基于机器学习的海里油耗估计算法
2021-03-09李湘军朱慧敏谭笑张瑞薛晨彭志强
李湘军,朱慧敏,谭笑,张瑞,薛晨,彭志强
(震兑工业智能科技有限公司,广东 深圳 518101)
0 引言
当前世界经济形势低迷,国际航运市场也不可避免地受到影响,如何降低航运的成本,提高利润,成为国际航运市场普遍关心的话题,而降低主机燃油消耗则是其中关键的一环。与此同时,随着生产力的发展,人民生活水平的提高,越来越多的国家开始关注环境问题,要求航运船舶降低碳排放量。这些均促使着航运公司追求更低的主机燃油消耗。
一方面,挖掘与主机燃油消耗相关的因素,进而建立主机的燃油消耗模型,是进一步实现更低主机燃油消耗的重要条件。另一方面,流量计价格昂贵,也给船运公司造成了一定的负担,而当前基于实际航行数据进行油耗估计的研究却很少。在此背景下,本文提出了基于机器学习方法的海里油耗估计模型,既为指导船舶更高效地利用燃油,也为船舶无流量计运行而依赖算法根据实际航行数据估计船舶燃油流量奠定了基础。
首先,本文利用随机森林算法从众多的参数中选择出了与主机燃油流量最相关的五个参数;其次,对输入的五个特征维度进行了预处理;最后,为了验证所选特征的有效性,本文从众多船舶参数中随机抽取五个特征与所选特征进行建模对比,多次实验结果表明随机森林所选特征取得了最高的准确度,证明了该方法的有效性。
为了增强模型的可解释性,本文使用LASSO回归建模对主机燃油消耗进行预测,实验结果表明LASSO算法具有较好的预测结果和较强的可解释性。
1 随机森林和LASSO回归
现实情况下,一个数据集中往往有成百上千个特征,如何在其中选择对结果影响最大的那几个特征,以此来缩减建立模型时的特征数是我们非常关心的问题[1-2]。因此,本文首先利用了随机森林算法从众多的船舶参数中进行了特征选择,通过随机森林来进行特征选取的主要优点在于,可以处理特征较多的数据集,并且使用随机森林算法进行特征提取前,无需对数据进行标准化处理。
随机森林是机器学习中的一种常用方法[3],是用随机的方式生成由多个没有关系的决策树组成的森林。其中决策树是一个树结构[4],每个非叶节点表示一个根据特征属性的划分方法,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个输出结果。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,最终将叶子节点存放的类别作为决策结果。
获得森林之后,当有一个新的输入样本进入时,森林中的每一棵决策树将分别进行判断样本的所属类别(对于分类算法),被选择最多的类别即为最终的分类结果。另外,随机森林还可以进行无监督学习聚类和异常点检测。
在统计学[5]和机器学习[6]中,LASSO算法[7]是一种同时进行特征选择和正则化的回归分析方法,可以增强统计模型的预测准确性和可解释性。LASSO算法揭示了很多估计量的重要性质,例如 LASSO系数估计值和软阈值之间的联系,当协变量共线时,LASSO系数估计值不一定唯一。
LASSO算法的特点是在拟合广义线性模型的同时进行变量筛选和复杂度调整。例如,假设模型有100个系数,但其中只有10个系数是非零系数,这实际上是说“其他90个变量对预测目标值没有用处”。LASSO回归自动进行了“参数选择”,未被选中的特征变量对整体的权重为0。基于上述特点,本文采用了LASSO算法进行燃油消耗模型构建。
2 算法流程
本文应用算法流程如图1所示。
2.1 特征选择
根据两艘船舶不同数据进行特征选择,步骤如下:
(1)用N来表示训练用例(样本)的个数,M表示特征数目。
(2)输入用于确定决策树上一个节点的决策结果的特征数目m。

图1 算法应用流程图
(3)从N个训练用例(样本)中以有放回抽样的方式,取样N次,形成一个训练集,并用未抽到的用例(样本)作预测,评估其误差。
(4)对于每一个节点,随机选择m个特征,决策树上每个节点的决定都是基于这些特征确定的。根据这m个特征,计算其最佳的生成方式。
(5)每棵树都会完整成长而不会剪枝,这有可能在建完一棵正常树状模型后会被采用。
本文采用sklearn开源模块库[8]集成算法模块ensemble[9]中的随机森林算法相关的函数进行实现,此过程共需要输入3个超参数:①n_estimators:它表示建立的树的数量。一般来说,树的数量越多,性能越好,预测也越稳定,但这也会减慢计算速度。基于经验,在实践中选择数百棵树是比较好的选择,故本次分析过程取值100。②n_jobs:超参数表示引擎允许使用处理器的数量。若值为1,则只能使用一个处理器。 值为-1则表示没有限制。设置n_jobs可以加快模型计算速度,本次分析过程设置为-1。③oob_score:它是一种随机森林交叉验证方法,即是否采用袋外样本来评估模型的好坏。默认是False。本文设置为True,因为袋外分数反应了一个模型拟合后的泛化能力。
2.2 数据标准化
在进入机器学习模型前通常需要对原始数据进行中心化处理和标准化处理。在实船数据中,各变量拥有不同的量纲和量纲单位,因此在后续决策模型训练使用前,同样需要对原始数据进行标准化处理,过程如公式(1)所示。

标准化是基于原始数据的均值(μ)和标准差进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1。
2.3 模型构建
在模型构建过程中,首先利用随机森林根据参数重要性进行排序,选择重要的参数进行LASSO回归建模并确定其相关系数。最后针对不同船舶数据重复上述步骤直至获得LASSO回归函数。
3 实船验证
3.1 测试数据集信息
利用随机森林进行特征提取,最终选择出了与燃油消耗相关性排名较高的5个特征,表1为两船舶特征提取结果。

表1 特征提取结果
根据上述特征选择结果,我们提取到了如表2所示的测试数据集。

表2 测试数据
测试集数据同样需要进行数据标准化操作,需要注意的是在针对测试集进行标准化时应该与训练数据集的转化标准保持一致,如1号船舶测试集标准化过程应该按照1号船舶训练集的各变量均值及方差进行转化,1号船舶测试集速度变量标准化如式(2)所示:

式中:μtrain是训练集中变量船速S的均值;是训练集中变量船速S的方差。
经过上述标准化后,为了验证我们选择到的特征有效性,我们采用了SVM算法进行模型训练。以1号船舶数据为例,首先我们进行了如表2所示的五个特征到海里油耗的预测,进一步地,我们从众多的船舶参数,包括时间戳、对水速度、船艏向、舵角、水深、吃水、航速、风向、风速、纬度、经度、转速、主机功率、1号电机功率、2号电机功率、3号电机功率、电机进口流量、电机出口流量、滑失率当中随机抽取5个特征进行训练(为了保证海里油耗是可以计算的,其中5个特征中必然有航速数据)。重复四次随机选取特征,最后一次用随机森林选择到的五个特征进行训练,偏差采用中位数绝对误差,得到如表3所示的结果。如表中所示,第5次实验取得了最高的准确度。因此,我们能够看出随机森林选择到的特征是有效果的。

表3 特征验证
3.2 模型准确性衡量
为了增强模型的可解释性,本文尝试采用了LASSO回归进行建模。经过LASSO回归模型训练,得到的1号船舶模型如公式(3)所示,2号船舶如公式(4)所示。
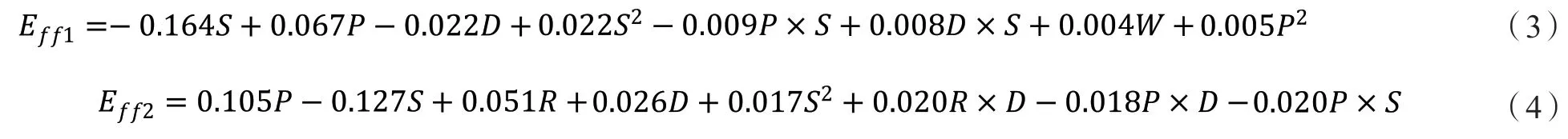
式中:S表示实际航速,P表示主机功率,R表示主机转速,D表示吃水,W表示风速,Eff表示海里油耗。
为了验证上述训练模型的准确性,评价回归模型程度优劣程度和所拟合的回归方程效果,我们一方面采用了R2来衡量模型预测值的准确性。决定系数(Coefficient of Determination)是反映模型拟合优度的重要的统计量,为回归平方和与总平方和之比[10]。R2数值大小反映了回归贡献的相对程度,其取值在0到1之间,且无单位,即在因变量Y的总变异中回归关系所能解释的百分比。另一方面,通过计算MSE(Mean Square Error)来衡量线性模型的准确性[11]。该统计参数是预测数据和原始数据对应点误差的平方和的均值,计算公式如式(5):

式中:yi是真实数据,是拟合的数据,其中n为样本的个数。
如表4所示为模型测试结果。如图2和图3所示为测试集目标参数真实值与模型预测值可视化对比,由于测试集数据较多,本次可视化过程只随机选取测试集中200个目标参数,及其对应的模型预测值进行展示,以方便观察。图2与图3分别代表了两船舶模型测试结果,蓝色虚线代表模型预测值,绿色实线代表目标参数真实值。观察图2和3所示的预测值和真实值对比结果和表4所示的R2和MSE值,可以看出模型能够较好地通过筛选到的五个特征拟合海里油耗,这验证了LASSO算法的有效性。同时,从公式(3)和(4)中,我们能够看出模型具有很好的可解释性。

表4 模型测试结果

图2 号船舶预测值与真实值对比

图3 号船舶预测值与真实值对比
4 结论
本文基于随机森林和LASSO算法构建了海里油耗模型,实验结果表明我们的方法取得了较好的效果,可以通过所筛选到的五个船舶参数较为精确地估计主机海里油耗,从而为节省船舶航行时的海里油耗提供了依据,为最终实现更加科学指导船舶运营实现降低燃油消耗和实现船舶无流量计运行打下了良好基础。
