可缓解类重叠问题的跨版本软件缺陷预测方法
2021-03-23曲豫宾
曲豫宾,陈 翔,李 龙
(1. 桂林电子科技大学 广西可信软件重点实验室,广西 桂林 541004; 2. 江苏工程职业技术学院 信息工程学院,江苏 南通 226001; 3. 南通大学 信息科学技术学院,江苏 南通 226019)
软件缺陷预测用于识别软件开发过程中的软件缺陷,软件开发过程中产生的历史数据构成了软件缺陷预测分类器的训练数据,这些数据可以从文件、类等多粒度进行标注[1-4]. 基于软件开发过程,面向历史数据的度量元用于构建分类模型,这些度量元包括基于代码行数的度量元、Halstead科学度量以及McCabe环路复杂度等[4]. 传统的项目内缺陷预测模型主要关注静态度量元,基于度量元进行分类模型构建,基于潜在的有缺陷模块应具有相同的统计分布特征. 但在实际软件开发过程中,静态度量元构建的分类器无法预测具有相同统计特征分布却不同语义特征的代码模块,如JAVA代码中Queue队列的add,remove方法的先后顺序虽然具有相同的统计分布特征,却有明显不同的语义特征. 通过使用自编码网络[5]、卷积神经网络(CNN)[6]等深度学习框架能从源数据集中学习到语义特征,建立面向语义学习的软件缺陷预测模型. 在实际训练数据集标注过程中,拥有不同的数据标记却在特征空间中有相同的特征,这种类重叠问题是由标注过程中多种因素导致的. 类重叠问题是数据挖掘以及机器学习中常见的问题,其影响了分类性能. 类重叠的训练样例模糊了分类边界,增大了分类难度[7]. 很多应用领域都存在类重叠问题,如信用卡欺诈检测和文本分类领域等. Chen等[8]提出了使用基于k近邻的方法处理存在类重叠的样例;文献[7]提出使用改进的K-means聚类算法清理重叠样例. 但这些策略都是基于传统的静态度量元进行的,而面向基于语义学习的软件缺陷预测的类重叠问题研究目前报道较少.
基于此,本文将基于卷积神经网络的深度学习框架应用到跨版本软件缺陷预测中,提出一种面向跨版本软件缺陷预测的深度学习框架,从前一个版本的历史数据中根据抽象语法树构建基于文件级别的特征语义向量;以该语义向量为基础,改进数据抽样策略,融合基于近邻的样例清理策略与基于K-means 算法的清理策略,对训练数据集进行预处理,作为Logistic模型分类器的输入训练分类模型;将下一个版本软件代码作为测试数据集,用常见的AUC(area under curve)作为分类性能的评价指标,测试了该清理策略的有效性. 通过对实验结果使用Friedman测试与Nemenyi后检验进行统计分析,证明该策略能解决类重叠问题,提升了基于深度语义学习特征的分类器性能.
1 面向深度语义学习的跨版本软件缺陷预测
1.1 跨版本软件缺陷预测中面向深度语义学习的整体框架
针对软件缺陷预测过程中未充分使用源代码语义特征以及训练数据集中的类重叠问题,提出一种面向类重叠的跨版本软件缺陷深度特征学习方法CnnSncr,该方法采用混合式最近邻清理策略处理深度语义特征学习过程中的类重叠. 用该方法可自动地从源代码中学习语义和结构特征,为分类器提供基于深度语义学习的特征向量. 该方法的整体流程如图1所示.
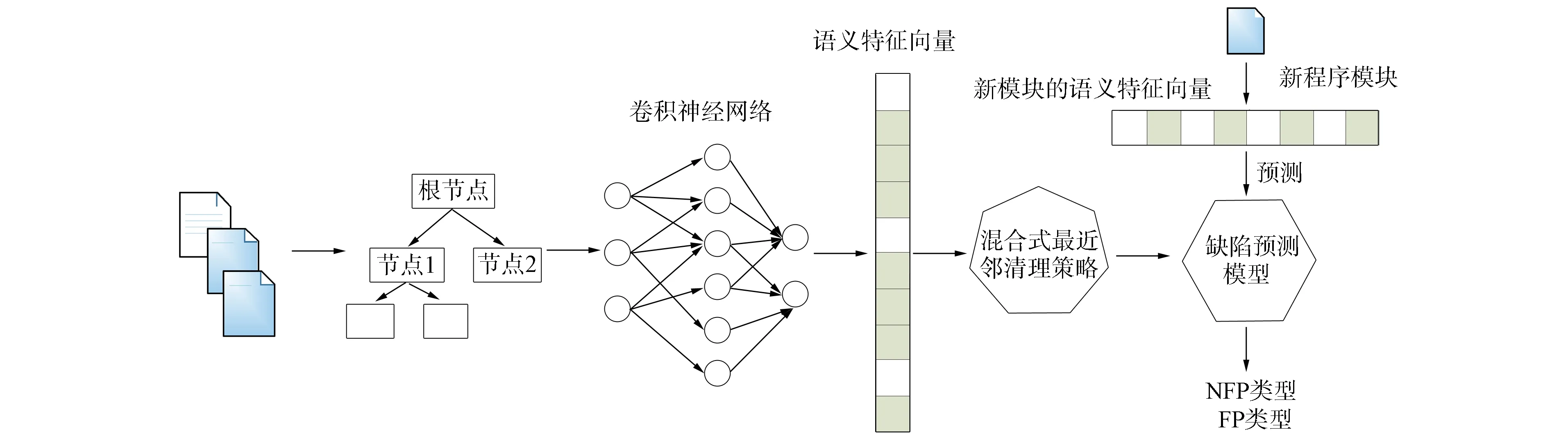
图1 面向类重叠的跨版本软件缺陷深度特征学习方法CnnSncr流程Fig.1 CnnSncr work flow of cross-version software defect deep feature learning method for class overlap
该方法首先从训练数据集和测试数据集出发,构建抽象语法树用软件开发过程中发布的前一个版本的历史数据作为训练数据集,下一个版本的软件开发数据作为测试数据集. 构建抽象语法树过程中,选择如图2所示的具有代表性的语法树节点[6]表示软件模块,每个软件模块构筑符号向量.
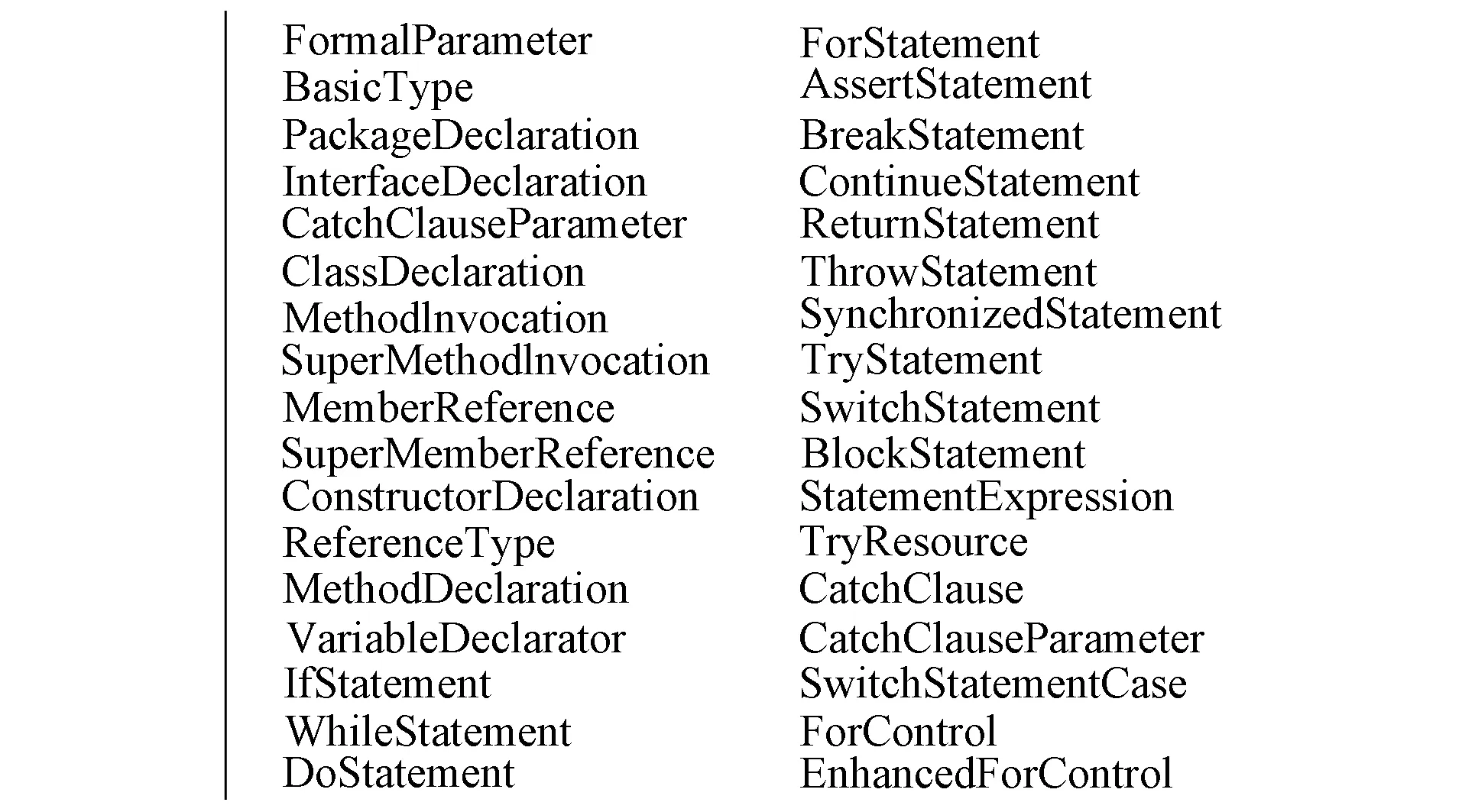
图2 具有代表性的语法树节点Fig.2 Representative syntax tree nodes
符号向量采用one-hot编码方式进行编码,先对输入向量进行词嵌入,作为卷积神经网络的输入,卷积神经网络再从输入向量中自动学习深度语义特征. 由于标注过程中存在噪声,类重叠不可避免[7-8],因此需对深度语义特征进行预处理. 由于在软件缺陷预测数据集中普遍存在类不平衡问题[9-10],因此需对训练数据进行过采样,而过采样完的数据集可能会产生更多的类重叠. 从近邻出发,对多数类和少数类同时进行清理,处理潜在的重叠软件模块向量. 将经过预处理的深度语义特征作为传统分类器,如Logistic回归分类器的输入. 在Logistic回归分类器上训练分类模型,并对测试数据集进行测试.
1.2 基于卷积神经网络的语义特征学习模型
卷积神经网络具有深度特征提取的能力,基于源代码使用one-hot编码后的特征向量具有内在的语义和语法结构,通过引入卷积神经网络能创建表征语义信息的新深度特征向量. 考虑到不同的源代码之间文件大小差异较大,该卷积神经网络框架既不同于文献[8]使用的标准卷积神经网络框架,也未采用在某些理论分析中使用的复杂学习框架[11-12]. 同时该框架与文献[5]提出的基于深度信念网络框架也有较大差异. 基于深度信念网络的深度语义学习框架采用无监督学习模式,语义特征学习过程中训练数据集并未参与梯度下降的优化过程. 本文提出的基于卷积神经网络的语义特征学习模型采用有监督的深度语义学习模式,通过对训练数据集的优化生成更适合当前项目的语义. 文献[13]提出的采用代码注释嵌入的软件缺陷语义学习框架与文献[8]使用的标准卷积神经网络框架均采用卷积神经网络,在软件缺陷预测相关研究中取得了较好的效果.
假设当前软件项目有n个文件数目:X={x1,x2,…,xn},则软件缺陷预测问题可被形式化为学习任务,该学习任务从训练数据集中学习预测函数为
F:X→Y,yi∈Y={1,0},
(1)
其中yi∈Y,表示软件模块是否含有软件缺陷. 深度特征语义向量生成总体过程如图3所示.

图3 深度特征语义向量生成过程Fig.3 Deep feature semantic vector generation process

将训练过的词嵌入向量作为卷积神经网络的输入. 在输入方向设置多个一维卷积核,从词嵌入向量中提取单词的特征,并将输出结果输入到池化层. 为对优化过程中的参数进行约束,引入正则化,采用dropout方法在反向传播误差更新权值时随机删除部分神经元. 对池化层输出展开为全连接层,多次迭代训练得到语义特征向量. 训练过程中采用小批量梯度下降算法[15],选用Adam优化器[16]. 基于该语义特征向量判断当前模块是否存在缺陷.
1.3 面向深度语义学习的混合式最近邻清理策略
基于卷积神经网络的深度语义学习模型,能从软件开发过程中的源代码学习到语义特征. 软件缺陷模块标注存在特征相同但标记不同的情况,称为类重叠[7-8],类重叠问题也存在于文本分类[17]等领域. 文献[7-8]针对软件缺陷预测研究了类重叠问题对跨项目软件缺陷预测等的性能,提出了用NCL(neighborhood cleaning learning)和IKMCCA(improvedK-means clustering cleaning approach)策略缓解该问题. 但这些策略并未针对深度语义特征中存在的类重叠问题进行研究,同时对普遍存在的类不平衡问题也仅使用了消除潜在缺陷模块类的方式获取数据集的平衡. 基于此,本文提出使用混合式的策略SNCR(special neighborhood cleaning rule)解决类重叠问题. 该策略的伪代码如下.
算法1混合式最近邻策略(SNCR).
步骤1) 输入: 训练数据集T={Cmax,Cmin},其中Cmax属于多数类,Cmin属于少数类,d表示有缺陷模块与所有模块数目的比值;
输出: 清理完成的数据集T′={C‴max,C‴min};
步骤2) 遍历Cmin集合中的每个样例;
步骤3) 利用欧氏距离选择k最近邻;
步骤4) 选择样例xi(nn),生成随机数δ∈{0,1};
步骤5) 利用当前样例与xi(nn)生成新样例xi1=xi+δ(xi(nn)-xi);

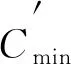
步骤8) 根据预定义的欧氏距离计算与当前样例最近的Nx个样例;
步骤9) 如果Nx中任意一个样例包含于集合Cmax,则删除该样例;


步骤14) 使用标准K-means算法将数据集分为k簇;
步骤15) 循环遍历每个簇;
步骤17) 如果当前比值 ∂′>∂,则删除当前簇中少数类;
步骤18) 如果当前比值 ∂′<∂,则删除当前簇中多数类;
步骤19) 合并所有簇中的剩余样例为新的输出集合T′.
该策略以生成的深度语义特征向量集合为输入,根据集合中标记的不同,将样例分为Cmax和Cmin两类,算法过程主要分为如下三步:
1) 对少数类样例循环遍历,根据欧氏距离选择k个最近邻,并使用随机种子数在某个样例与最近邻之间生成新的样例,迭代完成过采样,实现多数类与少数类之间的平衡,解决类不平衡问题;
本文提出SNCR策略的目的是由于软件缺陷深度语义数据集包含大量数据,并且类重叠的问题不可避免,仅对多数类别进行欠采样解决类别不平衡问题是不合理的. 首先利用过采样使不同类型直接达到数据平衡. 同时,过采样也可能导致更多的类重叠. 此时,对当前多数类和少数类执行最近邻居学习,并消除潜在的类重叠实例. 由于深度语义数据量相对较大,因此除使用上述最近邻方法查找潜在的类重叠实例外,还可以通过引入标准K-means算法分析当前数据集. 对数据集执行聚类分析,并删除每个集群中的异常实例.
2 实 验
本文实验在至强E5-2670的CPU与16 GB内存的工作站上完成,同时在NVIDIA GeForce RTX 2070的GPU上训练深度神经网络并进行分析处理. 实验中使用的相关分类器来源于scikit-learn,深度神经网络库采用TensorFlow 2.0稳定版本. 卷积神经网络的输入向量维数为93维,经过词嵌入后输出为20维. 源数据集作为训练数据时,对数据集进行了随机分层抽样,共训练1 000个批次,每个批次的样例数目为1 024个.
2.1 实验数据集
实验采用的软件缺陷预测数据集来源于PROMISE数据库(http://openscience.us/repo/defect),该数据集为公开的数据集,广泛应用于软件缺陷预测中. 选择该数据集中7个开源的JAVA软件项目进行实验,因为每个软件项目的版本号、类名称、相关标记都是确定的,与类名称相对应的源代码从GitHub上下载并进行分析处理. 实验中所用7个项目的项目描述、版本号、缺陷模块比例等信息列于表1. 为获取项目中需用的训练数据集和测试数据集,参考文献[18]方法,将前一个版本的源代码作为训练数据集,将下一个相邻版本的源代码作为测试数据集. 本文实验中未使用传统基于统计的软件缺陷特征.

表1 实验所用数据集中项目信息
2.2 评价指标及数据统计分析方法
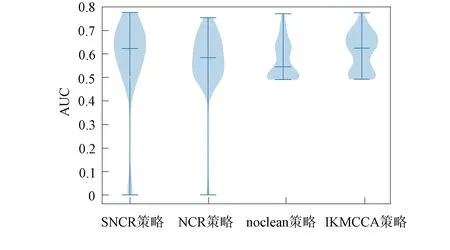
图4 不同策略使用AUC指标对比的小提琴图Fig.4 Comparison of violin plot of AUC index for different strategies
基于软件缺陷预测数据集中常见的类不平衡问题,选择AUC作为分类器性能的评价指标. AUC定义为ROC曲线与坐标轴所包围的区域,最大值不能超过1,AUC值越接近1,则分类器检测的真实性越高; 反之,当AUC接近最小值0.5时,则没有应用价值. 本文首先使用Friedman测试确定不同数据处理策略之间是否存在统计学上的显着差异,如果存在统计学上的显着差异,则应用post-hoc Nemenyi测试比较差异.
2.3 实验中用到的类重叠处理策略
为比较类重叠对基于深度语义的软件缺陷预测分类性能的影响,将SNCR策略与IKMCCA策略以及NCR策略的性能进行对比. 为使实验结果更具说服力,将以上3种数据预处理策略与无数据预处理的情况进行比较,该策略被记为noclean策略.
2.4 实验结果分析
使用IKMCCA和SNCR策略时,算法中的超参数值p%被设定为少数类与多数类之比. 不同数据处理策略的性能对比小提琴图如图4所示. 由图4可见,使用SNCR策略可获得Logistic回归模型分类器上AUC度量的最佳中值,即与noclean策略相比,清洗策略解决类重叠问题性能更优;与IKMCCA和NCR策略相比,SNCR策略在7个开源项目组成的数据集上性能更好.
评价指标的图形显示不能量化表明不同策略的直接差异,同时,为基于统计学比较差异训练数据集上不同策略的性能,使用置信度为95%的非参数Friedman测试对实验结果进行统计分析. 假设:
(H0) 基于深度学习学出的语义特征,不同针对类重叠问题的数据预处理方法不存在性能差异;
(H1) 基于深度学习学出的语义特征,不同针对类重叠问题的数据预处理方法存在性能差异.
设显著性水平α=0.05,计算结果表明,计算值小于临界值,因此条件(H0)不成立,从而这4种策略间存在统计差异. 为揭示不同策略间的差异,进一步采用post-hoc Nemenyi测试分析方法,使用4种数据处理策略的AUC指标结果列于表2.

表2 4种不同策略的AUC指标计算结果
综上所述,类重叠问题的结果是语义特征向量在特征空间中重叠,这种模糊性削弱了分类器的边界,并导致分类器性能下降. 因此,以解决深度语义特征学习和清除噪声为目标,本文提出了一种SNCR策略,并通过实验证实了该策略解决类重叠问题可有效提高分类器的性能. 在PROMISE公开数据集上进行测试的结果表明,采用混合式最近邻清理策略能处理类不平衡问题与类重叠问题. 对数据的统计分析结果表明,该策略能提升基于深度语义学习的软件缺陷预测性能,AUC指标最多在中值上提升14.8%. 软件质量保障问题包括:软件缺陷中的语义学习问题[18]、跨项目软件缺陷预测问题[19]、软件缺陷分析算法[20]、随机测试方法[21]、恶意软件分类[22]、基于机器学习的项目缺陷预测方法[23-24]等,其中基于机器学习的方法需要高质量的数据样例,在训练数据集中应该存在尽可能少的数据噪声,采用本文提出的SNCR策略,能构建更高质量的训练数据集,提升模型的准确度.
