基于Python的网络爬虫与反爬虫技术的研究
2021-03-16江西科技师范大学张宝刚
江西科技师范大学 张宝刚
随着互联网的快速发展,网络中的信息量也变得越来越巨大。如何从庞大的互联网中快速准确的收集到我们需要的信息,成为了一个巨大的挑战。因此,网络爬虫技术应运而生,相比较于传统的人工搜集,网络爬虫可以快速的持续的准确的搜集到我们需要的信息。但对于网站内容提供者而言,并不希望自己的数据信息被别人搜集到,且爬虫程序的大量请求,也会对服务器造成一定的压力,因此就出现了反爬虫技术。本文将通过一个案例系统的介绍网络爬虫的原理,并指出一些有效的反爬虫技术。
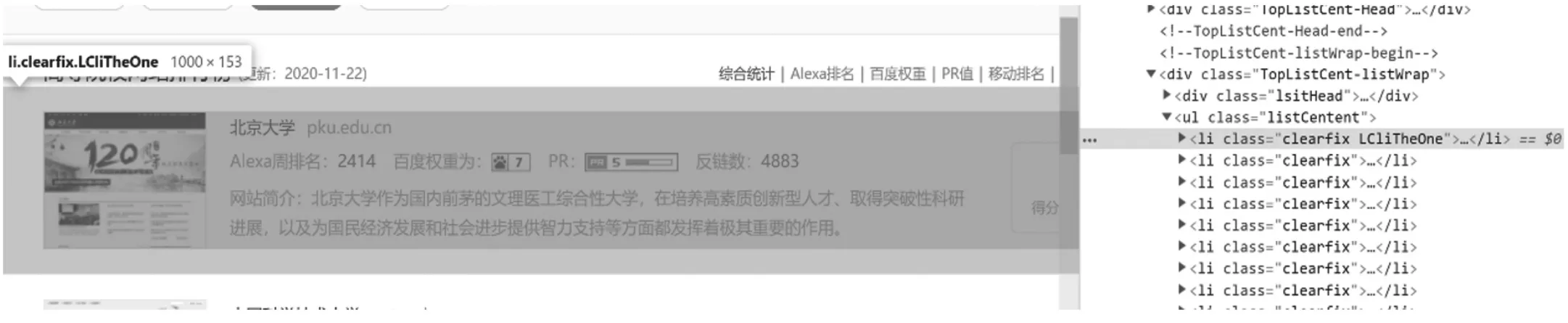
图1 目标网页源码分析
互联网中蕴含着大量的信息,如何有效的获取这些信息并利用这些庞大的信息就变成了一个不小的挑战。传统的人工收集信息的方式效率低、易出错,因此就出现了网络爬虫程序,它是一种根据事先制定好的规则主动的搜集万维网中的数据的一种程序。我们上网用的搜索引擎采用的就是爬虫技术,用无数个爬虫每天爬取各种各样的网站,并把这些网站放到数据库中,等着我们去搜索。网络爬虫根据其实现架构大致可分为深层网络爬虫(Deep Web Crawler)、通用网络爬虫(General Purpose Web Crawler)、聚焦网络爬虫(Focused Web Crawler)、增量式网络爬虫(Incremental Web Crawler)等。本研究主要通过爬取全国高校官网排名情况来介绍爬虫技术的使用,并介绍一些有效的反爬虫技术。
1 爬虫程序的开发
1.1 请求网络数据
开发爬虫程序的第一步是请求网络数据,首先我们要找到要爬取数据的目标网页的url地址,然后利用Requests请求,获取目标html页面的源码。本研究以爬取站长之家的高等院校网站排行榜里的数据为例,该页面地址:https://top.chinaz.com/hangye/index_jiaoyu_daxue.html,我们通过Requests请求该页面就可以拿到该目标网页的源代码了。
1.2 html页面解析
通过上一个步骤后,我们已经获取到了目标网页的源代码,下面我们就可以通过解析源代码获取我们想要得到的数据了。在解析前,我们还要先分析网页源代码,然后才能解析。通过Google Chrome浏览器的开发者模式,我们可以看到整个网页的源码,在这里我们可以清晰的看到,我们需要的数据在源码里的什么地方,如图1所示。

图2 代码实现图
由图1可以看出,我们需要的的信息,都在class=listCentent的
- 标签里,
- 标签里,因此我们在解析时只需要获取到这个ul标签的所有SS信息,并遍历里面的
- 标签就可以获取到所有的高校的网站排名信息了。其代码实现如图2所示。
在解析的过程中主要使用的是BeautifulSoup库。 BeautifulSoup默认使用Python标准库里的HTML解释器,它还可以支持一些其他的第三方解释器,比如lxml、html5lib等,这里我们使用的是lxml解释器,它具有速度快,文档容错能力强的特点。在解析时,我们先用BeautifulSoup的find函数将标签名和样式名传入进去,这样就可以得到我们要爬取的信息所在的
- 标签所有的
- 标签列表了,通过对网页的分析我们可以发现,每个
- 标签对应着一条高校网站排名信息数据,因此,我们只需要遍历
- 标签就可以获取所有的高校网站的具体排名信息了。每一条数据,我们只获取名称、链接、alexa、bd_weight、反链数、网站简介这几个数据。
2 数据的存储
通过以上的操作,我们已经成功的获取到了我们想要的信息。接下来,我们要做的就是将我们获取到的信息保存下来,避免反复爬取浪费资源。本研究将数据保存在MySQL数据库,MySQL是一种开源的、关系型数据库,它使用结构化查询语言SQL进行数据库管理。在使用MySQL存储数据前,我们要先建立一张表,用来存放我们解析到的数据。建表语句如图3所示。

图3 建表语句图
我们设置id为主键,并且其是自动递增的,用id作为每一条数据的唯一识别码。name代表高校的名称,link为高校官网的网页链接,chain_num为反链接数,info为高校简介。创建完数据表后,我们就可以往表里插入我们解析到的数据了。
3 反爬虫技术
网络爬虫不仅可以轻松的“窃取”别人发布到网上的资源,更会给服务器带来额外的压力。因为网络爬虫会无休止的访问目标服务器,其带来的伤害相当于DDOS攻击,消耗目标服务器的带宽、内存、磁盘和cpu等资源,导致正常用户的网络请求异常。因此,我们需要反爬虫程序来帮助我们抵御爬虫程序。
3.1 User-Agent控制请求
User-Agent中可以携带一串用户设备信息的字符串,包括浏览器、操作系统、cpu等信息。我们可以通过在服务器设置user-agent白名单,只有符合条件的user-agent才能访问服务器。它的缺点就是很容易被爬虫程序伪造头部信息,进而被破解掉。
3.2 IP限制
我们知道爬虫程序请求服务器速度是特别快的,并且访问量也特别大,正常用户不可能在短时间里有这么大的访问量,通过这个特点,我们可以在服务器设置一个阈值,将短时间内访问量大的IP地址加入黑名单,禁止其访问,以达到反爬虫的目的。其缺点也很明显,容易误伤正常访问的用户,而且爬虫程序也可以利用IP代理实现换IP的目的,避免其IP被加入黑名单。
3.3 session访问限制
session是用户请求服务器的凭证,网络爬虫往往通过携带正常用户session信息的方式,模拟正常用户请求服务器。因此,我们同样可以根据短时间内的访问量的大小判断是否为爬虫程序,将疑似爬虫程序的用户的session加入黑名单。此方法缺点就是爬虫程序可以注册多个账号,用多个session轮流进行请求,避免被加入黑名单。
3.4 蜘蛛陷阱
蜘蛛陷阱通过引导爬虫程序陷入无限循环的陷阱,消耗爬虫程序的资源,导致其崩溃而无法继续爬取数据。此方法的缺点就是会新增许多浪费资源的文件和目录,而且对正常网站排名有影响,会造成搜索引擎的爬虫程序也无法爬取信息,进而导致在搜索引擎的网站排名靠后。
3.5 验证码
在用户登录或访问某些重要信息时可以使用验证码来阻挡爬虫程序。验证码分为图片验证码、短信验证码、数值计算验证码、滑动验证码、图案标记验证码等。这些验证码都可以有效的阻挡爬虫程序,区分机器和正常用户,使用户可以正常访问服务器,而爬虫程序因识别不了验证码,所以爬虫程序不能进一步访问服务器,以达到反爬虫的目的。验证码的缺点是影响用户体验。
3.6 动态加载数据
前面介绍的通过Python的Requests函数库请求网页,只能获取到静态网页的数据。如果我们的网页通过js动态的加载数据,爬虫程序要爬取我们的数据就没有那么简单了。但是,爬虫程序可以通过抓包的形式得到url请求链接,然后模拟url请求进行数据抓取。
3.7 数据加密
前端请求服务器前,将请求参数、user-agent、cookie等参数进行加密,用加密后的数据请求服务器,这样的话网络爬虫程序不知道我们的加密规则,就无法进行模拟请求我们的服务器。但是,这种方式的加密算法是写在js代码里的,很容易被用户找到并且破解。
以上的反爬虫技术,都可以在一定程度上实现反爬虫的目的,给爬虫程序增加一定的困难。在实际应用中,如果能将以上技术组合起来使用,反爬虫的效果会更佳。当然现在还没有任何一种通用的反爬虫技术可以抵御所有的爬虫,开发人员应该根据实际情况选择合适的反爬虫技术。
结语:使用Python语言编写爬虫程序是一种人工智能大数据时代下进行数据采集与分析的重要方式。本文以爬取站长之家中的全国高校网站排名信息为例,介绍了简单Python爬虫程序的爬虫原理,以及一些反爬虫的技术和它的优缺点。爬虫技术和反爬虫技术,天生的相生相克、相辅相成,它们之间并没有谁对谁错、谁好谁坏,主要看使用他们的人是出于什么目的。
- 标签里以列表的形式放着各个学校的排名信息放在
