基于面部特征分析的疲劳驾驶检测方法
2021-03-07胡习之黄冰瑜
胡习之, 黄冰瑜
(华南理工大学机械与汽车工程学院, 广州 510641)
疲劳驾驶是交通事故的主要诱因之一,美国国家高速交通安全管理局统计表明,17%~21%的交通事故与驾驶人员的精神状态有关[1]。疲劳驾驶问题的根本诱因为驾驶员安全意识薄弱、休息时间不规律、连续高强度集中作业等,仅在规章制度上约束难以根绝此类事故。因此,除了加强驾驶作业管理、合理安排长途运输,提升相关智能驾驶辅助预警系统的性能是一项重要途径。针对疲劳驾驶检测的相关研究中,主要有主观检测和客观检测两种办法。客观检测指对驾驶员行驶过程中的生理和心理相关特异性指标进行检测,如行车数据、生理状态、视觉特征。行车数据极易受驾驶员个人行为习惯、技术水平、车型及道路状况影响[2-3],主要作为判定辅助。基于生理信号的疲劳检测技术通过穿戴设备采集驾驶员的脑电、心电等生理信号,进行清醒及疲劳特征差异分析[4]。生理信号采集需要驾驶员穿戴设备,属于侵入性检测,成本也相对高,不利于实际应用推广。基于视觉特征的疲劳驾驶检测方法依据视频采集设备获得驾驶员实时驾驶图像,对图像进行后期处理,可获得驾驶员面部、头部、手部等的特征参数,判断疲劳状态[5-6]。与前两种技术手段相比,该方法对硬件设备要求低、可移植性强,算法优化空间大,是疲劳检测领域的主流检测方法。
常用的面部疲劳特征检测方法可分为基于机器学习的检测算法和基于深度学习的检测算法。基于机器学习的算法采用滑动窗口的检测策略,利用灰度积分法、哈尔特征等提取视觉特征,通过支持向量机(support vector machine,SVM)、自适应增强算法(adaptive boosting,AdaBoost)等分类器识别眼睛闭合度、哈欠动作等疲劳特征[7]。该方法原理简单直观,易于设计及优化,但人工设计特征的鲁棒性不足,检测精度易受光线变化、遮挡缺失等环境因素影响。基于深度学习的检测算法利用卷积神经网络提取隐式特征,对疲劳动作的判别精度大大提高,但复杂的模型结构影响检测速度,在实时检测中的应用受到阻碍。
针对实时疲劳驾驶检测的特点,结合深度学习模型及机器学习模型设计一套基于面部特征分析的驾驶员疲劳检测系统。在人脸检测环节,对SSD(single shot multi box detector)目标检测模型进行优化,后续使用目标跟踪算法进行驾驶员人脸区域定位,以平衡人脸定位的精度及效率。在人脸定位的基础上,使用级联回归树模型提取面部特征点,以特征点相对位置的变化作为疲劳检测依据。计算并使用眼部闭合百分比、最大闭眼时长、眨眼频率及哈欠次数作为疲劳特征参数,建立多指标融合模型以提高系统准确率及鲁棒性。
1 基于改进SSD的人脸检测算法
1.1 SSD模型结构
SSD是一种端对端的基于回归的One-stage目标检测算法[8],具有检测速度快、检测精度高的优点。SSD可针对不同尺度的目标,使用卷积神经网络直接预测物体位置、判定所属类别、计算置信度。最后利用非极大值抑制(non maximum suppression,NMS)算法综合多层特征图的信息给出检测结果。SSD模型基本框架如图1所示。

图2 基于ResNet50的SSD网络结构Fig.2 SSD network structure based on ResNet50
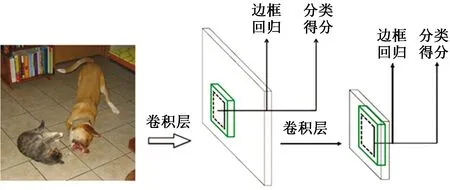
图1 SSD模型基本框架Fig.1 Basic structure of SSD
1.2 改进SSD模型结构
SSD采用VGG-16(visual geometry group-16)[9]作为基础模型,该网络结构简单,由若干卷积层堆叠成较深的网络。由于结构限制,若进一步加深网络将面临梯度消失问题,因此使用ResNet-50(residual network-50)[10]作为主干网络。
ResNet-50的特点是引进了残差模块,释放了深层网络的优化潜力。具体做法为,在部分网络的输入输出之间添加一个恒等映射的快捷连接,即在原输出上做加和,加和部分为原始输入。其计算公式为
H(x)=F(x)+x
(1)
式(1)中:x为残差模块的输入;F(x)为残差;H(x)为经过第一层线性变化并激活后的输出。
更换主干网络后的SSD模型结构如图2所示。
1.3 分类损失函数替换
在目标检测算法中,不处在Ground Truth和背景过渡区域的先验框称为易分样本,具有较大损失值、对网络收敛具有重要作用的先验框称为难分样本。为避免大量驾驶室的背景样本抑制少数难分样本,引入Focal Loss[11]代替原分类损失函数Softmax Loss。
二分类任务的FL(Focal Loss)公式为
FL(pt)=-αt(1-pt)γIn(pt)
(2)
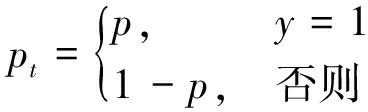
(3)
式(2)中:pt表示模型预测的当前样本属于true class的概率;p表示模型预测的当前样本属于其中一个类别的概率;y为类别标签;αt为平衡因子,0<αt<1;γ为权重因子,0<γ<5。
对于二分类任务,αt=0.25,γ=2时有最佳检测效果。可知,pt越大,(1 -pt)γ权重就越小,从而使模型更关注困难、易错样本。
1.4 模型训练及评估
为训练并验证模型性能,采集驾驶员人脸图像以构建实验样本集。通过安装在静止车辆前方的摄像头,拍摄驾驶位上的人员的面部视频。视频拍摄期间,驾驶员会模拟看左右后视镜、车内后视镜、仪表盘等一系列驾驶行为。提取视频中的图像并进行手动标注,形成包含5 000张样本的人脸数据集,标注样本如图3所示。
共设置120轮迭代,并采用自适应学习率衰减、数据增强、过拟合早停等技巧。模型训练环境配置如表1所示。
在自建的人脸数据集上验证改进前后的模型性能。通常用平均正确率(average precision,AP)反映检测精度,用画面每秒传输帧数(frames per second,FPS)反映图像处理速度。实验数据如表2所示。

图3 标注图像示例Fig.3 Annotation samples

表1 训练环境配置
实验表明,改进SSD算法的检测精度显著提升,比原SSD算法提高7.0%的平均正确率。同时,由于卷积层加深,模型检测速度有一定下降。为提高人脸定位效率,引入CamShift(continuously adaptive MeanShift)跟踪算法及卡曼滤波机制。

表2 改进前后模型性能
2 基于改进CamShift的跟踪算法
2.1 改进CamShift的基本原理
将CamShift跟踪算法[12]与卡尔曼滤波算法[13]相结合,提出一种跟踪预测算法。
CamShift是由MeanShift算法改进得到的自适应均值漂移算法[10],其原理为使用MeanShift算法在颜色概率密度分布图进行迭代运算,找出目标在当前帧的位置。设I(x,y)为像素点(x,y)在颜色概率密度分布图中对应的概率估计值,定义概率密度分布的零阶矩M00和一阶矩M10、M01分别为
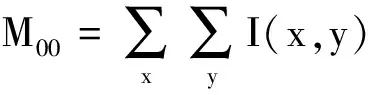
(4)
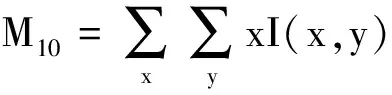
(5)
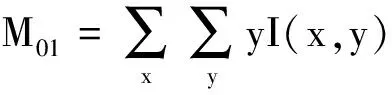
(6)
运动目标的质心坐标为
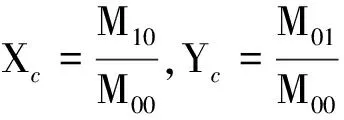
(7)
依据零阶矩反映的长宽度调整窗口大小,依据求得的质心坐标调整搜索框的中心到质心位置。
由于CamShift算法对颜色空间敏感度高,易受相近颜色或光线变化干扰,因此增加卡尔曼滤波预测机制。
卡尔曼滤波状态方程为
Xt=AXt-1+Wt-1
(8)
式(8)中:Xt和Xt-1分别为t时刻和t-1时刻的状态向量;Wt-1表示过程噪声。
观测方程:
Zt=HXt+Vt
(9)
式(9)中:Zt表示t时刻的观测向量;A为相应的状态转移矩阵;H为观测矩阵;Vt表示测量噪声。
Kalman滤波利用观测数值对状态变量的预测估计进行修正,得到状态值的最优估计。算法融合的具体策略如图4所示。
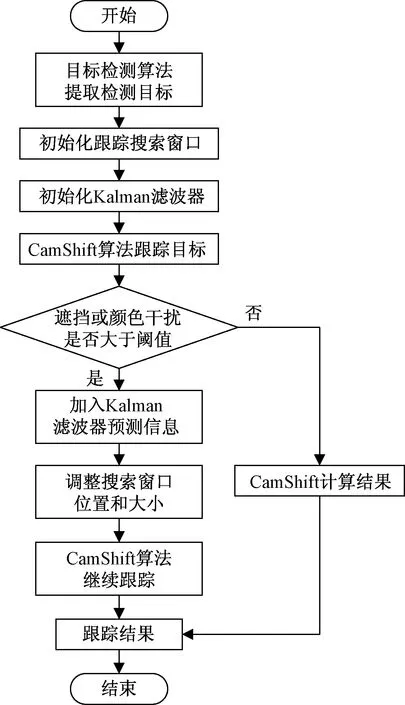
图4 改进CamShift跟踪预测算法流程图Fig.4 Flow chart of improved CamShift algorithm
改进CamShift跟踪预测算法的具体策略为:将初始化人脸区域输入CamShift进行跟踪,并实时判断判断是否出现颜色干扰或者严重遮挡,若有大面积的颜色干扰或遮挡,则用卡尔曼滤波器的预测值作为当前帧的质心位置,并自动更新作为下一帧CamShift跟踪算法计算的质心位置。
采用巴氏距离来度量跟踪区域的相似性。巴氏距离计算两个统计样本的重叠量,以衡量两组样本的相关性[14],其定义为

(10)
式(10)中:pu(f)为测量对象样本;qu为参考样本;m为样本分区数目;u为当前样本分区;ρ[pu(f),qu]越大,表示所构造模型间相似性越高,取值最大的即为匹配度最高的候选目标模型。
2.2 跟踪效果实验
使用改进CamShift算法进行不同情况下的运动目标跟踪。
2.2.1 一般情况
如图5所示,蓝色框为CamShift算法计算结果,绿色圆圈为卡尔曼滤波器预测结果。运动目标在视频范围内移动并发生尺度变化,算法都能很好地完成预期目标物体跟踪任务。
2.2.2 颜色干扰
颜色干扰实验过程如图6所示。颜色干扰靠近目标,算法借助Kalman滤波器预测结果的校正作用,仍能稳定跟踪目标。当颜色干扰离开目标,搜索框仍保持跟踪目标不变,并未发生偏离现象。
2.2.3 遮挡干扰
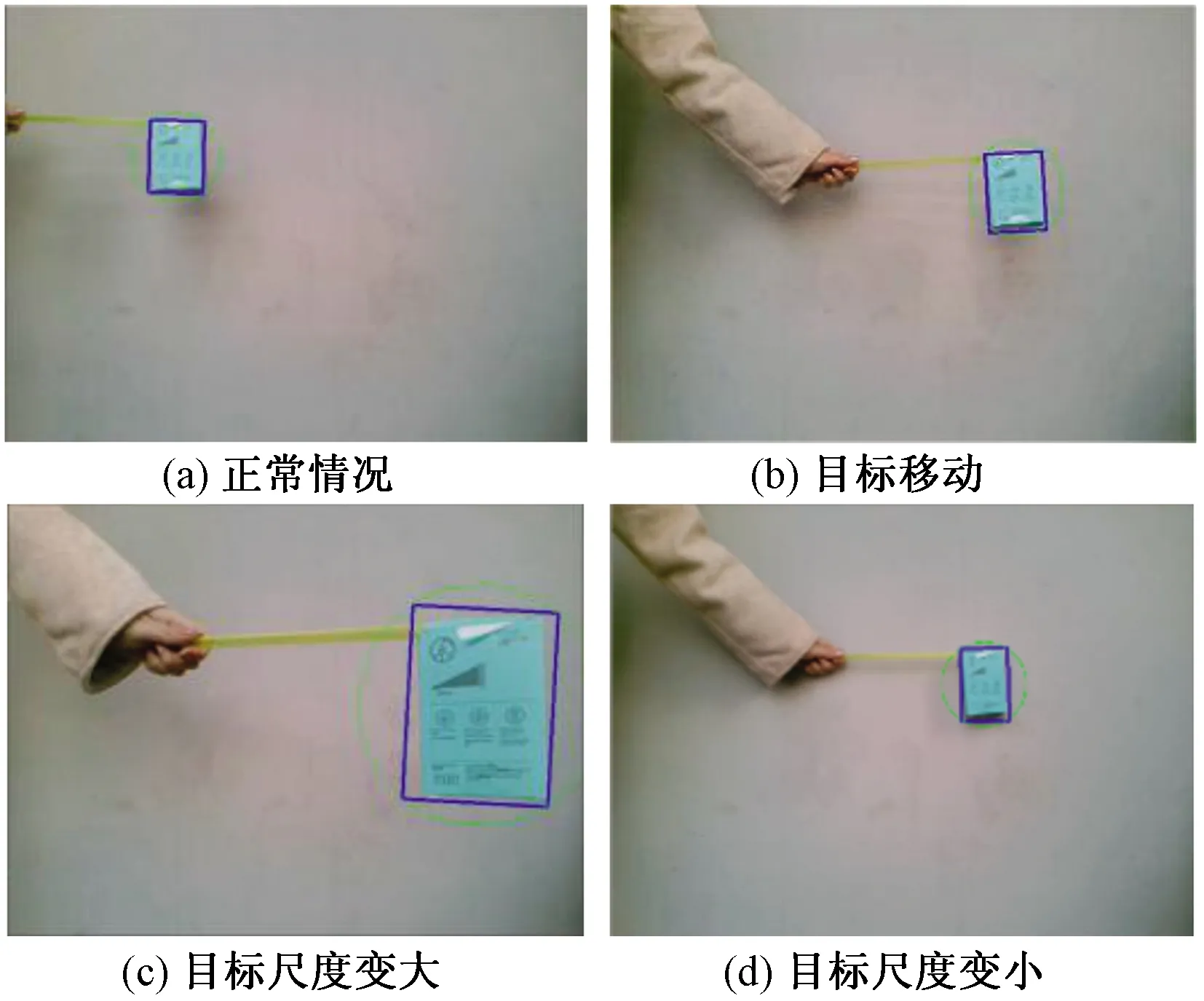
图5 一般情况跟踪效果Fig.5 Tracking effects of general condition
遮挡干扰下的实验结果如图7所示。遮挡物进入视频区域后逐渐对目标产生遮挡作用。大范围遮挡时,仍可勾选画面中少部分的目标物体。当目标在视频中消失,搜索框失去跟踪目标,但当遮挡消失,目标重新出现时,算法重新跟踪目标。
由实验可知,增加了卡尔曼滤波机制的改进CamShift跟踪算法的鲁棒性显著提高,能防止颜色及遮挡干扰带来的目标误判或丢失。
2.3 算法融合
融合基于改进SSD的人脸检测算法和改进的CamShift算法,使面部区域定位更加准确、高效。融合算法流程如图8所示,系统包含两个主要的判定环节。
(1)是否存在初始搜索窗口。当判定不存在初始搜索窗口时,系统启动人脸检测算法。判定存在初始搜索窗口时,系统使用跟踪算法进行预测跟踪。在进行跟踪时,判断人脸区域是否超出形态约束阈值,如果超过,即返回人脸检测算法,重新检测人脸;否则,将跟踪到的人脸作为目标人脸输入给下一帧图像,进行后续检测。
(2)是否检测到人脸。启动人脸检测算法检测人脸时,如果成功检测到人脸,即设置检测结果为目标人脸。否则,代表视频中不存在有效人脸信息,返回原视频重新检测。
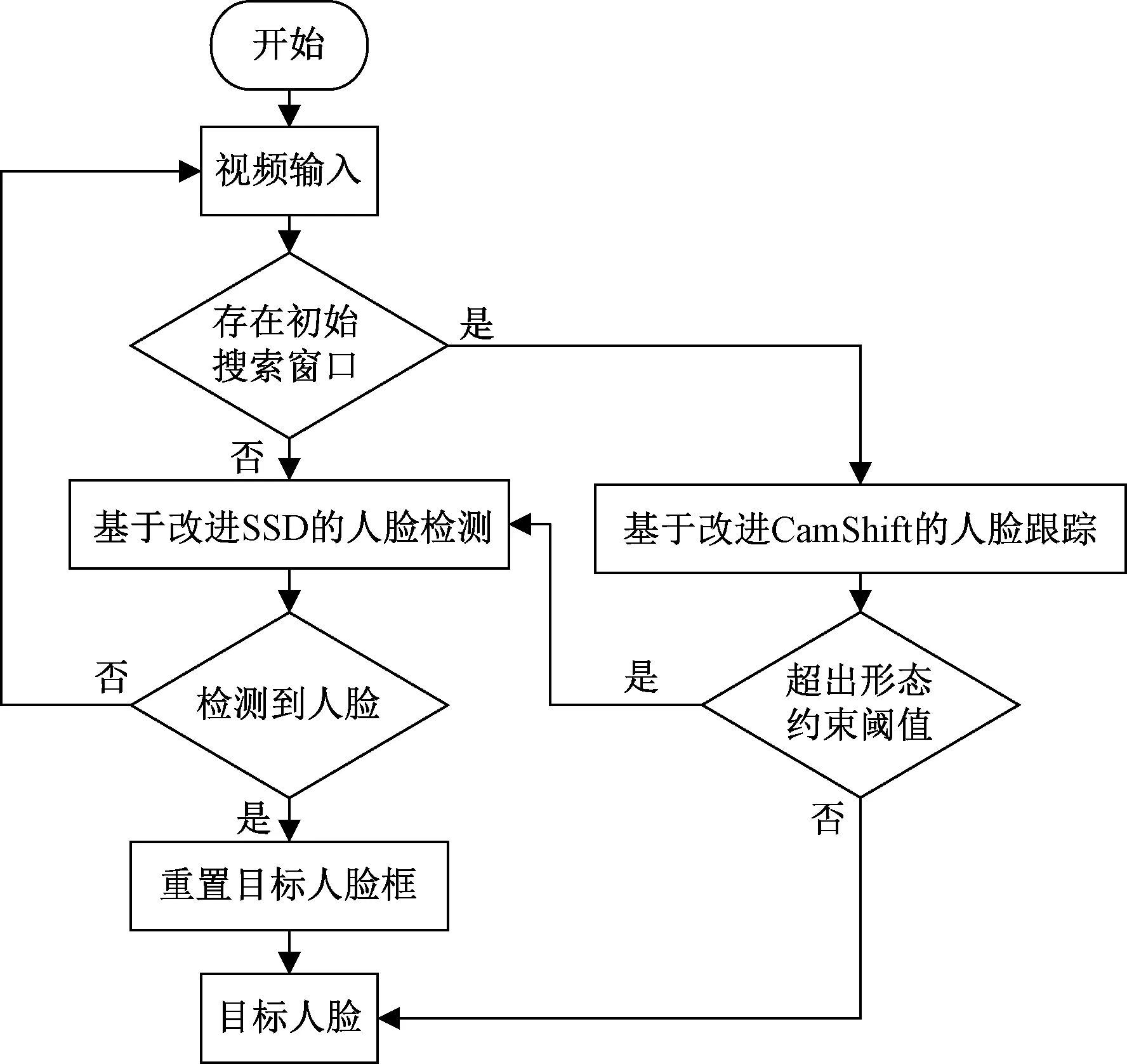
图8 人脸检测系统流程图Fig.8 Flow chart of face detection system

表3 算法检测速度对比
表3为算法检测速度对比实验结果。从对比结果(表3)可知,改进SSD算法融合改进CamShift跟踪预测算法之后,不仅保证了更好地检测效果的同时,也大幅降低了检测时间,提高了实时性。
3 驾驶员疲劳特征建模
在基于面部特征的驾驶员疲劳研究中,眼部及嘴部特征具有易提取、变化明显等优点。因此选取人脸眼睛特征和嘴巴特征,提取相关参数进行驾驶员疲劳状态的研判。
3.1 实车数据采集
在实际道路驾驶环境下,采集驾驶员在驾驶过程中的面部图像数据,以分析提取的特征并测试模型的有效性。
共10名具有不同驾驶年龄的驾驶员参与了实际道路试验,分布不同的年龄段,男性8名,女性2名。在实验过程中,要求驾驶员尽量减少换道操作,如遇阻挡则以跟车为主,在驾驶过程中尽量避免交谈,禁止开车内音乐和广播。所选取的路线均为一般城市道路,要求驾驶员保持车速在50~80 km/h,一般不超出该范围行驶。
在获取视频样本后,结合驾驶员事后描述和评价小组的综合评价结果来标注样本的疲劳状态。具体的评判规则实施步骤为:将驾驶员面部视频进行分割,形成系列时长为30秒的视频片段(样本),根据驾驶员面部表情特征对每个样本中驾驶员的疲劳状态进行评价。评价时将驾驶员的状态分为清醒(0分)、疲劳(1分)与严重疲劳(2分)三级。样本情况如表4所示。

表4 实验样本集情况
3.2 特征点定位
采取一种基于回归树的人脸对齐算法[15],基于特征点定位完成面部疲劳特征的提取。
级联回归树模型的预测原理为
S(k)=S(k-1)+sk(I,S(k))
(11)
式(11)中:S(k)、S(k-1)分别表示当前级及上一级的回归器预测结果;k表示级联序号;sk表示当前级的回归器,回归器的输入参数为预测图像I和上一级回归器的更新值。
级联回归器的预测过程如下:加法模型中的第一棵决策树利用得到的最优参数,挑选图像中的随机像素点对进行阈值对比,判断分裂方向,将图像划分到某个叶结点中,使用叶结点的平均残差,即位置偏移量更新初始形状向量,再将结果输出给下一棵树。每一级回归器都经过M′次更新,并输出位置偏移量。对结果进行级联回归更新,得到最终的预测形状。在实际检测中,对视频图像帧进行灰度化、去噪等预处理,输入级联回归树模型获得特征点序列如图9所示。

图9 人脸特征点定位Fig.9 Face feature point location
3.3 面部疲劳特征参数
3.3.1 眼睛闭合时间百分比
眼睛闭合时间百分比(percentage of eyelid closure,PERCLOS),指在单位时间内眼睛闭合程度超过某一阈值的时间所占百分比[16]。研究采用P80标准,图10为PERCLOS的基本原理。
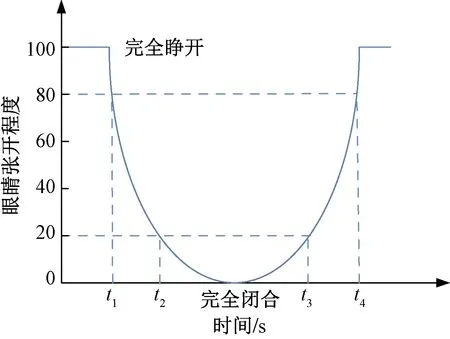
图10 基于PERCLOS P80的测量标准Fig.10 Criterion of PERCLOS P80
为了提高准确性和简化计算,使用视频帧数代替时间,即采用单位时间内闭眼的视频帧数占视频总帧数的百分比来代替眼睛闭合时间所占总时长的百分比。
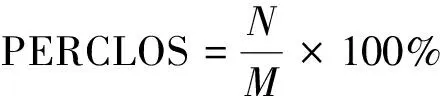
(12)
式(12)中:N表示单位时间内闭眼的视频帧数;M表示单位时间的视频总帧数。
3.3.2 闭眼持续时间最大值
闭眼持续时间最大值(maximum duration of eye closure,MDEC)指在特定时间内眼睛闭合状态持续时间的最大值,其表达式为[17]
MDEC=max{Z1,Z2,…,ZN}
(13)
式(13)中:Z1,Z2, …,ZN表示某时间段内的眼睛闭合持续时间记录值。
在疲劳状态下,眼部睁闭时间随着疲劳程度的加深会大幅延长。因此,可通过统计正常清醒状态下,驾驶员正常闭眼持续时间最大值作为阈值,当检测到一段时间内驾驶员闭眼持续时间最大值大于该阈值时可判定为疲劳状态,否则为清醒状况。
3.3.3 眨眼频率
眨眼频率(blink frequency,BF)是指在1 min内的眨眼次数。通过眼睛的纵横比(eye aspect radio,EAR)来衡量其张开的程度,并考察其持续的时间,可以对眨眼频率进行直观准确的判断。
眼部特征点如图11所示。将眼部纵横比应用在疲劳参数建立中,其计算公式为

(14)
式(14)中:p1、p2、p3、p4、p5、p6为眼部特征点的坐标。
疲劳时人的眨眼频率会明显减少,可将清醒状态下最慢的眨眼频率统计数据确定为状态判定的阈值,当检测出驾驶员眨眼频率小于该阈值时,认定驾驶员处于疲劳之中,否则,为清醒状态。
3.3.4 嘴部纵横比
通过嘴巴的纵横比来衡量其张开的程度,并考察其持续的时间(一般打哈欠会持续4 s以上)来判断其是否打哈欠。嘴部特征点如图12所示。嘴部纵横比(mouth aspect ratio,MAR)的定义为

图11 眼部特征点模型Fig.11 Model of eye points
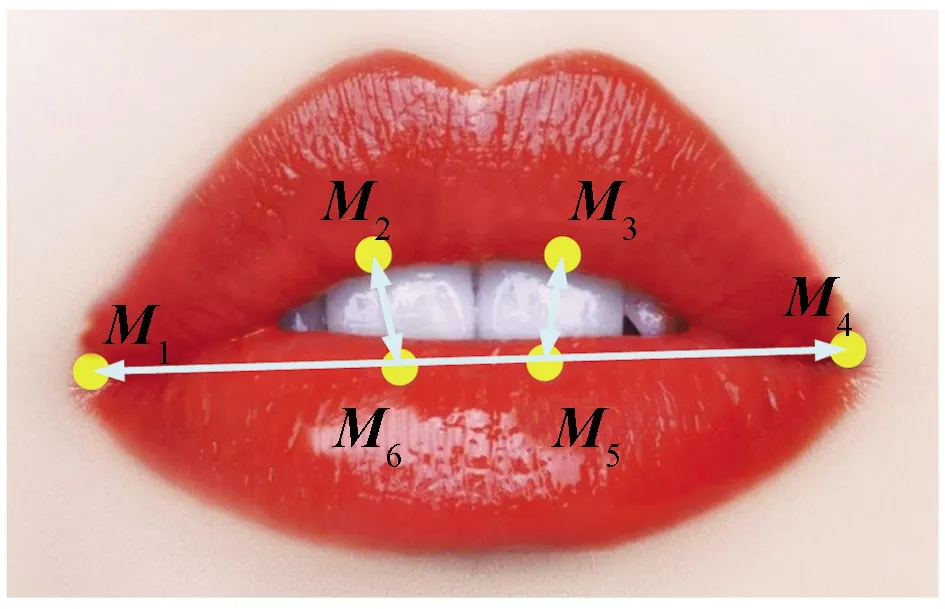
图12 嘴部特征点模型Fig.12 Model of mouth points

(15)
式(15)中:M1、M2、M3、M4、M5、M6为唇部特征点的坐标。
若MAR超过了正常状态下的最大阈值,则认为有打哈欠行为。
3.4 疲劳判定流程
针对眼睛状态参数选取PERCLOS参数阈值为0.12,大于此阈值时表明驾驶员出现疲劳;选取MDEC>0.8 s时,表明驾驶员出现疲劳;选取眨眼频率阈值为15~20次/min,如果未达到该范围,则认为驾驶员处于疲劳状态。针对是否打哈欠,选取MAR阈值为0.8,超过即表明驾驶员出现打哈欠。
图13为疲劳驾驶整体检测流程。若眼部及嘴部疲劳特征参数不一致,有两种策略。①当系统检测到眼睛的参数有两项或两项以上超出阈值时,嘴部未出现打哈欠,则以眼睛状态参数为主要指标,判定为疲劳状态;②当检测到嘴部出现打哈欠时,若眼睛状态参数正常,则以嘴部疲劳状态为主,判定为疲劳状态。
由于重度疲劳时驾驶员的面部表情僵滞,头部姿态变换迟缓,肢体动作缓慢或短时无任何动作,因此,以眼睛状态参数为主要指标进行判断。设定有两项或两项以上眼部状态参数超出疲劳状态阈值的25%时,系统将判定为重度疲劳状态。
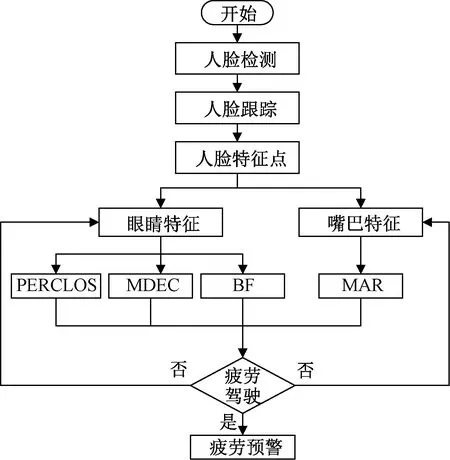
图13 疲劳驾驶整体检测流程Fig.13 Flow chart of fatigue driving detection
4 疲劳判定实验与分析
4.1 典型样本参数分析
利用获取的实车数据进行实验验证与分析。图14为来自同一驾驶员的3个典型样本。图14中,样本1、样本2、样本3分别标定为清醒样本、疲劳样本、重度疲劳样本。利用所设计疲劳检测系统进行分析,分析结果如表5~表7所示。
图15中,样本1为清醒状态,样本2为中度疲劳状态,样本3为重度疲劳状态。实验结果(图15)与样本标定结果一致。

图14 疲劳检测样本Fig.14 Samples of fatigue detection

表5 样本PERCLOS分析结果

表6 MDEC分析结果

表7 样本BF分析结果
4.2 样本集检测效果
从实车采集的10名驾驶员样本集中随机抽取共计200个有效样本用于分析。将200个有效样本分别标定,最终得到清醒状态样本共142个,疲劳状态样本37个,重度疲劳状态样本21个。
分别将样本输入疲劳检测系统,系统识别判定结果如表8所示。
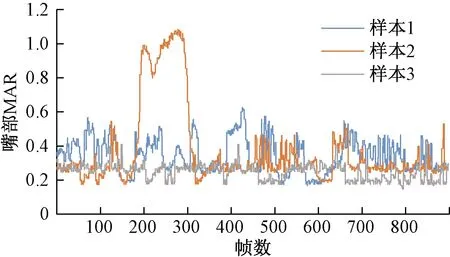
图15 样本MAR比较Fig.15 MAR comparison of samples
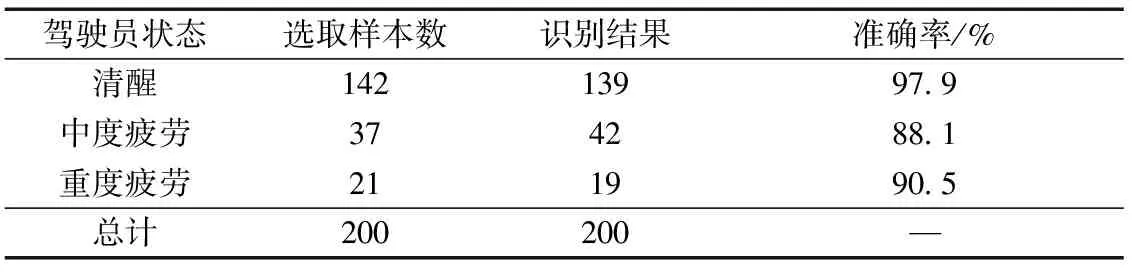
表8 系统识别结果
从实验结果(表8)可知,对照样本的人工标定结果,系统对3种疲劳状态的检测普遍具有较高的检测准确率,在区分清醒和非清醒状态时达到了97.9%的检测效果。系统的平均识别准确率达到了92.2%,在同类疲劳检测系统中达到了较高的水平。
5 结论
针对疲劳驾驶检测的特点,融合多个疲劳特征参数设计了一种高效、可靠的疲劳检测系统,得出如下结论。
(1)针对复杂的驾驶环境,对SSD目标检测算法进行结构优化及损失函数改进,改进后的SSD算法在人脸数据集上的平均准确率提高了7.0%。
(2)为提高检测效率及鲁棒性,结合CamShift及卡尔曼算法进行人脸跟踪预测。颜色干扰实验及遮挡实验表明,融合后的算法对环境干扰的鲁棒性更强,能避免跟踪丢失或目标误判。
(3)利用眼睛和嘴巴的特征点序列,建立疲劳多个特征参数并设定疲劳判定策略。整体系统在实车样本集上的平均检测准确率为92.2%,达到了疲劳检测系统的要求。
