基于人工智能的强化学习理论及其应用
2021-02-26钟伟岚
钟伟岚





【摘要】 近年来,人工智能研究领域中强化学习大受欢迎,它与监督学习有异曲同工之妙,也有许多的不同点可以区分。首先,监督学习需要在他人的督促下进行,而强化学习更多的依赖自身的管理。强化学习强调能够不是先设置目标,从周围数据中获得有关动作的反馈信息,然后再利用这些信息来优化模型数据。显而易见,强化学习具有广阔的前景。集多种环节于一体的复杂控制系统,具有非常经典的复杂问题,以本次论文研究的倒立摆为例。自然界有很多无规律的不稳定的物体,倒立摆系统可以通过控制手段,使不稳定的物体变得稳定,具有规律性。而在控制过程中,倒立摆系统也是一个验证各种控制理论的很理想的模型之一。它可以反映例如可镇定性,随机能动性以及鲁棒性一系列情况。近代以来,倒立摆系统广泛应用于我们的生活当中。卫星的运行、火箭的飞行都借助了倒立摆系统。因此,非常有必要对倒立摆系统进行研究,该系统具有无可取代的现实意义,以及深刻的工程意义。
【关键词】 强化学习 Q学习算法 倒立摆系统
引言:
众所周知,我们获得新的知识的主要途径之一就是学习,学习是人类聪明才智的体现。近年来人工智能领域在研究机器学习时,主要将研究的内容放在拟人化,目的是让机器的行为举止与人类无限接近,能够像人类一样主动吸收知识。机器学习比人类学习具有更多的优点,首先机器是不会感到疲惫的,不需要大脑对信息进行整合,通过数字编码就可以对信息进行储存复制,具有学习时间长,学习效率高的优点。[1]选择机器学习,可以让学习不会因为人类的寿命因素被影响,有利于知识的储备。
强化学习[2]机器学习的研究模块中,有一部分涉及到心理学理论和动物学习原理。首先从生物学的研究中构建反馈机制,借助该反馈机制采集周围环境对动作产生的评价信息,利用反馈的信号对学习模型参数进行更新。强化学习是人工智能学习模块中非常热门的一个板块,涉及到多个学科的内容[3]。
智能控制,人们希望通过对人工智能的研究,赋予机器人性化。详细的说就是使僵硬的机器被赋予学习的功能,通过机器的运转将信息储存,从而达到拥有类似于生物的运动控制技能[4]。到目前来说也取得了不少成果,许多机器人构建的认知模型中,很少涉及到运动平衡控制问题,但实际上,机器人的运动与运动平衡控制具有十分紧密的联系,所以本次论文研究将从运动平衡问题入手,结合相关认知问题进行探索[5]。在借阅许多学者前辈的研究材料发现,对倒立摆的控制问题的研究,一直是智能领域中热门板块。
倒立摆系统,该系统拥有非常多的特殊性,常见的有快速、多变量、严重非线性等。除此之外该系统是实验室中研究自控理论时所必备的设备,同样是经典的控制理论教学物理模型[6]。倒立擺采用线性设计,能够使用线性控制理论,而且还与系统识别等多方面皆有所关联,在控制理论研究中极具挑战性,一直被学者所关注。倒立摆系统在近代的许多科学领域都有应用,像直升飞机和卫星的运行等等都与倒立摆系统稳定控制有所联系。所以倒立摆系统的研究对于我们生活中的许多的新兴科技都具有十分重要的研究意义。笔者在对论文进行设计时,以运动平衡控制为出发点,将强化学习作为研究对象,倒立摆系统作为实验模型。在这些的基础上使用一种基于Q学习的强化学习系统以对倒立摆平衡控制展开深入探索,最终目的将学习能力赋予学习系统,以期该学习系统在日常运行时,能够自主学习新的知识,能够做出行走、跳跃各种动作,从而在各个领域中进行应用。
一、强化学习原理
1.1 强化学习原理与模型
众所周知,机器学习有许多的方向,强化学习是其中一种重要的方法。在我们的身边的诸多领域都与强化学习有着不少联系。在强化学习过程中,装载强化学习系统的智能体与周围的环境进行信息交流,再通过反馈信息不断更新策略,直到最终获得最优决策。在训练的过程中系统会通过不断的尝试并且在这个过程中得到相应环境反馈评价。系统会在这整个过程中不断的积累经验并且更新策略,最后可以使累积的奖惩值达到最大值。
很明显由强化学习的原理与模型可知强化学习不等同于自适应控制技术和规划技术。
强化学习也被认为是一种直接最适应最优方法,拥有自适应控制技术的环境反馈机制。但是,自适应控制技术是要处理参数问题,系统也要求能够在统计数据中获得结果。但强化学习去除了这些限制因素。实际上,无论是强化学习还是规划技术,他们二者之间在技术上是有明显区别的。以状态图的规划构造为例,如果一些复杂的状态图没有提前进行设计,就无法进行规划技术。但是强化学习只对环境的反馈信息进行记忆即可。除此之外,强化学习与规划技术相比更加强调与环境的交互。也由此可见,强化学习拥有更广阔的适用面。
1.2 强化学习系统的组成要素
强化学习的内容按要素分可以分为三类:策略、奖赏函数和值函数。在一般情况下智能体在给定的时间内产生相应的动作的方法就是策略(Policy)。 策略在强化学习中占据着举足轻重的地位,是智能体的核心。在一般情况下策略会给予智能体特定的答案,告诉在智能体应该采取哪些动作。奖赏函数(Reward Function)在强化学习问题中有着举足轻重的地位,一般表现在奖赏函数往往会对问题中的目标会起到决定性的作用。奖赏函数具有确定性和客观性等性质,这些性质会给予智能体正确的动作选择。最后再来介绍一下值函数(Value Function) ,从长远的角度来看,直函数可以用来判断状态的优劣,这种函数可以更有效的帮助学者研究强化学习的算法。
二、强化学习算法的应用
马尔可夫决策问题在人类科技进步的过程中扮演着重要的角色,而动态规划方法的提出可谓是马尔可夫决策问题里具有代表性的成果之一,Q学习算法和SARSA学习算法可以通过值函数的逼近来寻求最优策略,这两种算法可以说把时间差分和动态规划结合起来的典型。
2.1 SARSA算法
到现在,算法有了新的突破,理论研究也向前迈进一大步。Sarsa学习算法和Q学习算法可以算作是里面具有代表性的两个。
Rummery在1994 年第一次提出了SARSA这种强化学习算法,我们可以把SARSA学习算法看作Q学习算法的一种改进过的在线的(Online)形式。
2.2 Q学习算法
整体的算法流程如下所示:
对Q(s,a)初始化,在每一个情节都会进行以下的操作:
初始化状态s并且重复以下的操作一直到能够到达终态;
由贪心策略确定和执行动作a,状态得到转移到s'并且能够获得奖赏r;
对Q(s,a)进行更新,令s←s'。
列式如下所示:
(1)
其中C为常数,用高等代数的方法对该式子进行收敛判断,如果在贪心策略的方法下式子是收敛的,就可以将该式子认为是强化学习中最有效的算法是Q学习。
2.3 程序运行结果
我们分别运行SARSA算法,Q学习算法的有模型和无模型三个程序,得到结果如图1。
由图1可知,三个程序都顺利的验证了不同的强化学习算法按照目标验证了其在倒立摆平衡控制过程中有认知和学习的能力。
2.4 仿真结果分析与结论
在本次毕业设计中,我们主要会对Q学习算法的倒立摆实验进行波形的仿真与研究。在设置变量时,初始状态的倒立摆是随机数,而这个随机值常常被指定在一定的范围内。
从图2的仿真曲线中我们不难看出即使没有储备的知识条件,强化学习也可以让倒立摆系统具备自我的学习能力和记忆联想能力并且很快的得到控制。在图2中,不难看出这是强化学习系统的学习曲线,我们可以观察到的是平衡控制技能在强化学习系统的学习过程中在被逐渐掌握,直至最后强化学习系统成功的控制了倒立摆系统。接下来我们会通过不同的仿真波形探究在不同的条件下Q学习强化学习系统对于倒立摆系统平衡的掌握。
2.4.1 不同初始角度的控制效果
我们先改变摆杆的初始角度,再去观察系统控制性能是否会产生明显的变化。我们观察图3不难看出摆杆的角度初始角度分别为-5与10,角度不同,但是强化学习系统在时间为三秒的时候,都几乎达到直线状态,控制效果几乎没有变化。
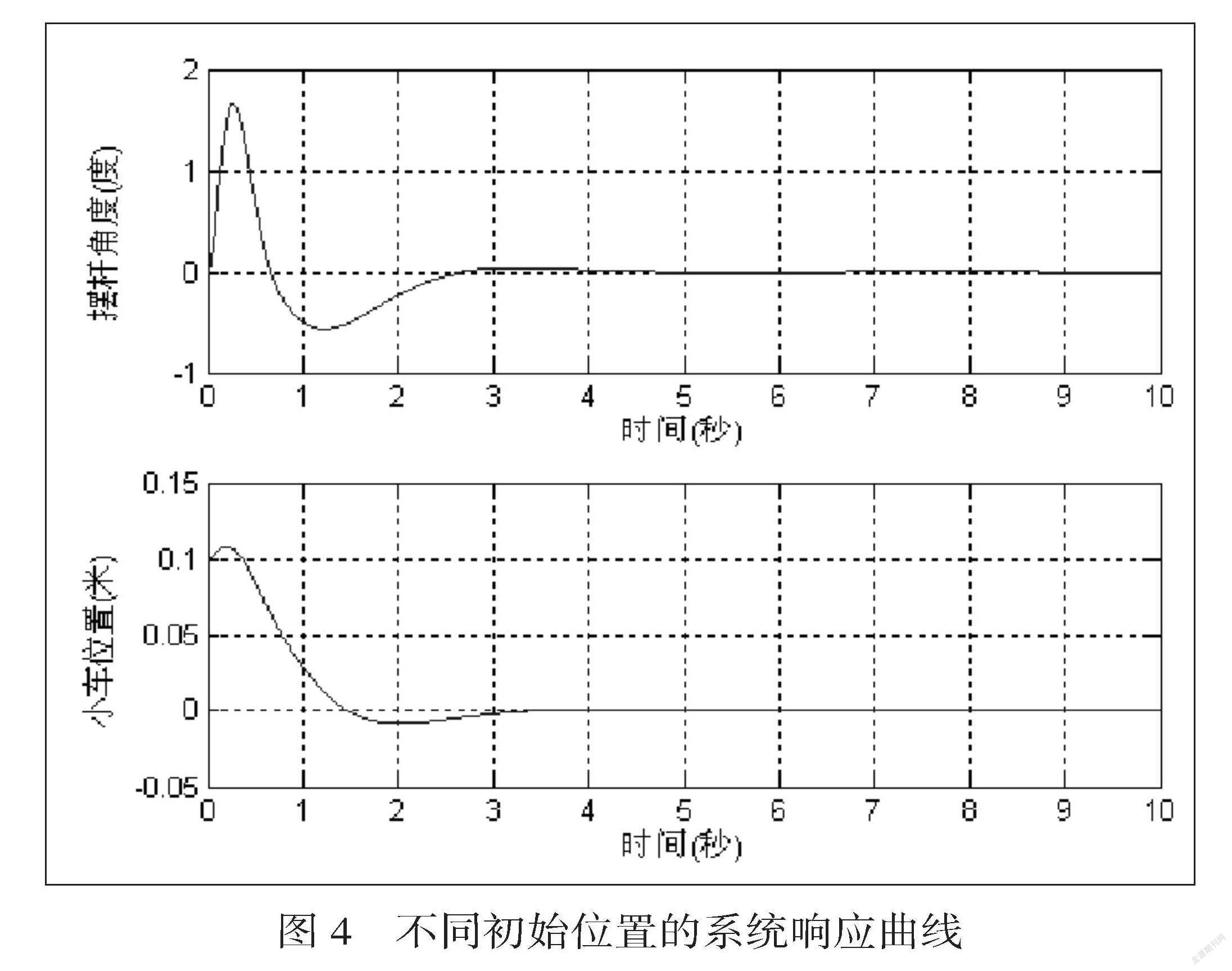
2.4.2 改变小车初始位置多次实验
在其他条件一致的情况下,我们改变小车初始位置变量,进行重复实验,探索系统的控制性能变化情况。我们从图4不难看出即使小车处在不同的初始位置,倒立摆的控制精度仍然可以达到要求并在短时间内再次返回到平衡状态。
2.4.3 有外界扰动的控制效果
在我们加入幅值不同的脉冲干扰后强化学习系统仍然可以顺利的完成对倒立摆的控制。在图5中不难看出在控制过程中的脉冲干扰无法对但强化学习系统产生明显的影响,证明了其具有良好的抗干扰能力。
三、结束语
强化学习采用了生物学习中的“行动——评价——改进”机制。这种评价机制的特点是将活动与环境相联系,将活动置于环境下,接收环境对于活动的评价信息,从而利用评价信息更新模型数据,优化决策行为。强化学习在目前已经成为了很多领域研究的热点之一,是一个多学科交叉的研究方向。在本次实验中,我们把倒立摆系统作为实验的载体,对几个强化学习算法做了研究与学习,并探究了强化学习在倒立摆系统中的控制和应用。
具体对整体的过程进行总结:1.通过查阅文献的方式来分析总结强化学习研究的现状。2.介绍分析本文中用到的相关强化学习的基础概念以及模型。3.在 Python 语言开发环境下利用 Pycharm完成了强化学习 SARSA算法和Q学习算法在一级直线倒立摆平衡控制的实验仿真,三种控制算法均可以完成训练以达到一级直线倒立摆的平衡控制。4.对实验仿真的波形进行提取分析,对实验进行总结与展望。
总之强化学习已经在默默影响与改变我们的生活,在机器人规划和控制和人工智能问题的求解等领域取得了成绩,拥有值得期待的未来与前景。
参 考 文 献
[1]李京,劉道伟,安军,李宗翰,杨红英,赵高尚,杨少波,郑恒峰.基于强化学习理论的静态电压稳定裕度评估[J].中国电机工程学报,2020,40(16):5136-5148.
[2]万里鹏,兰旭光,张翰博,郑南宁.深度强化学习理论及其应用综述[J].模式识别与人工智能,2019,32(01):67-81.
[3]刘洋,崔颖,李鸥.认知无线电网络中基于强化学习的智能信道选择算法[J].信号处理,2014,30(03):253-260.
[4]闫友彪,陈元琰.机器学习的主要策略综述[J].计算机应用研究,2004(07):4-10.
[5]张汝波,顾国昌,刘照德,王醒策.强化学习理论、算法及应用[J].控制理论与应用,2000(05):637-642.
