文本情绪分析中词嵌入模型对比研究
2021-03-07胡琼李奇王树军
胡琼 李奇 王树军

摘要:在利用神经网络进行文本情绪分析时,不同的词嵌入会得到不同的判断结果。该文对比了由文本自身建立的基线模型和预训练词嵌入模型GloVe以及FastText的识别效果,通过实验得出了在不同情况下两种类型的识别优劣性。此外,针对两种预训练词嵌入,得出高频词汇的缺失对总体结果无重要影响的结论。
关键词:情绪分析;预训练词嵌入
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2021)36-0109-03
开放科学(资源服务)标识码(OSID):
文本情绪分析是在神经网络,尤其是以RNN(Recurrent Neural Network)为方向的深度学习方法上所重点研究的对象之一。简单的文本情绪分类有正、负情感评价之分,稍微复杂一点的增加了中性评价,再为复杂的分类则是以1~5或1~10类似的多级评分表示,如对网店商品的打分,对酒店、旅游景点的评价等。研究文本情绪分析可在一定程度上协助被评价方更改产品体验,改进广告投放策略等。例如KFC决定用在社交媒体上获取的“流行文化元素”作为某一季的产品主题,Apple公司以市场调研和竞争对手产品分析获取的情感评价作为新产品的研发关键词等[1]。
在以文本为分析对象的神经网络结构中,文本信息通常是以词元(token)的形式进行计算,即将单个字符(charlevel)或单词(wordlevel)的数据转换为数字,再将数字转换为固定大小的向量。向量可以由文本自身决定,也可由外部预训练词向量导入。这一将独立的文本信息映射为向量或矩阵的形式称为词嵌入。词嵌入将作为深度模型中嵌入层的输入进行下一步的运算。选择合适的词嵌入能更好地建立权重参数,不仅降低计算维度,且能更为准确地描述各个向量之间的关系[2]。为对下文中名词概念加以解释说明,本文以文本自身建立词向量作为嵌入层输入的算法模型称为基线模型,以预训练词向量输入嵌入层所建立的模型称为预训练嵌入层模型。
目前针对英文词嵌入的研究主要包含有Word2Vec、GloVe和FastText三个方向等,根据语料库差异,又可分为谷歌新闻热词模型、维基百科词汇模型、网络爬虫(CommonCrawl)词汇模型等。使用预训练词嵌入的目的一般是为了节约训练时间,减少损失,同时获得更为准确的预测性。目前,已有不少论文论证了预训练嵌入层模型的有效性[3],也有部分论文表明相对基线模型,使用预训练嵌入层模型并无优势[4]。其中大部分论文都是以文本分类(如判断文本内容是否包含非法信息等)作为研究方向,针对文本情绪分析的词嵌入研究还不太多。
本文选取了金融类数据集[5],该数据集包含散户投资者对美国财经新闻标题的4837条看法,每条看法有其对应的情绪标签,为正、负、中三种评价之一。通过实验,可针对该数据集建立一个较为准确的神经网络预测模型。因研究对象为含有较长信息的文本变量,实验选用了RNN算法,基于Tensorflow的Keras[6]建立了神经网络模型,包括有嵌入层、含有256个神经元的GRU层、最大池化层以及全连接层,激活函数为softmax。在词嵌入方面,为研究基线模型及预训练嵌入层模型的区别和利弊,本文使用了FastText[7]以及GloVe[8]预训练词向量,通过调整参数,对比发现和使用文本自身词嵌入时对识别结果造成的不同影响。
1 预训练嵌入层和基线模型
在Keras中,定义一个嵌入层需要有词汇表大小,输出词向量维度,初始化权重等。在以文本自身为语料库的词向量建立中,可设嵌入层初始化权重值为高斯随机数,设定该权重值可随着迭代次数学习更新;而在使用预训练词向量时,需首先导入词向量,初始化权重值为向量值并禁止其迭代更新。在使用GloVe词向量时,本文采用了其基于维基百科训练的300维词向量模型,FastText词汇表同样如此,同时为了更好地保持在实验中各嵌入层一致性,实验设定基线模型的输出词向量也是300维。
比较两种预训练词嵌入,GloVe以单词作为训练中的最小单位,通过构建各单词在指定语料库中所对应的共现矩阵进行训练,共现矩阵表示了每个单词在上下文中出现的频率。为了提高效率,需要分解共现矩阵以实现降维计算,例如在本文中所用GloVe向量为300维,GloVe同时也提供了100维、50维等向量模型。GloVe的优势是在词向量空间中能够更好地描述词与词之间的关系。
FastText使用n-gram字符作为最小单位。例如,词向量“apple”可以分解为单独的词向量单元,如“ap”“app”“ple”等,取决于n的大小。使用FastText的最大好处是它可以为稀有词甚至是训练期间未见过的词生成更好的词嵌入,因为经过n-gram分解后的字符向量与其他词所分解的字符向量部分重复。这是以單词为基本学习单位的GloVe或Word2vec词嵌入所无法实现的。
2 简单预处理
在训练之前通常会对数据作预处理,在本文中,仅对数据作了简单的清理,删除了非英语字符、数字、各种标点符号,以及将所有单词一律改成小写。尽管在GloVe模型中保留了数字及部分特殊符号,为和FastText作对比,文本中统一不予考虑。事实上,如“经济增长10%”这一句中,“经济增长”作为关键,数字10或者符号%的省去并不会造成理解上的误差。
在预处理后,实验将预训练词向量与文本中所有词汇量作对比,取交集作为词嵌入。对于文本中出现,预训练词向量中未出现单词统一设零,对于预训练词向量中包含,文本中未包含单词统一舍去。对比而言,在基线模型中,预处理后文本中所有单词参与训练,没有置零或舍去的操作。
3 实验
3.1 分批次训练
以前文所述RNN模型进行实验,机器运行环境为Linux系统,Anaconda版本4.10.1,Tensorflow-2.4.1,Python-3.8.1。通过调整训练集大小和批次大小进行分步实验,设测试集大小分别占总数据集的0.2、0.5和0.8。同时设时期(epoch)为50,提前停止(EarlyStopping)节点设定为损失函数停止下降3次。验证集大小设为0.2。将训练好的模型用于测试集,以批次大小为32、128和512分三次进行实验。结果如图1所示。
從图中可以看到,测试集正确判断文本情绪的比例总体随着训练集的增加而上升。当训练集数量占比0.2时,三种词嵌入形式预测正确率都在70%以下,使用预训练词嵌入的效果比自嵌入更好,当训练集数量增加时,三种词嵌入形式预测正确率超越70%,使用基线模型的结果和预训练词嵌入的结果逐渐持平,在训练集占比0.8时,三种词嵌入形式预测正确率在74%上下,基线模型的准确度和GloVe词嵌入近似,高于FastText模型。对比两种词嵌入,GloVe的识别率相对FastText略高。因设定训练集每次打乱数据进行学习,Keras在同一参数下运行结果可能产生3%的波动,根据上图并不能取得更详细的结论,同时经作者多次验证,图1只是所有可能性的一种,实验结果证明GloVe并不一定比FastText识别结果要好。
3.2 同一批次下损失函数分析
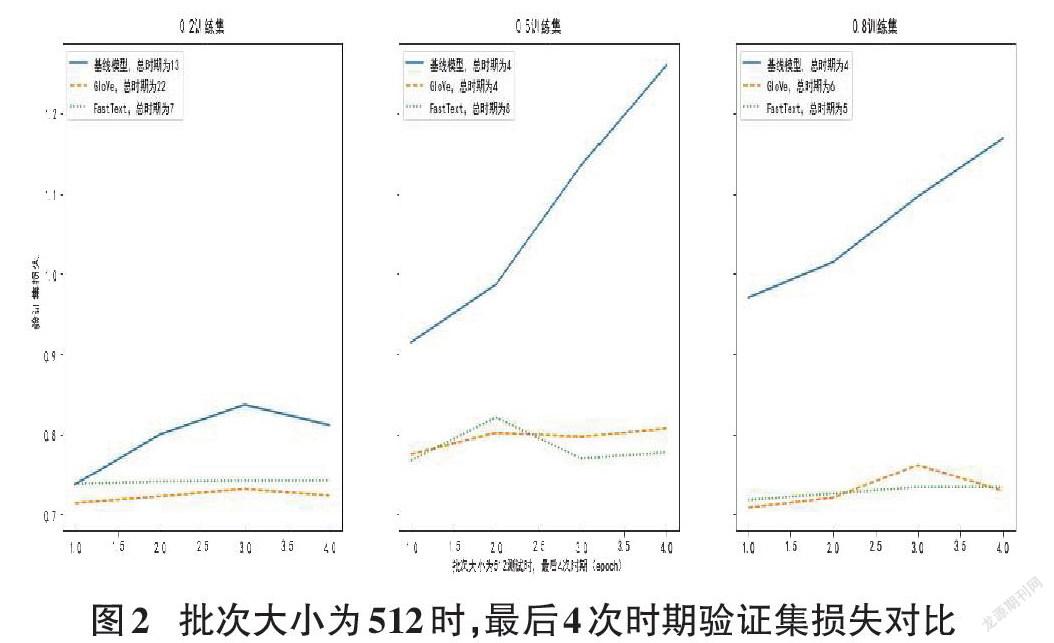
从图1中三种批次大小设定来看,32~512的改变并没有对测试集的识别率产生重要影响,本例中批次大小改变更多的是影响运算效率而非结果准确性。图2展示了以512为批次大小运算情况下,不同词嵌入方式的验证集损失。因设定了提前停止为3,故选取最后4次时期运算结果作图。
从图中可以看到基线模型损失基本全部高于预训练词嵌入模型且呈上升趋势,两种词嵌入模型之间的区别并不大。说明预训练词嵌入在取得较小的损失函数上具有更大的优势。以本例来看,基线模型的损失更大,更容易产生过拟合。另一点需加以说明的是在实验中发现总体上使用基线模型需要的时期小于预训练词嵌入,也就是在相同参数的设定下,基线模型的运算速度大于预训练嵌入层模型。
3.3 GloVe与FastText对比
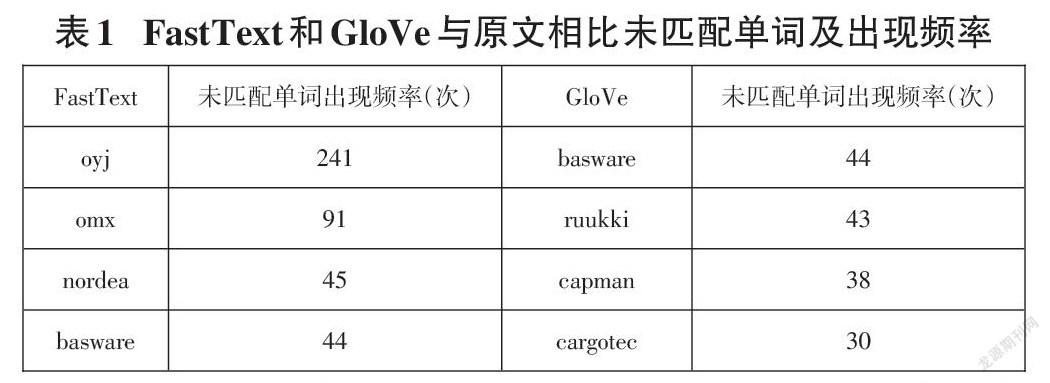
为进一步找出两种不同预训练词嵌入的区别,实验分别对比了GloVe和FastText词向量与原文的匹配度,结果为FastText的词汇匹配度是80.62%,即4846个总词汇量中有3906个单词存在于预训练词汇库中,总文本词嵌入为94.91%,未匹配单词为“oyj”等专有名词。对比而言,GloVe的单词匹配度有88.46%,总文本词嵌入达到了97.45%,未匹配单词为“basware”等专有名词,且出现频率不高。GloVe的预训练单词总量为40万,FastText为100万,前者是基于2014年的维基百科和英语字典(English Gigaword Fifth Edition), 后者是基于2017年的维基百科、UMBC语料库和统计机器翻译(SMT)中新闻数据集。表1列出了两种词嵌入中前4种高频未匹配单词。
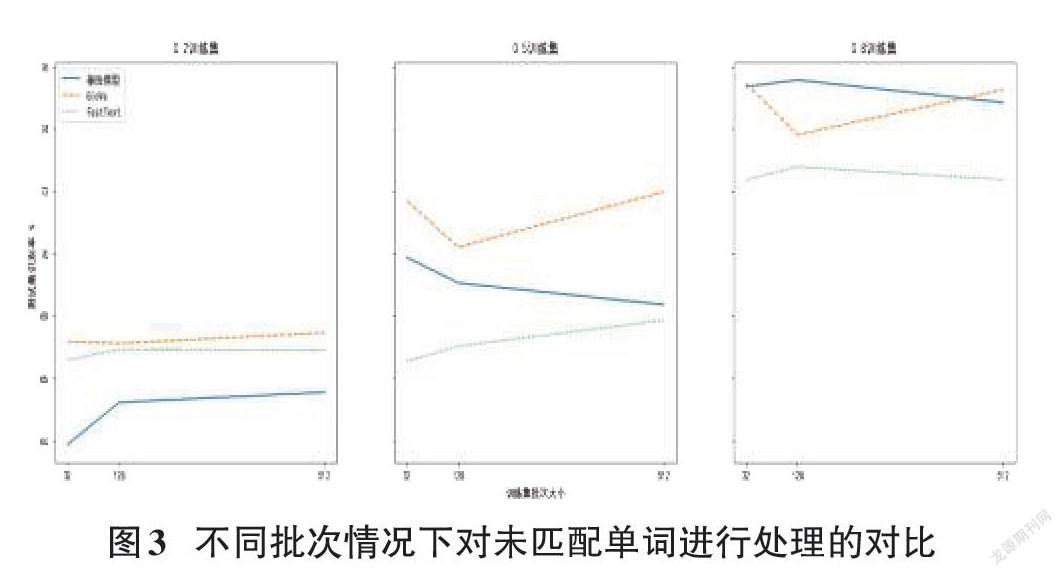
以“basware”为界,“oyj”“omx”“nordea”这三个单词在GloVe中全部匹配而在FastText中全部未匹配。因无法获得真实的fasttext中三个单词所对应的词向量,实验将GloVe中这三个单词所对应的词向量值全部置零,重复前文实验,如测试集结果下降则能说明更精确的单词匹配度能获得更好的识别效果。为了证明高频单词对全文识别的影响,实验同样考虑将基线模型中这三个单词的词向量置零。
结果证明在去掉三个单词后,文本情绪判断的准确率几乎不受影响,图3是对原实验多次重复后的一种情况。尽管图中数据间有较大空隙,以Keras计算波动来看可以说几乎没有差别。可见本例中高频未匹配单词并不是影响两种预训练嵌入层模型测试结果之差的主要原因。
4 结语
本例中,不管是基线模型还是预训练嵌入层模型都表现出了较好的识别率,总体损失上后者相比前者更为稳健,同时使用预训练词向量可以更好地解决过拟合的问题,如训练集数量较少,预训练词嵌入应是一种更为推荐的嵌入层方法。在比较GloVe和FastText两种预训练词嵌入时,前者的单词匹配度大于后者,测试集识别率两者相近,意味着更高的单词匹配度不一定带来更好的识别结果。此外,本文选用金融新闻类数据集,FastText中本身包含有新闻类语料库但其真实匹配度反而不如GloVe,说明在选择预训练词嵌入时不一定要寻找与文本相应的类别,100万的总词汇量不一定比40万的词汇量更贴合文本数据。从另一角度来看,FastText在单词匹配度较低的情况下可以获得和GloVe基本一致的识别率,说明n-gram算法确实对陌生单词有更好的识别率,如文本内容较为生僻,FastText词嵌入或可取得更为优异的分析结果。
参考文献:
[1] Régens. How companies can leverage sentiment analysis to improve operations and maximize their workflows[EB/OL].[2021-04-10].https://www.regens.com/en/-/how-companies-can-leverage-sentiment-analysis-to-improve-operations-and-maximize-their-workflows,2021-3-16.
[2] Levy O, Goldberg Y. Neural word embedding as implicit matrix factorization[J].Advances in neural information processing systems,2014,27:2177-2185.
[3] Kumar P S, Yadav R B, Dhavale S V. A comparison of pre-trained word embeddings for sentiment analysis using Deep Learning[C]//International Conference on Innovative Computing and Communications. Springer, Singapore, 2021: 525-537.
[4] Rezaeinia S M,Rahmani R,Ghodsi A,et al.Sentiment analysis based on improved pre-trained word embeddings[J].Expert Systems With Applications,2019,117:139-147.
[5] Malo P,Sinha A,Korhonen P,et al.Good debt or bad debt:Detecting semantic orientations in economic texts[J].Journal of the Association for Information Science and Technology,2014,65(4):782-796.
[6] Géron A. Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow: Concepts, tools, and techniques to build intelligent systems[M]. Cambridge:O'Reilly Media,2019.
[7] Bojanowski P,Grave E,Joulin A,et al.Enriching word vectors with subword information[J].Transactions of the Association for Computational Linguistics,2017,5:135-146.
[8] Pennington J,Socher R,Manning C.Glove:global vectors for word representation[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP).Doha,Qatar.Stroudsburg,PA,USA:Association for Computational Linguistics,2014:1532-1543.
【通聯编辑:朱宝贵】
