一种基于改进Attention U-net的联合视杯视盘分割方法
2021-03-16秦运输王行甫
秦运输 王行甫
(中国科学技术大学计算机科学与技术学院 安徽 合肥 230031)
0 引 言
青光眼是一种慢性的眼底疾病,也是当前世界范围导致视力损伤的主要原因之一[1]。由于其发病早期并不伴随较为明显的症状,且造成的视力损伤具有不可逆性,因此青光眼的早期诊断工作对于青光眼的预防和保护患者视力具有重要的意义。
已知的青光眼诊断方法主要有以下几种:(1) 通过接触或非接触的方式来对眼内压进行测量并评估。(2) 对视觉区域进行评估。(3) 对视神经头区域进行评估[2]。针对第一种方法,由于部分的青光眼亚种发病过程并不伴随明显的眼内压变化,因此该方法具有一定的偏差性。对视觉区域的评估一方面需要较为昂贵的医疗设备,另一方面该评估方法较为主观,存在较高的观察者内和观察者间的差异[3]。对视神经头区域进行评估主要是通过对数字眼底图像中的视神经头区域进行分析并提取特征来进行青光眼诊断。得益于近些年光学眼底成像技术的进步,基于眼底图像的青光眼定性和定量诊断方法变得可能,同时也成为当前青光眼诊断中所采用的主要手段[4]。在青光眼的发病过程中,视网膜眼底的视神经头区域(也被称为视盘)的视神经细胞会逐步死亡并伴随着中心视杯区域不断扩大,表现出不断扩大的视杯盘比(CDR),如图1所示(数据来源于REFUGE)。因此在临床诊断中,较大的CDR值是评估是否患有青光眼的主要标准之一。为了准确地获取到CDR值,对眼底图像中视杯、视盘区域进行准确的分割即成了青光眼诊断中最为关键、重要的一步。
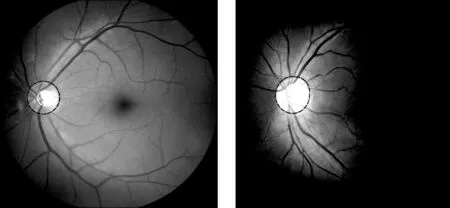
(a) 正常人 (b) 青光眼患者
视杯、视盘分割方法主要分为三大类:人工分割,半自动分割,自动分割。人工分割方法是一种主观、重复性差且耗时耗力的方法,此外针对眼底图像这种医学图像分割需要操作者具有较强的领域专家知识[5]。半自动方法需要初始的人为干预,这些可能会导致结果出现一定的偏差且效率较低。自动分割方法则是将需要分割的眼底图像输入到自动分割系统中,自动处理并输出分割好的结果图像,更加客观,且高效准确。传统的视杯、视盘自动分割方法主要包括基于阈值的分割方法、基于主动轮廓模型的分割方法、基于水平集的分割方法[5]等。上述方法共同的特点就是严重依赖于手工设计的特征,效率和精度都不是很理想,为了满足当前大规模的青光眼诊断需求,更加高效、精准的自动视杯、视盘分割方法研究具有重要意义。
随着近些年深度学习技术的不断发展,卷积神经网络(CNN)开始被应用在医学图像分割中,一些基于CNN的视杯、视盘分割方法也被提出来并取得了不错的效果[6-8]。基于深度学习的青光眼分割方法主要是基于像素分类的,不同于传统的基于像素分类方法[9]和基于超像素的分类方法[10]中采用手工设计的特征,深度学习的方法可以通过模型来自动提取具有高辨别力的特征来进行像素分类,克服了手工提取特征的诸多限制。在众多应用于视杯视盘分割任务的深度学习方法中,基于U-net的方法尤为普遍。U-net是Ronneberger等[11]最先提出的一种基于FCN[12]的深度分割模型,由于该模型在医学图像处理领域的突出表现,越来越多基于U-net的变种方法被应用于医学图像处理的各个领域。Sevastopolsky[7]首次将U-net模型应用于青光眼的视杯视盘分割任务中,通过简化初始的U-net模型取得了较传统分割方法高效且精准的分割结果。Yu等[13]提出了一种基于残差结构的U-net视杯视盘分割网络,将预训练好的ResNet-34模型作为U-net的特征编码模块,一定程度上增强了模型的特征提取能力,取得不错的分割结果。Fu等[8]在初始U-net基础上引入了多尺度的输入、输出和深监督策略,并且采用了极坐标化预处理的方法进行视杯视盘分割,在一定程度上缓解了空间信息损失的问题并取得了优异的分割效果。然而上述的这些方法都是基于多模型的分割架构,因为针对于视杯、视盘分割,视杯和视盘区域相对于整个眼底图像区域而言是较小的,尤其针对视杯分割,这种情况更加突出。因此在传统的视杯、视盘分割任务中,大部分方法都是先利用一个单独的网络来提取视盘区域,即图像的感兴趣区域(ROI)。此外上述方法为了避免分割任务中出现较为严重的类不平衡问题,都采用了基于DiceLoss的损失函数,DiceLoss的一个缺陷就是它对分割中的假阳性和假阴性的权重是一样的[14],然而在实际的分割情况中存在着高准确率、低召回率的特点。针对数据不平衡和感兴趣区域相对较小的分割背景,需要通过增加检测假阴性的权重来提高召回率。
本文提出一种基于注意力机制和递归残差卷积的U型网络(MAR2U-net)用于青光眼的视杯和视盘分割,并且采用了多尺度输入和多标签的Focal Tversky损失函数。
本文方法创新点如下:(1) 采用多标签的Focal Tversky 损失函数来进行视杯视盘的联合分割,在提高效率的同时,也更好地避免了分割中容易出现的类不平衡的问题,使模型更加专注于难分割区域。(2) 将注意力机制引入到视杯视盘分割任务中,可以在ROI区域相对较小的时候,更好地突出与分割任务相关的重要特征且抑制不相关区域特征的表达。(3) 引入递归残差模块可以利用该结构关于时间步的特征积累特性来进行更好的特征表达,且有利于训练更深层次的模型和提取到更低层次的特征。
1 相关工作
Liu等[15]首次将水平集方法引入到视杯、视盘分割中,提出了基于变分水平集的方法对视盘进行分割,对视杯区域的分割采用阈值法和水平集结合的方法,并对分割后结果利用椭圆拟合进行平滑处理,该方法较单纯的基于阈值的方法具有更好的分割性能。Xu等[16]提出了一种利用视网膜结构先验知识从眼底图像中进行高效视杯视盘分割方法,首先将输入图像进行超像素分割处理,然后基于视网膜结构的先验知识利用提取的超像素特征来训练一个超像素分类器,利用分类器对输入图像的超像素进行分类得到包含所有视杯超像素的最小椭圆。该方法与传统基于像素分割方法相比精度有了一定提升且不需要额外带标签的训练数据,但该方法较为复杂且效率较低。
Zilly等[6]提出了一种基于集成学习的混合神经网络用于视杯视盘分割,构造了基于增强滤波和基于熵采样的集成学习的CNN 体系结构,最终取得了优于以往所有方法的分割精度,但是这种方法需要非常大的数据集来训练,同时该方法较为复杂,复现难度较大。之后,Sevastopolsky[7]首次将U-net引入到视杯视盘分割任务中,并对传统的U-net进行了简化,以较小性能损失为代价大大减少了网络的参数量,先通过对视盘区域的分割来提取感兴趣区域,再利用提取好的感兴趣区域进行下一步的视杯区域的分割。
为了实现高效的视杯视盘联合分割,Fu等[8]提出了一种基于多尺度的改进型U-net(M-net)用于视杯视盘分割,先使用一个简单的U-net来提取感兴趣区域,然后使用极坐标变换方法来对视杯视盘区域进行转换,并且采用多标签的损失函数来进行视杯视盘的联合分割,在提升分割性能的同时精简了步骤,大大提高了分割效率。
Alom等[17]提出了一种基于递归残差模块的U-net用于医学图像分割任务,通过引入递归模块,利用递归模块的特征累积特点来使U-net能够更好地提取到具有辨别力的底层特征用于图像的分割任务。Oktay等[18]首次将Attention U-net用于乳腺肿块分割问题,通过将Attention Gate引入到U-net中,在没有使用额外的ROI提取网络前提下,取得了更好的分割性能。实验结果表明提出的Attention Gate能够有效地抑制非ROI区域特征响应,在不增加额外关键区域提取网络前提下提取到了更加具有辨别力的特征。
为了减少分割任务中出现的类不平衡现象,提升模型分割性能,Abraham等[14]在Focal Loss基础上引入Tversky系数提出了Focal Tversky Loss损失函数用于图像分割任务,在减少分割任务中类不平衡现象的同时,保证了高准确率和高召回率,使网络专注于难分割区域,提高了模型分割性能。
2 方法论
本文提出一种多尺度的基于注意力门和递归残差卷积模块的U型网络(MAR2U-net)用于青光眼的视杯和视盘的联合分割。该方法的结构示意图如图2所示。该方法首先使用预处理好的多尺度输入图像输入到模型的编码模块,并在编码模块中引入递归残差卷积模块;同时在模型的译码模块中引入Attention Gate模块和递归残差卷积模块,使用特征拼接方式将两模块进行连接;最后使用深监督的方法来对各层的输出结果进行整合得到最后的分割结果。
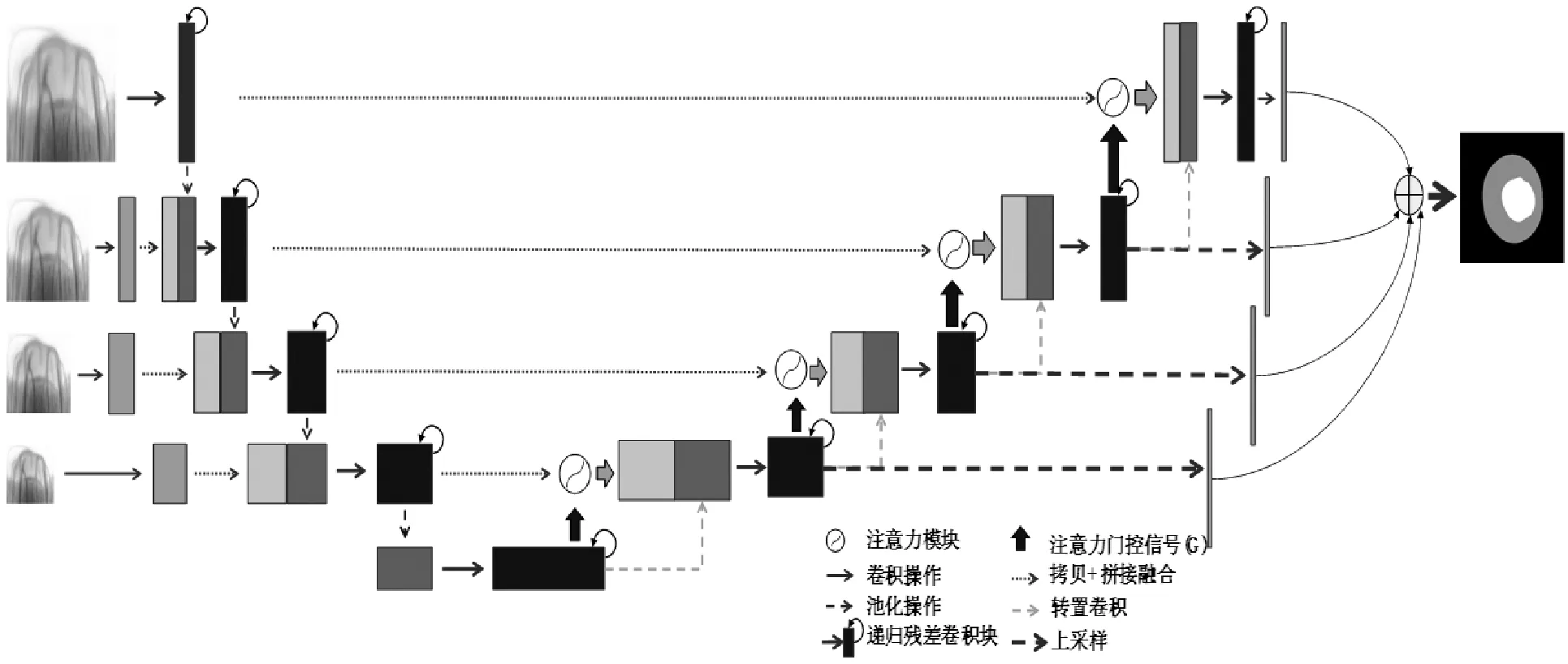
图2 MAR2U-net结构示意图
2.1 U-net
MAR2U-net是一种基于U-net框架的变种。作为医学图像分割领域最常见的一种架构,U-net最早是Ronneberger等[11]提出的一种基于FCN的深度分割框架,其架构图如图3所示。不同于FCN的特征逐点相加的特征融合方式,U-net采用拼接的方式来进行特征的融合,U-net架构相较于其他的分割框架可以更好地提取并融合不同层次的图像特征。其架构主要分为编码、译码两大模块,整个U-net类似一个U字母,网络的左侧即编码路径是由一系列的卷积、池化操作构成的降采样操作,将初始的输入降采样到较小尺寸,一方面可以降低计算量,另一方面可以增大感受野大小,更利于提取到一些更深层次的抽象特征[11]。网络的右侧即译码路径是由一系列反卷积(也被称为转置卷积)和卷积操作组成的升采样操作,逐步将抽象的特征再还原解码到较大的尺寸,中间采用拼接操作将同一层次的编码、译码模块进行了特征融合,相对于FCN的逐点相加模式,拼接的融合方式可以形成更厚的特征[11]。

图3 U-net网络架构图
2.2 Attention Gate
本文采用的Attention Gate是Oktay等[18]提出的一种用于乳腺肿块分割任务的改进型Attention模块。通过提出基于网格的门控,相较于基于全局特征向量的门控,Attention模块可以使注意力系数更加具体到局部区域[18]。该模块可以方便地被嵌入到其他的网络结构中,其结构示意图如图4所示。

图4 AttentionGate结构示意图

(1)
式中:b1和b2表示偏置;Ψ和ω表示1×1×1的卷积操作。
引入Attention Gate的U-net可以增强模型对前景像素的敏感度。传统的U-net架构,对于表现出较大形状差异的小物体,存在较高的假阳性的预测错误。为了减少假阳性预测提高分割的准确率,传统的方法通常会在最终分割前增强一步感兴趣区域提取的操作,Oktay等利用提出的Attention Gate的特点避免了ROI区域的提取并在胰腺分割中取得了较为优秀的结果。
带有注意力门的网络模型能够有效地抑制输入图像中与目标任务不相关区域特征的表达,同时突出与任务相关的特征的表达[18]。最初Attention Gate被提出来是利用该结构可以根据分割任务来抑制非ROI区域特征表达特点来避免ROI的提取操作,但是针对视杯视盘分割任务而言,由于视盘区域相较于初始眼底图像太小,尤其是视杯分割,如果不进行ROI区域的提取,对视杯的分割结果会产生较大的干扰,同时会出现视杯、视盘、背景三者比例过于悬殊的问题[8]。鉴于视杯分割任务难度较视盘分割难度大得多,为了提高视杯分割精度,需要进行ROI的提取操作来增加视杯区域的比例,也可以避免模型训练过程中由于极端的失衡比例而可能导致的过拟合现象[8]。综上所述,本文在进行ROI提取的同时,引入了Attention Gate结构,以此来增强模型的特征提取能力。
2.3 递归残差模块
Alom等[17]最初将递归残差操作引入到U-net中提出了R2U-net架构,并在眼底血管分割、皮肤癌病灶分割、肺部分割等多个任务中验证了该结构强大的特征提取能力,图5(a)为递归残差单元的结构示意图,图5(b)为其中的递归卷积模块(RCL)结构。
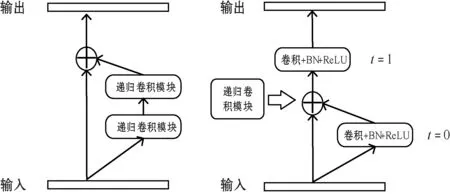
(a) 递归残差 (b) 递归卷积
RRCNN Block的模型内部具有特征累积的功能,因此在模型的训练和测试阶段均能有较好的表现。其中关于时间步的特征累积有利于模型提取更底层的特征且进行更强和更好的特征表达。
2.4 多标签的Focal Tversky Loss
为了实现视杯视盘的联合分割,本文提出一种基于多标签的Focal Tversky损失函数,其中采用的Focal Tversky Loss是Abraham等[14]提出的一种对Focal Loss[20]的改进型损失函数。传统的医学图像分割为了避免分割中出现的类不平衡问题,通常使用基于Dice得分系数(DSC)的Dice Loss,式(2)是针对像素分割问题的DSC表达式, Dice Loss如式(3)所示。
(2)
(3)
式中:c表示图像中像素的类别;pic表示分割结果中像素属于c类别的概率;gic表示标签中像素属于c类别的概率;ε取1e-5防止分母为0。
Dice Loss损失函数虽然可以减少分割任务中存在的类不平衡问题,但是它的一个限制是对于假阳性(FP)和假阴性(FN)检测分配的权重是相同的,然而实际分割中,针对一些高度不平衡的数据和ROI区域较小的情形,分割结果往往会出现高准确率、低召回率的情况[14]。因此需要动态地调整假阳性(FP)和假阴性(FN)检测权重来平衡两者,进而达到更好的分割结果。式(4)是文献[14]中提出的Tversky系数,式(5)是对应的Focal Tversky损失函数。
(4)

(5)
式中:γ取[1,3],表示Focal参数用于调节损失函数的超参。当Tversky较大的像素(容易分类的样本)被错误分类后,FTL值变化不大;当Tversky较小的像素(难分类的样本)被错误分类后,FTL值会显著变化。当α和β都取0.5时,此时Tversky系数就类似于文献[20]首次提出使用Focal参数来使损失函数更加关注于难分割的图像类别。Focal Tversky损失函数可以通过控制分割中易分割的背景和难分割的ROI区域来缓解Dice损失函数中出现的作为关键的ROI区域对损失函数贡献并不是很明显这一缺陷[14]。
考虑到视杯视盘分割任务难度的差异,在视杯视盘联合分割的过程中,本文采用了多标签的损失函数,并且对于视杯视盘的分割贡献进行了动态的平衡。式(6)是文中所采用的损失函数,式(7)和式(8)为具体的FTLod计算过程,FTLoc类似。σ1和σ2是用来调整视杯、视盘对总的损失函数的贡献。
FTLM=σ1FTLod+σ2FTLoc
(6)
(7)
(8)

此外当模型接近收敛的时候,类精度会较高,此时会出现FTL过度抑制的情况。为了防止对损失函数的过度抑制,本文采用了文献[14]中的训练策略:对中间层的训练使用了FTL,但是对最后一层的输出使用了TL,以此来提供较强的误差信号来减轻次优收敛。
2.5 多尺度的输入
传统的U-net虽然采用了拼接的方式将特征进行融合,一定程度上融合了多层次的特征,但是传统的U-net的连续池化操作和跨步卷积操作会导致一定的空间信息损失[21],本文采用了文献[8]采用的多尺度输入层来减少空间信息的损失并提高模型分割精度。文献[8]通过多尺度的输入尽可能地减少了空间信息的损失,通过图像金字塔(多尺度的输入)可以减少由于卷积和池化操作带来的空间信息的损失,进而可以提高图像分割效果[22]。此外多尺度的输入对模型的参数影响很小,且使编码路径的宽度更宽使每层都可以学习到更多丰富的特征[8]。
3 数据预处理
3.1 极坐标变换
本文实验所采用的数据集是全尺寸的眼底图像数据集REFUGE,示例图片如图1所示,可以清晰地注意到视盘区域相比于背景区域要小很多,视杯区域与背景区域的比例则更加夸张。由于视盘和视杯之间的边界相对比较模糊且不容易鉴别,因此视杯的分割难度要比视盘的分割大很多[8]。在实际情况下,这种极端的视杯和背景区域比例会导致视杯分割结果出现较大误差。Fu等[8]为了解决上述的问题,提出了极坐标化的预处理方法。图6展示了图片ROI区域即ROI的极坐标化后的图片。

(a) 经过提取的ROI图片 (b) 初始ROI标签
通过极坐标变换,将原本径向的空间结构关系转化为层状空间结构,即将椭圆边界这种强约束转化为线条处理更加有利于分割任务[8]。在实际的实验中,为了进行极坐标转化,必须先通过预处理的方法来提取ROI区域及该区域的中心点坐标。在获得ROI区域即中心点坐标后,采用不同的半径来进行极坐标化也可以达到数据增量的效果。初始的ROI区域中视杯和背景区域比例虽然相比于原始图片中有了很大提升,但是仍然存在较大的失衡。图像分割即像素级别的分类,较大的类别失衡会对模型的训练产生一定的偏差和过拟合的风险[8]。通过上述的极坐标变化,从图6(b)和图6(d)的对比可以观察到,视杯和视盘及背景区域的比例得到较大的平衡。
3.2 数据增量
不同于自然图像,青光眼诊断所用的数字眼底图片数据集较为缺乏且数据集的规模较小。实验中所采用的REFUGE数据集作为目前最大规模的带有视杯、视盘标签的眼底图像数据集,其训练集数据规模也仅400幅,这个数量对于稍微复杂的深层网络模型很容易出现训练过拟合的情况。本文通过一定范围内的随机旋转、翻转、位移等操作来对训练图片进行了数据增量操作,进而降低模型训练过拟合的风险来提升分割性能。
此外,本文还采用了限制对比度直方图均衡方法(CLAHE)[23]来处理图片,它通过改变图片区域的颜色和插值结果来增强对比度,进而更加凸显视杯、视盘区域。从图7的对比结果可以较为直观地观察到,经过CLAHE处理后的图片的视杯、视盘边界更加明显。
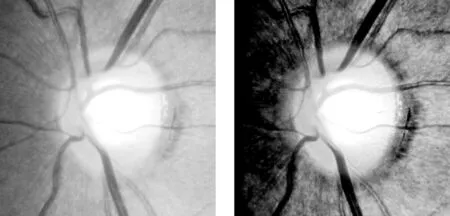
(a) 初始ROI图片 (b) CLAHE处理后图片
4 实 验
本文在REFUGE数据集[24]上测试了MAR2U-net在联合视杯视盘分割任务上的表现,并且对比了已有的多种视杯视盘分割模型:U-net[7],R2U-net[17],M-net[8],MAU-net[14]。表1给出了实验中各个模型的实际参数信息。

表1 实验模型参数量
4.1 评价指标
为了评价分割结果,并与其他分割方法进行比较,本文使用Dice系数和平衡精度(Balanced Accuracy)作为评估标准。Dice系数如式(2)所示;平衡精度计算如式(9)所示。
(9)
式中:TP表示图像中像素预测真阳性的数量;FN表示假阴性的数量;TN表示真阴性的数量;FP表示假阳性的数量。
4.2 数据集
本文所采用的数据集是REFUGE数据集[24],该数据集中分别包含了400幅带有视杯、视盘分割标签的训练、验证、测试集。图8为一幅REFUGE中的测试图片样例。
图8 REFUGE数据集样例
4.3 实验设置
本文实验基于Keras并以TensorFlow作为后端。在训练阶段,使用Adam 优化器[23]来训练优化实验中的模型,学习率设置为1e-5;Focal Tversky损失函数中的超参α和β分别取0.7和0.3,γ取4/3;联合分割损失函数中的超参σ1和σ2分别取0.5和0.5;epoch大小设置为200;此外一个用于从概率图中得到二值遮罩的固定的阈值也设置为0.5。本文实验硬件环境是GTX 1080TI显卡、32 GB的运行内存、i7 8700K的处理器。
4.4 实验结果及分析
从表1中可以观察到R2U-net和MAR2U-net参数量要明显小于其他的模型。正常情况下,因为采用了递归残差卷积模块,网络层数比较深,模型的参数量会非常大。因此为了证明模型分割性能的提升不是单靠扩增模型大小而导致的,本文对实验中的R2U-net、MAR2U-net模型进行了简化,使卷积核的数量减少到对比模型的一半。这样一来,对应模型的参数量就得到了大幅度的减少(R2U-net从24.65 M减少到6.17 M,MAR2U-net从最初的29 M降低到7.31 M)。
表2展示了几种模型在视杯视盘分割任务上的性能表现。为了更加客观地对比各个实验模型,本文对每组实验模型从损失函数、数据预处理方面进行了统一,默认均采用Dice Loss损失函数,以及非极坐标化的输入,其中模型带M的表示多尺度输入。为了更好地对比极坐标化处理和Focal Tversky损失函数的效果,本文增加了三组对比模型,其中:MAR2U-ne-P表示使用极坐标图片作为输入;MAR2U-net-F表示使用Focal Tversky损失函数;MAR2U-net-FP表示两者的结合。由表2可以发现,本文提出的MAR2U-net-FP架构在各个评价指标上较对比方法取得了显著的提升,对于较难分割的视杯区域也取得了较高的分割精度。通过表2中各个实验的对比分析,可以观察到不同模块、处理方法的引入对结果的影响,其中:Dicecup表示视杯分割Dice系数得分;Dicedisc表示视盘分割Dice系数得分;BAdisc表示视盘分割平衡精度;BAcup表示视杯分割平衡精度。对比U-net和M-net的结果可以发现多尺度输入能有效提升模型分割性能;对比U-net和R2U-net可以验证递归卷积模块的引入也可以提升模型性能;在参数量远小于MAU-net的前提下,采用DiceLoss和非极坐标输入的MAR2U-net结果仍优于MAU-net,这也说明模型架构的优越性。通过最后三组的对比实验,可以发现Focal Tversky多标签损失函数和极坐标化处理的引入使本文提出的架构在联合视杯视盘分割任务的性能得到了较大幅度的提升。
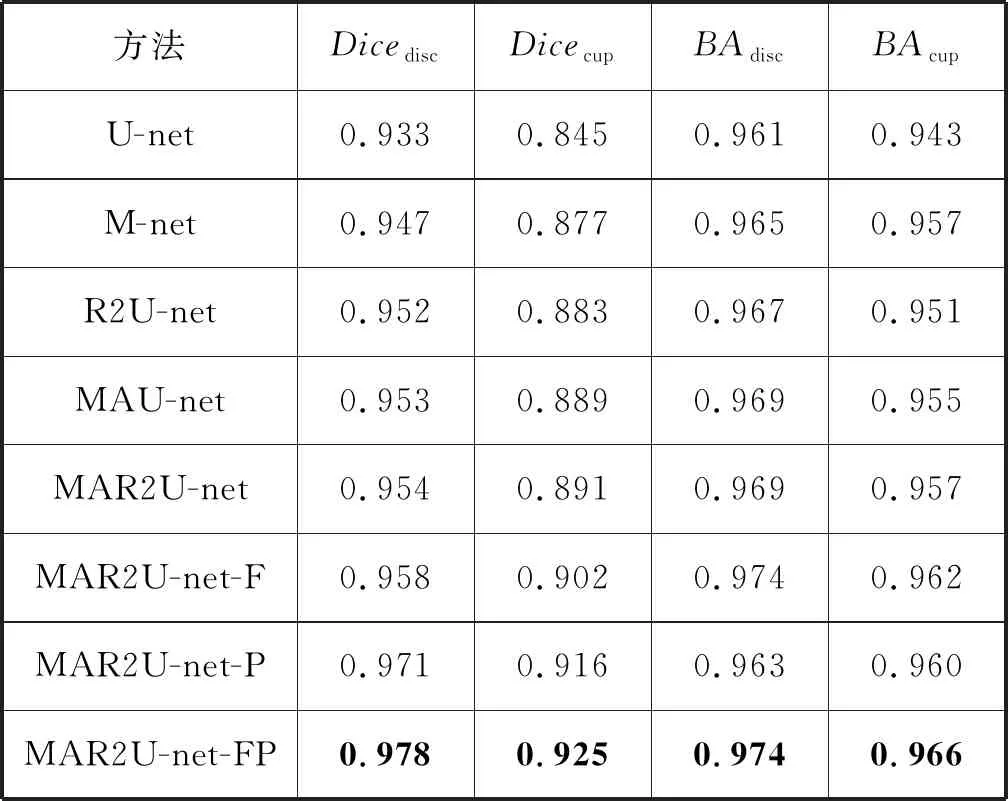
表2 各模型在REFUGE数据集上测试结果
图9直观展示了各模型在部分测试样例上的分割结果。可以清晰地发现本文方法在分割效果上比对比方法取得的显著提升,尤其是在最后一列的测试结果中,由于原图的眼底图像中渗出液影响导致出现较大亮斑,影响了模型对视杯视盘的分割,只有本文方法取得了相对可以接受的结果,但是与标注的结果仍然存在一定差距。

图9 各模型在REFUGE数据集上的部分测试结示意图
此外为了验证Attention机制能够使模型更加专注于关键区域的分割,本文采用了不同大小的ROI图片进行了对比实验。本文采用了以下四种不同的对比模型:U-net400, U-net800,AU-net800,AU-net400。其中400和800分别表示图片ROI区域的尺寸大小。如图10所示,可以发现ROI为400的图片视杯、视盘相比于背景区域的比例要明显大于ROI为800的图片,ROI为400的图片有更好的视杯、视盘、背景比例,对于较难分割的视杯区域,ROI为400的图片更加有优势。从表3的实验结果中可以观察到AU-net400结果优于AU-net800,AU-net800 优于U-net400,U-net400优于U-net800,该对比实验也再一次佐证了文献[18]中的观点:Attention Gate具有ROI提取的类似作用,可以有效地抑制非ROI区域特征响应。此外,通过不同ROI的同一架构的结果对比可知,ROI为400的更有利于提升模型分割结果,因此在实际实验中,本文采用了较小的ROI区域作为模型的训练数据。
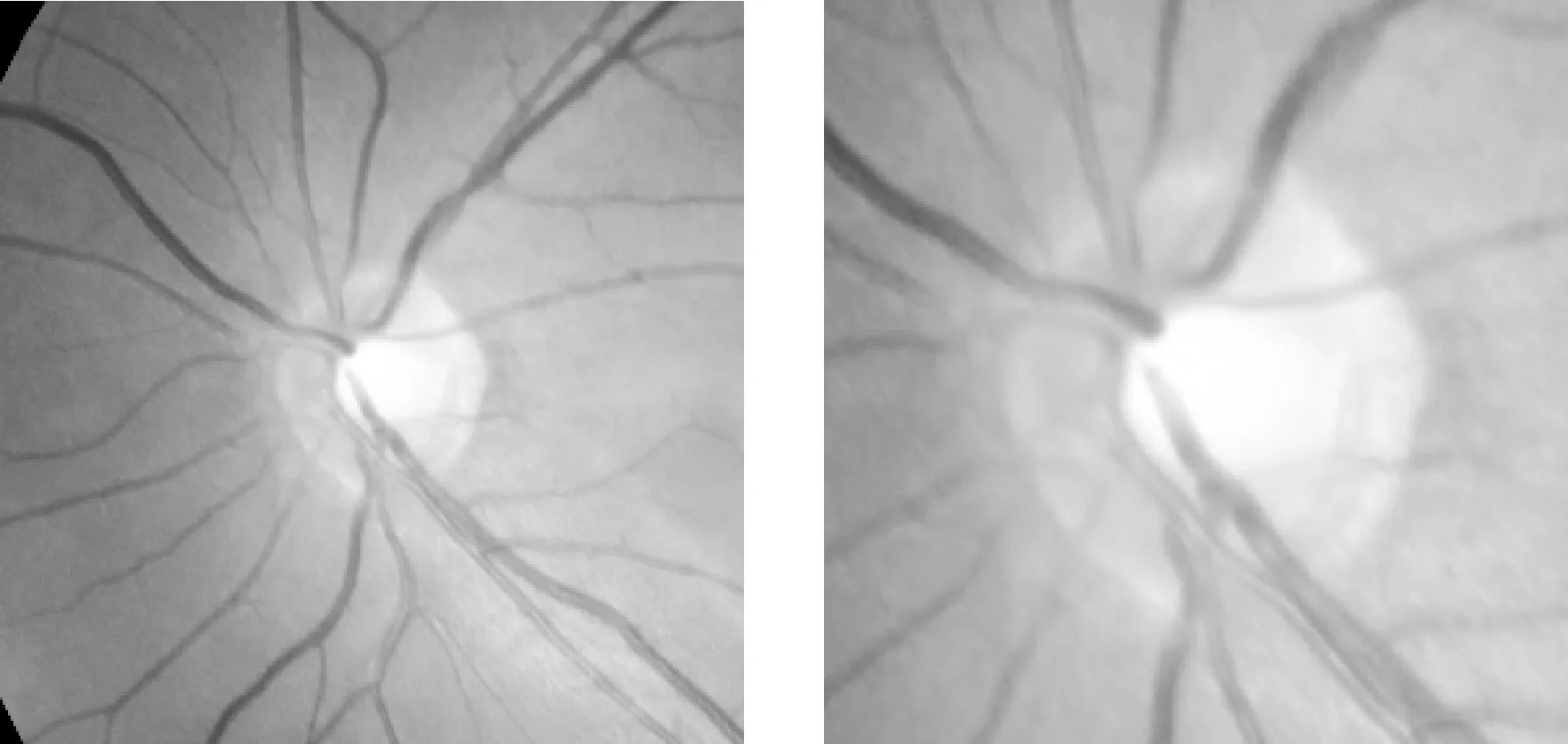
(a) ROI为800的图片 (b) ROI为400的图片
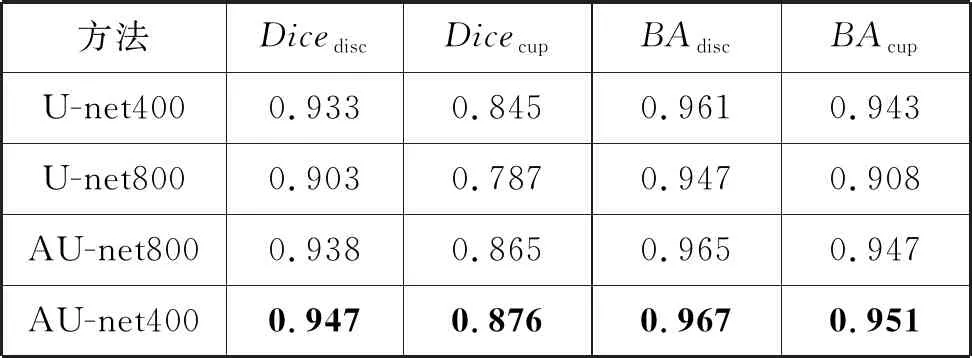
表3 Attention Gate引入对不同ROI输入结果的影响
为了对比不同的σ1和σ2取值对模型训练结果的影响,本文还增加了不同σ1和σ2取值下得到训练模型的测试结果对比,表4是不同取值下模型测试结果,其中U-net11表示σ1和σ2都取0.5,U-net23表示σ1和σ2分别取0.4和0.6,U-net32表示σ1和σ2分别取0.6和0.4。从表4中可以发现U-net和MAR2U-net模型中σ1和σ2分别取0.4和0.6时,视杯分割结果均优于其他取值;当σ1和σ2分别取0.6和0.4时,视盘分割结果达到最好。即通过调节σ1和σ2的取值,可以对不同分割任务进行动态的平衡。U-net23与U-net11相比,Dicedisc值减少了0.004,但是Dicecup值增加了0.16,BAdisc值减少0.001,BAcup增加了0.08,与U-net32比较也出现了较小的视盘分割性能下降和较大视杯分割提升。观察MAR2U-net的三个对比模型结果,也可以发现类似的规律,即:通过对σ1和σ2取值调节可以达到以较小的视盘分割性能损失换取较大视杯分割性能提升。对于较难分割的视杯区域,这种做法显然更有利于提升整体的分割性能。
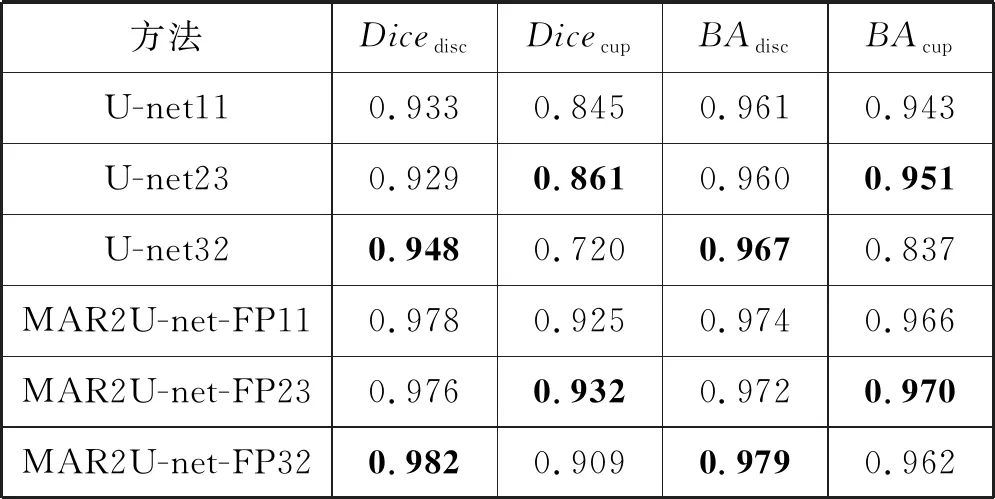
表4 不同σ1和σ2取值下的模型测试结果
5 结 语
本文提出一种新型的联合视杯视盘分割模型(MAR2U-net)。以U-net架构为基础,通过引入注意力机制和递归残差模块,使模型更加专注于待分割的关键区域,并且利用递归卷积的特征累积特点提取到更加利于分割的深层特征,结合残差模块的特点,可以使深层网络得到更好的训练。此外本文还采用了多标签的Focal Tversky损失函数用于联合视杯、视盘分割,一方面提高了视杯、视盘分割效率,另一方面使模型更加专注于难分割的关键区域,平衡了模型分割的准确率和召回率,从而进一步提升了模型的分割精度。最后本文通过了一系列的对比实验证明了本文方法的有效性。
虽然本文提出的方法在视杯视盘分割效果上取得了较为显著的提升,但是对于一些较为特殊复杂的样例,结果仍然需要进一步提高。此外,本文提出的架构在结构上相比于对比方法较为复杂,虽然实验中通过减少卷积核数量使模型参数得到了降低,但是如何在保证高精度分割性能的前提下,进一步使模型更加简洁和轻量化是接下来研究的重点。
