基于Scrapy技术的高校计算机类课程网络视频库建设的研究
2021-03-07张笑青蒋慧
张笑青 蒋慧







摘要:该文基于Scrapy爬虫技术采集慕课网站(大型开放式网络课程)的视频资源,并使用协同推荐算法对采集的信息进行推荐和展示。主要内容包括对大学开放课程平台进行视频爬虫、数据解析、数据存储;将数据爬取的结果与Recommend算法相结合实现课程信息推荐功能;通过使用Flask框架对采集和推荐的结果进行展示,并实现视频分类与模糊查询等功能。该视频库系统可以给教师与学生提供更丰富便捷的教学资源平台。
关键词:Python爬虫;Scrapy框架;视频库;高校计算机课程
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2021)36-0037-03
开放科学(资源服务)标识码(OSID):
1 背景
基于慕课平台的高校计算机类课程网络教学是推动高校计算机类课程教育改革、促进高校计算机课程教育网络化、科学化的有效途径。视频课程突破了传统教学活动的时间和空间限制,使课堂上枯燥的教学内容变得更加生动,同时实现了教学双方的全面交流与互动。随着慕课模式在高等教育中的普及,视频课程库的开发逐渐成为高等教育领域的重要课题之一。为了确保高校教育的质量和效果,本文对高校慕课平台下计算机类视频课程库建设过程中的相关问题进行了研究,讨论了构建视频课程库系统的方法,有助于确定与设计有效且稳健的视频课程模型相关的问题,期望能为高校计算机类视频课程的科学建设提供一些参考。
本文的各部分组织如下:首先,介绍网络爬虫Scrapy框架,它包含了Scrapy引擎(核心)、Downloader Middlewares下载器、Schedular调制器、管道Spiders解析器,并介绍其相关功能。其次,介绍视频信息的采集和存储,根据慕课平台的内容和它的网页源代码分析其页面结构,从而实现网页数据的采集;同时,采用协同过滤算法(Recommend)得出权重矩阵并返回数据库进行永久保存。最后,介绍对采集的视频信息数据进行描述性的界面展示,并对采集的数据进行二次开发,使用Flask技术实现视频数据的分类和模糊搜索。
2 网络爬虫
网络爬虫可以根据既定的算法和逻辑自动采集所需要的页面资源数据,并能更新网页数据[1]。通常网络爬虫可以分为数据爬取、数据预处理、数据存储几部分操作。其中,聚焦爬虫能根据既定的定量爬取策略,通過网页分析算法,过滤有效的URL及其与主题相关的链接,在特定的搜索框架下,从所需要的队列中选取下一个数据想要爬取的网页,并进行反复爬取,直到得到满足数据匹配的URL网页时停止。根据爬取策略所爬取的网页数据,将会被后台处理,包括分析过滤、创建索引以便下一步可以进行查询和检索操作。
2.1 视频信息采集爬虫的分析与设计
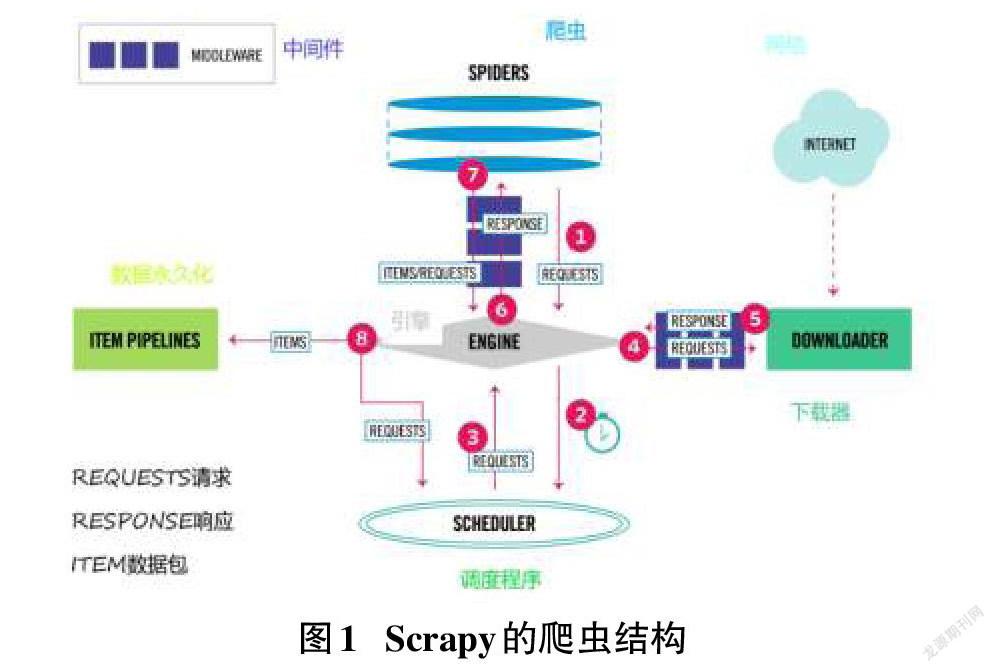
Scrapy引擎是Scrapy的核心,它可以将前端收到的请求发送给爬虫,然后Spiders发送给核心对Scheduler请求,再被引擎提交到下载器处理,下载器处理完成后会发送Responses给引擎,引擎将其发送至Spiders进行处理[2]。Scrapy的爬虫结构如图1所示。
3 视频信息采集的实现
本文的网络视频数据爬虫的整体框架大致如图2所示。
3.1 数据源与网页分析
本文先对慕课网站的爬取进行研究,由于网课为在线播放的模式,普通爬虫较难下载视频,所以本次抓取的慕课网的视频基本信息包括课程名称、图片的地址、课程图片内容、课程人数、课程简介、课程的评分、课程难度指数以及课程的时长等,示例页面如图3所示。
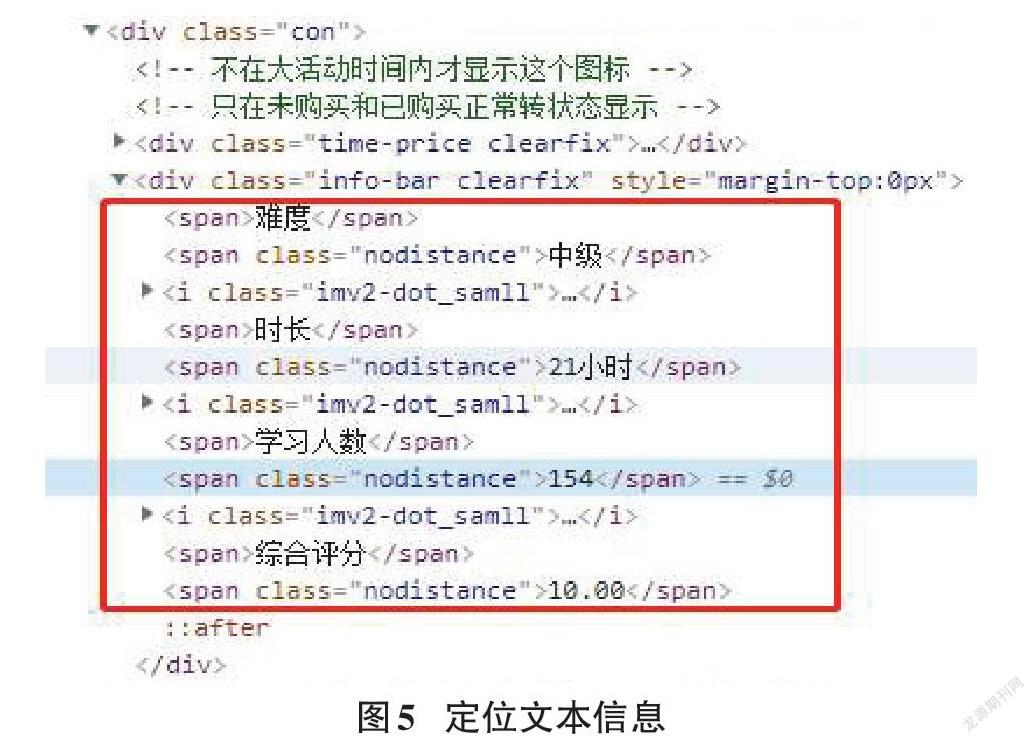
使用Response爬虫请求获取网页资源,可以抓取慕课网站中每个课程的Div,这里Scrapy支持使用Xpath定位器定位想要爬取网页资源的具体位置,可以使用Xpath表达式获取所有h3标签里的文本内容,从而获取页面中课程的标题[3-4]。如图4代码可以定位课程名称:
3.2 MongoDB数据库与数据存储
本文采集的数据是慕课网的视频信息,对于视频信息的存储,这里选择使用非关系型的文档数据库MongoDB来进行存储。
MongoDB数据库是基于文档的非关系型数据库,因此MongoDB并没有固定的结构,在建立文档型的范例时,即便没有该数据库的布局信息,仍能存到MongoDB数据库中[5]。根据慕课网提供的字段信息,设计了如下集合:cursesinfo用于存储采集的视频信息数据,history用于存储点击的历史数据,hotcourse是根据前面的演算和总结计算出8大热门课程。其中curseinfo集合存储的信息对应慕课网爬取的各个字段如图7所示。
数据存储使用代码实现,即先将爬虫爬取的网页元素内容解析,并创建一个dict对象,将爬取的数据逐一对应填充到dict内,再通过PyMongo的collection方法将dict中的数据存储到MongoDB中即可。
3.3 数据预处理
数据预处理主要是去除脏数据,这里主要从数据缺失值检测、数据去重、噪声数据处理、数据集成这四个方面对数据进行清洗。通常在数据采集和传输等情况下会导致数据缺失,对于缺失值处理方法通常有两种方法:第一种方法是直接删除不完整的数据,该方法适用于缺失值的样本占整个数据集样本的比例较低的情况,但是这样可能会丢失大量隐藏在这些删除数据中的信息或者造成资源浪费;第二种方法是通过插入数据将数据填充完整,通常是将平均数据插入来补充完整,即是取数据中的平均数代替数据中所缺少的值,或者在数据中随机地挑选个别数据进行插入。本文中使用的是第一种方法,Python中的isnull为是否需要进行插入填补。
3.4 基于物品的协同过滤算法的实现
基于物品的协同算法步骤:1)计算物品之间的相似度;2)根据物品的相似度和用户的历史行为记录给用户生成推荐列表。该算法的核心是:从物品角度找到相似度高的商品进行推荐。算法思想为:根据用户对物品的喜欢程度找到相似的物品,再根据用户曾经喜欢的物品推荐相类似的物品。从计算层面看,衡量物品的好坏就是根据用户对这个物品的喜欢程度,根据用户的曾经喜欢程度和现在喜欢程度得到一个物品推荐的排序列表。
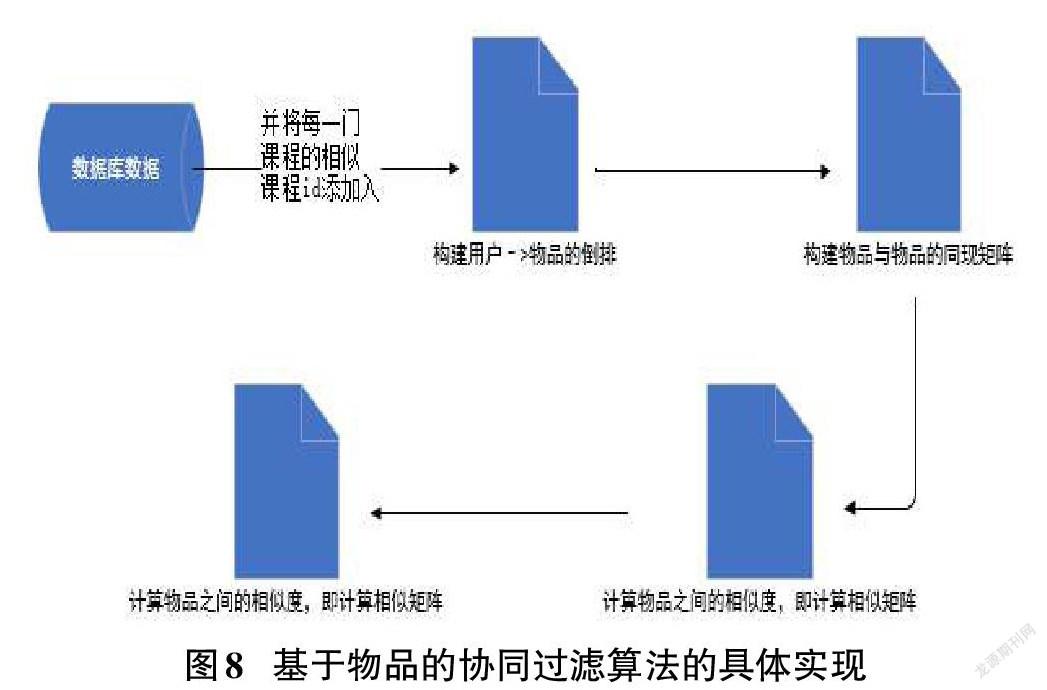
基于Python语言和物品的协同过滤推荐算法,对数据库中的课程相关数据进行功能的实现,具体实现过程如图8所示。
图8的第一步是搭建用户和物品的直接关系,接着得到用户和物品之间的权重矩阵,计算他们之间的相似度,然后根据用户的浏览记录,给用户推荐系统认为用户需要的物品,因此最终推荐的物品根据用户自己的喜好决定。
4 视频数据采集展示的实现
本文中推荐课程系统的设计采用Flask框架,其功能主要为视频课程的推荐、搜索、分类。Flask是如今流行的Web框架,它使用Python实现功能,由于Flask不会将其全部的Web框架放在Python里面,而是将代码简单化,因此它又被称为“微框架”。通常情况下Flask自己不会主动提供系统所需要的功能,在项目结构的运行状态下它们可以自由进行配置。Flask主要包含两个核心:Werkzeug和Jinja2,这两个核心有着不一样的功能。而就是由于Flask这两个核心功能让Web前端展示更为简便明了。
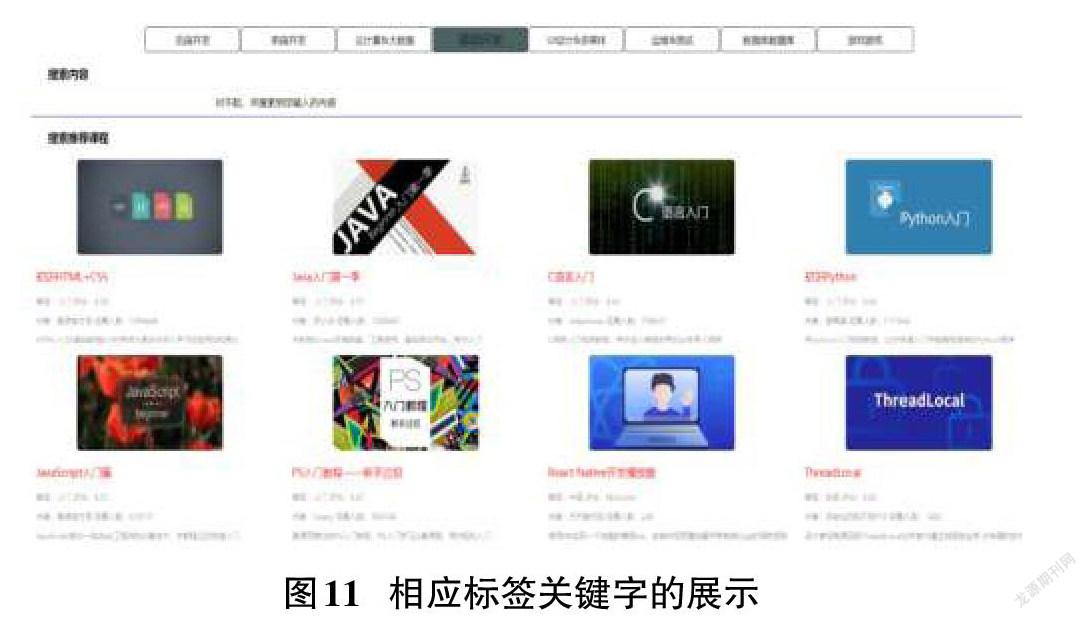
分類展示:选择搜索框下的技术标签,对于慕课网的对应分类视频信息书籍进行展示,如图11展示结果为前端技术教学相关内容。
推荐课程展示:在系统的推荐下,Recommend算法根据用户浏览的课程进行推荐,实现推荐与关键字相关的课程信息。
相关课程关键字搜索:系统根据输入的关键字进行模糊查询,并实时进行数据采集,将采集后的内容呈现在页面上,以展示相关的课程搜索结果及相关推荐课程展示。
5 结束语
本文主要使用Scrapy爬虫技术爬取慕课网站的视频资源,并使用协同推荐算法对采集的信息进行推荐和展示。该视频资源系统可以给教师与学生提供更丰富便捷的教学资源平台,对今后的计算机课程在线教与学具有创新价值和意义。
参考文献:
[1] 刘雯.主流开源爬虫框架比较与分析[J].电子世界,2018(6):65-67.
[2] 施金龙.基于PythonScrapy技术的新闻线索汇聚实现[J].电子技术与软件工程,2020(13):180-181.
[3] 张捷,郝建维,李欢欢.基于Scrapy的分布式网页及文件爬虫应用的研究[J].科技创新导报,2020,17(21):149-153.
[4] 唐琳,董依萌,何天宇.基于Python的网络爬虫技术的关键性问题探索[J].电子世界,2018(14):32-33.
[5] 李兴武.大数据下MongoDB数据库数据文档存储去重研究[J].数字技术与应用,2017(9):99-101.
【通联编辑:谢媛媛】
