基于机载LiDAR点云多层聚类的单木信息提取及其精度评价*
2021-03-13霍朗宁张晓丽
霍朗宁 张晓丽
(北京林业大学精准林业北京市重点实验室 北京 100083)
激光雷达(light detection and ranging,LiDAR)是一种集激光、全球定位系统(GPS)和惯性导航系统(inertial navigation systems,INS)于一身的用于获取地面及地面目标三维空间信息的主动式雷达探测技术系统。将LiDAR应用于林业领域,不仅能够生成地面地形特征,还能够得到林木树冠表面和垂直结构信息,如树高、冠幅、胸径、生物量等,可为森林生物量、生长模型等研究提供数据支撑(Næsset,2002;Hyyppäetal.,2001)。近年来,随着科学技术快速发展,LiDAR数据获取成本不断下降,应用于林业领域的研究也越来越多,特别是机载LiDAR,探测森林垂直结构的优势日益突出,在林分和单木尺度森林信息提取方面的探索逐步深入(Pedersenetal.,2012;Hyyppäetal.,2012;Packalenetal.,2015)。在单木尺度方面,如果能够通过机载LiDAR数据获取林分中单木位置、树高、冠幅等信息,将极大提高森林经营管理效率,为林木生长动态评估、林分择伐作业、森林可视化经营等提供数据支持。
在LiDAR单木提取研究中,树冠2D分割和3D空间信息分割是2种主要的分割方式(Hyyppäetal.,1999;Solbergetal.,2006;Tangetal.,2007;Ferrazetal.,2012)。其中,常用的2D分割方法有分水岭分割(Tangetal.,2007;Eneetal.,2012)、区域增长法分割(Hyyppäetal.,1999;2001;Solbergetal.,2006)等,但这些方法存在一个共通的问题,即依赖CHM进行分割操作,CHM的滤波效果会极大影响最终提取效果(Eneetal.,2012),且很可能导致信息丢失。从原理上分析,基于CHM构建并进行分割的方法仍为基于表面模型信息的分割,往往是在对最上层点云进行分割、划分单木位置和冠幅范围后将下层点云与之叠加,由于中下层点云利用率较低,数据信息没有充分挖掘,复杂林分结构条件下几乎无法提取到中下层林木,因此研究结果应用范围受限。相比之下,3D空间信息分割则利用每一个点云的空间信息,单木提取更全面,信息也更完整(Lietal.,2012)。目前,常用的3D分割方法主要包括K均值聚类(Morsdorfetal.,2004;Guptaetal.,2010)、均值移动聚类(Ferrazetal.,2012)、自适应距离聚类(Leeetal.,2010;Guptaetal.,2010)等,然而这些方法并不一定都能获得很好的提取效果,一些研究指出其中的单木提取方法误差较大(Kaartinenetal.,2012;Eysnetal.,2015),而对于提取单木正确率能够达到多少的问题,很多研究避而不谈(Guptaetal.,2010;Tangetal.,2013)。3D分割方法存在的困难主要有以下几点:1)对高郁闭度林分下层林木提取能力较低,林分密度、郁闭度、林分结构异质性程度严重影响提取效果,提取效果较好的往往是林分密度较低的(Lietal.,2012);2)提取林木有效性问题,由于3D分割方法对下层林木提取能力较低,导致能够准确提取的林木数量占总体比例偏低(Kandareetal.,2016),如果没有地面实测数据进行匹配,将不能得知是哪部分林木被准确提取;3)点云密度问题,尽管有研究指出点云密度对单木树高、冠幅精度影响不大(Reitbergeretal.,2009;Kaartinenetal.,2012;Yaoetal.,2014),但在复杂林分结构条件下,点云密度过低将造成下层林木信息不完整,影响更新木的提取效果。
此外,以往研究在反演森林结构方面没有过多关注,LiDAR反演森林结构的探索仍停留在林分尺度,且构造的指标仅适用于LiDAR数据,并没有将其与实际生产实践中常用的森林结构指标进行转换,从而导致应用性较低。常用的森林结构指标如树高基尼指数、树高变异系数、聚集指数、竞争指数等,在林分空间结构优化、抚育改造等森林经营管理工作中具有重要指导意义,如果能够通过LiDAR数据反演出高精度的指标,则可进一步将遥感调查结果向生产实践应用转化。
鉴于此,本研究聚焦上述问题,改进单木提取策略和算法,主要特色和创新点如下:1)挑选1块林分密度高、空间结构异质性大的复层林作为研究对象,重点关注中下层林木的提取效果;2)在聚类前将点云划分为多个水平层,增加下层林木探测能力,同时制定合理的点云簇融合方法,重点分析水平层设置情况对信息提取精度的影响;3)构建合理的精度评价指标,重点关注提取林木的正确性、有效性,对提取效果进行综合评价,提升成果的可用性。
1 研究区概况与研究方法
1.1 研究区概况
研究区地处我国甘肃省祁连山国家级自然保护区肃南裕固族自治县西水林场,为祁连山山区天然次生林、黑河流域水源涵养林,海拔2 700~3 000 m,属温带高寒半干旱、半湿润山地森林草原气候,阳坡为山地草原,阴坡为森林景观,林区主要森林类型为青海云杉(Piceacrassifolia)天然纯林(成熟林)。研究区位置、样地布置和原始点云示意如图1所示。

图1 研究区位置、样地布置和原始点云示意
1.2 数据获取与预处理
1.2.1 机载LiDAR数据与预处理 机载LiDAR数据获取于2008年6月23日,无人机平均飞行海拔约3 560 m,距离地面飞行高度约760 m;搭载LiteMapper5600 LiDAR系统,激光扫描仪为RiegILMS-Q560,波长1 550 nm,激光脉冲长度3.5 ns,激光脉冲发散角小于等于0.5 m·rad,地面平均光斑直径38 cm,可分辨目标最小间隔0.6 m,脉冲重复频率50 kHz。
从原始点云中裁出与地面实测数据相匹配的100 m×100 m区域,采用Terrasolid软件进行点云去噪、地面点与非地面点分离、植被标准化,并去掉高度小于2 m的点云,获得样地林层点云作为算法的试验数据。平均点云密度为2.86 m-2。
1.2.2 地面调查数据 地面调查时间为2008年6月1—13日,沿山坡走势布设一块100 m×100 m超级样地,方位角约122°,按照25 m×25 m尺寸划分为16块子样地(图1)。对样地中林木进行每木检尺,记录林木胸径、树高、冠幅和枝下高,通过全站仪获取单木位置,共得到1 435株单木信息。本研究重点讨论LiDAR反演单木树高、冠幅、位置以及林分结构参数的精度,相关统计量如表1所示。
1.3 单木分割方法
聚类是一种无监督学习,其将相似的对象归到同一个簇中,簇内对象越相似,聚类效果越好。本研究应用K均值聚类算法,首先从数据集中随机选取K个点作为初始聚类中心,然后计算各样本到聚类中心的距离,将样本归到距离其最近的聚类中心所在的类。计算新形成的每一个聚类数据对象的平均值得到新的聚类中心,如果相邻2次的聚类中心没有任何变化,样本调整结束,说明聚类准则函数已收敛。基于MATLAB中的聚类算法,完成单木分割、信息提取和精度评价。分层聚类方法提取单木工作流程如图2所示。

图2 分层聚类方法提取单木工作流程
1)点云水平切片 对于郁闭度高、株数密度大的复层林,直接对所有点云进行聚类分析存在2个问题:一是数据量大、运算速度慢,每加入一个新的聚类数据,则需要重新计算其聚类中心,将点云直接聚为2类的时间远大于聚为4类后对相近2类进行融合的时间;二是初始聚类中心的选择依赖于局部最大值位置,对于树高异质性大的林分,只对整体提取局部最大值会不可避免错过被压木的树冠顶点,从而无法分割优势层下的低矮木和更新木。通过对点云进行水平切片(图3),可提取到各林层的局部最大值,尤其更利于下层林木顶点的侦测。切片片层高可根据林分分层情况人为设置,也可依照点云在垂直方向的分布规律自动分层,保证每层点云数量相同。

图3 点云水平切片和局部最大值位置提取
2)点云局部最大值位置提取 决定聚类算法运行效率和聚类效果的主要因素之一是初始聚类中心选择,点云数量庞大,初始聚类中心越接近最终聚类中心,运算效率越高。本研究区主要树种为青海云杉,其形态近似圆锥体,树顶点大致位于该树垂直投影的形状中心,因此通过提取点云局部最大值位置确定树顶(图3),并将其作为初始聚类中心。利用MATLAB中的imregionalmax函数提取局部最大值点,其原理是通过一系列腐蚀、膨胀运算,从1个点的26个邻近点判断该点是否为局部最大值。由于点云数量庞大、异质性高,因此需对点云进行平滑滤波后再提取局部最大值。本研究采用高斯平滑滤波器对点云进行多次滤波,再提取点云局部最大值,所得结果为单木树顶点坐标。
3)点云纵向压缩K均值聚类算法适合于三维特征空间内大体为球体、簇密度均匀的数据集聚类分析,本研究区青海云杉林形态近似圆锥体,因此需对其进行纵向压缩。采用3倍缩放比例,即点云x、y坐标不变,z坐标缩放为原来的1/3。
4)点云层聚类 计算每个缩放后的点云数据到每个聚类中心的欧氏距离,将点云归到距离其最近的聚类中心所在的类,并重新计算聚类中心。重复该步骤至聚类中心不再变化,即完成点云聚类,可获得标注不同类别属性的点云簇。
5)隶属不同点云层的点云簇融合 对接近分割线且聚类中心距离满足一定条件的点云簇进行合并。合并条件具体设置和计算过程如下:经凸包处理求得点云簇面积,将点云簇视为圆求圆形半径作为点云簇半径;融合条件设置为上下2层点云簇中心的水平距离不超过下层点云簇半径。合并顺序如下:从最上层开始,先合并1、2两个点云层的点云簇,得到新的点云簇和聚类中心,再与第3层点云簇合并,以此类推。合并完所有符合条件的点云簇后,重新计算点云簇中心,作为单木位置信息。
1.4 参数反演
1.4.1 单木参数反演 单木分类工作完成后,可获得标注不同类别属性的点云,具有同一属性的点云为同一株单木的点云簇。对点云簇的x、y进行平均,作为单木位置信息;提取点云簇中z的最大值,作为单木树高。在冠幅提取方面,由于点云密度较低,尤其在提取最下层被压木时,存在因点云数量过少、点云共线而无法形成凸包的情况,因此不能应用凸包算法提取林木冠幅。本研究通过点云密度、数量计算冠幅面积的方式求得冠幅,即:
(1)
式中:c为冠幅;d为点云密度;n为点云簇中的点云个数。
1.4.2 林分结构参数反演 获得所有单木的位置、树高和冠幅后,进一步计算林分结构参数。
1)林分树高分布 在林分中,不同树高林木按树高组的分配状态,以2 m为一级,分别统计各树高级范围内的林木数量。为了量化LiDAR提取林分树高分布与实际情况的差异性,计算各树高级林木数量均方根误差:
(2)
式中:n为树高级数;N-test、N-ref分别为各树高级中LiDAR提取数量和地面实测数量。
2)林分冠幅分布 在林分中,不同冠幅林木按树高组的分配状态,原理同树高分布。
3)树高基尼指数(Gc) 树高基尼指数是目前成功应用于树高不均等性测度的极少数指标之一(Gini,1912),为样地中所有个体间某一测定指标成对比较的差值绝对值的算术平均,范围在0~1之间,用于表示树高指标的不均匀性,即群落的树高多样性,指数值越接近1,则林分树高越不均匀,指数值越接近0,则越均匀。计算公式为:
(3)
式中:Xi为第i株树的树高;i为研究区所有林木按高度从小到大排序后的顺序;N为林木总数。
4)树高变异系数(Cv) 树高变异系数可反映林分垂直结构的变化程度,为样地中所有树高标准差和平均值的比较。计算公式为:
(4)

5)聚集指数(Clark-Evans’s aggregation indes)聚集指数是常用的林木空间分布格局指数(Clorketal., 1954),为样地种群内每个个体和其最近邻体间的平均距离与其为随机分布时的期望平均距离比较,所得比率为一随机性偏离测度值,可以根据其统计显著性判断种群分布格局类型,取值范围在0~2.149 6之间,若等于1为随机分布,大于1为均匀分布,小于1为聚集分布。计算公式为:
(5)
式中:r0为样地中每个个体和其最近邻近体间的平均距离;ri为第i个个体和其最邻近体间的距离;E(r)为样地中所有个体随机分布时r0的期望值;A为样地面积(m2)。
1.5 精度评价
1.5.1 参数名称设置 为便于结果呈现,本研究涉及的单木参数名称及缩写如表2所示。

表2 本研究涉及的单木参数名称及缩写
1.5.2 单木聚类效果评价指标 聚类经常会出现欠分类或过分类的情况,在聚类效果评价中,数量精度评价尤为重要。从匹配原理来说,由于匹配时较看重位置和树高因素,而过分类对树高影响不大,只增加了林木位置点,更容易将原本不能匹配的林木匹配在一起,当聚类数量增加甚至超过实际数量时,可以成功匹配实测数据的林木数量往往随之增加,因此片面提升成功匹配林木比例或单独关注聚类数量与实际数量的差异,都不能全面反映聚类效果。本研究设置3个精度指标,具体如下。
1)聚类数量精度(A-QT) 即单位林分中聚类出的单木数量与地面实测单木数量的差异性,代表聚类效果的数量精确程度,公式如下:
A-QT=1-|N-test-N-ref|/N-ref。
(6)
式中:N-test为聚类的单木数量;N-ref为地面实测单木数量。
2)聚类质量精度(A-QL) 即聚类出的单木中可与地面实测单木相匹配数量占总体的比例,代表聚类质量的好坏,公式如下:
A-QL=1-|N-test-N-match|/N-test。
(7)
式中:N-match为成功匹配的单木数量。
3)聚类有效精度(A-ED) 即单位林分中可匹配的聚类单木数量与地面实测单木数量的差异性,代表聚类效果相对实际情况而言有效部分所占比例,公式如下:
A-QL=1-|N-ref-N-match|/N-ref。
(8)
以数量精度、质量精度和有效精度三者的平均值作为总体聚类效果的评价指标,定义为聚类效果指数(A-k),代表聚类方法对单木的侦测和提取能力,公式如下:
A-k=(A-QT+ A-QL+ A-ED)/3。
(9)
2 结果与分析
2.1 不同分层方式对精度的影响
为了对比不同分层方式对精度的影响,暂将点云分为2层并设置分层界限高分别为3、4、5…12 m,统计聚类效果指数(A-k)、单木树高精度(A-h)、单木冠幅精度(A-c)、林分平均高精度(A-H)、树高基尼指数精度(A-Gc)如图4a所示。可以看出,单木树高精度、单木冠幅精度随层高增大变动幅度较小,规律性不大;而树高基尼指数精度、林分平均高精度、聚类效果指数随层高增大呈单峰曲线变化,尤其是树高基尼指数精度在50%~85%范围内剧烈变化,三者的最佳点分别对应层高5、7和9 m,且存在此消彼长现象,无法选出最优情况,故将点云分为2层不能同时满足各方面要求,需进行多层聚类。
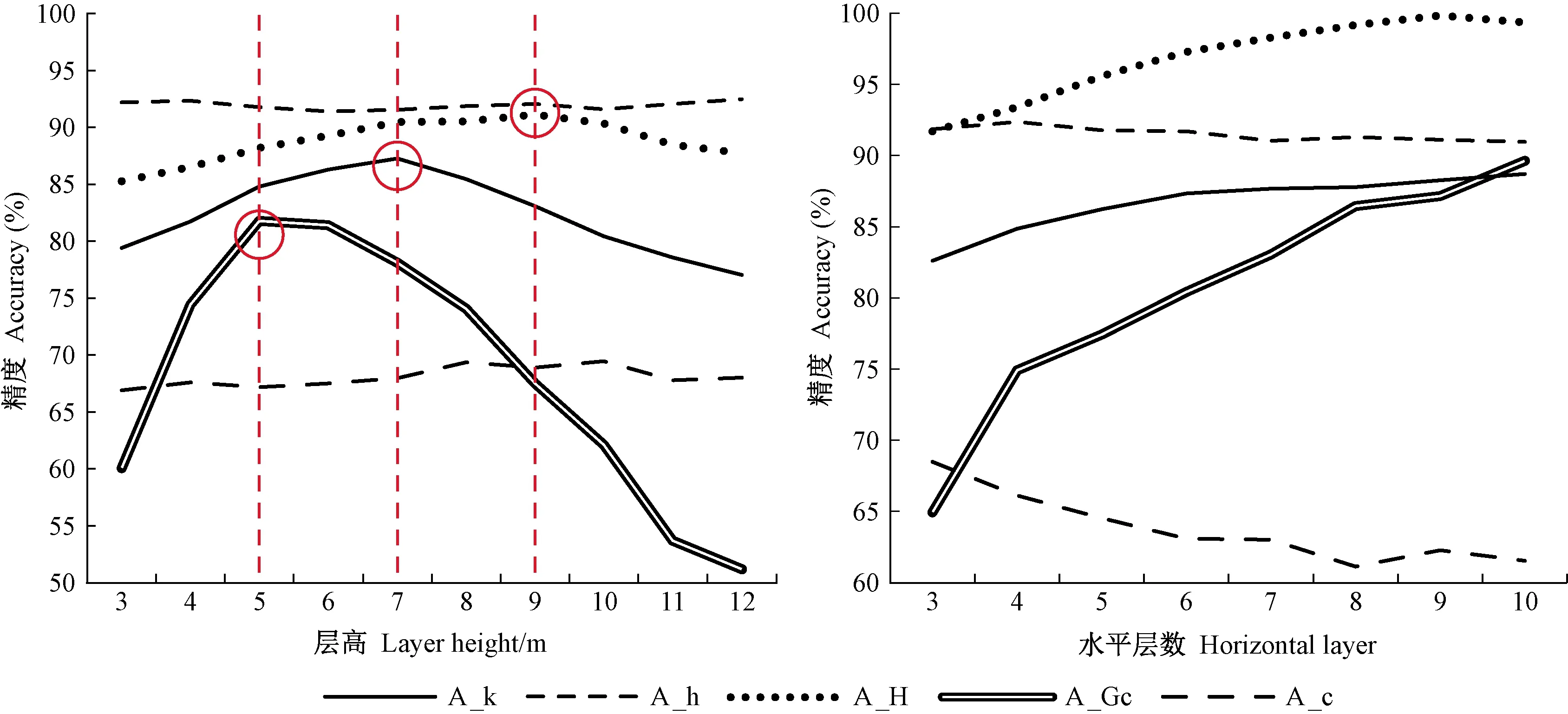
图4 不同分层方式对精度的影响
在多层聚类中,为了避免人为设置层高对精度的影响,统一采用均分百分位数方式进行分层,即保证每层点云数量相同。由4b可知,分层数对林分水平参数精度的影响很大,尤其是树高基尼指数精度变动最大,由65%升至90%,林分平均高精度和聚类效果指数也有明显提升;而单木树高精度变化不明显,单木冠幅精度显著下降。
2.2 参数提取精度
由表3可知,无论分层数设置多少,单木树高精度均在90%以上,可满足林业调查对精度的要求,而单木冠幅精度较低,在60%左右,说明整体冠幅提取难度较大,需进一步改进;此外,聚类效果指数均在80%以上,最高可达88.28%,说明提取有效性较高,而林分平均高精度最高可达99.84%,树高基尼指数精度最高可达89.65%,说明对林分整体信息和结构反演能力较强。

表3 分层数设置对聚类效果和精度的影响
为了解具体影响情况,按树高组的分配状态,以5 m为一级,分别对各树高级的单木树高精度和聚类效果指数进行分析。由图5a可知,无论分层数设置多少,精度曲线大致趋势相同,即10~20 m主林层单木树高精度较高,达94%左右,而少数树高达20 m以上的林木,由于点云密度过低,可能错过树顶点造成树高精度较低。
对比不同分层数的单树高精度和聚类效果(图5b)可知,分层数对5 m以上主林层单木树高精度影响不大,整体单木树高精度差异主要是对5 m以下更新层林木的聚类。随分层数不断增加,对2~5 m更新层林木的提取能力显著增强,由最低的34.86%升至74.43%,而其他林层聚类效果变动不大,直接导致整体LiDAR提取能力较显著提升,但也由此带来了单木树高、冠幅精度的波动。更新层点云密度比主林层低,平均每株林木仅有4.9个点,聚类误差引起1个点的聚类错误,即会对单木整体造成较大影响。对更新层林木的提取也是所有LiDAR单木提取研究中较为困难的一部分。

图5 不同分层数对单木树高精度和聚类效果的影响
2.3 提取有效性
以分2层聚类结果为例,将LiDAR提取出的林木与地面实测林木以5 m为一级,分别统计各树高级范围内的林木数量,计算二者比值代表该树高级的提取率,超过100%的部分视为无效。不同层高对应的各树高级提取率如图6所示。
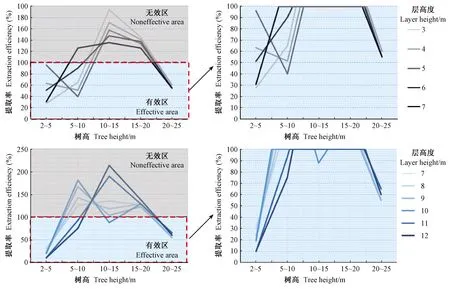
图6 层高3~12 m时各树高级提取率
以7、10 m为界,各树高级提取率大致分2种情况:1)分层高小于7 m或大于等于10 m时,10 m以下林木提取率较低,10 m以上林木提取率虚高,均超过100%,最高甚至达194%,即有近一半林木提取错误,没有实际意义;而决定最终聚类效果指数的往往是10 m以下林木提取的有效性;2)分层高在7~10 m之间,情况正相反。总体来说,提取率曲线在100%以下的面积可代表整体提取有效性高低,如以7 m为分层高,各树高级提取率较为均衡,有效性最高。
2.4 林分结构信息反演
对聚类结果和地面实测林木按树高统计数量,结果如图7所示。可以看出,不分层时树高近似呈正态分布,而实际树高分布为双峰曲线,聚类结果与实际情况严重不符;相比之下,分层聚类对树高分布的预测能力更为突出,尤其对10 m以上主林层,无论是数量还是比例均与实际情况十分吻合,而树高2~8 m时还存在一定误差,可通过提升对下层林木的提取能力来攻克这一难题。此外由上述可知,林分平均高精度最高达99.84%,树高基尼指数精度最高达89.65%,树高变异系数最高达89.23%,同时计算出最邻近体间平均距离为1.53 m,与实际的1.31 m较为接近,均体现了分层聚类算法在林分结构反演上的突出优势。

图7 聚类结果与地面实测林木树高分布情况对比
3 讨论
3.1 LiDAR提取林木的有效性及评价指标
以往LiDAR单木提取研究中,评判算法优劣时较看重提取率、匹配精度和单木树高精度等指标。以分水岭分割为代表的分割表面模型算法以及不分层、直接分割的相关算法由于对林下层点云利用率低,造成林木分割数量少于实际数量,而基于LiDAR提取林木只要不超过树高、距离阈值均视为有效,因此LiDAR提取林木的有效性问题并不突出。但本研究采用的分层K均值聚类算法,很有可能因过分类出现LiDAR提取林木数量多于实际数量的情况,在实际应用过程中,如果没有地面实测数据匹配验证,有效林木和无效林木将无法区分,并可能进一步影响整体结果的有效性。
以往研究表明,林木提取率(提取数量与实际数量比)在20%~60%之间不等(Morsdorfetal.,2004;Kandareetal., 2016;尹艳豹,2010),大多数研究更加关注提取出并匹配的林木在三维信息方面的精度,忽视了提取有效性问题,即没有验证提取出的林木究竟是主林层、优势木还是包括多少比例被压木,因此尽管提取出的部分林木信息很精确,但由于不清楚其与整体的关系,不能够确定这部分信息是否可以代表总体情况,在实际生产应用中意义不大。在LiDAR单木提取研究中,追求能够“更准确”地提取出“更多”的林木,其中“更准确”以单木信息精度来反映,而“更多”则以提取有效性来体现,即本研究中设置的“聚类效果指数”,用该指数综合判断“LiDAR提取了多少林木”“提取的林木中有多少比例是正确的”等问题,充分考虑了结果的可用性。聚类效果指数越高,提取有效性越高,只有达到一定标准,才能说明算法可以摆脱对地面实测数据的依赖,能够直接应用于生产实践中。
3.2 LiDAR点云密度对单木及林分结构信息的影响
点云密度对信息提取的影响是近年来比较热门的研究内容之一。在单木信息精度方面,研究指出点云密度高于20 m-2带来的精度提升微乎其微(Reitbergeretal.,2009;Kaartinenetal.,2012;Yaoetal.,2014),点云密度2、4、8 m-2(Kaartinenetal.,2012)的单木信息提取精度差异不显著,因此,很多后续研究采用先稀释点云再进行信息提取的方法(Magnussenetal.,2010;Hansenetal.,2015)。本研究中,林冠层平均点云密度为2.86 m-2,所得单木树高精度达90%以上,单木冠幅精度达60%以上,与大多数研究结果一致,验证了该密度水平的点云数据可以很好完成单木信息提取工作。
然而在林分结构方面,有研究对60 m-2点云先进行不同程度稀释后再反演林分结构信息,包括林分密度、水平结构和垂直结构,结果发现60 m-2与6 m-2点云的效果存在显著差异,极高密度点云在林分结构反演方面更具有优势(Kandareetal., 2016)。本研究中,通过点云多次分层再聚类的方法反演林分结构信息也得到很好效果,当分层数大于8时,树高基尼指数、树高变异系数精度在85%以上,不以增加10倍信息量为代价也能够较好反演森林结构参数。
在提取有效性方面,目前还未有研究专门探讨点云密度对提取有效性的影响。本研究中,通过点云分层可提升对下层林木的提取能力,但受困于下层林木的点云密度过低,平均每株林木仅有4.9个点云,在聚类时1个点分类错误就有可能引起整体信息的剧烈变化,因此猜测如能提高点云密度,将会提升对下层林木的提取能力,从而提升整体的提取有效性。5 m以上的单木树高精度达90%以上,提取有效性也在90%以上,可反映整体林分除更新层外其他林木的生长情况;如果能够通过提高点云密度从而攻克更新层林木的提取问题,将在森林精准量测、林木生长模型构建、可视化经营等方面起到一定的推进作用。
4 结论
本研究提出一种基于机载LiDAR点云多层聚类的单木信息提取方法,并将其应用于1块林木密度高、空间结构异质性大的复层林进行验证,同时对比不同匹配方法对同一聚类结果的匹配精度。结果表明:1)分多层次K均值聚类进行单木提取具有很好效果,尤其在下层林木的提取方面表现突出;2)可在低点云密度条件下完成工作,降低高密度点云数据信息的冗余;3)在单木信息精度方面,分层K均值聚类提取的单木树高精度达90%以上,单木冠幅精度在60%左右;4)在林分结构方面,采用多次分层方式可提升对林分结构的反演能力,林分垂直结构、水平结构、树高分布结构等方面均有较好反映;5)通过构建LiDAR林木提取有效性指标,着重关注算法的适用性,提取林木有效性最高达88.70%,进一步说明该方法可以摆脱对地面实测数据的依赖,能够应用于生产实践中。
