MapReduce框架下基于线性回归的短期负荷预测
2021-03-09吴丽珍
吴丽珍, 孔 纯, 陈 伟
(兰州理工大学 电气工程与信息工程学院, 甘肃 兰州 730050)
电力系统负荷预测是从已知的电力系统数据、经济状况、气象变化、人口数量等多种情况出发,通过对历史数据的提取分析,研究事物之间的内在联系和变化规律,从而对未来负荷的变化作出预先的估计和推测[1].短期负荷预测是电力系统运行、规划、调度的基础.精准的短期负荷预测有助于电力系统规划、控制、运行,合理地安排发电厂发电机组的启停,确定电厂冷、热备用容量,有效降低发电成本,提高经济效益和社会效益[2].要实现精准的短期负荷预测需要精准的预测模型,精准的预测模型来源于海量的精准数据.随着各种配电智能终端在电力系统中的广泛应用,以及社会智能化、信息化水平不断的提高,产生了庞大且多样的电力数据和丰富的天气、温度、地理等数据,这些数据构成了短期负荷预测的数据来源[3],数据呈现“4V”特征[4],即数据量大(volume)、数据格式多样(variety)、数据处理速度快(velocity)和数据价值密度低(value).在如此海量的数据中常常存在着大量重复记录、错误记录和不完整记录的数据,这些数据将对负荷预测产生不良后果.如何从海量数据中提取有效数据,并快速处理这些数据,是大数据背景下负荷预测的关键问题[5].为了从海量数据中提取有效数据,需在计算之前对数据进行清洗.近年来,数据清洗技术获得了广泛关注.Nascimento等[6]利用近邻排序算法(sorting neighbor algorithm,SNM)对文中数据进行清理,通过分析数据集关键属性,对不同属性进行排序以检测重复数据,但其检测精度和计算成本受其观测窗口的影响.莫文雄等[7]基于随机矩阵理论对扰动数据进行检测,通过比较扰动事件观测矩阵与随机矩阵在互相关谱分布上的差异,以确定扰动源的类型及其所在区域,该方法可用于异常数据监测.
此外,有关电力负荷预测数据处理的研究也不断发展,涌现出多种电力负荷预测的理论和方法.基于历史数据确定多种变量之间关系的回归分析法[8]、研究随时间变化动态电力数据的时间序列法[9]、针对电力系统建立模糊推理系统来进行负荷预测[10]以及数据驱动的人工神经网络负荷预测[11]等.以上所述方法虽然针对某些特定情况的负荷预测十分有效,但是对于海量且复杂的大数据情况有一定的局限性,不适于现今配电网短期负荷预测.
为此,本文在MapReduce并行编程框架下,提出基于小批量随机梯度下降法算法的线性回归模型.利用大数据分析与处理技术从海量的数据中挖掘出负荷变化的规律,结合基于自适应近邻排序算法(adaptive sorting neighbor algorithm,ASNM)和K均值聚类的数据清理技术对数据进行预处理.在Hadoop大数据平台上,利用基于MapReduce并行计算框架,建立基于小批量随机梯度下降法算法的线性回归模型,并通过显著性检验方法检验该数据集在负荷预测中的显著性.最后,基于以上方法建立短期负荷预测模型,并应用在甘肃武威某区域配电网短期负荷预测系统中.实验结果表明,所提短期负荷预测模型满足负荷预测的要求,并且极大地提高了负荷计算的速度,缩短了负荷预测时间.
1 数据清理
某个传感器检测到扰动记录的数据,可能会被下游变电站电能检测装置重复记录,传感器故障会造成该节点记录数据的缺失,智能终端在非正常状态下工作则带来异常数据.重复数据、不完整数据和异常数据会对实验分析结果造成巨大影响[12].为了减少重复数据的计算,减少异常数据带来的干扰,很有必要对数据进行清理.此外,负荷预测数据类型复杂多样,数据种类繁多,有像电压、电流、功率这样的浮点型数据,还有像天气状况、居民消费水平等无法直接计算的数据[13],因此,需要对这些数据进行初始化.
1.1 基于自适应近邻排序算法的重复数据检测
自适应近邻排序算法(ASNM)是一种适用于并行计算模型MapReduce的重复数据检测算法,其步骤如图1所示.
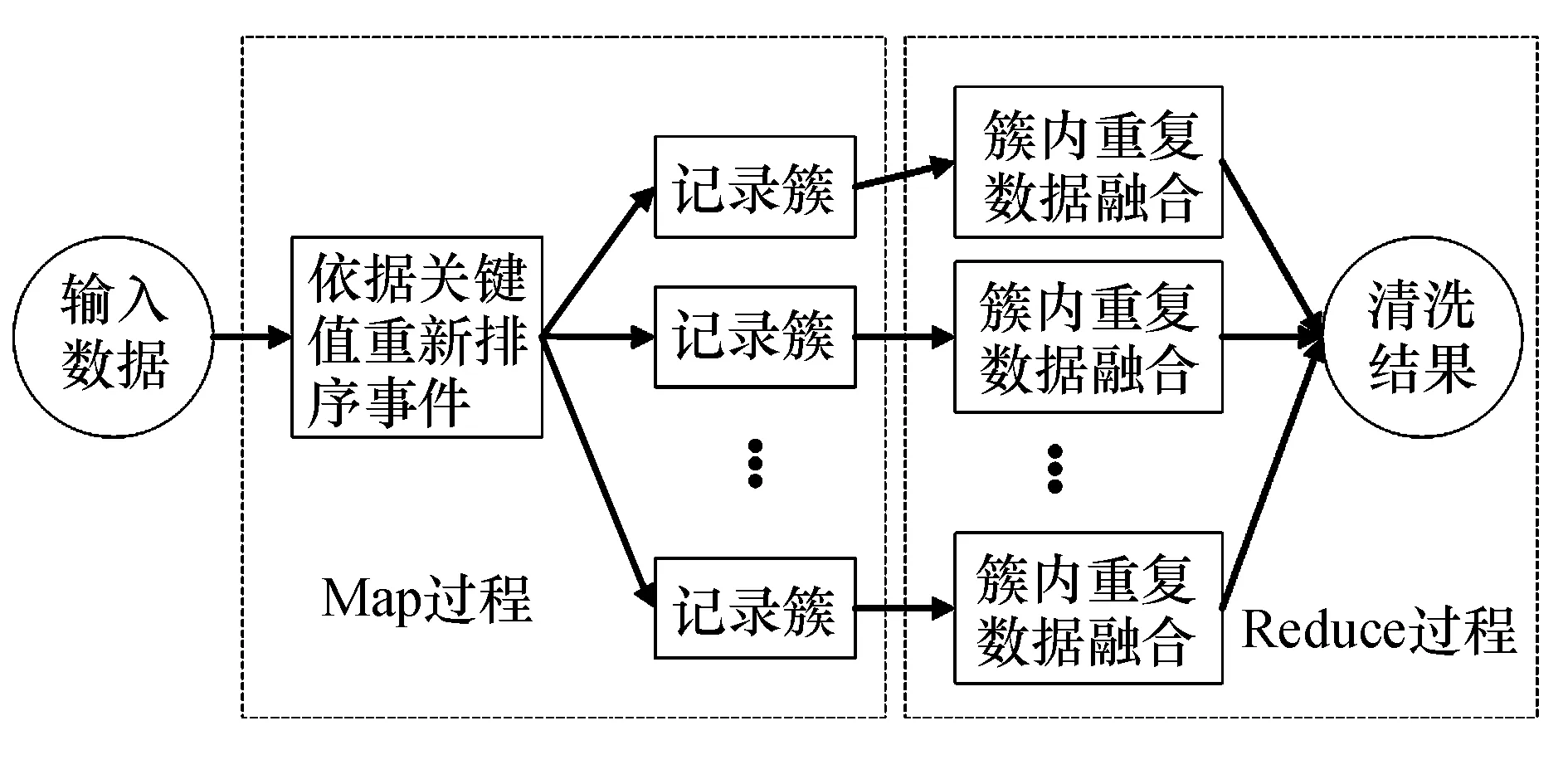
图1 ASNM算法步骤示意图Fig.1 Illustration of procedures for ASNM
从图1可以看出,该算法可分成两步实现,其步骤如下:
Step1:自适应记录簇划分.同一扰动源引起的观测数据会在极短的时间内被多个传感器检测记录,不同的扰动事件其扰动发生的时刻也不同,因此可以将扰动发生的时刻作为扰动时间的关键属性,以事件记录的时间间隔作为事件的相似距离,距离函数为
d(Ri,Rj)=|Ti-Tj|
(1)
式中:Ri和Rj分别为第i条和j条扰动记录;Ti和Tj分别为第i条和j条扰动事件的时间.当事件相似距离小于距离阈值φ时,可将这两条记录划分至同一簇.
Step2:簇内重复数据融合.在同一时间段内也可能发生不同类型或者不同空间的扰动,这些扰动不属于重复记录的数据,因此要将它们区分开来,具体判断函数为
(2)
式中:Fi和Fj分别表示事件i和事件j的类型;Wi和Wj分别表示事件i和事件j的检测子站;0表示Ri和Rj不是重复记录的数据;1表示Ri和Rj是重复记录的数据,需要进行数据清理.
1.2 异常数据和不完整数据检测
异常数据和不完整数据的特征值与有效数据的特征值有较大差异,因此能利用K均值聚类算法对有效数据、异常数据和不完整数据的特征向量进行划分.基于K均值聚类算法的数据检测方法的具体步骤如下:
Step1: 建立时空观测矩阵.智能终端依据时间序列和空间分布记录观测数据,建立时空观测矩阵:
(3)
式中:xk(n)为第k个传感器在n时段内收集的数据.
Step2: 初始化聚类中心.本文涉及到3种数据分别是有效数据、异常数据和不完整数据(将不完整数据缺失部分补0),因此需要初始化3个聚类中心c={c1,c2,c3},每一个聚类中心包含k个传感器收集数据,每个聚类中心cj所在集合记为Gj.
Step3: 将每个待聚类数据放入聚类集合中.计算带聚类数据x(n)到聚类质心的欧式距离:
(4)
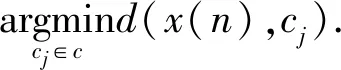
Step4: 更新聚类中心.根据每个聚类集合中包含的所有数据点,更新聚类中心使得每个数据点到新中心的几何均距最小,即
(5)
Step5: 每当有一个数据输入,就重复Step3到Step5,直至输入最后一个数据,跳出循环,完成K均值聚类.
完成聚类后,所有数据会被分成3类(有效数据、异常数据和不完整数据),可以直接将异常数据和不完整数据剔除,因为数据量足够大,且异常数据和不完整数据占总数据量比例很小,剔除这些数据不会对负荷预测的准确性造成影响.
2 基于小批量随机梯度下降算法的线性回归模型
2.1 回归分析
多元回归分析研究的目的是找出因变量Y与多个变量X=[x1,x2,…,xn]之间的定量关系,利用最小二乘法[14]找出相关因素之间的线性关系.
多元线性回归模型是计算所有影响因素与其权重之积的总和再加上一个常数偏差,其模型为
(6)
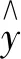
多元线性回归模型用向量表示为
(7)
式中:θT为权重因子向量,θT=[θ0,θ1,θ2,…,θn];X为变量矩阵,在此表示影响因子向量,X=[1,x1,x2,…,xn].
(8)
为找到使得损失函数最小的θ值,需对均方差MSE(θ)求导,令其导数为0:
θMSE(θ)=0
(9)
从而求得多元线性回归方程的正规方程:
(10)
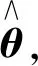
2.2 小批量随机梯度下降算法
梯度下降法是寻找最优解问题的通用优化算法[15-16].梯度下降的主要思想是通过迭代微调参数最小化损失函数.
传统的梯度下降法在于进行每一次迭代的过程都要遍历整个数据集,当数据量过大时,传统梯度下降的计算速度就变得很慢.此外,当目标函数存在多个局部最小值时,传统的梯度下降算法很容易陷入局部最小值.
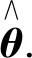

图2 小批量随机梯度下降流程图Fig.2 Flow chart of mini-batch stochastic gradient descent
小批量随机梯度下降法的求解步骤如下:
Step1: 对式(8)中每个θi分别求偏导,得到梯度向量的损失方程为
(11)
θ(n+1)=θ(n)-ηθMSE(θ(n))
(12)
其中:η为学习率,决定了每次迭代的步长.
Step3: 根据式(12)的迭代式,随机选取一小批实例数据(k个样本)进行迭代计算,并更新一次梯度和权值.
2.3 显著性检验
2.3.1F检验
在电力负荷预测的线性回归分析中,F检验的目的是检验因变量y与自变量x1,x2,…,xp之间是否存在线性关系[17].检验统计量为
(13)
对给定的显著水平α,根据第一自由度p和第二自由度(n-p-1)查表可以得到拒绝域的临界值Fα(p,n-p-1).再与计算所得到的F检验值比较,若F≤Fα(p,n-p-1),则认为y与X无显著的线性关系;若F>Fα(p,n-p-1),则y可以用x1,x2,…,xp线性拟合.
2.3.2T检验
在电力负荷预测中,不是所有的数据都与负荷有较强的线性关系,因此在负荷预测过程中要剔除那些与负荷相关性不强的数据[18].T检测法就是针对每个自变量xi检验它的总体参数θi是否显著为零,以判断该特征数据与负荷相关性的强弱.其检验统计量为
(14)
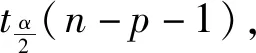
在实际负荷预测中,通常设定一个衡量显著性的阈值,一般取0.05,再将所有特征放入模型进行训练,计算每个特征的p值,p值若比选定的显著性阈值小,则选择该特征;若p值比选定的显著性阈值大,则认为该特征与负荷模型不存在强相关性,并将该特征移除利用剩下的特征进行新一轮的拟合,若还存在p值高于阈值的特征则继续移除,直到满足条件.
3 MapReduce并行计算框架
Hadoop是Apache软件基金会下的开源分布式计算平台,具有良好的通用性,适用于构建智能电网大数据平台[19].根据电力负荷数据量大、数据类型复杂多样的特点,需搭建基于Hadoop生态体系的分布式电力大数据计算分析平台.Hadoop的核心是利用分布式文件系统(hadoop distributed file system,HDFS)作为大数据的存储框架,利用分布式并行计算框架MapReduce作为数据处理框架[20].本文实验在Ubuntu 16.04系统上搭建大数据平台,Hadoop版本为2.7.1,使用Hadoop平台上的分布式计算框架MapReduce、分布式文件系统HDFS和资源调度管理框架(yet another resource negotiator,YARN)[21].
MapReduce计算原理如图3所示,先从分布式文件系统(HDFS)中取出以固定大小的块为基本单位存储数据,通过Map程序将数据切割成不相关的分片,分配给多台计算机实现分布式计算,Map任务输出的〈key,value〉键值对,再通过Shuffle过程归并键值对送给Reduce任务,最终输出另一批〈key,value〉键值对存入HDFS中.
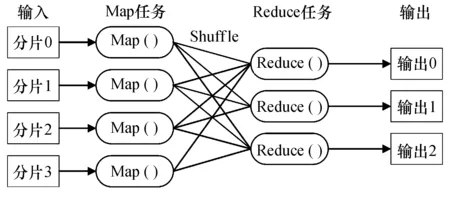
图3 MapReduce计算原理图Fig.3 Schematic diagram for MapReduce calculation
在Map过程中,将来自矩阵XT的元素xij,标识成n条〈key,value〉的形式,其中key=(i,1),value=(‘x’,j,xij);将来自(Xθ-y)矩阵的元素记为ei1,将其标识成1条〈key,value〉形式,key=(1,k),value=(‘e’,i,ei1).通过key把计算结果归为一类,通过value区分元素是来自哪个矩阵以及确定其具体位置.在Shuffle过程相同key的value会被整合到同一列表中,形成〈key,list(value)〉对,再传递给Reduce.经过Reduce阶段最终输出的是〈key,value〉,其中key=(i,j)表示输出矩阵元素的位置,value表示元素的值,这样就完成了矩阵乘法的MapReduce过程.矩阵加减和矩阵数乘的Map阶段生成的〈key,value〉键值对,key用来标识矩阵元素的位置,value则为对应元素位置的值,Shuffle过程将具有相同key的value整合到同一列表,最后通过Reduce过程将相同位置元素进行加减或数乘.
4 算例分析
4.1 负荷预测评价指标
本文采用的评价指标有绝对误差、相对误差、平均绝对百分误差和均方根误差.
(1) 绝对误差(absolute error,AE)是负荷实际值与预测值之差:

(15)
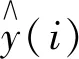
(2) 相对误差(relative error,RE)是绝对误差与实际值之比:
(16)
(3) 平均绝对百分误差(mean absolute percentage error,MAPE)能准确地反映预测误差的大小:
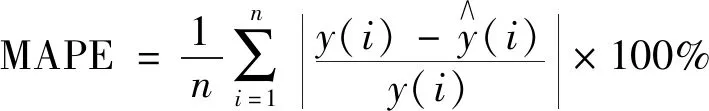
(17)
(4) 均方根误差(root mean square error,RMSE)是预测值与观测值之差的样本标准差:
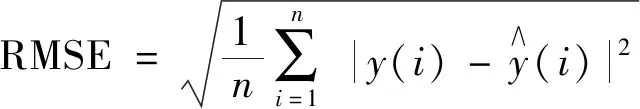
(18)
4.2 实验结果分析
实验采用甘肃省武威市某配电网的实际运行数据作为算例.首先对负荷预测数据进行重复数据检测实验,然后对数据进行异常数据和不完整数据的清理,再组成负荷预测数据集.负荷预测数据集包含1 480条记录作为训练集,用于建立负荷预测模型,另外1 186条数据作为测试集,用于验证负荷预测模型的准确性.训练集和测试集中每条记录都包含8条属性,将每条数据信息都存入影响因子矩阵Xi(x1,x2,x3,x4,x5,x6,x7),x1表示系统相电压,x2表示相电压畸变率,x3表示系统相电流,x4表示相电流畸变率,x5表示负载相电流,x6表示补偿电流,x7表示功率因数;Yi=y,y表示负荷功率.
4.2.1数据清洗实验结果分析
利用自适应近邻排序(ASNM)算法对甘肃省武威市某配电网2018-08-01到2018-08-21的电力数据进行重复数据检测.图4为重复数据检测的实验结果.实验结果表明,自适应近邻排序算法能有效地检验出重复数据,且该数据集的重复数据占总体数据的4.7%~24.7%.
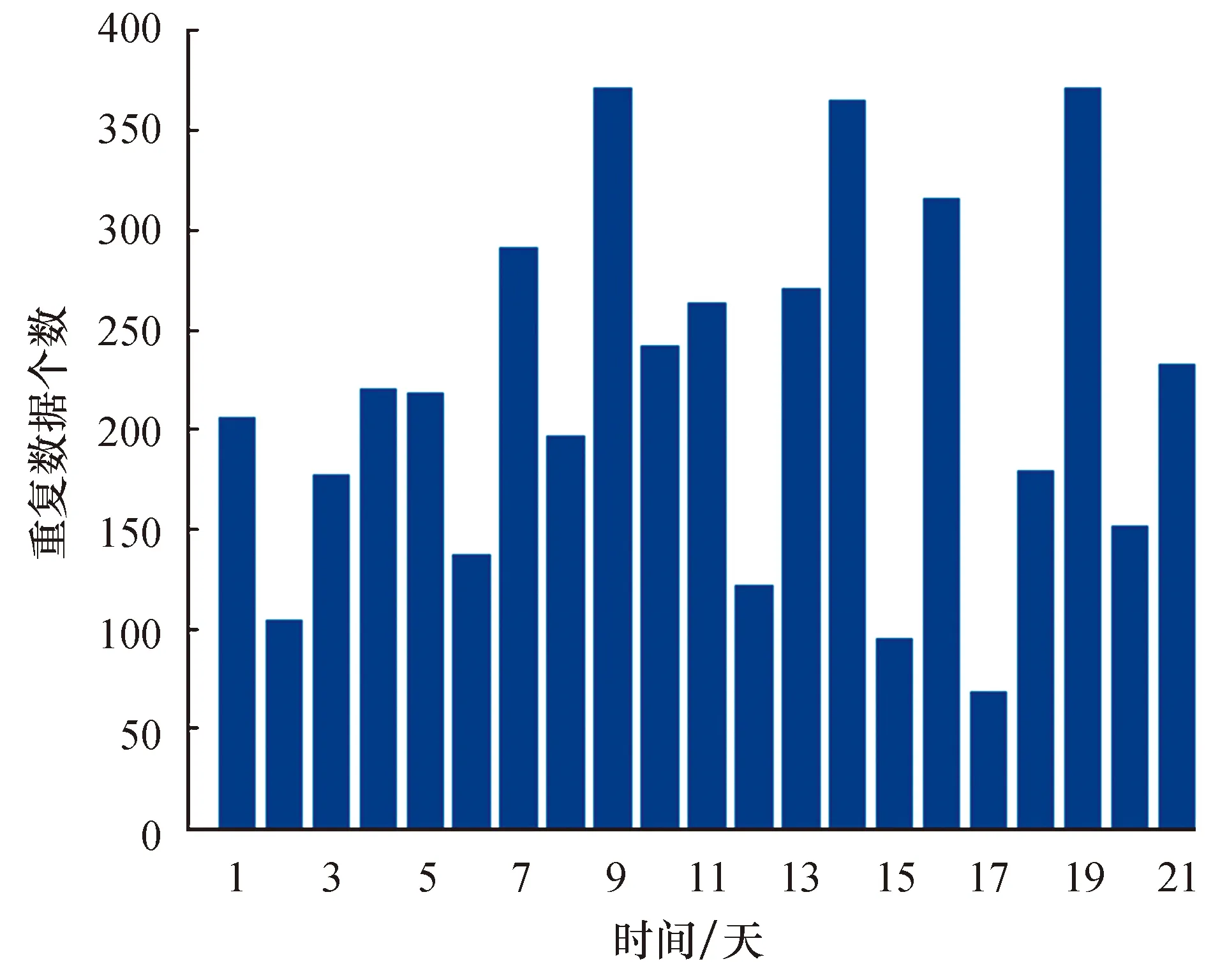
图4 重复数据检验实验结果Fig.4 Tested results of repeated data verification
利用K均值算法对完成重复数据检测后的数据进行处理,以分离出异常数据和不完整数据.图5为K均值算法聚类结果.实验结果表明,K均值聚类算法能有效地从数据集中分离出异常数据和不完整数据.

图5 利用K均值聚类分离数据Fig.5 Separating data by K-means clustering
4.2.2负荷预测结果分析
基于MapReduce分布式并行计算框架的小批量随机梯度下降算法和传统梯度下降算法的运算速度对比结果如图6所示.
从图6可以看出,基于MapReduce分布式并行计算框架的小批量随机梯度下降算法相对于传统梯度下降算法,在数据量小于40 MB时计算速度甚至不如传统梯度下降算法.其原因是:当数据量较小时,如果训练数据样本量小于其分批处理阈值k,小批量随机梯度下降法就变成了传统的梯度下降法,且并行计算各个主机之间的通信和数据交换需要消耗带宽,这样反而降低了运算速度.但当数据量较大时,并行小批量随机梯度下降算法所消耗的运算时间远小于传统算法,且这种差距会随着数据量的增大变得越发明显.

图6 并行小批量随机梯度和传统梯度下降算法运行时间对比Fig.6 Comparison of running time between parallel mini-batch SGD algorithm and traditional gradient descent algorithm
将完成数据清洗工作负荷的数据存入分布式文件系统(HDFS),利用分布式并行框架MapReduce对小批量随机梯度下降算法并行化处理,完成计算,得出负荷预测模型(表1).
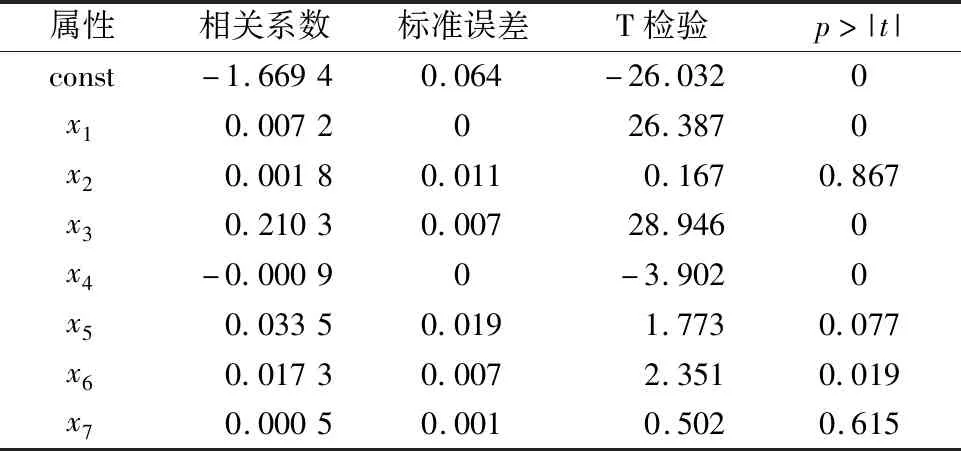
表1 负荷预测模型分析Tab.1 Model analysis of load forecasting
表1中相关系数为每一个变量对应的权重因子θi,常采用标准误差来衡量相关系数的可靠性.标准误差计算公式为
(19)
式中:X代表变量矩阵;diag()为求取方阵对角线元素函数.根据式(19)求取的标准误差如表1 所列,可知在该数据集下利用小批量随机梯度下降算法获得相关系数的标准误差较小,利用该方法获得的相关系数可靠性较高.再借助T检验来确定自变量显著性,设定显著性阈值为0.05,计算每个特征的p值,根据负荷预测结果,p>|t|的有x2、x5、x7,说明负荷预测的结果与相电压畸变率x2(%)、负载相电流x5(A)和功率因数x7没有显著的线性关系,因此需要将这3个特征从训练模型中删去,重新进行拟合.重新拟合的结果如表2所列.
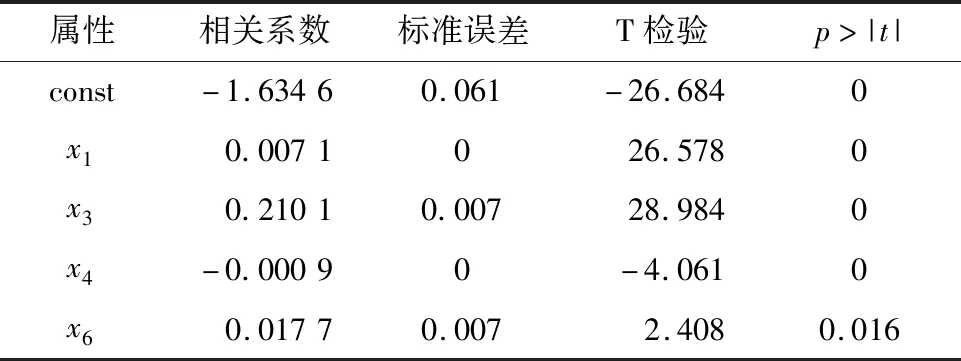
表2 剔除无关特征后的负荷预测模型分析Tab.2 Model analysis load forecasting after eliminating irrelevant features
重新拟合后,通过T检验,所有特征均具有显著性.再通过F检验验证该数据能否线性表征负荷模型,计算获得F检验的值为135 826,远大于表3所查的极限值,所以负荷预测模型在该特征数据下存在显著的线性关系.最终,得到负荷预测的模型为
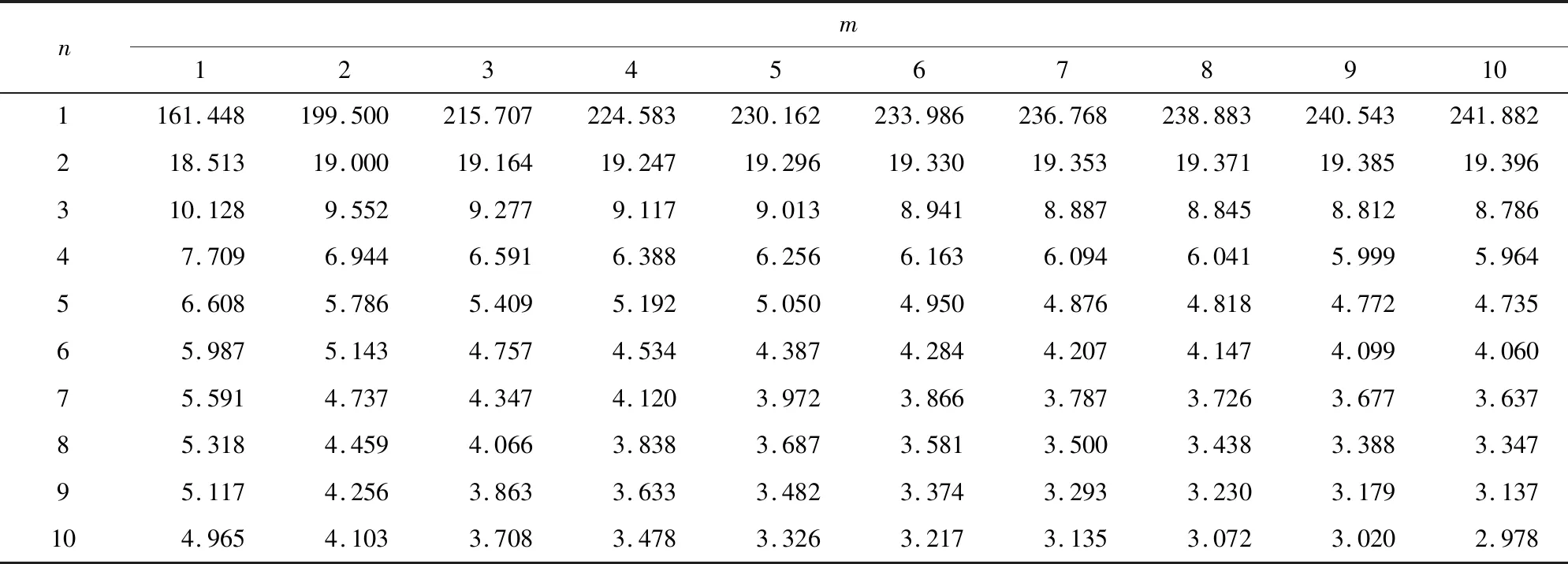
表3 F检验临界值(α=0.05)Tab.3 F test threshold (α=0.05)
y=-1.634 6+0.007 1x1+
0.210 1x3-0.000 9x4+
0.017 7x6
(20)
根据1 186条测试数据集,利用式(20)预测模型获得的负荷曲线与实际运行的负荷曲线进行对比,结果如图7所示.
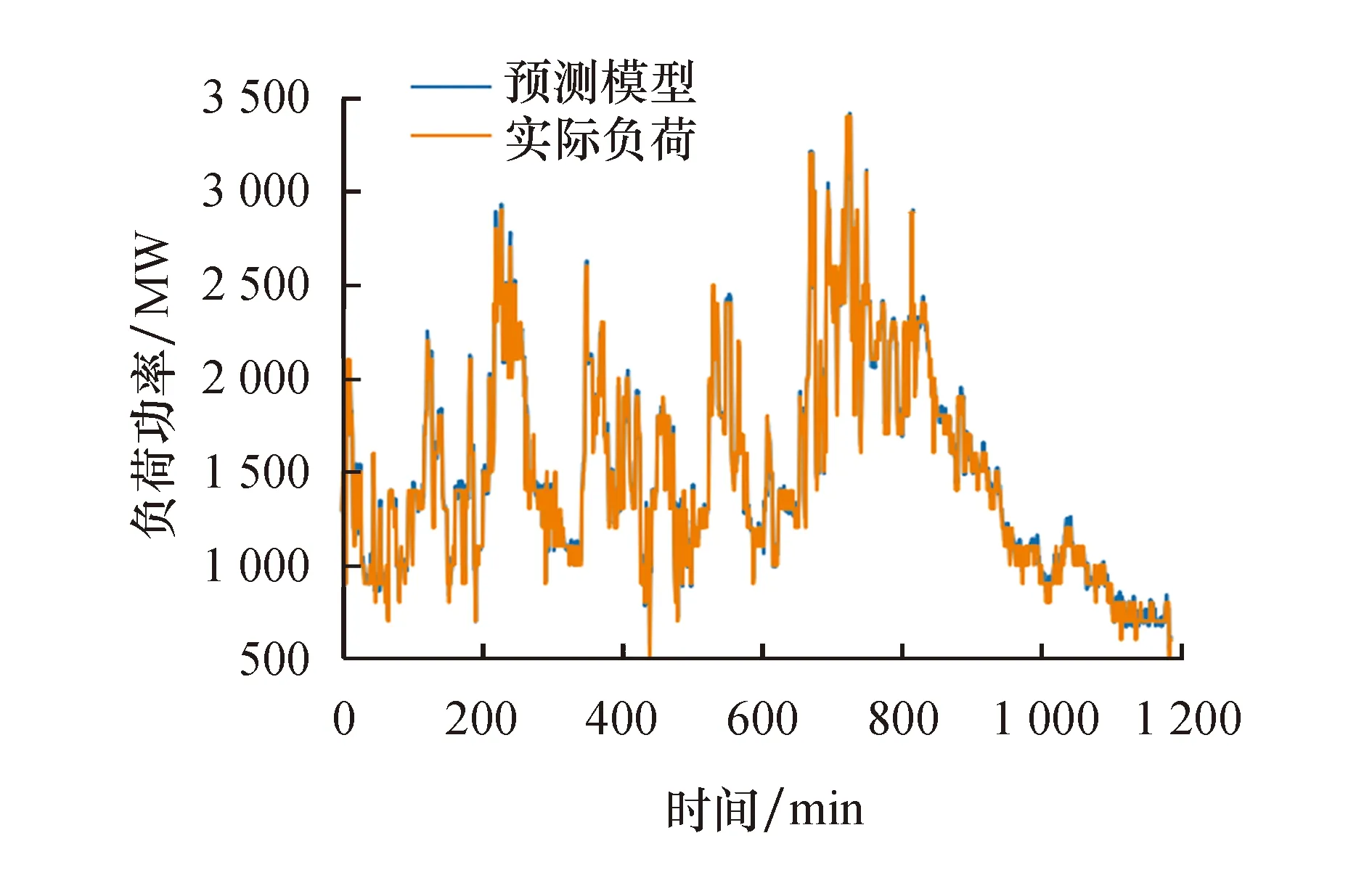
图7 模型预测的运行负荷与实际运行负荷对比曲线Fig.7 Comparison curve between the load predicted by the model and the actual operating load
从图7可以看出,预测模型得出的负荷预测曲线与电力系统实际运行负荷曲线拟合较好,预测结果与实际值偏差较小.
为了更清楚地展示每个预测点相对于实际误差的大小,对1 186条测试数据逐点绘制的绝对百分误差曲线如图8所示.该负荷预测模型的最大相对误差为8.246%,平均绝对百分误差(MAPE)为2.043%,均方根误差(RMSE)为3 112.62,该模型预测能准确捕捉负荷变化规律,快速预测负荷变化趋势,负荷预测结果精准.
5 结论
本文针对大数据背景下负荷预测计算速度慢和预测不精确的问题,提出了在大数据平台上利用小批量随机梯度下降法建立负荷预测回归模型,并在计算之前对数据进行数据预处理和数据清洗工作.实验结果表明,采用所提的自适应近邻排序算法能够有效地检测出重复数据;采用所提的K均值聚类方法能够有效地剔除异常数据和记录不完整数据.采用所提的基于大数据平台和MapReduce并行编程框架的小批量随机梯度下降算法建立的短期负荷预测模型进行实际配电网负荷预测,其平均绝对百分误差(MAPE)为2.043%,均方根误差(RMSE)为3 112.62,表明该方法能快速、高效地处理大批数据,建立精确的短期负荷预测模型.
