SVM算法在风力发电机功率预测中的应用研究
2021-03-16江汉大学人工智能学院
江汉大学人工智能学院 陈 岩 周 晨 侯 群
风电功率的预测对风力发电系统具有重要意义,然而,风力发电的输出功率具有较大的波动性和间歇性,这对制定发电计划、调度运行带来了巨大的挑战。本文介绍了一种基于SVM算法对风电功率进行预测的方法,将风电功率的历史数据作为因变量,将其对应的影响风电功率的主要因素数据作为自变量,使用SVM回归方法建立预测模型,找出最佳的模型参数,将需要预测的数据自变量输入到模型中,有效并准确地预测出风电功率数据,预测准确度可达到94%以上。
随着地球环境的污染和不可再生资源的过度消耗,人们把更多的目光投在了可再生资源身上。风资源作为一种清洁能源,取之不尽,用之不竭,和目前常见的火力发电相比,没有污染排放,也没有煤炭资源消耗。中国作为风资源储量巨大的国家,装机量逐年提高,从保护环境和节约资源的角度来看,风力发电具有良好的未来发展前景。
风电功率是风力发电系统中最为重要的指标之一,然而,风电功率会受到风速、风向角等因素的影响,因此对风电功率预测的准确性成为了关键。
国外风电功率预测研究工作起步较早,比较有代表性的方法主要有:丹麦的Riso国家实验室的Prediktor预测系统、西班牙的LocalPred预测系统和德国AWPT预测系统等。其主要思想均是利用数值天气预测提供风机轮毂高度的风速、风向等预测信息,然后利用风电功率预测模块提供风电功率。
我国风力发电起步虽然较晚,但是在数十年来的发展趋势不容忽视,过快的发展速度导致了风电行业质量跟不上速度的结果。在近些年,我国的风力发电领域开始由快速导向型发展转向质量导向型发展。正是因为这种原因,我国风电功率预测在二十一世纪才开始受到行业重视,目前仍处于起步阶段。
我国目前正在开展基于人工神经网络、支持向量机等方法的风电功率预测模型研究,以及基于线性化和计算流体力学的物理模型方法,同时正在进行多种统计方法联合应用研究及统计方法与物理方法混合预测模型的研究。
本文采用机器学习中的支持向量机(SVM)算法,探讨其在风力发电机功率预测中的应用研究,将有功功率的历史数据及其对应的变量数据进行训练建模,并使用测试数据集对预测模型进行检验。
1 SVM算法介绍
支持向量机(Support Vector Machine,SVM)是一种按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane)。
SVM使用铰链损失函数(hinge loss)计算经验风险(empirical risk)并在求解系统中加入了正则化项以优化结构风险(structural risk),是一个具有稀疏性和稳健性的分类器,SVM可以通过核方法进行非线性分类,是常见的核学习方法之一。
SVM在1964年被提出,在二十世纪90年代后得到快速发展并衍生出一系列改进和扩展算法,在人像识别、文本分类等模式识别问题中得到应用。
2 基于SVM的风电功率预测模型
2.1 数据采样
影响风力发电机功率的变量有很多,如风速,空气密度,发电机扇叶半径,风向角等等,如果将这些因素都考虑进去来预测风电功率则需要大量数据,所以仅选取影响较大的几个变量对风电功率进行预测。
根据风电功率计算公式:

其中,p为风电功率,A为扫风面积,V为风速,Cp为风能转化率值,D为空气密度,φ为功率因子。
在风电功率计算公式中,扫风面积与风机叶片半径和风向角有关,风能转化率值与风机生产厂家技术的不同而有所高低,所以在单台风机的风速预测中,最直接的影响因素为风速、风向角和功率因子。
本文选取风力发电机连续12h的有功功率数据,采样间隔为30s,共计1440条数据,其中前1080条设置为训练集,后360条设置为测试集。
训练集和测试集数据均分为自变量和因变量两部分,因变量为发电机有功功率,自变量为功率因子、瞬时风速、30s平均风速、10min平均风速、风向角和60s平均风向角六个变量,首先对历史数据进行标准化处理。
2.2 数据归一化
在建模训练的过程中,不同的评价指标往往具有不同的量纲和量纲单位,这样的情况会对数据分析的结果造成影响,为了消除这种影响,需要进行数据标准化处理,以解决数据指标之间的可比性问题。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。在这里,本文选用数据归一化来对数据进行处理。利用公式:
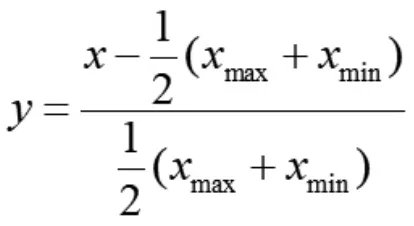
其中,y为归一化后的目标值,x为原始数据,xmax为原始数据最大值,xmin为原始数据最小值。
2.3 使用SVR建立预测模型
支持向量回归(Support Vector Regression)是支持向量机的重要分支,目的是找到一个平面,使一个集合的所有数据到该平面的距离最近,以达到预测的目的。
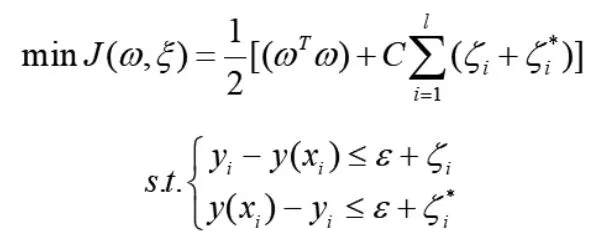
式中,ε为常数,C为惩罚因子,ζi和为松弛因子。
对上述公式引入拉格朗日乘子ai和,转化为对偶问题,则优化函数为:


构造支持向量回归模型需要借助算法计算对偶参数,本文选取径向基核函数(RBF),这里需要确定SVM算法的惩罚因子C和RBF核函数参数γ。
惩罚因子C代表模型重视离群点的程度,C越大表示越不能容忍出现误差,容易出现过拟合的情况,而C越小则容易出现欠拟合的情况。C值的过大或过小都表示其泛化能力变差。
伽马值γ是选择RBF函数作为核函数后,自带的一个参数,隐含地决定了数据映射到新的特征空间后的分布,伽马值越大,支持向量越少,伽马值越小,支持向量越多,其影响着训练与预测的速度。
在训练样本数据的过程中,时常会遇到数据缺失的情况,也就是缺失了特征数据,导致向量数据不完整。SVM算法没有处理缺失值的策略,并且希望样本在特征空间中线性可分,所以特征空间的好坏会对SVM的性能有较大影响,会直接导致训练结果乃至预测精度。针对这种情况,有两种解决方法,一是选取正常工况下连续的、质量较高的数据,二是对不完整的数据集进行数据预处理,通过数据清理来填写缺失值、识别并删除离群点的方式使数据集达到较高的质量。结合实际情况,本文选择第一种方法选取了正常工况下的连续风电数据。
通过对样本数据的训练,调整最适合模型的C值和伽马值,即可得到风电功率预测模型。在这里使用一款SVM模式识别与回归的工具包LIBSVM,使用回归模型函数svmtrain,函数参数为训练集数据,得到最优的惩罚因子C为4,伽马值γ为0.3536。整个预测模型的流程图如图1所示。

图1 预测模型流程图
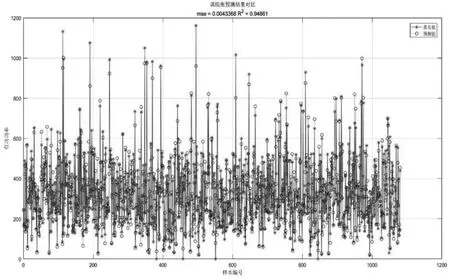
图2 训练集数据及其预测值曲线

图3 测试集数据及其预测曲线

图4 BP神经网络预测曲线
3 结果分析
3.1 模型训练结果
原始数据为国内某风力发电机2018年7月14日21:00——2018年7月15日9:00的30s采样间隔数据,在对预测结果进行评价时,使用RBF核函数自带的svmpredict方法,加入误差参数。如图2所示,在训练结束后得到训练集预测的拟合程度为0.94861,其中,参数C为4,γ为0.3536。
3.2 模型检验
将测试集数据输入到已经确定参数的模型中去,从图3所示可以看出,采用SVM算法对连续时间的风电功率进行预测,其预测曲线与实际的曲线基本一致,拟合程度达到0.94725,拟合程度较高,证明使用SVM在风电功率预测场景中的可行性。
使用BP神经网络的方法对训练集数据进行训练,得到该数据集的BP神经网络,并使用该神经网络对测试集数据进行预测,可以得到如图4所示的预测曲线,拟合程度为0.94506,略低于基于SVM训练的预测模型。
结论:风电功率预测是风力发电系统中重要的一环,受外界因素影响,风电功率具有不稳定性,需要将主要因素考虑进来并对结果进行预测。本文首先对样本数据进行数据预处理,将归一化后的数据分为训练集和测试集,选取RBF核函数对训练集进行训练,得到模型参数,再将测试集数据输入到预测模型中,得到最终预测结果。该模型的预测结果与实际数据相比,拟合度可以达到94.7%。同时,使用BP神经网络的方法对风电功率进行预测,可以得到略低于SVM方法的拟合精度,再次印证了SVM算法在风电功率预测领域的可行性。此外,对于SVM的一些其他改进算法对风电功率预测精度的效果,可以期待后续的探讨。
