基于深度学习的维吾尔文扫描体识别
2021-03-27吾守尔斯拉木许苗苗熊黎剑王明辉
汤 敬,吾守尔·斯拉木,许苗苗,熊黎剑,王明辉
(1.新疆大学软件学院,新疆 乌鲁木齐 830091;2.新疆大学信息科学与工程学院,新疆 乌鲁木齐 830046)
0 引言
中国作为一个多民族的国家,维吾尔文是目前中国使用比较多的少数民族语言之一,尤其是新疆作为维吾尔族的主要聚居地,人们平时的交流、学习等方面都会频繁地使用维吾尔文,并且有关维吾尔文的文献资料也相当多,而现有技术在中文的图像文字识别中已经广泛应用,相比之下维吾尔文图像文字识别的研究相对落后了很多,因此研究维吾尔文的图像文字识别有着重要的意义.
文献[1-4]针对维吾尔文图像识别是采用对单词文字进行先切分,然后再来识别的思想,分析如何切分更好才能使识别结果更优.其中有关将单词不进行切分,整体直接识别的研究相对来说还是较少.由于维吾尔文文字自身的特点,其是粘连型的文字,所以在进行切分的时候具有很大的难度,是过往切分研究中的难点之一.
随着深度学习在视觉研究领域所展现出的强大性能,其在英文和中文的图像文字识别中也表现非凡,从众多科研人员展示的实验研究结果中也可以看出深度学习优于传统方法.所以在维吾尔文图像文字识别中使用深度学习的方法来整体识别文字就可以避免切分.已有的关于维吾尔文的研究中,贾建忠[5]在研究维吾尔文文字识别时采用的神经网络研究是对单个字符的识别,在单字符的识别上有着不错的效果.
本文建立了维吾尔文图像识别的数据集,提出了TRBGA模型.
1 深度学习
1.1 深度学习概念
深度学习(deep leaning,DL)来源于人工神经网络,其概念是由G.E.Hinton等[6]在2006年提出,从此开启了深度学习在学术界和工业界的浪潮.深度学习是目前最成功的表示学习方法,它把表示学习的任务分成几个小的目标,可以先从原始的数据中学习低级表示,之后从低级表示学习到高级表示.这样,机器就更容易自主地将这些小目标学好,从而完成最终学习任务,并且省去了人工选取过程[7].目前深度学习在算法、模型、硬件设施与开发社区都取得了重要的突破[8],解决了之前神经网络难于优化、应用有限等问题.目前深度学习在计算机视觉领域大放异彩,其中卷积神经网络、循环神经网络、深度残差网络、密集卷积网络等常被使用.
1.2 深度学习模型介绍
1.2.1 卷积神经网络
卷积神经网络(CNN)的英文全称是“Convolutional Neural Network”.而神经网络的灵感来自于生物神经网络的功能和结构,并以此提出一种计算模型.CNN可以从端到端的通过传统的方法训练并学习图像的特征[9].CNN网络最早可以追溯到1989年[10].近些年它在图像分类的问题上获得了成功.目前,CNN在图像识别领域也有着广泛的应用.CNN作为一种人工神经网络,其结构特征主要由输入层、卷积层、池化层、全连接层组成,其中卷积层主要是提取特征,池化层下采样,全连接层用来做分类.其结构如图1所示.得益于现在GPU所提供的强大算力支撑以及网络中加入激活函数RuLu,原来难于处理的大量数据,现在处理起来变得容易很多,计算时间大幅减少、收敛速度也更快.

图1 卷积神经网络结构
1.2.2 循环(递归)神经网络
循环神经网络(Recurrent Neural Networks,RNN)[11]中神经元的输出可以在下一个时间戳直接作用到自身,这样可以在普通的CNN或全连接网络里解决,由于每层神经元的信号只能向上一层传播导致样本的处理在各个时刻是独立的,以及全连接的DNN会因为时间序列上的变化而无法对其进行建模等问题.RNN被设计出来的目的是用来处理序列相关的数据,其核心思想就是将当前时刻的输入与上一个时刻的输入一起作用于当前时刻输入的计算,这样隐藏层之间的节点就变得有连接了,而传统的神经网络每层之间的节点是无连接的.与CNN网络通过空间上参数共享从而减少参数的思想不同,RNN的参数共享体现在时间序列上.目前RNN在语言建模、语音识别[12]、机器翻译[13]、生成图像描述、视频标记等领域都有很好的应用.RNN结构示意图如图2所示.
1.2.3 残差网络
理论上讲,神经网络层数越多能提取到的特征信息就越丰富,也就越具有语义信息.在计算机视觉领域,兼有分辨率信息和语义信息的网络才能获得更好的性能,单靠浅层网络提取的分辨率信息获取的效果会降低.采用堆积神经网络层数来提取特征应该会有好的性能,但实际情况却与之相反,深层的网络结构不仅会出现性能退化,而且带来了梯度消失或爆炸的问题,通过初始化数据和正则化等传统方法解决了梯度的问题.
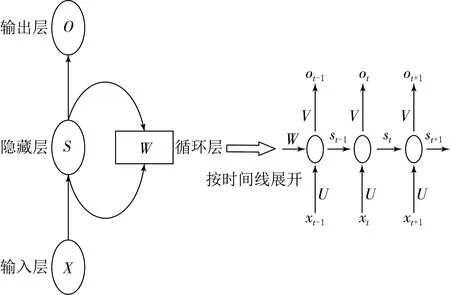
图2 RNN结构
文献[14]提出来的残差网络(ResNet)在提升性能的同时也很好地解决了加深神经网络层数带来的缺陷.ResNet的核心思想是引入了身份近路连接(IdentityShortcut Connention),也就是浅层特征和深层特征的一个简单相加,将一个跳跃(skip connection)添加到标准前馈卷积网络来绕过一些中间层,实际效果相当好,在保持原有网络性能的同时,通过加深网络层数来提高网络性能.目前残差网络已经在计算机视觉[15]等领域得到了广泛的使用.其结构如图3所示.
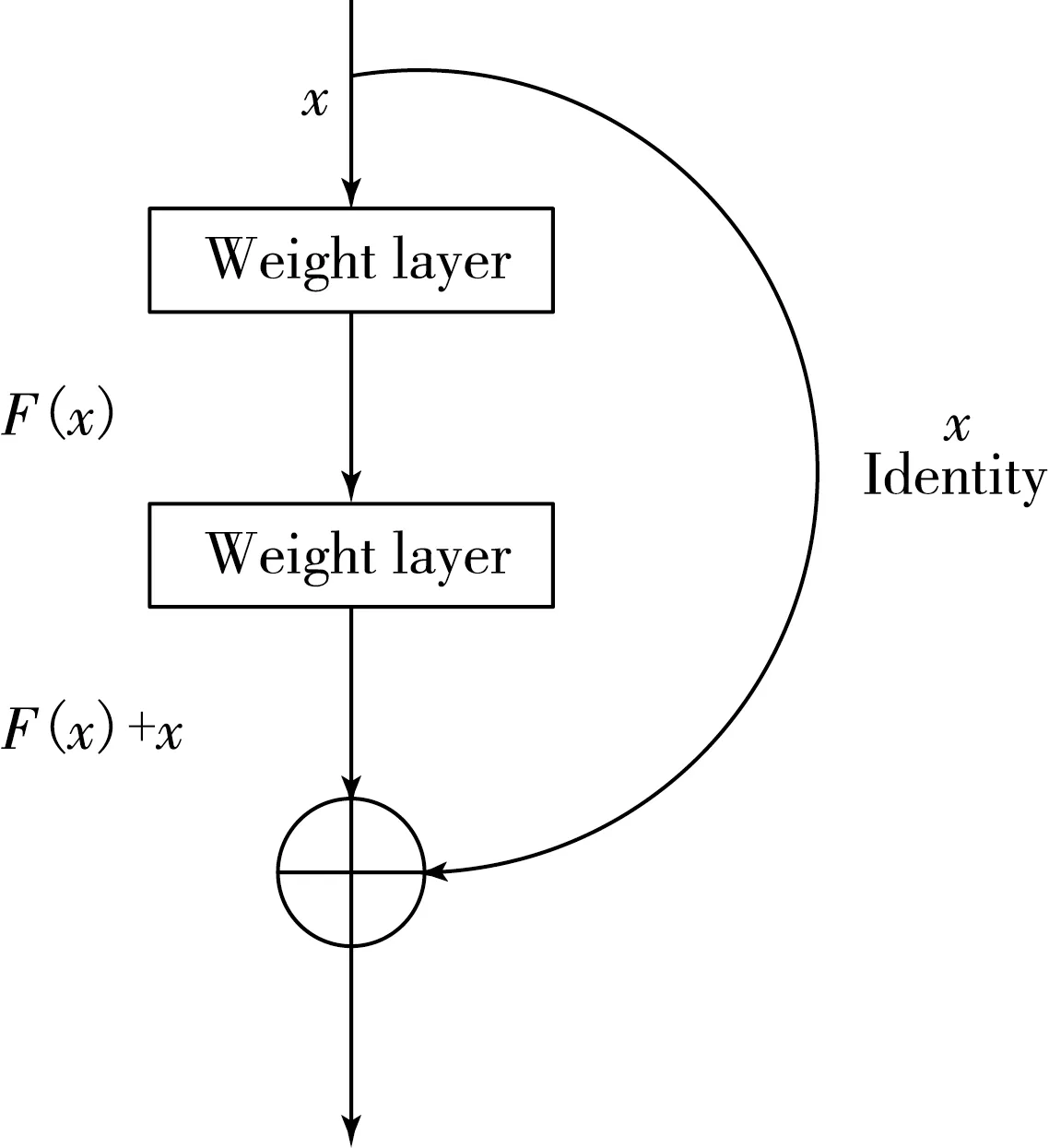
图3 残差网络结构
1.2.4 密集卷积网络
加深的网络可以带来丰富的表达,从AlexNet和VGG等可以看出研究人员在深度问题上一直在研究.但更深的网络又不可避免带来梯度消失问题,随后ResNet、Highway Networks、Stochastic depth[16-18]等网络都是针对该问题提出的,尽管这些网络结构不同,但是它们的核心点是相似的,都是构建一个从早期层到后期层的短路径.
G.Huang等[19]提出的密集卷积网络(DenseNet)借鉴了ResNet的设计理念,并在此基础上推陈出新.为了保证网络之间各层能有最大的信息流动来进行更加有效地训练,DenseNet采用了一种更为密集的连接方法,通过前向传播将各层和其他层密集地连接起来.在普通卷积神经网络里,网络有多少层就有多少连接,其模式是一对一的,在DesnseNet网络中就不一样了,各层会和所有的其他层进行连接,L层的DenseNet网络将有L(L+1)/2个连接,对于每层来说,在它前面的各层的特征都将作为它的输入,同时它的特征也将会和它前面的层一起作为其后各层的输入.DenseNet网络结构有效地缓解了梯度上的问题,网络层间特征的传播得以加强,支持特征重用,同时也在很大程度上减少了参数量,其结构如图4所示.
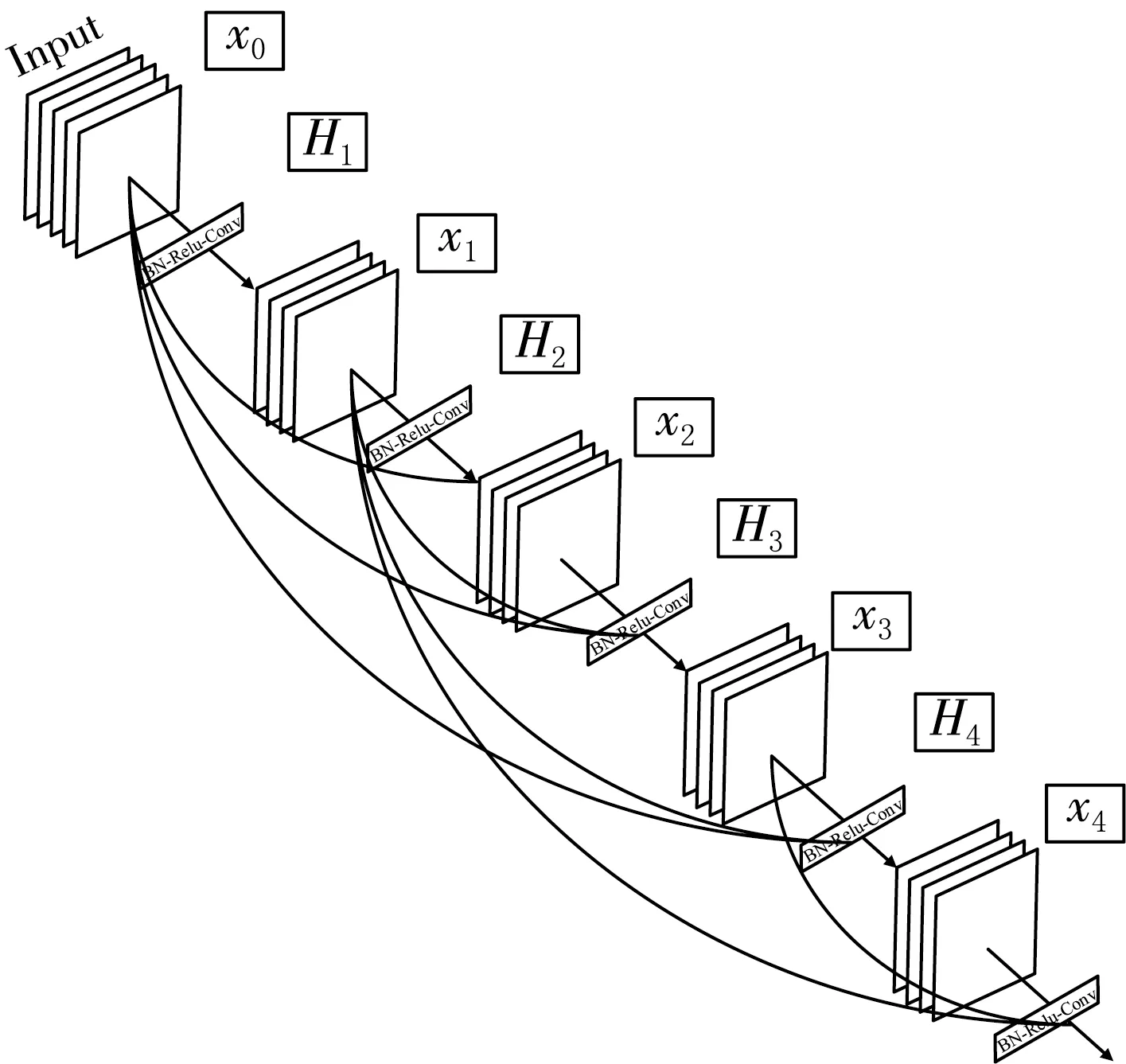
图4 密集卷积网络结构
2 基于深度学习的图像文字识别模型
维吾尔语的图像文字的识别过程主要步骤是先对输入进来的图像进行特征提取,在经过循环层来学习上下文的语义信息,最后通过CTC或者Attention生成最终的标签.如图5所示.
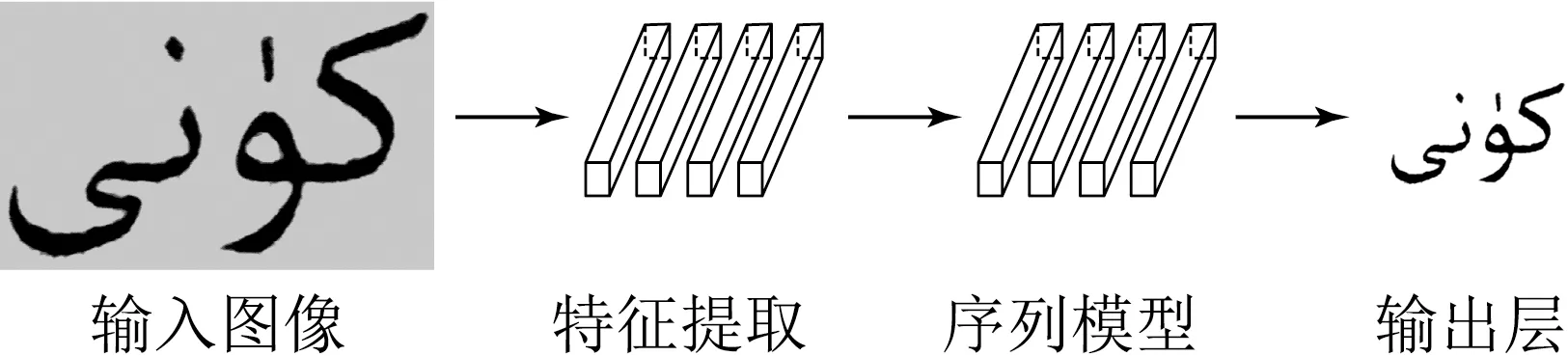
图5 识别模型结构示意图
2.1 CRNN模型
CRNN(Convolutional Recurrent Neural Network)[20]是一种端到端的模型,该网络结合了DCNN和RNN 2个模型,可以用来对长度不固定的图像进行序列识别.在该模型出来之前传统的识别方式都是先切分,然后再来识别的,用来识别的算法不仅烦琐而且可读性也很差,同时存在着许多的问题无法解决,比如粘连型的文字.CNN在提取图像表征特征上表现优异,RNN在处理序列相关的问题上具有优势,这样将两者结合起来的神经网络在需要对有时序的数据建模上表现惊人,因此不仅在音频、自然语言等领域得到了广泛应用,在文本序列识别研究的领域也带来了本质革新.
CRNN模型由3部分网络结构组成,分别是卷积层、循环层以及转录层(CTC)[21].
卷积层部分通过普通神经网络中的卷积层和最大池化层来提取输入进来的图像的序列信息,经过该层后的图像将被统一到相同的高度,也就是在空间上对图片进行了保序和压缩处理,相当于在水平方向上,图像被切成了若干片,然后从这些切片中提取出相对应的特征向量作为下一步循环层的输入.虽然卷积学习到的是每一列上的特征,但是这些特征与输入图像的一块区域是相对应的,也就是卷积网络的感受野之间是重叠的,这样就有了上下文有关的信息,为后面的RNN学习上下文特性提供了可能.
循环层部分使用一个双向双层的LSTM结构,LSTM是RNN的变形,其在学习序列有关的上下文信息上表现出色,因此图像识别时加入LSTM使得模型变得更稳定和有效.在网络训练中,RNN可以将误差值再反向传给卷积层,这样,卷积层和循环层就可以一起训练.另外RNN可以训练并学习长度不定的序列.
CTC层的工作是将RNN层每一帧的预测转成序列标签,在模拟动态规划的过程找出最高概率的序列标签.CTC中加入了空白类,通过一定的映射法则去除重复的序列,得到最终目标.其示意图如图6所示.
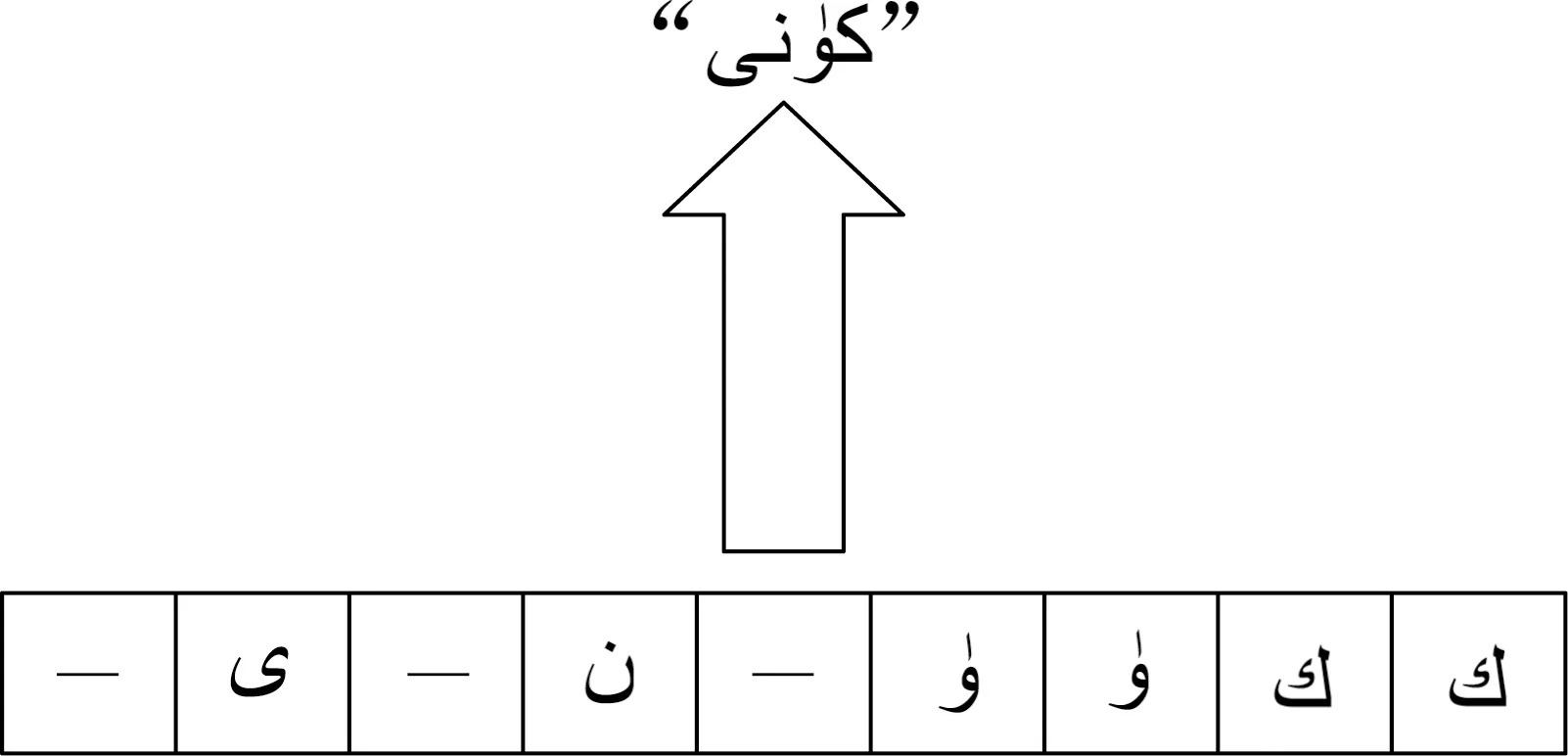
图6 CTC转录示意图
本文中测试运行了CRNN网络,其在维吾尔语识别中也有着不错的表现.
2.2 基于转换层(TPS)的深度学习模型
TPS的主要功能是将输入进来的图形X转换成归一化的图形X′.传统的池化方式(Max Pooling/Average Pooling)所带来卷积网络的位移不变性和旋转不变性只是局部的和固定的,而且池化并不擅长处理其他形式的仿射变换.TPS是一种基于样条的数据插值和平滑技术,是空间变换网络(STN)[22]的一种变体形式,而TPS非常强大的一点是它可以近似所有和生物有关的变形.因此,使用TPS可以在图像上找到多个基准点,然后基于这些基准点进行TPS转换成我们所期望的矩形,从而减轻网络的学习负担.
根据实验的需要选择适合实验的网络,本文选择了用ResNet来提取特征,并做了层数上的调整,采用了33层的ResNet提升网络的识别性能.
本文的序列层采用了和CRNN模型一样的BiLSTM,另外稍微做了调整,将第一层的LSTM换成了GRU层,GRU也是RNN的变体形式.
预测模型部分的主要任务是将输入H预测出一个字符的序列Y(Y=y,y,…).
本文的预测选择是基于Attention的模型,从文献[23]所做的大量对比实验可以看出,在提升识别的性能上面Attention的模型要优于基于CTC[24]的模型,所以在实验中直接选用了Attention的模型作为该阶段的预测模型[25],通过Attention来自动捕获输入进来的序列的信息流,并以此来预测出字符的输出序列.
在该Attention中用了一层基于LSTM的注意力机制的解码器.在第t步时,LSTM解码器将预测一个输出
yt=Softmax(WoSt+bo).
(1)
其中:Wo和bo是训练参数,St是LSTM解码器隐藏层在t时刻的状态.其中
St=LSTM(yt-1,ct,St-1).
(2)
式中ct是权重H(H=h1,…)的和,h来自于前面的网络.其中
(3)
式中的αti是attention的权重,计算公式为
(4)
eti的计算公式为
eti=vTtanh(Wst-1+Vhi+b).
(5)
式中v,W,V和b都是网络训练中的参数,该LSTM隐藏层使用的维数设置为256.
2.3 目标函数
实验训练中,训练数据集用TD= {Xi,Yi}来表示,其中Xi表示用来训练的图像,Yi表示训练的图像对应的单词标签.公式为
(6)
该目标函数通过图像及其对应标注的单词标签来计算成本,从而进行端到端的模型训练.
3 实验过程及结果
为了保证实验各项环境的一致性,本文所有的结果都是在相同的训练数据集、验证数据集、测试数据集以及计算性能上完成的.
本文是在CPU Intel Xeon 1.70 GHz、12 GB的GPU内存、Ubuntu18.04系统下搭建Pytorh的环境下进行的.实验环境以及配置参数如表1所示.

表1 实验环境配置参数
3.1 数据集
针对目前用于维吾尔文训练的数据集不足,难以达到深度学习训练的数据量.首先是收集整理维吾尔文图像文字的相关数据,为此从两方面进行了数据集的收集工作.
(1) 真实样本的采集.在新疆的天山网站上收集了大概50份的维吾尔语的新闻,然后通过脚本去除重复的单词以及符号写入word文档,一共采集了9 379个维吾尔文单词.然后通过打印机打印出来后用扫描仪扫入电脑,通过工具以单词为单位裁剪出可用于训练的图像.其中训练集7 397张、验证集991张、测试集991张.如图7所示.

图7 真实扫描体数据
(2) 合成数据集.尽管训练集采用真实数据集对实验的提升有着极大的帮助,但考虑到真实数据集的制作需要耗费大量的时间和人力,所以采用真实样本加合成样本的方案有其必要性,根维吾尔文由32个字母组成,有的字母的变体形式多达4种,所以形式一共有128种.本文中一个字符的多个变形仍视为该字符本身.因为和代表同一个字母,计算机没有做区分,所以显示的是33个字符.之后通过脚本以扫描体图片为背景,在上面合成随机的维吾尔文字符生成了10万张的图片,并请维吾尔族的同学做了后续的检查后,将合成数据集与真实样本的训练集一起作为本实验的训练集,一共是107 395张图像.合成数据如图8所示.

图8 合成数据示意图
3.2 实验结果对比分析
在该数据集上分别使用CRNN模型、RBA(ResNet+BiLSTM+attn)、CLOVA-AI v2(TPS+ResNet(29)+BiLSTM+attn)以及TRBGA(TPS+ResNet(33)+BiLSTM+GRU+attn)模型做了对比实验,实验结果如表2所示.

表2 实验结果
从表2中可以看出神经网络在维吾尔文图像文字识别中有着优异的表现,其中我们提出的模型TRBGA准确率达到了99.395%,是目前几个模型中最优的算法.
4 结论
本文对维吾尔文图像文字识别进行了深入的研究,收集制作维吾尔图像识别数据集和改进维吾尔图像文字识别的算法.其中构建的维吾尔文图像文字数据集对后续的维吾尔文识别研究有积极的促进意义,提出的TRBGA模型与主流的网络做了对比实验,实验结果显示所提出的识别准确率达到了99.395%,优于传统模型算法.
