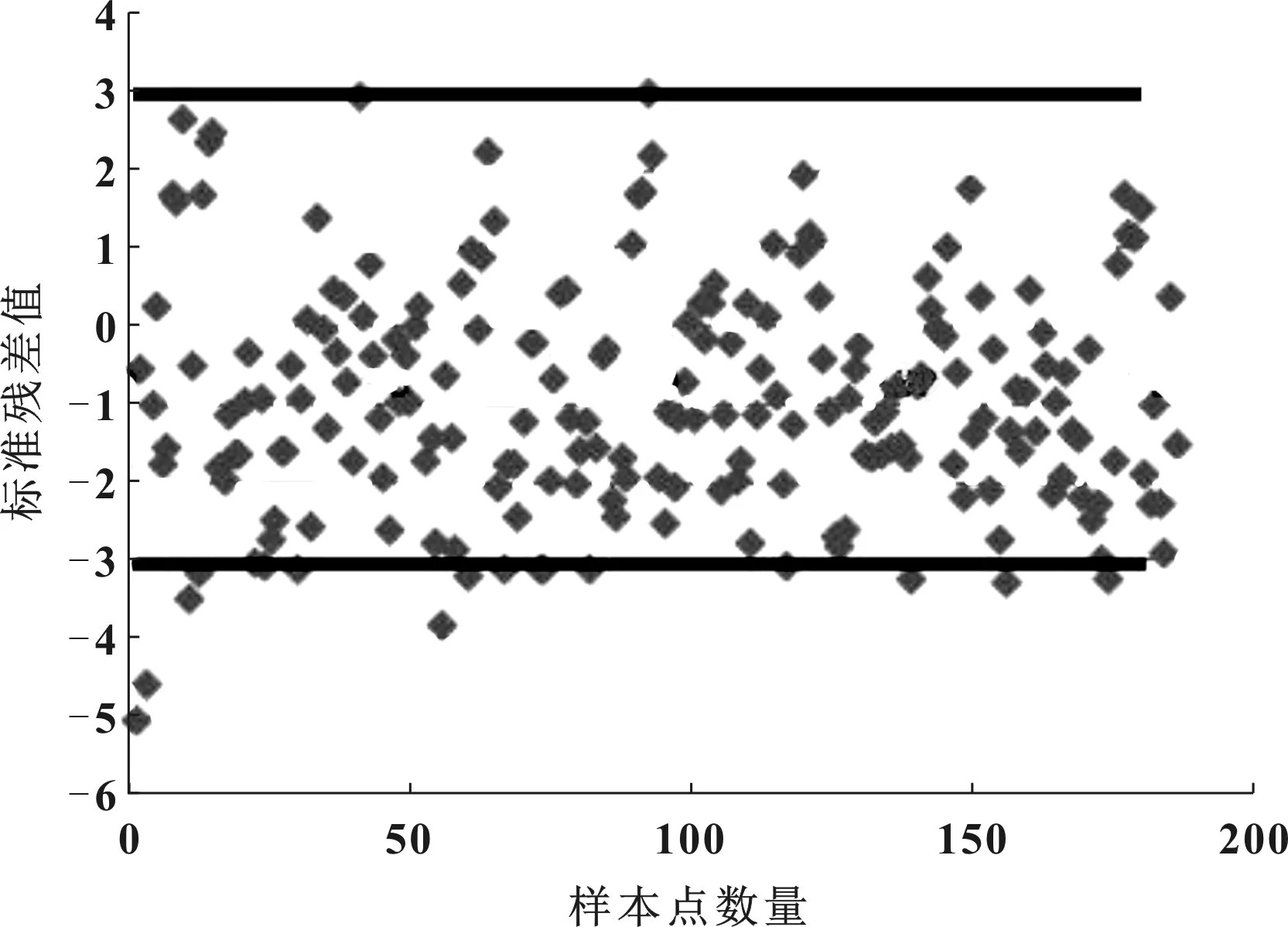
图7 误差结果
2.4 多目标优化算法
实际项目中,约束函数和目标设计变量可能是线性的连续单峰的函数或是非线性的离散多峰的函数;设计变量可能是连续的或是离散的,问题较复杂。需根据不同的情况,选择不同的优化算法。
根据优化算法的适用范围,优化算法可分为局部优化算法和全局优化算法。局部算法包括直接搜索算法和梯度优化算法,这种算法运算求解效率很高,但存在寻找不到全局解的可能性。
全局优化算法中有一种由进化理论和遗传变异理论为基础理论的遗传算法(Genetic Algorithm,GA),此种算法与局部优化算法相比,能够在全局空间内搜索优化解,但是这种算法运算求解效率相对较低。
实际项目中的优化目标较多,而且往往优化目标之间是互相矛盾、制约关系。针对此问题,在遗传算法基础上发展的多目标遗传算法给出了解决方案。多目标遗传算法共分为两代。第一代多目标遗传算法主要包括:多目标遗传算法(MOGA)、非支持排序遗传算法(NSGA)、Niched-Pareto遗传算法(NPGA)。
第二代多目标遗传算法包括:Strength Pareto遗传算法(SPEA)、Pareto Archived遗传算法(PAES)、非支配排序遗传算法II(NSGAII)和序列二次方遗传算法(NLPQL)等。
序列二次方遗传算法(NLPQL)特点是算法效率高、对求解非线性性能目标具有高稳定性、能快速收敛到高质量的优化解。
通过寻求车身质量最小的同时满足其他相关性能要求,或者在满足质量要求寻求更优其他性能指标。以此分析质量以及性能指标的带宽。
根据多种约束与目标的设置,进行多轮优化,最终得到最优结果。部分具体设计变量优化后的前后对比见表1。
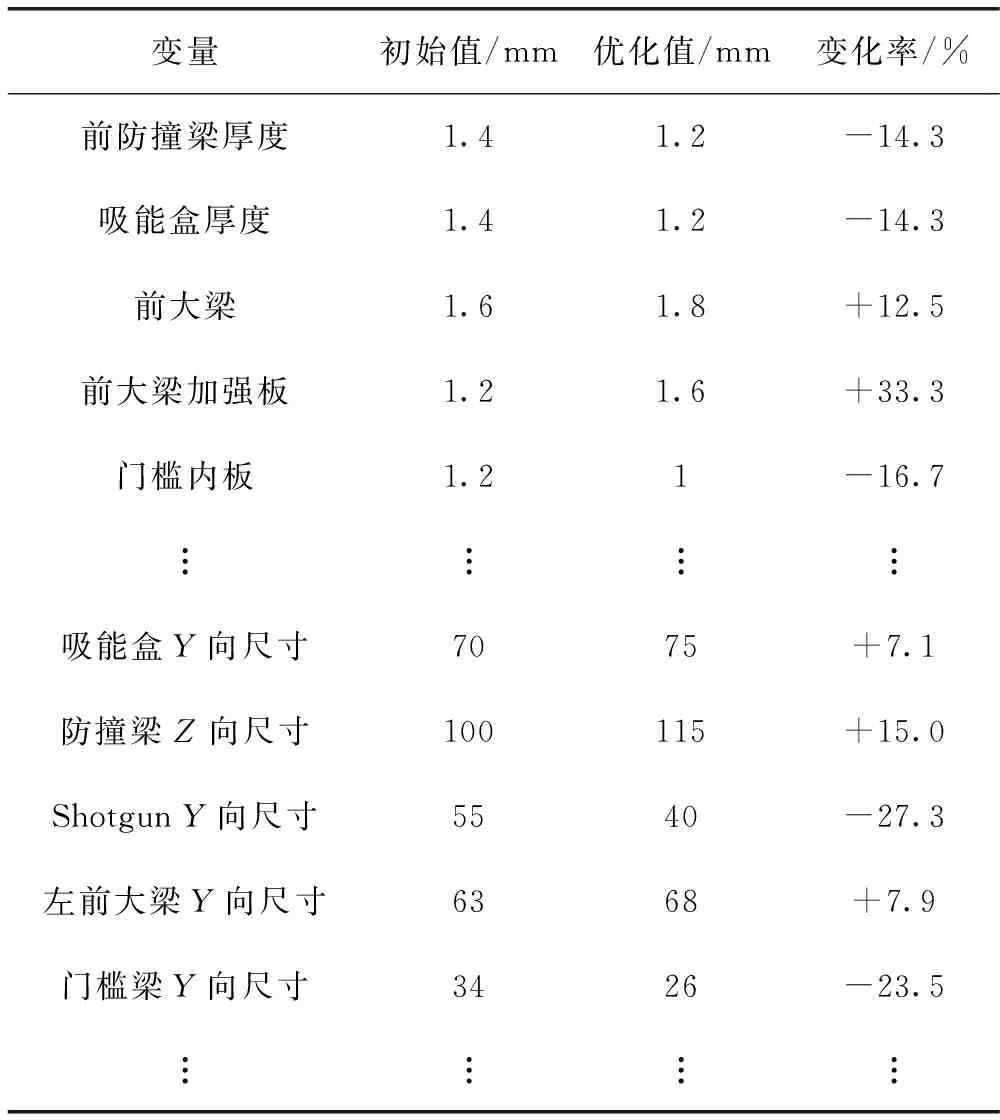
表1 设计变量优化结果
2.5 详细设计与结果验证
将优化算法得出的最优优化结果的参数(几何尺寸、材料牌号、零件厚度等)代入SFE模型自动划分有限元网格,并分别进行碰撞性能验证。对比实际仿真结果与IsightDOE实验输出结果误差。包括加速度曲线、最大侵入量、质量等。
经实际碰撞模型仿真分析得到结果,部分数值见表2。
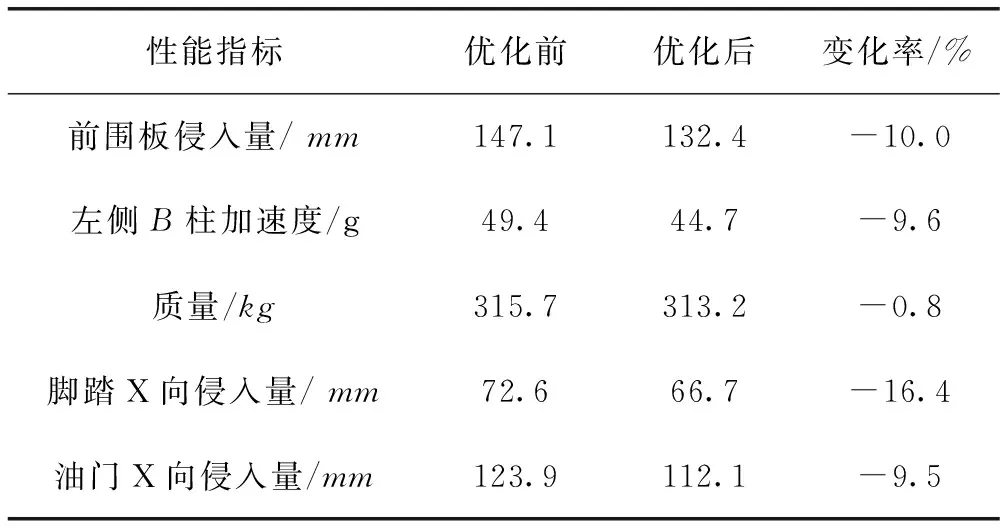
表2 碰撞性能优化结果
图8为优化前后左侧B柱加速度曲线对比,加速度峰值优化前为49.4g,优化后为44.7g,降低了9.6%。

图8 优化前后左侧加速度曲线对比
图9为优化前后前围板侵入量曲线对比,侵入量峰值优化前为147.1mm,优化后为132.4mm,降低了10%。
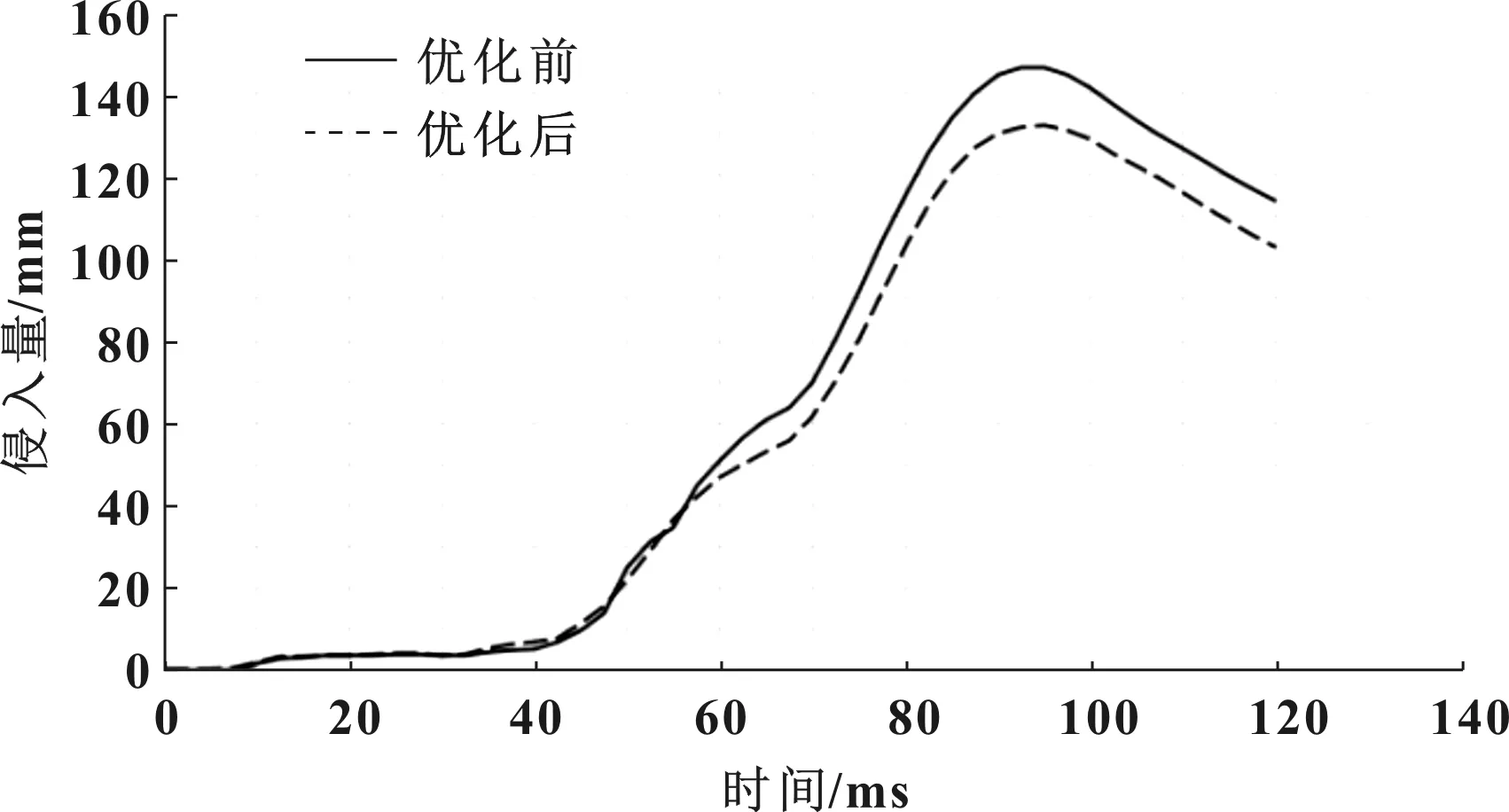
图9 优化前后前围板侵入量曲线对比
在ODB工况下,白车身优化后降低了前围板、三踏板侵入量和左侧B柱加速度,全面提升性能的情况下,又减少2.54kg。轻量化的同时,又达到了提升性能的要求。
最后,结合制造工艺和车身结果工程经验,对优化得到的结果,进行进一步判断与详细设计,实现参数化模型数据库在早期碰撞性能的预研。
3 结论
(1)基于参数化模型数据库可以快速地搭建早期车身碰撞性能仿真模型,利用SFE模型的参数化特性能快速有效地验证截面参数、材料牌号、零件厚度变更等方案。
(2)运用DOE实现了车身系统结构优化设计的自动循环运算。克服了提升车身综合性能和缩短整体开发周期难以兼顾的矛盾。在车身早期概念开发阶段实现CAE分析驱动CAD设计,为设计部门提供重要的整车性能信息和车身设计方向,达到参数化模型数据库在早期碰撞性能的预研的目的。
