面向云边协同的资源调度优化策略
2021-03-11赵宏伟荆学慧张子祺
赵宏伟, 荆学慧, 张 帅, 阮 莹, 张子祺
(沈阳大学 信息工程学院, 辽宁 沈阳 110044)
随着工业互联网和5G的大规模商用,整个产业对云边协同的深度融合充满期待.伴随5G技术的推广应用,已有的CDN架构已不能满足5G技术的发展需求[1].目前CDN已结合边缘计算,主要应用于本地化且热点内容频繁请求的应用场景.并将虚拟内容分发网络(vCDN)部署于运营商区域的边缘数据中心,解决传统架构所具有的网络压力大等问题.在日常生活中我们也离不开云边协同架构,如与我们生活息息相关的智慧交通和智慧家居.
传统云计算模式的数据传输过程,需要将用户待处理的大量数据汇聚于云数据中心,这种方式不但时延较长,浪费现有资源,而且对跨域链路带宽造成极大的负担.国内外学者对此也提出不同的改进办法,主要从解决负载均衡问题、任务卸载和排队处理等几方面着手研究.文献[2]提出以跨域作业平均完成时间最小化为优化目标的在线调度算法,该算法解决数据热点积压,边缘节点数据负载不均的问题,在降低整体任务平均完成时间的同时,也能有效降低当前任务完成时间.文献[3]提出一种集中控制的资源调度方法,选择合适少量的边缘计算节点,在已选择的节点间,采取降低端到端的时间延迟.文献[4]提出一种基于蜜蜂角色转换、蜜源的选择和改变随机数3方面优化人工蜂群算法,以满足多维QoS任务资源调度任务,从多方面考虑蜂群算法中解的适应度.减缓求解的搜索速度,扩大解的搜索范围,避免陷入局部最优解,能有效地提升用户满意度.文献[5]针对单目标的虚拟资源调度问题,提出多目标离散问题,在原有的智能算法基础上加以改进,提出离散型人工蜂群算法.满足单目标的同时,从用户和服务商2方面考虑保证多性能的最优化.目前智能算法在处理边缘和云协同的资源调度问题上已经取得一定的成果.但数据发展多样化对云和边缘上资源调度问题提出更高的要求,在提高效率的同时,需要尽可能满足多目标任务.

图1 云边协同的网络结构Fig.1 Cloud and edge collaboration network structure
本文针对上述大环境的要求,结合文献[6]中提出的条件,从经济花费、完成时间和负载均衡3方面建立云和边缘上的适应度计算函数.提出一种改进搜索策略的人工蜂群算法,并结合差分思想,使算法搜索方向和搜索步长随着迭代次数的增加进行相应的调整,加快搜索速率,跳出局部最优解的同时确保解的准确性和稳定性.
云边协同的结构如图1所示,主要分为云计算中心层、终端层和边缘服务器层[7].各层次间相互联系,相互协同通信.
1 改进的人工蜂群算法
智能群体算法在云计算技术中起着至关重要的作用,在资源调度上也取得较好的成果,确保云边结合能够带给用户高效快捷的服务.对此本文提出一种优化的人工蜂群算法,主要是针对搜索策略等加以改进.
1.1 人工蜂群算法
人工蜂群算法(ABC)是模仿蜜蜂行为提出的一种优化算法[8],由蜜源和人工蜜蜂2种要素构成,人工蜜蜂又分为侦查蜂、跟随蜂和引领蜂3种.蜜源相当于优化问题的可行解.引领蜂负责在随机蜜源周围进行搜索找到合适的蜜源,并把搜索到的蜜源信息以一定概率分享给其他蜜蜂.跟随蜂根据引领蜂发送回的信息,按一定概率进行跟随,进一步挖掘.如果蜜源经过若干周期仍没有改进,侦查蜂则随机搜索新的蜜源.具体步骤如下[9].
解的初始化.搜索空间内随机分布产生NP个初始蜜源(x1,x2,…,xNP),对应空间解.每个蜜源xi都是一个D维的向量,其中D是解的维度.由式(1)随机产生可行解xij,其中i∈{1,2,…,NP},j∈{1,2,…,D}.
xij=xmin j+rand[0,1](xmax j-xmin j).
(1)
式中:xmin j表示解在j维度下的下边界;xmax j表示解在j维度下的上边界.
引领蜂阶段.根据式(2)在现有蜜源的基础上搜索新蜜源,即新解vij.
vij=xij+φ(xij-xkj).
(2)
式中,φ∈[-1,1]的随机数,k是{1,2,…,NP}中随机选取的参数,且k≠i.分别计算适应度值,根据贪婪算法,选择较大进行保留.
跟随蜂阶段.跟随蜂采用轮盘赌的方法选择引领蜂,见式(3),选择概率pi大的跟随.其中fiti的计算见式(4).
式中,fiti为xi的适应度,fi表示解的函数值.再根据式(2)在所选择解的周围搜索并计算适应度值,采用贪婪算法选择较好解.
侦察蜂阶段.经过tr次迭代后解仍没有变化,且已超过开采次数L,则放弃该蜜源,选取新解.
1.2 差分人工蜂群算法
当侦查蜂和跟随蜂采取局部搜索时,基于人工蜂群算法的局部搜索策略,随机选取2个蜜源在j维上做差值,作为更新部分.这导致步长是随机选取,没有方向性,浪费不必要的时间.针对这一问题引入最优解xbest的概念,利用已知的最优解提供参考,加快搜索效率.φ表示对步长的扰动程度,决定搜索区域的范围,对此提出结合差分思想的改进人工蜂群算法[10].改进后的方法可以在避免陷入局部最优解的同时,提高搜索效率,从而提高算法的开发能力.这种变异策略以一定的概率变换搜索方程.
vij=xij+2(φ-0.5)(xij-xkj)+φ(xbest,j-xij),φ∈[0,1].
(5)
式(5)中,式(2)更新的蜜源变为新的vij,2个蜜源的步长系数由原来的φ变为2(φ-0.5),在原有基础上增加搜索密度,对解的范围加以精分,大大增加解的可能性,克服原人工蜂群算法的局限性.同时利用精英因子的学习功能,兼顾搜索速率.式(5)的第3项易使当前解偏向原有最优解,所以给予较小倾斜,当系数取0时,式(5)更接近式(2).
在式(5)的基础上提出改变φ的系数得到式(6),这样即使在解的密度较大情况下,也能及时跳出局部最优的限制,增加步长,避免陷入局部最优解.对于后期的搜索也可以避免已知最优解的影响,增加随机性,从方向和步长2方面寻求新解,加快搜索效率.a、b分别为第2项和第3项的系数因子[11].K表示人工蜂群算法迭代次数.
vij=xij+2a(φ-0.5)(xij-xkj)+bφ(xbest.j-xij),φ∈[0,1].
(6)
DABC算法描述给出了改进后的人工蜂群算法具体执行过程.变系数人工蜂群算法,是通过结合差分的思想以及添加变系数因子在原始人工蜂群算法上加以改进.算法中种植条件由3个评价指标负载均衡度、经济花费和消耗时间的阈值所决定,当迭代周期数达到最大迭代周期数时,记入当前的最优解.改进算法中根据式(6)更新蜜源,其中a、b主要决定搜索效率,加快搜索最优解的时间.
算法伪代码如下.

1) 输入:最大迭代周期数L,初始蜂群规模Cn,蜜源NP,函数维数D;2) 初始化食物源位置xij,其中i∈{1,2,…,NP},j∈{1,2,…,D},评估蜜源质量(即解的适应度值fiti).3) While(l≤L) do4) 引领蜂阶段 每个引领蜂选取相应蜜源; 根据式(6)产生一个新的蜜源vij; 计算该位置适应度值fiti,应用贪婪选择机制进行选择;5) 根据式(3)计算每个蜜源被选择的概率pi;6) 跟随蜂阶段 每个跟随蜂采用轮盘赌选取引领蜂进行跟随; 根据概率pi选择一个蜜源; 根据式(6)在该蜜源周围搜索产生新蜜源vij; 计算新蜜源适应度值fiti,应用贪婪选择机制进行选择;7) 侦察蜂阶段 判断是否有放弃的解; 如果有,引领蜂变成侦察蜂; 根据式(1)在解空间随机产生新蜜源; 如果没有,结束搜索;8) 记住迄今为止发现的最优解9) l=l+1.10)End while11)输出:最优解.
2 云边协同资源调度
2.1 云边协同系统调度框架
云边协同调度框架如图2所示,用户设备发送任务到达服务器,由服务器将任务抽象成n个子任务,分别送于不同的边缘集群进行计算.由于边缘集群计算能力有限,对于较大任务调度到云计算中心处理,再由云计算中心将数据层层反馈至用户设备端.
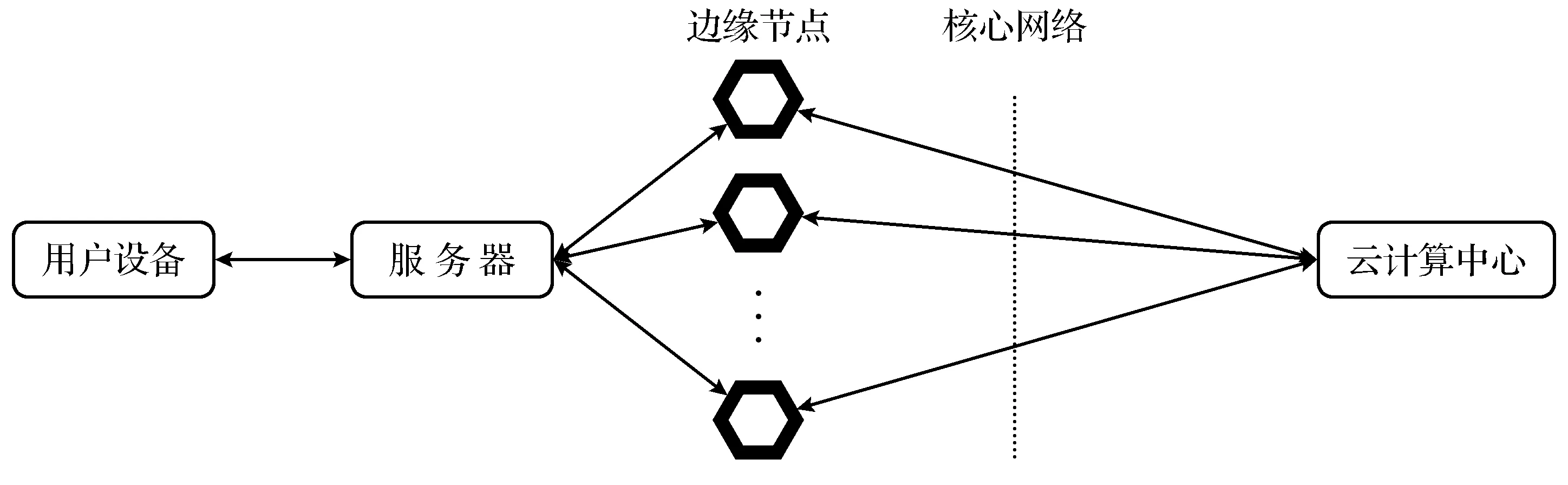
图2 云边协同调度框架Fig.2 Cloud edge collaborative scheduling framework
2.2 云边协同调度模型
边缘和云协同系统中包含一个计算能力强大的云计算中心,和跨域部署于各地区的边缘集群构成.各集群的计算能力用计算单元s的数量来描述,各计算单元的处理能力均相同.边缘集群以Si表示,云计算中心以Sv表示.各集群包含不同的计算热点,热点所含有的计算单元数目不同则计算能力不同,云计算中心视为计算单元充足.将任务T采用一定算法分配到各集群上,同时满足各项评价指标,这里给出负载ws、经济花费c和消耗时间t三个指标.
任务T分解为n维的抽象子任务T={T1,T2,…Tn},每一个子任务Ti分配到一个计算集群(Si)处理.每个计算集群中包含m个计算能力不同的计算热点Si={Si1,Si2,…,Sim}.本文引入3个消极的评价指标,即表现为数值越小越好的评价指标,以P表示集群属性.则每一个计算集群热点属性可以表示为P(Sim)={pw s,pc,pt},由此每一个计算集群属性记为P(Si)={Pw s,Pc,Pt}.m表示每个计算集群的热点总数,n表示需要计算的抽象任务数[12].综上计算集群则需要满足以下条件:
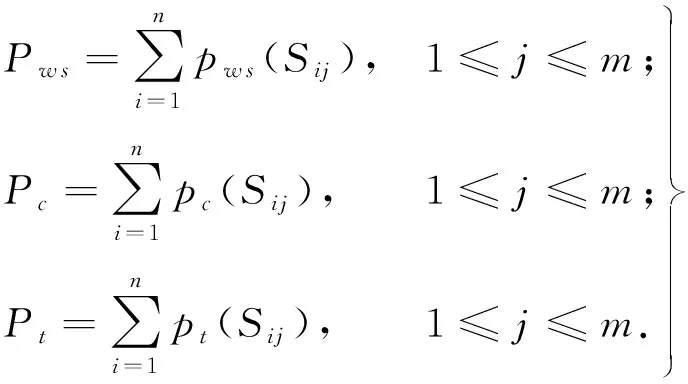
(7)
在数据处理上优先考虑将数据上传至边缘端,各抽象任务部署于边缘集群的属性集合式(7)上,则应满足少于调度至云端的负载均衡度、经济花费和消耗时间.即满足条件如下:
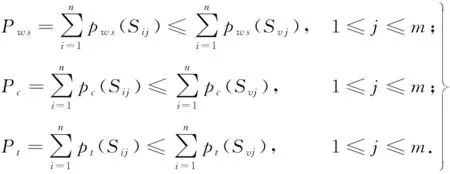
(8)
云计算中心计算功能强大,计算单元数充足. 当把抽象任务集中于云端时, 任务可以全部计算, 但计算单元应用达到最多, 消耗资源最多, 负载、经济花费和时间消耗都较大, 不适宜选取. 当把待处理任务集中于某一边缘计算集群时, 集群可能因计算单元不足而无法完成计算任务. 对此提出用解本身最小值来弥补, 用当前解值和最小解做差值, 消除最理想状态. 所以选取式(9)计算解的适应度函数,消除影响.
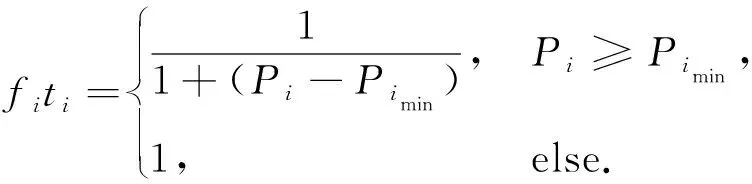
(9)
式中:Pi表示计算集群单个属性;Pimin表示单个属性的最小值.
2.3 基于DABC的云边协同资源调度
基于改进人工蜂群算法DABC的云边协同资源调度策略,将云边协同资源调度的3个评价属性负载均衡度、经济花费和完成时间的最优值选取问题转化为人工蜂群算法对Pw s、Pc和Pt的寻优问题.并选取云边协同调度模型作为适应度函数,最大迭代周期数L的选取依赖于云边协同仿真模拟器的处理能力和实际任务数.蜂群整体规模的选取依据为云边协同资源调度系统所需要处理的任务T.以下是云边协同资源调度的具体流程:
步骤1 设置3个评价指标负载Pw s、经济花费Pc、消耗时间Pt,最大迭代周期数L;
步骤2 根据需要处理的任务数T,随机产生初始种群,蜂群规模为Cn;
步骤3 引领蜂初始化蜜源位置,根据式(9)评估属性适应度fiti;
步骤4 根据式(6)的计算方法(这里xij和vij均为资源调度策略中的任务属性解,以Pi表示)产生任务属性Pi的解,并计算该位置适应度值;
步骤5 根据式(3)计算解的选择概率pi,跟随蜂采用贪心算法进行跟随;
步骤6 跟随蜂根据式(6)的计算方法在已求得单个属性Pi的解周围产生任务属性的新解Pi;
步骤7 计算新求得任务属性解的适应度,采用贪婪机制选择;
步骤8 判断是否有被抛弃任务属性Pi的解,如果有,引领蜂转化为侦察蜂,侦察蜂根据式(1)进行计算,随机搜索新属性的较好解;
步骤9 记入当前任务属性得到最优值;
步骤10 判断是否满足终止条件,预设的仿真模拟器最大迭代周期数;
步骤11 满足则输出最优的资源调度方案,若不满足则转为步骤4.
3 云边协同资源调度模拟仿真
本文实验在CloudSim仿真器上结合多台虚拟机进行模拟. 选取一个云数据中心,600个边缘集群, 各边缘集群所含热点数随机. 任务数由100~500递增. 为评价多目标情况下云边协同调度模型及改进算法, 本文通过多次改变经济花费、负载均衡度和完成时间3个函数的权值的大小, 得出算法改进有效的结论, 同时也验证了算法的普适性和稳定性. 本文选取人工蜂群算法(ABC)、改进的人工蜂群算法DABC和PSO算法进行比较, 通过改变任务数来衡量对经济花费, 完成时间和负载均衡度造成的影响.
通过图3可以得出改进算法有效降低成本,改进算法中随着任务数的增加,经济花费增长逐渐变缓,说明更多的任务选择部署在边缘端,就近选择本地服务器来调度数据,减少不必要的资源浪费,降低调度成本.整体可以看出改进算法有效降低成本,任务数越高,效果越明显.
图4看出人工蜂群算法对完成时间的影响较大,能有效的减少完成时间,提升算法效率.由于是多目标问题,需要牺牲其他函数,对经济花费和负载均衡度的提升有一定影响.当任务数增多时,完成时间降低效果较好,随着任务数的增长,后期完成时间增长相对稳定.
图5显示了负载均衡度随任务数增长的变化,利用空闲资源与带宽进行任务调度,分散整体任务,将整体任务部署于多个边缘集群和云计算中心,以达到负载均衡的目标.当任务数较少时,对PSO算法的负载均衡度影响较大.从整体图像可以看出,相较于其他2种算法改进的人工蜂群算法对负载均衡度有一定影响.ABC算法和DABC算法较为平稳,说明系数因子对负载均衡度影响较小.
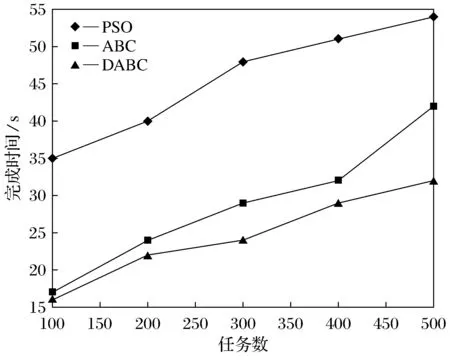
图4 完成时间随任务数的变化

图5 负载均衡度随任务数的变化
4 结 论
本文针对跨域环境下的资源调度问题,提出了云边协同的多目标资源调度优化策略.基于云和边缘计算的各自特点,搭建了云边协同资源调度模型,其综合考虑经济花费、完成时间和负载均衡3个指标,同时提出一种基于差分思想的人工蜂群算法,用于优化和求解所构建的协同模型.最后,通过仿真实验验证,DABC蜂群算法性能较好,云边协同模型能满足云边资源调度系统的多目标要求,在降低成本和减少时间的同时,提高了资源调度效率.DABC算法和模型对解决云边协同的多目标资源调度问题具有重要的意义.
