基于GSK-AdaBoost-LightGBM的交通事故死亡人数预测研究
2021-03-11纪俊红昌润琪温廷新
纪俊红,昌润琪,温廷新
(1.辽宁工程技术大学安全科学与工程学院,辽宁 葫芦岛 125105; 2.辽宁工程技术大学系统工程研究所,辽宁 葫芦岛 125105)
道路交通事故对人类生命和财产安全造成了极大威胁,被认为是当今世界最严重的安全问题之一。据世界卫生组织(WHO)统计,交通事故每年导致全世界大约135万人死亡,2 000万至5 000万人受伤,各国每年因交通事故造成的经济损失达到了各国国内生产总值的3%左右。因此,开展交通事故的预测研究已成为交通事故预防的重要环节,有助于相关决策者提前了解事故发生趋势,预先采取管控措施。
近几年,机器学习学科发展迅速,众多学者基于机器学习算法建立了交通事故预测模型,如基于支持向量机、最小二乘支持向量机的交通事故预测模型,基于BP神经网络的交通事故预测模型,将多元线性回归方法应用于交通事故死亡人数预测,基于贝叶斯网络的交通事故预测模型,基于LSTM神经网络的交通事故预测模型,基于人工神经网络(Artificial Neural Network,ANN)的交通事故预测模型。
以上学者的研究推动了我国交通事故预测领域的发展,但是应用的算法类别较为集中,主要为神经网络等算法,且多为单一基础算法,关于树类算法、集成算法的应用研究相对较少。
Light Gradient Boosting Machine(Light-GBM)是Ke等于2017年提出的一种Boosting集成模型,不同于其他梯度增强决策树算法,LightGBM算法应用的是基于Histogram的决策树算法,提出了基于梯度的单边采样(Gradient-based One-Side Sampling,GOSS)和互斥特征捆绑(Exclusive Feature Bundling,EFB)。因此,LightGBM算法不仅表现出了优异的预测性能,还具有训练速度更快、内存消耗更小等特点,已被广泛应用于互联网金融、网络安全、心理学以及医学等众多领域。因此,本文拟将LightGBM算法应用于交通事故预测领域,但单一基本算法泛化能力有限。AdaBoost是一种自适应的Boosting算法,通过将多个基本算法加权组合形成一个强预测器,以实现提升预测精度的目的,已在冠心病中医症候诊断、人脸检测、遥感影像水体信息提取以及火灾烟雾探测等多个领域得到了广泛的应用。
综上,本文基于AdaBoost算法集成多个LightGBM模型建立了AdaBoost-LightGBM(Ada-LightGBM)增强集成模型,并应用网格搜索法和K折交叉验证(Grid Search and K-Cross-Validation,GSK)进行参数寻优,进一步优化模型,最终得到了GSK-AdaBoost-LightGBM模型。
我国道路交通事故统计主要有事故次数、死亡人数、受伤人数和经济损失4项指标,但事故次数、受伤人数和经济损失易出现衡量标准不一致、统计遗漏等问题,而死亡人数的可测性、代表性较强。因此,本文以死亡人数作为研究对象,基于采集到的1953—2018年我国道路交通事故数据训练模型,得到了基于GSK-AdaBoost-LightGBM的交通事故死亡人数预测模型;同时,引入均方误差(MSE)、平均绝对百分误差(MAPE)和平均绝对误差(MAE)3项评估指标评估了模型的预测性能,探究了模型的优化效果,以期为交通事故预测领域的研究工作开拓思路,从而提升交通事故预防工作的效率,以提高道路安全性。
1 GSK-AdaBoost-LightGBM模型
1.1 GSK-AdaBoost-LightGBM模型的基本原理
GSK-AdaBoost-LightGBM模型的主体构建思路是基于AdaBoost算法训练LightGBM多次,得到多个LightGBM基预测器,然后将多个基预测器加权组合得到强预测器。但是,LightGBM算法和AdaBoost算法都包含多个超参数,不当的参数取值会极大地影响其预测的准确性。因此,将网格搜索法结合K折交叉验证(本文进行5折交叉验证)作为本文的参数寻优方法,对LightGBM和AdaBoost算法的主要超参数进行参数寻优。GSK-AdaBoost-LightGBM模型的基本原理见图1。
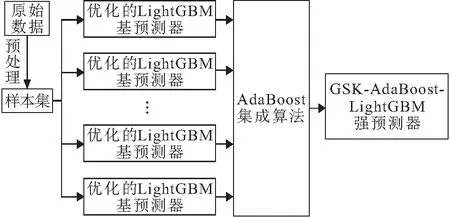
图1 GSK-AdaBoost-LightGBM模型的基本原理Fig.1 Basic principle of GSK-AdaBoost-LightGBMmodel
1.2 构建并训练GSK-AdaBoost-LightGBM模型
GSK-AdaBoost-LightGBM模型的具体构建、训练过程如下:
第1步:样本采集,数据预处理。采集样本数据,结合实际,排列成k
组,并采取数据标准化等预处理措施,生成用于训练模型的样本集。第2步:构建GSK-LightGBM基预测器。初始化LightGBM算法,基于样本集,应用网格搜索法对LightGBM模型进行参数寻优,同时进行5折交叉验证,输出LightGBM模型较优的超参数取值,进而得到优化的LightGBM(GSK-LightGBM)模型。
第3步:构建AdaBoost-LightGBM强预测器。将GSK-LightGBM模型作为基预测器,基于样本集,训练基预测器n
次,将n
个基预测器加权组合得到AdaBoost-LightGBM强预测器。第4步:构建并训练GSK-AdaBoost-LightGBM模型。应用网格搜索法结合5折交叉验证得到AdaBoost-LightGBM模型较优的超参数取值。据此设置强预测器的超参数,即得到GSK-AdaBoost-LightGBM模型。基于样本集,训练基于GSK-AdaBoost-LightGBM的预测模型,输出模型最终预测结果。
GSK-AdaBoost-LightGBM模型的构建流程如图2所示。
2 基于GSK-AdaBoost-LightGBM的交通事故死亡人数预测模型
2.1 样本采集与预处理
基于文献[35]和国家统计局网站中采集到的1953—2018年我国交通事故数据构建样本集,所有数据完整无缺失。
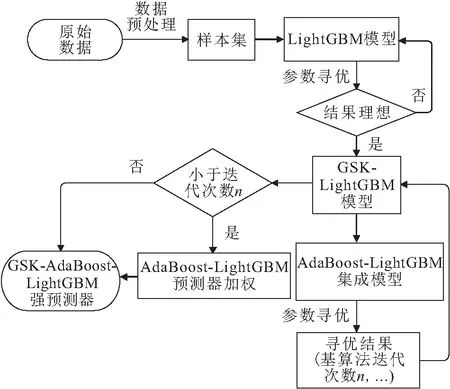
图2 GSK-AdaBoost-LightGBM模型的构建流程Fig.2 Construction process of GSK-AdaBoost- LightGBM model
交通事故死亡人数的影响因素众多,国内外关于交通事故死亡人数的预测研究主要考虑的影响因素是人、车、环境和道路四个方面,本文结合现有经验和采集到的实际数据,通过分析得到交通事故死亡人数(dypeo)的影响因素为:人口数量(people)、民用汽车拥有量(car)、国内生产总值(GDP)、公路里程(dist)、公路旅客周转量(trav)和公路货物周转量(goods)。1953—2018年我国道路交通事故死亡人数及统计指标值的部分数据,见表1。
训练模型时,将当年6个影响因素的值作为输入变量,第二年的交通事故死亡人数作为输出变量。另外,考虑到各影响因素的单位、量纲不尽相同,因此先对数据进行归一化处理,应用归一化处理后的样本集开展研究。
2.2 实验描述及结果分析
本文基于Python编程平台开展实验研究,按照3∶1的比例设置训练集和测试集。随机选取1962年、1966年、1972年、1974年、1978年、1980年、1983年、1986年、1988年、1992年、1993年、1995年、1997年、2002年、2012年、2015年的样本数据组成测试集,用于检验模型的预测性能,其余数据组成训练集,用于训练模型。

表1 1953—2018年我国道路交通事故死亡人数及统计指标值(部分数据)
(1) 构建并训练GSK-LightGBM基预测器。基于样本集,应用网格搜索法同时进行5折交叉验证,实现LightGBM模型的参数寻优。输出参数寻优结果:叶子节点中最小的数据量为2,叶子节点数为5,学习率为0.1,决策树子树数量为87。据此设置LightGBM算法的超参数,得到GSK-LightGBM模型。输入交通事故样本集,训练基于GSK-LightGBM的预测模型,输出的3项评估指标值见表2。
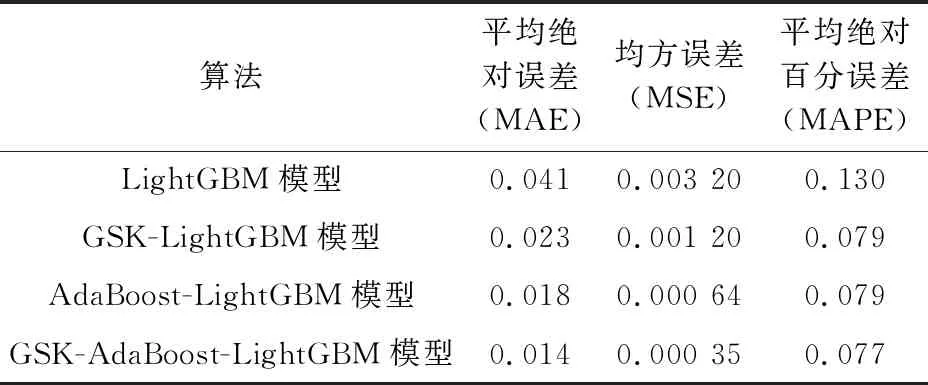
表2 不同预测模型输出的评估指标值
(2) 构建GSK-AdaBoost-LightGBM强预测器。训练GSK-LightGBM基预测器n
次,基于AdaBoost集成n
个基预测器,加权组合形成AdaBoost-LightGBM强预测器。结合5折交叉验证,采用网格搜索法进行参数寻优,得到强预测器较优的超参数取值:基本算法迭代次数为41、学习率为0.1、随机数种子为73,进而得到性能较优的GSK-AdaBoost-LightGBM强预测器。(3) 训练并评估基于GSK-AdaBoost-LightGBM的强预测模型。基于交通事故样本集训练GSK-AdaBoost-LightGBM预测模型,输出预测值,并对其进行逆归一化处理,考虑到交通事故死亡人数的实际特征,将逆归一化处理得到的预测值保留成整数形式,并与实际值进行了对比,以检验模型的预测性能,预测模型的3项评估指标值见表2。
为了探究GSK-AdaBoost-LightGBM模型的优化效果,利用相同的样本集,本文亦训练并评估了基于LightGBM和AdaBoost-LightGBM的预测模型。算法的主要超参数随机取值如下:LightGBM模型中,叶子节点中最小的数据量为13,叶子节点数为24,学习率为0.9,决策树子树数量为42;AdaBoost-LightGBM模型中,基预测器的参数值根据GSK-LightGBM的参数值设置,随机设置强预测器的超参数,即基本算法迭代次数为32、学习率为0.4、随机数种子为3。训练该两个预测模型输出的评估指标值见表2。
通过比较不同预测模型输出的评估指标值发现(见表2),GSK-AdaBoost-LightGBM模型输出的3项评估指标值(MAE、MSE和MAPE)均为最小值;经过参数优化得到的GSK-LightGBM模型输出的MAE、MSE和MAPE比LightGBM模型分别降低了43.9%、62.5%、39.23%;基于AdaBoost算法集成后得到的AdaBoost-LightGBM模型输出的MAE、MSE又进一步分别降低了12.2%、17.5%;对强预测器进行参数寻优,最终得到的GSK-AdaBoost-LightGBM模型输出的MAE、MSE和MAPE又分别降低了9.76%、9.06%、1.54%。综上可知,基于GSK-AdaBoost-LightGBM模型的预测准确性最高。
GSK-AdaBoost-LightGBM模型预测值与实际值的对比,见图3。
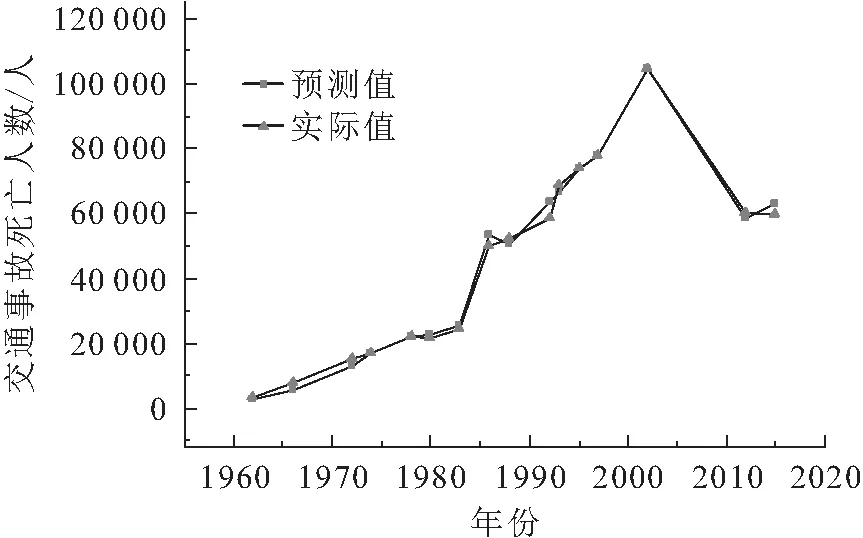
图3 GSK-AdaBoost-LightGBM模型预测值与 实际值的对比图Fig.3 Comparison between the actual value and the predicted value of the GSK-AdaBoost- LightGBM model
由图3可见,两曲线吻合程度较好,表明GSK-AdaBoost-LightGBM模型对交通事故死亡人数的预测准确性较高,模型拟合效果较好。本文基于AdaBoost算法集成多个LightGBM模型,并对基预测器和强预测器的主要超参数均进行了参数优化,最终得到的GSK-AdaBoost-LightGBM模型的预测准确性明显提高,且该模型的MAE、MSE和MAPE值分别比单一的LightGBM模型下降了65.85%、89.06%和40.77%。
3 结 语
相比于基于LightGBM训练的模型,本文建立的基于GSK-AdaBoost-LightGBM的交通事故死亡人数预测模型的预测准确性更高,且该模型训练速度较快,对噪声和异常值的容忍度较高,泛化性及抗拟合能力较强,亦适用于大数据场景,可为交通事故预测研究提供方法支撑,有助于交通事故预防工作的开展。后续可考虑进一步探究GSK-AdaBoost-LightGBM模型在交通事故严重程度及实时预测等场景的应用。
