基于加权贝叶斯的脱机手写阿文单词识别
2021-03-17许亚美何继爱
许亚美,何继爱
(兰州理工大学 计算机与通信学院,甘肃 兰州 730050)
0 引言
在关于手写文字识别的文献中,阿拉伯文字识别的研究逐渐受到关注[1-4]。阿拉伯文,简称阿文,是西亚阿拉伯地区和伊斯兰教信仰者使用的文字,使用者来自不同的国家与民族。阿文字母不能独立运用,字母相连书写成单词后才有语义,因此单词识别具有实际意义[4]。
阿文共有28个辅音字母、1个复合字母和12个元音符号,元音字母是在辅音字母上叠加元音符号而构成,每个字母根据在词中不同位置,有独立、前连、双连、后连中的2~4种字符格式,共演变成100个字符[5]。

图1 手写阿拉伯单词结构规则示例

鉴于上述讨论,本文针对手写阿拉伯文字,提出在组件(即字符或字符的一部分)层面上分解和识别单词。算法首先建立阿拉伯单词组件库,过分割单词图像形成组件序列,再结合形态特征和位置信息识别各组件并估计其权重。然后构建组件特征至单词的加权贝叶斯推理模型,加权融合组件识别置信度和构词先验信息,得到最终的单词识别结果。
1 阿文单词的组件分析
阿文单词组件是根据29个阿拉伯字母的100个变体字符和12个元音符号的形态和结构[5]来定义的,指在阿文单词中相对独立且可被共享的笔画区域块。根据组件特征,可将阿文组件分为3类: ①主体组件(main grapheme, MG): 从字符的主要笔画中分割出的沿着基线书写的区域块,鉴于多段型组件易被过分割为其他组件,这里去掉多段型组件,并将这类组件分解后以不同于现有组件的新区域添加到主体组件; ②点组件(dot grapheme, DG): 延迟笔画中点笔画的组合; ③附加组件(affix grapheme, AG): 延迟笔画中除DG之外的区域块,其中12个元音符号中有些是两个AG的组合。阿拉伯文字组件库如表1所示,共包含50个MG、5个DG和9个AG,其中DG和AG的虚线表示其位置在基线的上方或下方。

表1 阿拉伯文字组件库

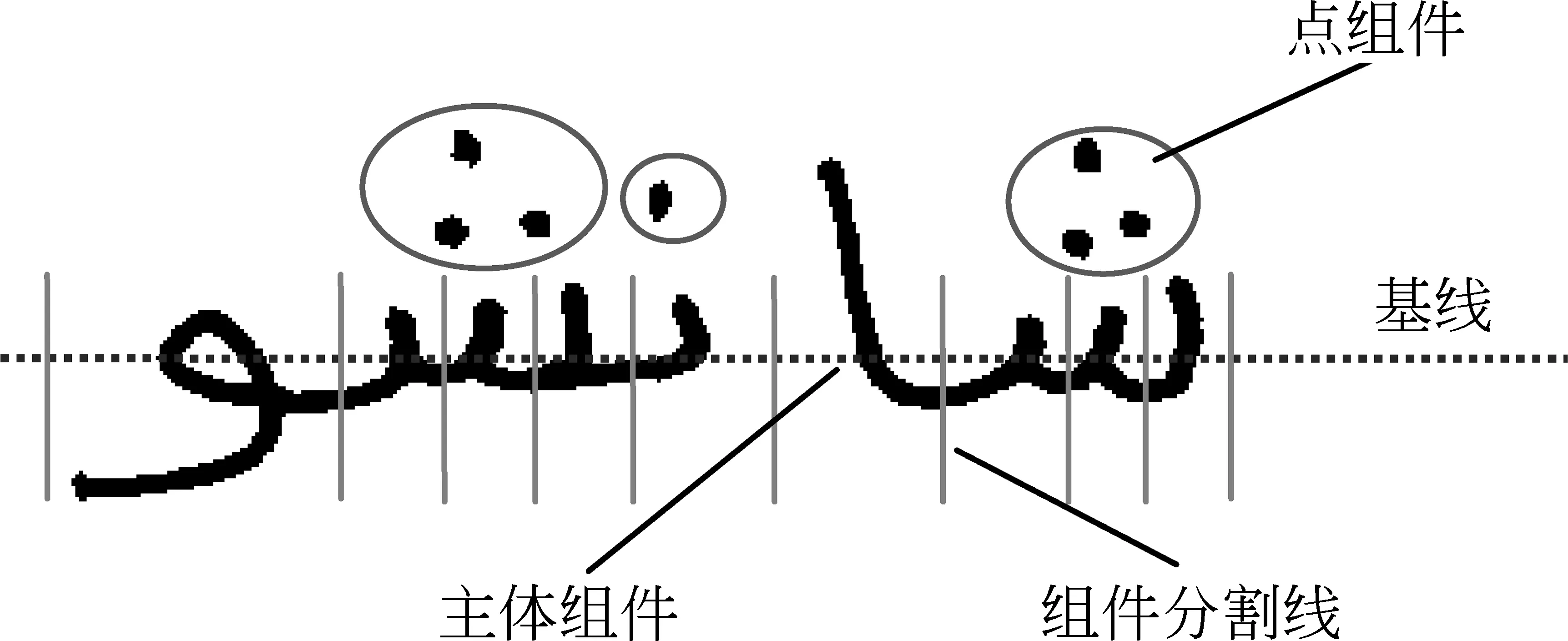
图2 手写阿文单词的组件构成示例
相比字符,在组件层面分解单词,不仅有效解决了多段型字符在分割时易产生过分割错误的问题,而且通过组件分析使相似字之间的微小差异被放大,从而易于检出和辨别。
2 阿文单词的贝叶斯推理模型
贝叶斯推理模型是一种以概率分析和图论为基础的数据模型,能有效地综合数据的先验信息和样本信息,近年来在模式识别领域上的应用逐渐被关注[17-18]。
本文依据对阿文单词的组件分析,构建自组件特征至单词类别的贝叶斯推理模型,该模型以单词的组件特征为起始状态节点,以组件为中间节点、以单词类别为终止节点,形成一个关系网络图,各状态节点之间的有向弧表示节点状态发生的关系和概率,由父节点指向子节点,如图3所示。
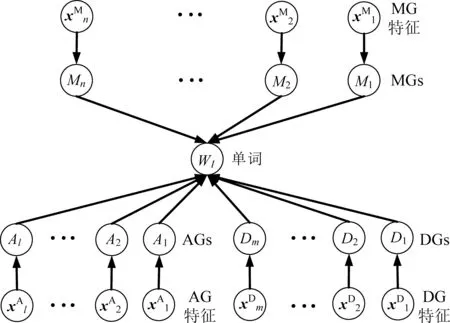
图3 阿文单词的贝叶斯推理模型
该推理模型的具体解释如下:

(2)基于单词类别的模型规整在本文单词识别算法中,需要利用单词贝叶斯推理模型分别计算该单词样本至946个单词类别的后验概率。由于单词所包含的各类组件数目不定,为计算待测样本至单词类别的识别概率,设定一个空组件Φ,代表该处没有组件,利用空组件Φ规整样本特征和单词类别的模型结构。规整方法是: 以单词类别的节点数为标准,调整单词样本的节点,如果样本的组件节点个数较大,则去掉后面多余的组件;反之,则以空组件Φ补全。包含空组件后,组件数目变更为51个MG、6个DG和10个AG。
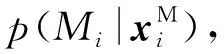
3 单词识别算法整体流程
本文基于加权贝叶斯的阿文单词识别算法,首先将阿文单词分割为组件序列,再进行组件识别和组件加权系数估计,最后通过加权贝叶斯推理,计算单词后验概率并获得单词识别结果。具体算法描述如下。
3.1 组件分割
本文采用我们在以前工作[19]中所提出的主体分割和附加聚类算法(main segmentation and additional clustering,MSAC),对脱机阿文单词进行组件分割,组件分割的流程如图4所示,主要包括以下几个步骤。
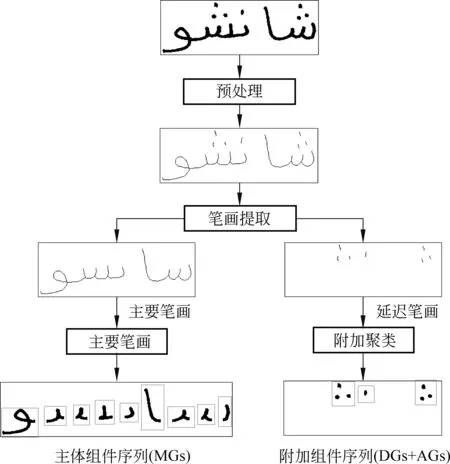
图4 MSAC组件分割流程
(1)预处理对脱机阿文单词进行预处理,包括二值化、归一化、断笔修复、倾斜校正和细化,其中二值化是灰度255置1,其余置0;归一化为宽度512,高度等比例缩放;断笔连接是两笔画间距小于笔画宽度的3/2时进行修复;倾斜校正范围是±30°;细化采用Z-S+Holt算法[19]。
(2)笔画提取首先通过连通域检测提取单词笔画,根据点阈值判定点笔画,再对除去点笔画后的剩余笔画进行Hough变换,并根据其峰值点找到基线位置,获取基线域,然后将与基线域连通的笔画确定为主要笔画,其他笔画为延迟笔画。
(3)主体分割和MG序列获取在基线域内计算主要笔画的垂直差分投影[20],取其极小值点为MG切分点,自MG切分点,垂直分割主要笔画得到主体组件,按位置自右至左记作M=(M1,M2, …,Mn)。

(5)DG序列和AG序列的获取聚类后的点群作为点组件,按位置自右至左,记作D=(D1,D2, …,Dm),除去MG和DG以外的单个笔画构成附加组件,按位置自右至左记作A=(A1,A2, …,Al)。
3.2 组件子分类和识别
本文结合组件分割时获得的位置信息,提出一种新的多级混合式组件识别算法,首先根据位置信息和组件类型将所有组件预分类为8个子类,然后针对MG、AG、DG三类组件,根据各自的结构特点,设计不同的特征提取和分类器,在各自所属的子类范围内再进一步分类。组件子类的描述如表2所示。

表2 阿拉伯文组件的8个子类
表2中,MG根据其在连体段中所处的位置可分为独立(S, stand alone)、前连(FC, front-connection)、双连(m, middle)、后连(BC, behind-connection)[5]等4个子类,DG和AG各自根据其位于基线的上方或下方可分为上方(up-diacritics)和下方(down-diacritics)两个子类,于是共有MG-S、MG-FC、MG-M、MG-BC、DG-U、DG-D、AG-U、AG-D等8个组件子类。
对于DG,由于点的数目特征确切直观,于是直接根据点数目nd(nd=1, 2, 3)计算点组件的识别距离,并对点数目的差值加1以避免距离为0情况。设组件特征向量为x,那么点组件识别距离的计算如式(1)所示。
其中,di(x)代表组件x对第i类候选的识别距离,NS是组件子类别数,对于DG-U,NS=3;对于DG-D,NS=2。
对于MG和AG,采用轮廓Freeman上、下、左、右4方向链码结合弹性网格特征提取(elastic mesh directional features, EMDF)[22]。考虑到MG和AG的面积比例,网格大小对MG取8×8,对AG取4×4。采用MQDF分类器[23]计算MG和AG的识别距离,如式(2)所示。
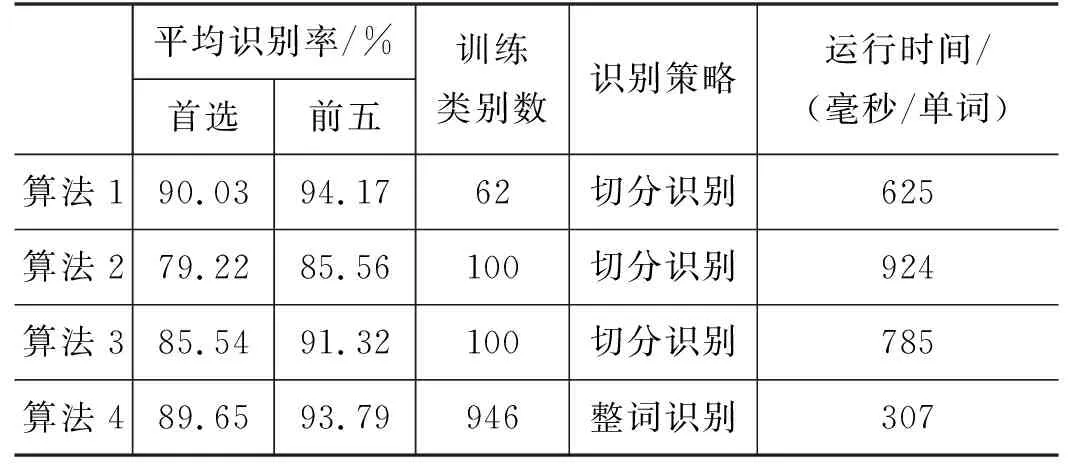
其中,μi是均值向量,λi,k代表协方差矩阵的第k个特征值,φi,k是其对应的特征向量,r是主轴个数,r 另外,对3.2节中所描述的空组件Φ,规定空组件的特征为全0向量。 3.3.1 识别置信度转换 根据组件分类器输出的识别距离dj(x),j=1, …,NS,采用softmax函数对识别距离进行置信度转换,得到组件识别置信度,计算如式(3)所示。 (3) 其中,p(qj|x)代表组件x至第j类候选的识别置信度,NS是组件子类别数。 若上述估计出的识别置信度在不同子类范围,则需要将其扩张到统一的MG、DG或AG组件空间,扩张方法如式(4)所示。 其中,p(ωi|x)为扩张后的组件识别置信度,i= 1, …,N,对于MG,N=NM=51;对于DG,N=ND=6;对于AG,N=NA=10。 3.3.2 组件权重估计 实验发现,单词中各组件的识别可靠度不同。当某组件的候选类别里具有相似字符时,相似字符对应的识别置信度往往较为相近,这时该组件的识别结果不太可靠;反之,当某一候选识别置信度相较其他候选显著地高,则说明该组件前几候选中没有相似字符的情况,识别结果较为可靠。本文算法试图在单词识别中对结果较可靠的组件给予较大的权重,以提高最终的单词识别率,考虑以组件识别置信度的熵值的分布来表述可靠性,组件权重估计的计算如式(5)所示。 (5) 其中,λk是第k个组件的权重系数,p(ωi|xk)是第k个组件的第i类候选识别置信度,N是组件类别数,NG是该组件所在单词中的组件总数。 单词识别的原理是计算待测样本至单词类别的识别置信度(即后验概率),然后按照置信度自大至小的顺序输出候选单词类别,整个识别过程包括训练阶段和识别阶段。 3.4.1 训练阶段 在训练阶段完成对单词贝叶斯模型推理中状态转移概率的获取。其中: (1) 对于表示单词和组件构成关系的转移概率p(WI|Mi),I= 1, …,NW,i=1, …,NM;p(WI|Dj),j=1, …,ND,p(WI|Ak),k=1, …,NA。采用最大似然估计进行参数学习,统计数据来自阿拉伯文语料库,先由阿文字母使用频率[24]转化得到各组件的先验概率,再对各单词类别的组件构成统计得到单词内各组件和单词的联合概率,然后用条件概率公式计算得到组件至单词的条件概率,即转移概率。 3.4.2 识别阶段 其中,Vi(i=1, …,NG)表示贝叶斯推理模型中与单词WI相关联的状态节点,有NG=n+m+l,pa(·)表示节点Vi的父节点集,Sh表示该父节点集的路径分布。 结合图3中所述的模型结构,如式(7)所示。 用组件权重系数λk(k=1, …,n+m+l)对式(7)进行修正,得到式(8): (8) 于是,组件特征为x的待测样本,其单词首选识别结果为最大后验概率对应的单词类别,如式(9)所示。 算法性能在IFN/ENIT v2.0手写阿拉伯文字数据库[6-7]上验证,该数据库包含946个突尼斯城市/村庄名,共32 492个脱机阿文单词样本,分为编号为a、b、c、d和e的五个组[6-7]。以下各实验均使用a~d组数据训练,使用e组数据测试,算法用VC++6.0编程,运行环境是2.6G Intel i5-4300M CPU、4.0 GB内存的PC机。 为评估分割结果,使用三个度量标准: 准确率、召回率和误检率。准确率是算法所获得分割点中正确的比率;召回率指真值分割位置中能被算法正确检出的比率;误检率=1-准确率,包括过分割和错分割两种错误,其中过分割是将一个组件分割成多个组件,而错分割则指分割边界不正确。 本实验在IFN/ENIT v2.0数据库[6-7]上测试三种过分割算法的性能,使用a~d组数据进行训练,测试数据是e组6 033个单词样本所包含的65 884个组件分割点。算法1即本文过分割MSAC 算法。算法2是采用文献[15]提出的最少像素定位结合最优拓扑结构筛选的手写阿文过分割算法。算法3是采用文献[16]提出的基于改进垂直投影和模板匹配的启发式手写阿文过分割算法。 表3给出了三种过分割算法的组件分割性能比较,可以看出,本文组件分割算法(算法1)性能良好,获得97.78%准确率和98.05%召回率。算法1针对过分割的误检率仅有0.96%,对于错分割的误检率为1.26%,均远低于另外两种算法。良好的组件分割性能是本文基于分割策略的单词识别算法实施的基础。 表3 组件分割性能比较 本实验所使用的组件样本通过对IFN/ENIT v2.0数据库[6-7]样本进行手动分割得到,训练数据是来自该数据库a~d组的共305 042个组件,测试数据是来自e组的71 917个组件。实验对比两种识别算法的性能。算法1即本文多级混合式的手写阿文组件识别算法。算法2是文献[25]提出的脱机阿文字符识别算法,该算法基于神经网络分类器,并结合了统计和结构特征。 表4列出了两种识别算法分别对MG、DG和AG的识别结果比较,可以看出,本文组件识别算法(算法1)相较算法2性能较好,这是因为本文多级混合式的手写阿文组件识别算法根据组件分割时的位置信息预分类组件,又为MG、DG和AG设计不同的特征提取和分类器,能获得较好的识别效果。而且,算法1使用距离分类器,因而相较算法2神经网络分类器的耗时少。对DG组件,算法1获得的识别率较算法2高2.11%,因为本文算法考虑了三种点连笔的情况,因而对书写连笔较多的样本组识别率高。 表4 组件识别性能比较 本实验使用IFN/ENIT v2.0数据库[6-7]的a~d组进行训练,训练数据包括单词样本26 459个,字符样本212 211个,组件样本305 042个,测试数据是e组的6 033个单词样本。实验对比了四种算法的性能,算法1、2和3基于切分识别,算法1是本文手写阿文单词识别算法;算法2是文献[13]提出的基于多边形近似描述结构特征和多边形模糊匹配的阿文单词识别算法;算法3采用文献[14]提出的结合纵、横向扫描模板和支持向量机(support vector machine,SVM)分类器的手写阿文单词识别算法;算法4基于整词识别,由文献[10]提出,采用滑动窗统计特征结合多流隐马尔可夫模型(hidden Markov models,HMM)分类器。表5总结了四种算法的单词识别性能。 表5 单词识别性能比较 可以看出,本文算法(算法1)性能良好,单词首选识别率为90.03%,证实了该算法的有效性。分析来说,首先,在分割单元方面,对比算法1和算法2、3可知,本文基于组件的分解和建模可以减少过分割错误,在组件层面识别单词,能将相似词间的微小差异定位至不同组件,并且在分割时考虑到点笔画的三种连写形式,有效解决了手写文字笔画粘连的识别难点,进而有效提高了单词识别率。其次,对比识别策略可知,本文基于切分识别的算法1获得的识别率稍高于基于整词识别的算法4,而识别所需的训练基元是50个MG、9个AG和3个点连笔,共62个组件,训练所需类别数目小且固定,算法向大规模词汇识别的可扩展性较强。最后,在耗时方面,由于分割模块会部分增加算法复杂度,切分识别策略相比整词识别策略,算法的运行时间较长。 脱机手写阿文单词书写粘连,笔画形态复杂,文字特征很难准确提取。本文将阿文单词分解为组件,并设计多级混合式分类器来识别组件,再通过单词加权贝叶斯模型的构建和推理来获取单词识别结果。算法不但能检测和辨识到相似单词间的微小差异,而且对书写连笔、笔画漂移等手写复杂情况具鲁棒性。另外,算法训练所需组件类别有限,易于向大词汇量识别任务扩展。 算法目前的识别错误主要出现在书写潦草、点笔画连写不规整和点笔画丢失的情况。下一步研究期望通过提高组件识别率和改进单词结构模型来获得更好的单词识别性能。3.3 置信度转换和权重估计
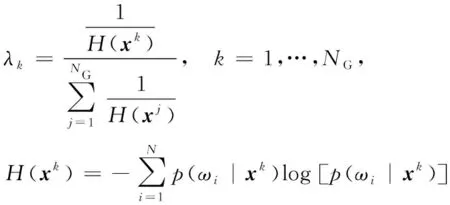
3.4 单词识别
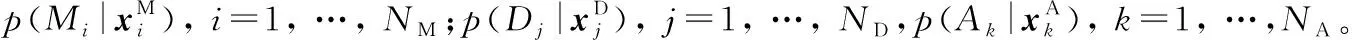
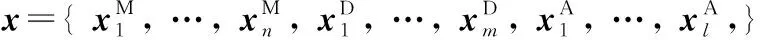
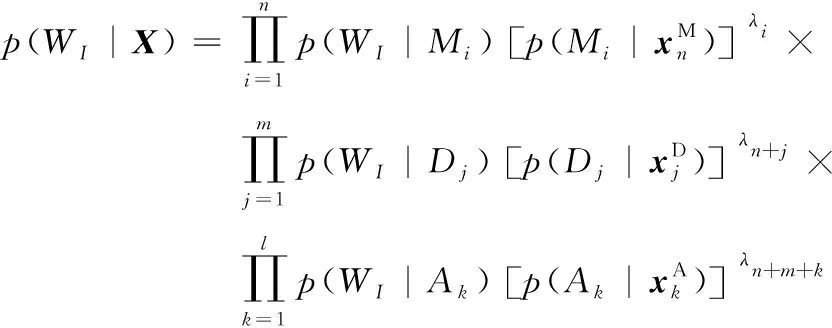
4 实验
4.1 组件分割性能分析

4.2 组件识别性能分析
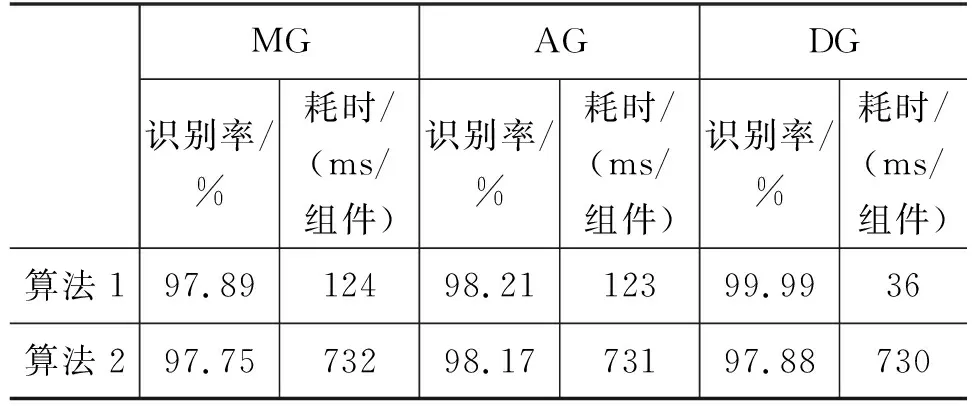
4.3 单词识别性能分析
5 结束语
