探索基于大数据的分布式隐私保护聚类挖掘算法
2021-03-22赵峰
赵峰
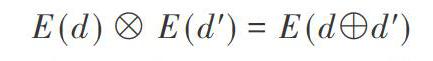

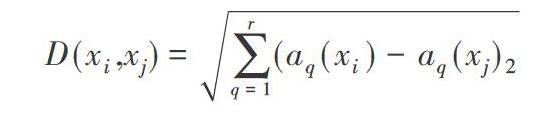
摘要:近些年来,全世界范围内的移动互联网以及云计算技术都得到了飞速发展,网络上随时随地都会出现诸多的各方面数据,在这大数据时代背景下,有必要加强对于分布式隐私保护聚类挖掘算法展开深入分析。本文简略介绍了大数据挖掘安全技术以及隐私数据保护技术,并对基于大数据的分布式隐私保护聚类挖掘算法展开了全面探索,旨在提升数据隐私保护水平的同时,还能达到高精确度的大数据聚类挖掘效果。
关键词:大数据;隐私保护;数据挖掘;分布式环境
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2021)04-0201-03
在当今时代下,大数据已经成为高校分析以及处理网络中海量数据的重要环节。经过调查发现,我国在挖掘算法方面已经取得了较为良好的研究成果,但事实上仍存在诸多不利因素对于数据安全以及隐私保护效率的提升起到了一定的制约作用。因此,有必要加强对该方面技术的重视,并在实践过程中对其进行逐渐地优化与完善。
1相关技术
1.1大数据挖掘安全技术
大数据挖掘主要指的是不断提取以及挖掘在当下不规则并且海量数据中的各类知识,当各个站点开展挖掘大数据任务的过程中,应着重考虑各站点所普遍存在地数据隐私泄露问题。从目前来看,对于隐私保护的数据挖掘算法包含着诸多种研究类别,分别为序列模式、聚类和分类以及关联规则数据挖掘算法。与此同时,应及时采取相关措施,强化对于各站点的规范和约束管理,此举能够切实保障在开展大数据挖掘的同时,尽量降低泄露数据隐私的概率[1]。
近些年,全世界范围内对于上述研究已经取得了一定的成果,例如:部分学者在半诚实模型和恶意模型的基础条件下,针对挖掘数据算法过程中隐私保护的数据挖掘隐私保护安全性以及执行效率展开了详细研究。除此以外,还对于在隐私保护以及数据安全基础上的序列数据挖掘技术进行了深入探究,设计出了一种能够高效实现重要序列属性隐藏的数据挖掘算法,这对于高效落实对于数据挖掘的隐私保护起到了重要意义。还有部分学者以分布式环境为基础,对基于隐私保护的数据额挖掘算法进行了科学系统的设計,这有助于缓解当前在进行数据挖掘过程中普遍存在的数据安全以及隐私泄露等问题。
1.2隐私数据保护技术
在进行大数据挖掘时,其所涉及的是包含诸多同个人隐私相关的隐私数据,例如个人社交动态资料、工作资料、财产和病历信息资料以及个人基本资料等,大数据挖掘隐私保护不仅要确保能够在保护隐私数据不窃取其他站点隐私数据的基础上进行各个站点的数据挖掘工作,同时,还要在充分考虑的其数据挖掘所达到的相关效果,确保其能够同相关预期效果相符合。从上述研究中可以看出,一般来说,研究大多会将数据加密的隐私保护技术应用于数据挖掘典型算法之中,通过使用全同态加密技术,开展针对原始数据的加密处理,便可以直接在挖掘数据的过程中直接处理加密密文,不仅能够确保隐私数据自身的安全性与稳定性,还可以提升数据挖掘的实际效率。同态加密技术的应用,并不会对原始数据进行解密,而是会通过大数据挖掘算法的应用,直接开展针对加密数据地复杂计算操作,并且可以得到同数据加密之前同样地结果。部分学者在该方面进行了深入的研究,其对全同态加密技术展开了探索,同时,对在全同态加密算法运行效率基础上的改进方案进行了研发设计,也得到了较为丰硕的研究成果。除此以外,部分学者在对全同态加密技术进行研究地基础上,提出了一种新型的全同态加密方法,这使得流行的外包计算以及云计算都能够再实现对于全同台加密技术的应用。
此文中的观点为,针对加法和乘法来说,任何一种加密算法都具有能够与之相适应的同态操作:
基于此便可以将其看作是全同态加密算法。
2分布式数据挖掘概述
2.1水平划分的数据
水平划分的数据是分布式数据挖掘的重要组成部分,其主要指的是在各个不同的站点中对拥有相同属性的信息进行搜集。但事实上其实体存在一定的差异性,例如:不同超市所搜集的杂货店信息。以具有不同的信用卡信息的两个数据库为例,其全局数据库所搜集的信息具有不同的实体,但拥有者相同的属性[2]。
2.2垂直划分的数据
除了水平划分的数据以外,垂直划分的数据也是分布式数据挖掘的重要组成部分,其主要指的是不同站点对于各类相同实体集合信息的收集,但其属性的集合存在差异,具体可以从以下角度出发进行理解。例如在某个数据库中,其中一个为相同实体使用手机的信息,另一个则为人的医疗信息。从数据库中可以看出,相关工作人员可以通过采用相关挖掘方法对全局数据库进行分析,以便于充分获取患者的实际情况。该模式的描述如下所示:有k个集合P1.P2.…,Pk,n个事务,基于此需要对n个与事物有关的信息进行相应的信息搜集工作。
2.3任意划分的数据
任意划分的数据是分布式数据挖掘的重要组成部分,其主要指的是搜集各不同站点中属性也不相同的相关信息。以两方参与方为例,分为A.B两方,二者各自所拥有的数据能够形成一个整体的数据库,该数据库中包含n个对象,可以采用m个属性来表示对每个对象金鑫表示,参与方A对于每个对象d来说都有着部分属性集,与此同时,参与方B则会拥有剩下的。通常情况下来说,可以将从水平划分以及垂直划分的角度来看,可以将其数据当作是进行任一分布的特殊形式。
3基于大数据的分布式隐私保护聚类挖掘算法
在当前分布式环境之下,若是基于大数据开展数据挖掘工作,有必要将各站点联合起来进行对于聚类结果的计算,有可能会导致数据安全及隐私泄露的问题。聚类挖掘主要指的是一种机器学习算法,其本身具有无指导的特点,数据要在其原有的实际特征的基础上经过多次迭代,进而形成各不相同的族群。在实际操作过程中可以通过多种方式实现聚类挖掘,包括基于模型的聚类、层次聚类、基于密度的聚类、划分聚类以及基于神经网络的聚类等等。笔者在文中主要将会针对K-means算法进行详细讲述,该算法本身是划分聚类的一种数据挖掘算法,文中主要使用的是同态加密技术以及公钥加密技术创新提出了一PPDK-means,其是在水平划分基础上的一种聚类挖掘方法[3]。
各参与方在分布式的环境中应先展开针对相关数据的同态加密工作,然后再充分利用安全信道,实现对于原有数据高效共享的目的,接下来便需要展开对于加密数据的进一步精密计算,然后便需要在某个参与方中通过同态加密技术的应用高质量地完成对于计算结果的加密。开展相应的解密工作,然后向全体参与方广播最终的实际计算结果,相关工作人员应当注意,实际所要开展的计算工作应当在经过加密的数据基础上进行,在加密后的数据中,准诚信第三方需要开展相应的聚类挖掘工作,这样一来便可以切实降低出现对于用户明文数据进行直接使用实践出现的概率,切实保障好数据本身的安全性以及稳定性,以免出现半程新的参与方直接获取相关其他参与方的隐私数据,进而达到对隐私进行高质量的保护的目的。
经过相关的实验证明以及理论分析发现,该算法可以既可以保障好数据隐私,还能够获取精确地聚类结果,有着较强的应用价值。
3.1问题描述
3.1.1分布式环境中的聚类算法
在以往所使用的数据储存方法中,主要是在一个数据仓库中实现对于全部数据的存储,然后在需要使用的时候,直接在其中进行相应的聚类分析,进而将有益的知识以及规律提取出来,该模式应用的最大优势便在于能够高效实现对于存储空间的利用,减少冗长繁杂的数据,同时还要从全面的眼光看待问题,进而采取相应的措施开展针对数据的保护工作。但从目前来看,全世界范围内的信息技术整体发展较为迅速,在当下的信息社会中已经有着越来越多传统行业的融入,从政治以及商业利益角度出发,未来的主流模式必定是多中心分布式的数据存储格局。分布式环境这一概念与集中式环境是对立的,上文对其划分进行了详细分析,下面不再赘述,在本文中,笔者将会对水平划分数据环境中的聚类挖掘算法进行精细化的探索。
加设分布式系统中存在n个站点Si(i=1,…,n,n≥3),每个站点的数据集为Di(i=1,…,n,n≥3),在每个数据集Di(i=1,…,n,n≥3)中所包含的对象个数为mi(i=1,…,n,n≥3),则联合数据集[D=i=1nDi(i=1,…,n,n≥3)]。
在针对联合数据集D开展相应的聚类挖掘的过程中,务必要确保各个站点Si的数据集D的数据安全,这主要指的是其他站点无法在经过结果推断之后将原本的数据集Di推导出来,同时还要对联合数据D所挖掘出的知识进行掌控。确保其是真实有效的,同直接挖掘Di所得出的结果完全符合[4]。
在分布式的数据存储环境中,分布式聚类挖掘算法能够有效实现聚类过程,在本文中,笔者先对于数据挖掘的环境进行假设,若是其为水平分割数据集,那么将由以下几方面内容入手展开对于分布式聚类算法的理解。首先,应在系统中选用两级架构。其次局部站点Si(i=1,…,n,n≥3)要从主站点发来的聚类中心出发,高质量地完成对于本地聚簇数据的计算工作,并将其直接向相应的中心站点进行发送。接下来中心站点便要接收那些从局部站点所发来的聚簇结构,并进行全局计算,判斷其是否能够同相应的受立案条件相符合,若是可以符合便要立即停止迭代进程,然后输出相应的聚类结果。如果其并未满足收敛条件,便要继续进行迭代,直至其能够相符合。
3.1.2分布式数据挖掘中的隐私安全问题
分布式环境相比其他环境来说具有一定的特殊性,数据在其中的存储有着较为分散的特性,主要是存储于各个逻辑隔离站点以及物理隔离站点之中,每个站点其所具备的功能基本上同相关资质单元相似,基于此,各个站点中的数据便有一定程度的私有特点。在开展数据挖掘工作的过程中,应联合各个参与方对聚类结果以及分类模型展开共同计算,在该过程中极有可能会出现泄露隐私的现象。本文主要从局部站点以及中心站点两级结构入手展开数据挖掘,在进行数值计算以及结果共享的过程中,是数据隐私最容易被侵犯的两个环节,所以有必要加强对以下几方面内容的认识强化保护数据隐私。首先,加强对于各个站点自身隐私数据安全性的保障,以免出现其他参与方直接获取他方数据的情况。其次,应当确保传输过程中数据的安全性,以免数据被其他半诚信以及被恶意的攻击者截获。最后,要加强对于聚类挖掘过程的重视,注重对于该过程中隐私数据安全的保护,降低在进行合作计算时,出现数据隐私泄露现象的可能性。
3.2分布式k-means聚类挖掘算法
标准的分布式k-means聚类算法。
K-means算法本身属于一种聚类挖掘算法,其是在距离基础上实现的,在对于相似度的评级方面,将距离看作是相应的评级指标,深入分析各聚簇对象的实际距离以及均值计算相似度,相似度会随着距离的减小而逐渐增加。采用K-means算法的最基本的目的便是对聚簇内相似度最低以及最高的聚类结果进行获取,通常情况下,可以通过使用欧几里得距离、闵可夫斯基距离以及曼哈顿距离三种方法进行距离度量,这三种算法之间都是衡量个体之间的差异的。其中,在运用欧几里得距离度量方法的过程中,其最终的结果会收到各指标不同单位可读的影响,所以在实际运用中应注重对其进行标准化,若是其距离越大,便会使得其个体之间产生较大的差异性。除此以外,其他二者同欧几里得距离基本上相似。
标准的欧式距离公式如下所示:
3.3正确性与安全性分析
3.3.1正确性
针对从站点的计算结果,笔者主要从同态加密系统以及RSA公钥加密系统两方面出发进行加密,以此确保各个参与挖掘的各方数据在半诚信的环境当中不会出现被泄露的问题。因为同态加密系统的加密操作并不会对最终的聚类结果产生影响,而RSK公钥加密系统则只能应用于对密钥的加密,所以在本文所提出的算法可以实现对于挖掘结果的精确获得。因为存在相应的解密过程,所以该算法有着较高的时间复杂度,RSA公钥加密的过程是最为耗时的,但是其智慧应用在特定的部分进行加密,并非是整个明文,所以可以在一定程度上减少指数运算,在这样的条件下便会适当增多所要执行相关挖掘操作的时间。在实际开展挖掘工作的过程中,如果其中心站点中的计算过程过于繁杂,那么便可以将其整体的计算过程输送至云端进行,这样便可以减少其复杂程度,提高计算效率。
3.3.2安全性
在安全性方面,该算法主要分为三个层次对数据隐私进行保护:
相关工作人员在面对局部聚类结果的过程中应灵活使用通态加密技术开展相应的加密工作。因为R本身是一个随机数,所以在实践过程中可以仅将其看作是拒不保存的聚类结果,中心站的具体职能在于对于相关已经完成好加密工作的局部数据的获取,根据其实际应用的各个方面来看,中心站无法实现对于其他与局部数据有关任何信息的获取。当中心站点做好计算工作之后,便会直接发送中间结果至局部站点处。接下来开展对其的解密工作,然后再将其反送至中心站点,以便于开展后续的运算工作,此举能够避免中心站点解密相关参与方隐私数据的问题,对于隐私数据的安全性有着较强的保障作用。所以本文中所提出的算法具有一定的安全性。
4结论
综上所述,从当下的时代背景来看,信息科技在飞速地发展以及进步中使得各个领域都在实践过程中积累了越来越多地数据,而数据挖掘技术的应用能够开展针对数据的二次利用以及分类管理工作。从目前来看,当下最为重要的数据存储模式便是分布式,过去的相关数据挖掘技术正在逐渐由原本的环境向当下分布式的环境中进行迁移。这使其逐渐出现了诸多安全问题。与此同时,在进行数据挖掘时,部分持有者并不愿意披露数据,而保护隐私数据的挖掘算法则能够有效缓解该类问题。
参考文献:
[1] 邓甜甜,熊荫乔,何贤浩.一种基于时序性告警的新型聚类算法[J].计算机科学,2020,47(S1):440-443,473.
[2] 杨涛,张红梅,王家乐,等.大数据下数据流聚类挖掘算法的优化分析[J].物联网技术,2019,9(8):58-60,64.
[3] 左国才.基于大数据的分布式隐私保护聚类挖掘算法研究[J].智能计算机与应用,2018,8(6):57-60.
[4] 徐东,李贤,张子迎,等.面向聚类挖掘的个性化隐私保护算法[J].哈尔滨工程大学学报,2018,39(11):1779-1785.
[5] 姚禹丞,宋玲,鄂驰.同态加密的分布式K均值聚类算法研究[J].计算机技术与发展,2017,27(2):81-85.
【通联编辑:光文玲】
