基于CEEMDAN-ARMA模型的年径流量预测研究
2021-03-03张金萍许敏张鑫肖宏林
张金萍 许敏 张鑫 肖宏林


摘 要:为了更好地预测河川径流,提高年径流的预测精度,以黄河源区唐乃亥水文站1956—2016年的实测年径流量为研究数据,采用完全集合经验模态分解(CEEMDAN)和自回归滑动平均模型(ARMA)相结合的方法,建立CEEMDAN-ARMA组合模型,并将组合模型的预测结果与单一的ARIMA模型的预测结果进行对比。结果表明:组合模型的拟合优度大于单一ARIMA模型的拟合优度;组合模型预测的平均相对误差为3.31%,比单一的ARIMA模型的预测精度提高了4.63%。由此可见,CEEMDAN-ARMA模型预测精度高于单一的ARIMA模型,利用CEEMDAN分解得到的IMF分量序列作为ARIMA模型的输入数据可以提高模型的预测精度。
关键词:径流预测;CEEMDAN;ARMA模型;黄河源区
中图分类号:TV121;TV882.1文献标志码:A
doi:10.3969/j.issn.1000-1379.2021.01.007
引用格式:张金萍,许敏,张鑫,等.基于CEEMDAN-ARMA模型的年径流量预测研究[J].人民黄河,2021,43(1):35-39.
Annual Runoff Prediction Based on CEEMDAN-ARMA Model
ZHANG Jinping1,2,3, XU Min1, ZHANG Xin1, XIAO Honglin1
(1.School of Water Science and Engineering, Zhengzhou University, Zhengzhou 450001, China;
2.Zhengzhou Key Laboratory of Water Resources and Environment, Zhengzhou 450001, China;
3.Henan Province Key Laboratory of Groundwater Pollution Prevention and Remediation, Zhengzhou 450001, China)
Abstract:In order to better predict river runoff and improve the accuracy of annual runoff prediction, the measured annual runoff of Tangnaihai Hydrologic Station in the source area of the Yellow River from 1956 to 2016 was taken as the research data and a CEEMDAN-ARMA model was established bycombining Complete Ensemble Empirical Mode Decomposition with Adaptive Noise(CEEMDAN)with Auto-Regressive Moving Average Model(ARMA)to simulate and predict the annual runoff sequence in the research area, and compared the predicted results of the combined model with the single ARIMA model. The results show that the goodness of fit of composite model is better than that of single ARIMA model; the average relative error of the combined model is 3.31%, which is 4.63% lower than that of the single ARIMA model. Therefore, the prediction accuracy of CEEMDAN-ARMA model is higher than that of the single ARIMA model. The IMFs component series which decomposed by CEEMDAN can be used as the input data of ARMA model to improve the prediction accuracy of the model.
Key words: runoff prediction; CEEMDAN; ARMA model; Yellow River source area
徑流量是河流的重要水文变量之一,受气象、人为等诸多不确定因素的影响,具有较强的随机性。提高径流长期预报的准确性,对于科学认识径流过程、掌握其变化成因和演化特征具有重要意义。传统的河川径流预测方法如成因分析和水文统计方法只能反映出线性时间序列或简单的非线性时间序列[1],而实际的径流序列受多种因素的影响,往往呈现出复杂的非线性空间过程。单一预测模型中的函数辨识选择受径流序列中噪声等随机因素的影响,难以对整个水文过程进行有效的拟合。组合预测模型成为近年来广受关注的研究方向之一,组合模型在实践中更多的是采用不同的分析方法与各种预测模型进行组合,以分析方法为基础来提高模型的预测精度[2]。
笔者将CEEMDAN与ARMA模型相结合,以CEEMDAN方法为基础对黄河源区唐乃亥水文站的年径流序列进行分解,得到年径流量在各个时间尺度上的波动特征,掌握径流内部变化规律。在此基础上利用ARMA模型对各分量进行预测,将各分量的预测值累加在一起得到径流量的预测值,分析预测的精度,并将其与单一的ARIMA模型预测值进行对比,为径流预测提出一种新的方法,以期为黄河源区水资源开发利用提供技术参考。
1 研究对象
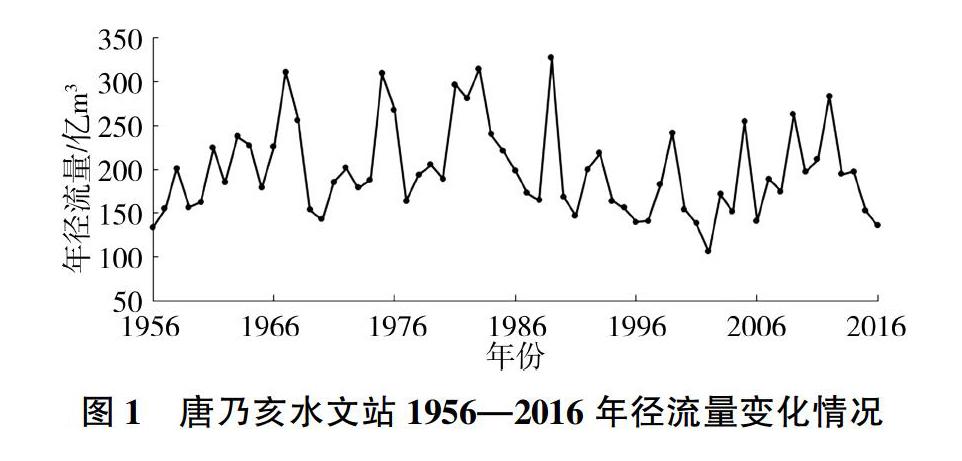
黄河源区唐乃亥水文站是黄河干流天然径流河段与人工调节河段的分界点,控制流域面积为12.2万km2,多年平均径流量为205.1亿m3,在黄河水量调度中具有重要的战略地位。研究数据采用唐乃亥水文站1956—2016年的年径流量资料,其中1956—2007年的径流量数据用于模型的模拟,2008—2016年的径流量数据用于模型的预测。唐乃亥水文站1956—2016年径流量变化情况见图1。
2 研究方法
2.1 CEEMDAN方法
CEEMDAN[3]是在EMD[4]和EEMD[5]基础上发展来的,它解决了上述两种方法中存在的模态混淆和重构序列中残留噪声的问题,其分解过程具有完整性且几乎无重构误差,具体算法如下。
假设经过EMD分解产生的第k阶模态分量为Ek(·),第j次加入的服从标准正态分布的白噪声序列为wj(t),CEEMDAN分解后得到的第i阶模态为fi(t),t为时间变量。
(1)在原始信号x(t)中加入噪声分量后进行EMD分解。假设第m次加入噪声后分解出的一阶模态分量为fm1(t),则CEEMDAN一阶模态分量为
f′1(t)=1M∑Mm=1fm1(t) (m=1,2,…,M)(1)
(2)计算CEEMDAN分解的第一个余量信号r1(t),并且向余量信号中加入高斯白噪声分量φ1E1[wm(t)],求第二阶模态分量,则
r1(t)=x(t)-f′1(t)(2)
f′2(t)=1M∑Mm=1E1{r1(t)+φ1E1[wm(t)]}(3)
(3)重复步骤(2),可得第i个余量信号和第i+1阶模态,当余量信号无法进行EMD分解时,CEEMDAN分解也随之终止。假设最后分解出k阶模态,则
ri(t)=ri-1(t)-f′i(t)(4)
f′i+1(t)=1M∑Mm=1E1{ri(t)+φiEi[wm(t)]}(5)
R(t)=x(t)-∑ki=1f′i(t)(6)
式中:R(t)为最终的残余信号。
2.2 ARMA模型
ARMA[6]是一种以随机理论为基础的时间序列分析模型,由自回归模型(AR模型)和滑动平均模型(MA模型)混合构成。ARMA模型对扰动项进行模型分析,使模型综合考虑过去值、现在值和误差,从而提高模型的预测精度[7],其建模过程如下。
设{yt}是一个平稳、正态分布且零均值的时间序列,它的取值不仅与其前p步的各个取值有关,而且还与前q步的各个干扰因素有关,则ARMA模型的一般形式为
yt=c+∑pi=1φiyt-1+∑qi=1θiεt-1+εt(7)
式中:p为自回归阶数;q为移动平均阶数;φi为自回归系数;θi为移动平均系数;{εt}为白噪声序列;c为常数。
一般将ARMA模型应用于平稳的时间序列,当序列不平稳时,则通过d阶差分过程将不平稳时间序列转化为平稳时间序列。实际上d通常为0或1,至多为2。此时,建立的模型为ARIMA(p,d,q)。其中d为滞后阶数,当d为0时,建立的模型为ARMA模型。
2.3 CEEMDAN-ARMA模型
将CEEMDAN方法和ARMA模型进行耦合,对年径流量序列进行预测。CEEMDAN-ARMA预测模型的方法步骤:①利用CEEMDAN方法将年径流量数据分解成IMF分量和一个趋势项;②ARMA模型作为预测工具对分解后的IMF分量和趋势项进行建模,并分别对每个分量进行相应的预测;③将所有分量的预测结果相加,得到最终结果,即为耦合后的结果,把该结果作为徑流量序列的预测结果。
3 实例分析
3.1 CEEMDAN分解
为了减轻数据的振荡,对黄河源区唐乃亥水文站1956—2016年的径流量数据取对数,再利用CEEMDAN方法对取对数后的数据进行分解,可以将序列分解成4个IMF分量和1个趋势项分量。分解结果如图2所示。
由图2可知,径流量时间序列的IMF分量表现了该时间序列在频率、振幅和波长方面的变化。IMF1分量的频率最高、振幅最大、波长最短,由IMF1分量到IMF4分量,分量的振幅逐渐减小、频率逐渐降低、波长逐渐变长。趋势项分量体现了径流量在长时期内整体的变化趋势,可以看出20世纪60年代中期至今,唐乃亥水文站的年径流量整体上呈现逐渐衰减的趋势。除此之外,唐乃亥水文站年径流量的IMF1~IMF4分量分别具有准3~5 a、准7~9 a、准9~16 a和准32 a的波动周期。利用CEEMDAN方法对径流量序列进行分解有助于了解径流量周期变化的特征,并且能将非线性、非平稳时间序列转化为平稳时间序列,有助于提高预测的准确性。
3.2 CEEMDAN-ARMA模型的识别与检验
3.2.1 模型识别
建立模型之前,需要检验径流时间序列的平稳性,即ADF单位根检验,这是目前应用较普遍的平稳性检验方法[8]。对原始径流量数据序列x和CEEMDAN分解后得到的IMF分量进行单位根检验,判断各分量是否平稳,检验结果见表1。
由表1可知,原始径流量序列在1%、5%、10%的显著性水平下存在单位根,序列不平稳,经过一阶差分后通过ADF检验证明差分后的数据是平稳的,故d=1。径流量取对数之后分解得到的本征模态函数在1%、5%、10%的显著性水平下,ADF检验值均小于0.05,拒绝具有单位根这一原假设,故其本征模态函数均为平稳序列。
根据经过差分后平稳的年径流序列的自相关函数(ACF)图和偏自相关函数(PACF)图,确定合适的模型为ARIMA(1,1,1)、ARIMA(2,1,1)和ARIMA(3,1,1),通过最小信息准则,最终选定的模型为ARIMA(1,1,1)。CEEMDAN分解后的IMF分量也可以进行同样的分析,最终IMF1分量选择ARMA(3,1)模型、IMF2分量选择ARMA(3,3)模型、IMF3分量选择ARMA(3,2)模型、IMF4分量选择ARMA(3,4)模型。
3.2.2 模型检验
根据选定的模型,对模型的合理性进行检验。采用LM检验,即假设残差序列不存在自相关性,如果F统计量的P值小于5%的置信水平,则拒绝原假设,模型存在序列自相关性,所建立的模型不合理,需要改进;反之则合理。LM检验结果见表2。由表2可知,得到的LM统计量对应的P值均大于5%的显著性水平,不拒绝原假设,表明残差序列不存在自相关性,所建立的模型是合理的。
3.3 模型的模拟和预测
3.3.1 模型的模拟
根据建立的模型对1959—2007年的径流量进行静态预测,即模型内的模拟。各分量的模拟值与实际值对比如图3所示,把分量的模拟值累加在一起得到组合后的模拟值,模拟结果如图4所示,利用原始数据建立ARIMA模型的模拟结果如图5所示,原始序列和组合序列的模拟值与实际值的相对误差如图6所示。
由图3可知,IMF1分量的拟合效果最差,并且由IMF1分量至IMF4分量,拟合程度逐渐提高,即高频分量的拟合程度低于低频分量的拟合程度,在提高模型的精度方面,可以考虑提高高频分量的预测精度,以期提高整个模型的预测精度。由图4、图5可知,组合后模型的拟合效果优于原始序列建立模型的拟合效果。进一步分析图6,原始序列模型模拟的相对误差整体上大于分解组合后模型模拟的相对误差,并且无论是原始序列还是组合后序列,径流量模拟值和实测值的变化趋势大体一致,拟合效果较好,所建立模型的模拟精度较高,可以利用该模型进行预测。
3.3.2 模型的预测
根据ARIMA模型和建立的CEEMDAN-ARMA模型,对唐乃亥水文站2008—2016年的年径流量进行预测,结果见表3。
由表3可知,利用ARIMA模型对2008—2016年的年径流量进行预测,预测值和实际值的相对误差在2008年、2009年、2012年和2016年均大于10%,其中2016年的相对误差最大为13.24%,平均相对误差为7.94%。利用CEEMDAN-ARMA模型对2008—2016年径流量进行预测,预测值和实际观测值的相对误差均在10%以内,平均相对误差为3.31%,远低于10%,说明利用CEEMDAN-ARMA模型预测的效果优于单一的ARIMA模型,同时也说明了CEEMDAN模型适用于年径流时间序列的分解,“分解与组合”的思想是可行的,所提出的CEEMDAN-ARMA模型可以克服单个模型的缺点,将CEEMDAN分解的年径流量数据作为模型的输入数据,可以提高模型的预测精度。
4 结 论
(1)CEEMDAN方法原理简单、操作方便,利用CEEMDAN方法对径流序列进行分解有助于了解径流量周期变化的特征,并且能将非线性、非平稳时间序列转化为平稳时间序列,有助于提高预测的准确性,解决了单独运用ARMA模型预测难以揭示径流变化特征和预测精度较低的问题。
(2)利用单一的ARIMA模型进行模拟时效果较好,但利用该模型进行预测时,有4 a的相对误差在10%以上,平均相对误差为7.94%;利用CEEMDAN-ARMA模型进行模拟时,相对误差均低于4.5%,平均相对误差为1.54%,模拟精度较好,利用该模型进行预测时,相对误差均在10%以内,平均相对误差为3.31%,远远低于10%,满足中长期预测的要求。
(3)CEEMDAN-ARMA模型的预测效果优于单一ARIMA模型的,将CEEMDAN分解的年径流量数据作为模型的输入数据可以有效地提高模型的预测精度。结合CEEMDAN建立混合预测模型,可以得到更准确、更稳定的预测结果,对水文时间序列预测的研究有一定的帮助,利用该模型能够為黄河流域水资源开发利用和水量分配、水库优化调度决策提供技术参考。
参考文献:
[1] 汤友成.现代中长期水文预报方法及应用[M].北京:中国水利水电出版社,2008:159-186.
[2] 赵雪花,桑宇婷,祝雪萍.基于CEEMD-GRNN组合模型的月径流预测方法[J].人民长江,2019,50(4):117-123,141.
[3] TORRES M E, COLOMINAS M A, SCHLOTTHAUER G, et al. A Complete Ensemble Empirical Mode Decomposition with Adaptive Noise[C]//IEEE International Conference on Acoustics. Shanghai: IEEE, 2011:4144-4147.
[4] HUANG N E, SHEN Z, LONG S R, et a1. The Empirical Mode Decomposition and the Hilbert Spectrum for Nonlinear and Non-Stationary Time Series Analysis[J]. Royal Society of London Proceedings Series A, 1998(454):903-998.
[5] WU Z, HUANG N E. Ensemble Empirical Mode Decomposition: A Noise-Assisted Data Analysis Method[J]. Advances in Adaptive Data Analysis,2009,1(1):1-41.
[6] 王文圣,丁晶,金菊良.随机水文学[M].北京:中国水利水电出版社,2008:56-57.
[7] 吴忠顶,吕梅斋,黄金莲.永康市1996—2010年病毒性肝炎流行特征分析[J].浙江预防医学,2012, 24(9):25-26.
[8] 高铁梅.计量经济分析方法与建模:Eviews应用与实例[M].2版.北京:清华大学出版社,2009:166-168.
【责任编辑 张 帅】
