基于IMI-WNB算法的垃圾邮件过滤技术研究
2021-03-26吉小鹏
吉小鹏
(南京理工大学自动化学院,江苏 南京 210094)
0 引言
工业互联网快速发展的今天,在信息传递上起到关键作用的电子邮件深刻改变了工作方式,与此同时大量无效的垃圾邮件却成了工业互联网界难以解决的问题,对邮箱存储和网络传输都造成了巨大困扰[1]。到目前为止,垃圾邮件过滤的方法主要包括基于黑名单过滤、基于行为识别过滤以及基于内容过滤等手段。由于从邮件文本中提取互信息特征,并通过朴素贝叶斯分类的方法简便、快捷,基于此方法的内容过滤逐渐成为了垃圾邮件的主流上应用技术[2]。
实际上,传统互信息方法并未计算出词频度,导致词频对互信息的偏置影响较大[3]。另外,多个垃圾邮件类别的样本差异性对朴素贝叶斯方法也较为敏感,造成传统方法对于样本差异较大的情况出现较高的误检率或漏检率。因此,在文本中,通过引入词频率因子和类别间差异因子来改进互信息计算,并将计算结果作为朴素贝叶斯分类的属性权重,建立基于IMI-WNB的垃圾邮件过滤算法,完成对垃圾邮件过滤的鲁棒性,降低垃圾邮件过滤时的误检率和漏检率。
1 基于IMI-WNB算法的工业互联网垃圾邮件过滤算法
1.1 改进的IMI互信息算法
传统互信息算法在计算过程中仅考虑文本频率,并未统计词出现的频率,在词频率不均衡的工业互联网垃圾邮件文本中过滤效果较差[4]。例如,文本频率相同的两个词,但是词频率的特征差距较大,在传统方法中认为词频率特征更大的词具有与类别更高的相关程度。然而,这种情况下采用传统方式互信息计算方式相关程度相同,与实际情况显著不符。因此,本文分别引进词频率因子和类间差异因子对IMI互信息算法进行改进。
首先,引入词频率因子α用于描述不同词频率特征之间的差异性,通过下式定义:

根据上述定义可以看出,如果某个特征的词频率高于文本频率,那么相应的词频因子的权重将会更大,此时垃圾邮件过滤时采用该特征的比重将会越高。
此外,当多个类别中的特征分布不均匀导致对类别的判定产生影响时,一般在某些类别中出现的次数较多而在另一些类别中出现的次数较少,这种情况下一般可认为该特征对于工业互联网垃圾邮件过滤的影响较大。实际上,这样的特征在统计学中被称为标准差较大的特征,能够反映出邮件文本的离散程度,从而有利于垃圾邮件的过滤。因此,在本文中,我们通过垃圾邮件Cspam和正常邮件Cham之间特征频率wi的标准差改进互信息计算过程。假设垃圾邮件中特征的频率为tfCspam(wi),正常邮件对应的特征频率为tfCham(wi),二者共同的平均特征频率为tfavg(wi),那么可以表示为:

上式(7)在式(3)的基础上增加了不同类间的频率差异权重因子,因而能够在对垃圾邮件过滤过程中体现出类间频率差异的影响,从而提升互信息计算方法的特征选择效率。
1.2 基于改进的IMI互信息的朴素贝叶斯算法
针对工业互联网垃圾邮件过滤的分类算法通常采用朴素贝叶斯分类器(NB),通常传统NB中的条件独立性假设会对工业互联网垃圾邮件的过滤造成不利影响[5]。因此,在本文中,我们通过在贝叶斯概率公式中添加属性权重,通过权重控制不同特征对于垃圾邮件过滤的贡献。实际的属性权重可通过改进的IMI互信息值获取,互信息值的结果偏大表明特征与类别相关程度较高,反过来,互信息值偏小则表明特征与类别相关程度较低。通过互信息值作为NB的属性权重,我们新提出的WNB将会消除独立性假设的影响,保证垃圾邮件过滤的稳定性。通常来讲,带权重的WNB的分类过程可以表示为:

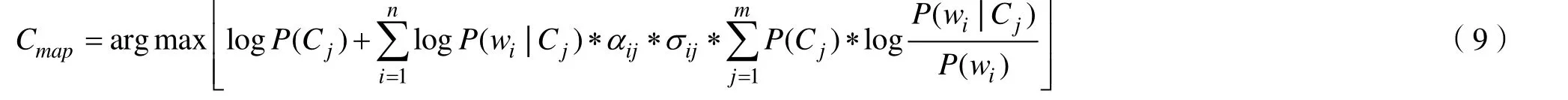
综上,本文提出的基于IMI-WNB的工业互联网垃圾邮件过滤具体过程如下:
(1)预处理阶段处理邮件文本的停用词,然后将文本完成自动分词;
(2)采用改进的IMI互信息算法选择分词后的文本特征,筛选过滤无关的特征;
(3)统计邮件文本训练样本的先验概率、条件概率,然后使用IMI-WNB算法完成最大后验概率的求解,通过概率是否超过阈值,判断是否为垃圾邮件。
2 仿真实验与结果分析
为了验证本文提出的基于IMI-WNB算法的工业互联网垃圾邮件过滤算法可行性与有效性,我们采用能明显反映工业互联网特性的trec06c开源邮件语料库,进行工业互联网垃圾邮件过滤对比实验。实验对比的算法对象包括传统NB算法以及改进的IMI-WNB算法。实验平台为Unbutu11.0,硬件配置为i7-6700K CPU配合16GB内存以及SSD固态硬盘,实验编程平台采用Matlab R2012b。由于实验采用的trec06c语料库中邮件文本较多,我们在具体实验中采用其中较为关键的15000个邮件样本,其中7500个垃圾邮件,7500个正常邮件,两种类别的样本数量保持均衡。为了对实验结果进行客观评价, 我们在实验中采用准确率和召回率两种指标对算法进行客观评价。针对开源邮件语料库的垃圾邮件过滤对比实验步骤如下:
(1)对所有15000个包含垃圾邮件和正常邮件的样本进行分词处理,并通过查找停用词表保留能进行垃圾邮件过滤的主要特征。在特征提取中,分别采用传统的互信息特征提取以及本文改进的互信息特征提取方法获得对应的特征集合TMI和TIMI;
(2)分别从互信息特征集合以及改进的互信息特征集合中n提取个样本 {t1,t2,...,tn},分别组成邮件文本特征向量RMI和RIMI,将特征向量集合作为NB的属性权重产生WNB分类算法,并通过IMI-WNB算法完成对垃圾邮件过滤的训练和验证;
(3)为了进行垃圾邮件过滤的训练和验证,我们在本文中采用经典的十乘交叉验证方法进行训练和验证。其中,我们将15000个样本随机大乱,并划分为10份,每次验证取其中的9份作为训练样本集合,剩下的1份作为验证样本集合。最后,将十次验证结果的平均准确率、平均召回率以及平均F-score记录下来,通过记录的数据验证本文提出算法的可行性与有效性。
经过十乘交叉验证后,图1(a)给出了传统NB算法与本文改进IMI-WNB算法的平均准确率对比。从图1(a)中的结果可以看出,传统NB算法能够在较低的特征维度(<50)时保证垃圾邮件过滤时的精准率上升,当特征维度较大的时候传统算法的垃圾邮件过滤准确率出现下降,直到特征维度超过200维时才继续上升。相比于传统NB算法,本文提出的IMI-WNB算法在较低特征维度时的准确率差距不大,但是随着特征维度的提升,传统NB算法的垃圾邮件过滤显著下降,但是IMI-WNB算法却只有少量的精度下降,随后一直保持精确度上升的趋势,本文提出算法在召回率上具有较强的鲁棒性。

图1 传统NB算法与本文改进IMI-WNB算法的对比
此外,图1(b)给出了传统NB算法与本文改进IMI-WNB算法的平均召回率对比。从图1(b)中的结果可以看出,传统NB算法能够在较低的特征维度(<20)时保证垃圾邮件过滤时的召回率上升,当特征维度较大的时候传统算法的垃圾邮件过滤准确率出现下降,直到特征维度超过180维时才继续上升。相比于传统NB算法,本文提出的IMI-WNB算法在较低特征维度时的准确率差距不大,但是随着特征维度的提升,传统NB算法的垃圾邮件过滤显著下降,但是IMI-WNB算法却只有少量的精度下降,随后一直保持精确度上升的趋势,本文提出算法在召回率上具有较强的鲁棒性。
表1给出了垃圾邮件过滤的常用算法与本文提出算法的计算性能对比。从表1的结果中可以看出,经典的PTw2v算法在准确率和召回率上差距不大,垃圾邮件过滤效果较好;本文提出的IMI-WNB算法比传统C4.5算法拥有更高的召回率,因此垃圾邮件的漏检率显著低于传统算法;GWO_GA算法虽然具有较高的召回率,但是其准确率却显著低于本文提出的IMI-WNB算法,因此正常邮件的误检率显著高于本文提出算法。

表1 主流算法与本文提出算法的性能对比
综合上述实验结果可以看出,本文提出算法在鲁棒性上优于传统的NB分类、PTw2v等算法,在准确率和召回率的双向对比上也优于近年来流行的C4.5 和GWO_GA算法。因此,本文提出的IMI-WNB算法对垃圾邮件过滤具较高的准确性和鲁棒性。
3 结论
在本文中,为了解决传统工业互联网垃圾邮件过滤时的词频、样本类别差异对漏检率和误检率的影响,提出了一种全新的工业互联网垃圾邮件过滤算法。该算法通过引入词频率因子和类别间差异因子来改进互信息计算,并将计算结果作为朴素贝叶斯分类的属性权重,建立基于IMI-WNB的垃圾邮件过滤算法。在开源数据集上的对比实验结果表明,本文提出算法能够比传统算法获得更鲁棒的垃圾邮件过滤结果,有效降低了垃圾邮件过滤时的误检率和漏检率。
