基于时间序列相似度的城市功能区识别研究
2021-01-26涂志德刘艳芳唐名阳王楠楠
李 莹,涂志德,刘艳芳,2*,唐名阳,王楠楠
(1. 武汉大学 资源与和环境科学学院,湖北 武汉 430079;2. 武汉大学教育部地理信息系统重点实验室,湖北 武汉 430079)
城市作为一个复杂的系统,存在着一定的秩序与模式,当各种社会活动开始聚集,就形成了居民区、商业中心等功能区[1]。城市功能区不仅承载着社会经济发展的各项职能[2],具有聚集和辐射能力,而且还是城市空间结构的重要体现[3]。识别城市功能区的空间分布特征,有利于发现城市空间特征、优化土地利用结构、促进资源的有效配置,对城市规划和经济建设具有重要意义。
传统的功能区识别主要是基于土地利用数据、遥感影像数据、实地调研、问卷调查、统计资料以及相关图书资料等,利用统计分析、计量模型或归纳演绎等方法进行识别,但这些数据和方法只能静态模拟城市现象,存在时效性不高、数据量大、成本较高、主观性较强的缺点,缺乏对居民这一城市空间活动主体的考量。随着大数据的发展,人们更加注重对居民行为数据的采集与分析,进而考虑居民活动对城市空间组织和结构的影响[4]。目前,研究者多基于签到数据[5]、手机基站数据[6]、轨迹数据[7]、公交刷卡数据[8]、腾讯LBS 数据[9]、GPS[10-11]等数据,结合POI 数据,采用聚类分析、因子分析等方法[12]进行功能区识别研究。研究单元多采用格网、Delaunay 三角网或OpenStreetMap(OSM)路网数据划分地块数据[13]。现有研究中多采用聚类分析方法对地理空间数据进行功能区识别[14],但缺乏对时间序列地理数据的研究[15]。尽管较长的时间序列数据能表达出更多的土地利用信息[16];但时间序列越长,数据维度越高,不仅会引发数据的维数灾难,而且很多距离度量会失效。因此,对于时间序列的相似性度量,研究者多采用降维的方法[17],虽然有研究利用动态时间扭曲(DTW)距离对时间序列数据进行聚类[18-19];但不够深入,并未考虑能分别降低时间复杂度和解决不对称问题的LB_Keogh 距离[20]和LB_Hust 距离[21]的适用性。目前鲜有研究探索基于时间相似性度量的聚类算法在识别功能区方面的潜力。
本文基于滴滴出租车订单数据,提取了上下车点;再采用OSM 路网数据,将研究区划分为3 185 个研究单元,并构建高维居民出行时空序列;然后将DTW 距离、泛化的LB_Keogh 距离以及LB_Hust 距离与传统的欧氏距离进行相似度刻画比较;最后采用PAM 算法进行聚类分析,将POI 数据作为辅助数据,进而识别城市功能区,以期为成都市城市规划提供决策依据。
1 研究区概况与数据来源
1.1 研究区概况
成都市作为四川省省会城市,位于四川省中部、四川盆地西部,下辖11 个区、4 个县、代管5 个县级市,即锦江区、青羊区、金牛区、武侯区、成华区、龙泉驿区、青白江区、新都区、温江区、双流区、郫都区、都江堰市、彭州市、邛崃市、崇州市、简阳市、金堂县、大邑县、蒲江县和新津县。成都市不仅具有优越的自然资源,还是国家历史文化名城,集经济发展与历史底蕴于一体,对促进西部城市的发展具有重要作用。本文选取的研究区为四川省成都市四环区域内,面积约为541 km2。
1.2 数据来源
1.2.1 滴滴订单数据
原始出租车数据来源于滴滴出行数据(https://gaia.didichuxing.com),时间为2016 年11 月14 日-11 月20 日,空间范围为成都市四环区域内,所有轨迹数据采集精度为2 ~4 s。每条订单数据包括订单ID、开始计费时间、结束计费时间、上车位置经度、上车位置纬度、下车位置经度和下车位置纬度。对原始数据进行上下车坐标提取等数据清洗后,得到有效订单数据总计1 628 134 条,数据格式如表1所示。

表1 订单数据格式
1.2.2 OSM 路网数据
路网数据来源于OSM(表2),范围为成都市四环区域内,共计12 442 条道路数据,其中一级道路909 条,二级道路741 条,人行道路1 092 条,非机动车道、小区内部道路以及未分级道路9 700 条。提取路网中双行道道路的中心线,去除过于细小的立交桥、转弯道和小区内部人行道后,对数据进行拓扑检查。由于沿道路分布的设施便于人们生活和工作,且人们的出行也往往以道路为参考,不同等级的道路将城市分割为不同的土地利用单元[22],因此本文采用真实路网划分研究区域,共计3 185 个研究单元,如图1所示。
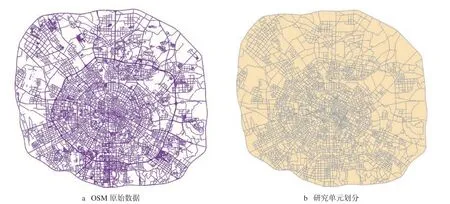
图1 OSM 路网数据
1.2.3 POI 数据
POI 数据从百度地图API 爬取,共计541 047 个POI 点。原始POI 数据属性包括名称、经度、纬度、地址、电话和类型(表3)。POI 一级类包括美食、酒店、购物、生活服务、丽人、旅游景点、休闲娱乐、运动健身、教育培训、文化传媒、医疗、汽车服务、交通设施、金融、房地产、公司企业、政府机构、出入口和自然地物19 个。为区分研究单元的主体功能,筛选出对研究单元影响较大的POI 类别[23-24],再对POI 点进行坐标转换和范围筛选,得到POI 分类结果(表4)。

表3 POI 数据格式

表4 POI 分类表
2 研究方法
2.1 乘客上下车时空序列构建
在基于时间序列数据发现特征和划分功能区的研究中,多采用密度数据[22,25-26]。本文首先提取上下车点以及每个研究单元(街区)的面积,并计算街区密度数据[24,27];再提取人流特征。式中,Dpick-up为上车人数;Ddrop-off为下车人数;街区面积的单位为km2;Dactiveness为人口活动密度;Dinflow为人口流入密度。

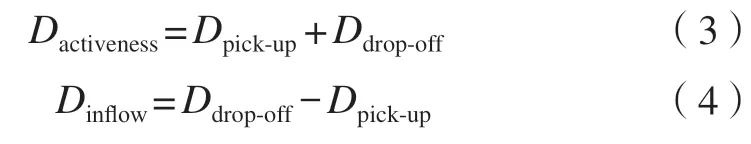
本文基于上述模型,获取了7 d 内共计168 h 的人口流动特征(图2),考虑到数据的有效性以及数据计算的复杂度,选取人口活动密度和人口流入密度特征构建了336 维时间序列表征居民出行特征。
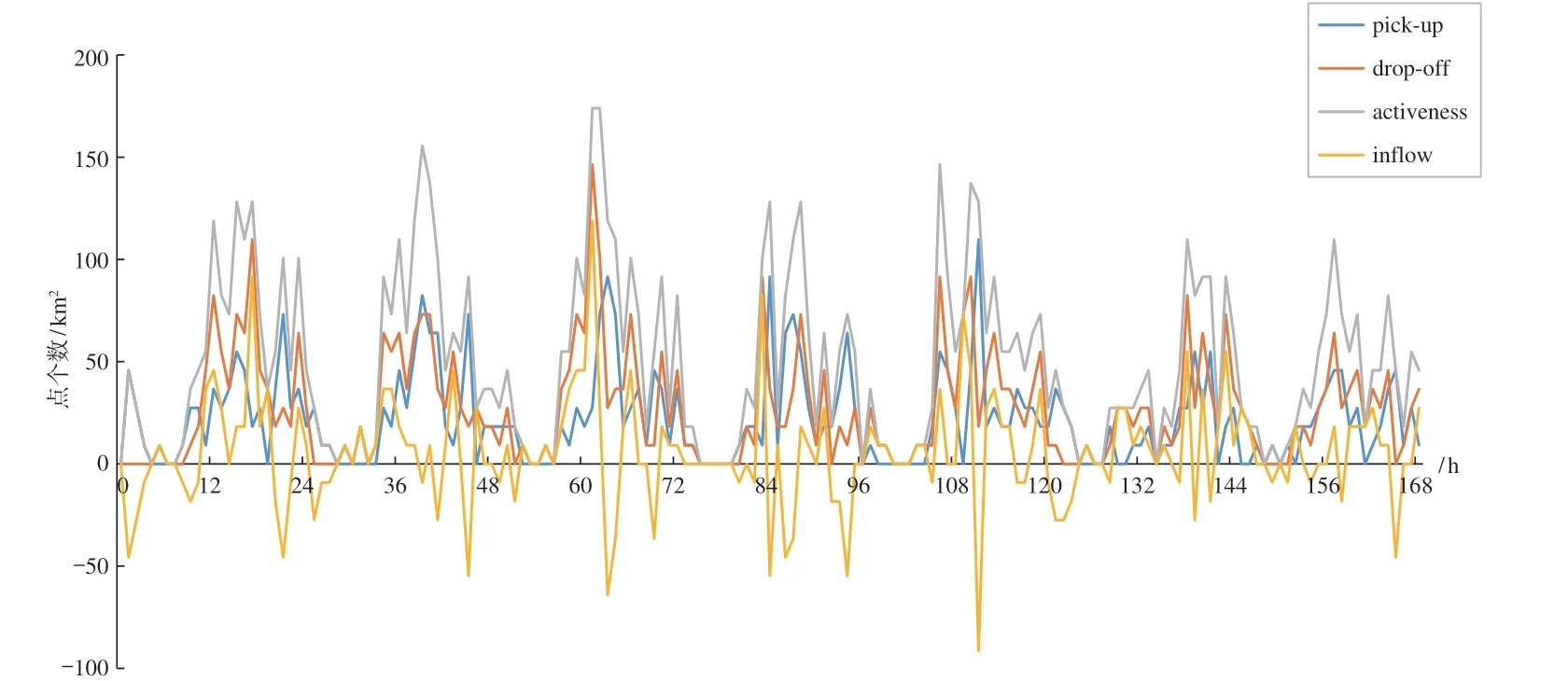
图2 区域样本时间序列特征
2.2 相似性度量
度量时间序列相似性的方法包括欧氏距离、DTW距离等[28]。与欧氏距离相比,DTW 距离对时间序列的突变或异常点不敏感,适用于时间序列的数据度量;相应地,其时间复杂度比欧氏距离高很多,在数据量很大时,将影响计算效率[29]。为减少DTW 距离的时间复杂度和不对称的问题,LB_Keogh[20]、LB_Hust[21]距离相继被提出。
2.2.1 DTW 距离
时间序列相似性的度量方法主要分为基于数据值度量和基于趋势度量两大类,DTW 距离属于基于趋势度量中波谱分析的一类[30]。DTW 是进行序列匹配的一种方法,最早应用于文档匹配中,允许数据在时间轴上的平移,两条时间序列保持形态相似即可[31]。本文对每两个街区单元的上下车构建时间序列X={x1,x2,…,xm},Y={y1,y2,…,yn}(m和n表示时间维度,均为336),并建立时间序列X、Y的距离矩阵:
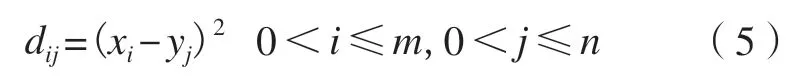
X、Y的弯曲路径为:
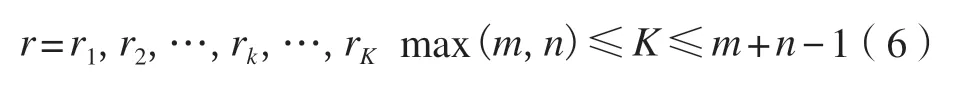
弯曲路径需满足3 个条件:
1)有界性。X和Y的弯曲路径必定从左下角出发,在右上角结束,即r1=d11,rk=dmn。
2)连续性。只能与自己相邻的点对齐,不能跨越某一点进行匹配,即rk=dij,rk-1=di'j'(i-i'≤1)。
3)单调性。在时间维上必须保持单调性,即rk=dij,rk-1=di'j'(i-i'≥0)。
DTW(X,Y)的求取过程就是寻找最短路径的过程,其最终路径为:
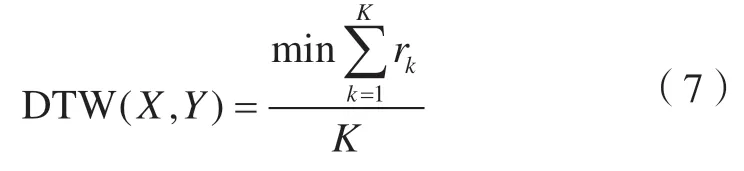
因此,本文定义累加距离作为两个序列的相似度,采用动态规划的思想来实现以下递归,则有:
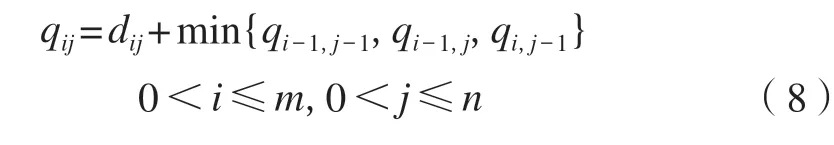
式中,qij为xi与yj之间的DTW 距离。
基于DTW 距离计算的时间比较效果良好,但计算复杂度与比较的时间序列长度成正比,在处理大型数据集时,时间复杂度很高。
2.2.2 LB_Keogh 距离
由于DTW 距离容易陷入病态弯曲,Keogh E[20]等将弯曲路径引入DTW 距离计算的方法中,于2005 年提出了LB_Keogh 距离。对于弯曲路径限制为w的时间序列的DTW 距离计算,定义了上界U和下界L。
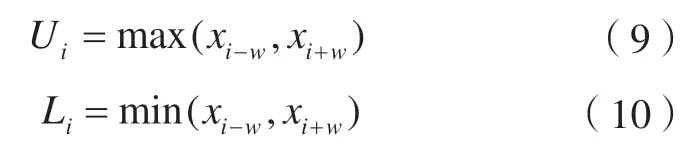
对于另一时间序列Y也有类似定义,X的上界函数U={U1,U2,…,Um},X的下界函数L={L1,L2,…,Lm},则两个时间序列的距离定义为:
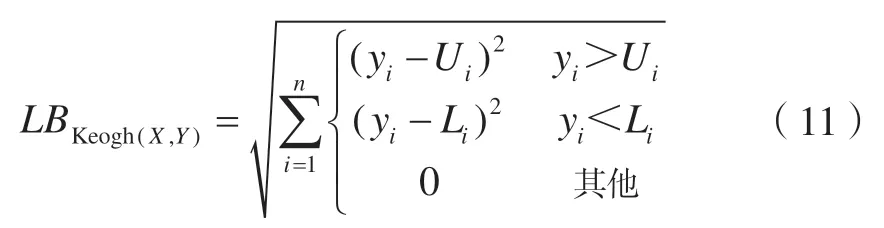
LB_Keogh 距离尽管降低了DTW 距离计算的时间复杂度,但不具有对称性,因此在与聚类算法进行结合时仍是一个问题。
2.2.3 LB_Hust 距离
LB_Keogh 距离延续了DTW 距离的非对称性,不仅增大了记录间距离计算的次数,而且在与聚类方法结合时,将影响初始点的选择,从而影响最终聚类结果。为解决LB_Keogh 距离的非对称性问题,LB_Hust距离于2006 年被提出[21],其核心思想是在时间窗口2w内,对两个时间序列进行泛化,求取相应的上下界函数,再基于上下界函数求取距离。对于时间序列X、Y, LB_Hust 距离为:
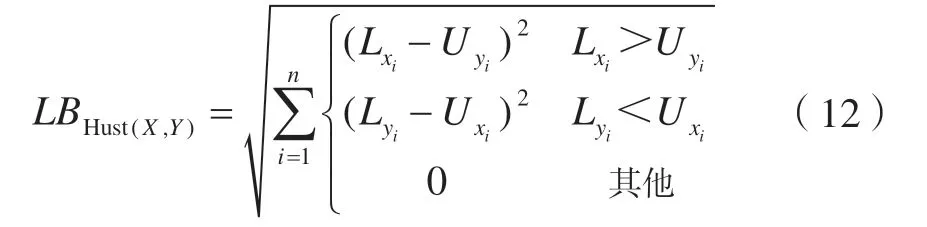
2.3 基于多种距离的PAM 聚类算法
目前的聚类方法主要分为基于划分的方法、基于分层的方法、基于密度的方法、基于网格的方法和基于模型的方法[32]5 大类。PAM 算法是围绕中心点的划分算法之一,也称为K-中心点算法[33],可对任何指定的距离度量执行集群,能允许灵活定义两个元素“接近”的含义[34]。同时,PAM 算法的簇中心点是簇内的某个对象而不是均值,从而对噪声和孤立点更鲁棒;在寻找最优解方面,利用的是贪婪搜索而不是穷尽搜索,从而提高了计算速度和精确度。PAM 算法中的损失值定义为数据集中所有点到中心点的距离之和。基于相似度距离的PAM 聚类算法的具体步骤为:①计算相似度距离矩阵,确定聚类数量k;②随机选取k个初始聚类中心,将其余点根据相似度划分至k个类别中,计算损失值S1;③用非中心点替代中心点,重新划分类别,计算损失值S2,若S2>S1,则不进行替换;④直至非中心点代替所有中心点后,计算所有总代价,其中总代价最小的聚类中心和聚类结果即为最终聚类结果。
2.4 聚类效果评价指标
对于聚类效果的评估,在文本聚类方面主要包括两种评价标准:一种是聚类结果中,团内越紧密、团间越分离越好;另一种是聚类结果与人工的判断结果越吻合越好[35]。本文将轮廓系数[36]作为评估聚类结果的一种标准,比对各距离聚类结果的相对好坏。将数据集划分为k个类别,对于其中的一个划分单元i而言:a(i)为i到所有所属簇中其他点的平均距离,b(i)为i与相邻最近的簇内所有点平均距离的最小值,则轮廓系数为:
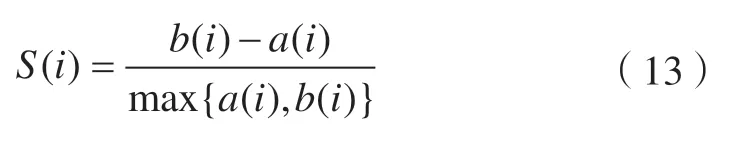
本文采用总体数据轮廓系数的平均值作为最终的轮廓系数。
2.5 POI 数据辅助分析
本文利用POI 频率平均密度(FD)来表示街区单元特性,但由于各类型POI 数据的数量不同,数量级引起的差异可能会掩盖土地实际的用途,因此通过富集指数进行判别[37-38]。FD的计算公式为:
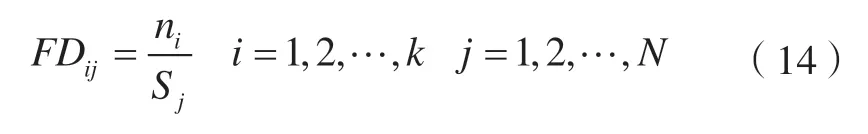
式中,假设POI 可被分为k种类型,ni为每种POI 在街区j内的数量;Sj为街区j的面积;FDij为第i类POI在第j个街区内的密度。
POI 富集指数的计算公式为:

式中,Ri,c为第c类别中的第i类POI 的富集指数;ni,c为第c类别中的第i类POI 数量;Nc为第c类别中的POI 总数;Ni为所有类别中的第i类POI 数量;N为研究区内所有POI 数量。
3 研究结果与分析
3.1 聚类总体结果与评价
本文采用轮廓系数来客观评价聚类质量的好坏,选取的聚类数为2~15 类,计算得到4 种距离的轮廓系数,受数据维度的影响,整体上的轮廓系数偏低。如图3 所示,在聚类数k=2 时,DTW 距离和欧式距离的聚类评分指标轮廓系数最大,超过0.6;在聚类数k=4,8,14 时,4 种距离的轮廓系数相差不大;在聚类数k<10 时,欧氏距离的评分基本小于其他3 种距离,尽管在聚类数k>10 时,欧氏距离的评分有所上升,但聚类结果仍不如DTW 距离和LB_Keogh 距离。值得注意的是,当聚类数2 <k<10 时,聚类结果最好的值大多出现在LB_Hust 距离中,在聚类数k=3 时达到最值,之后下降,直至聚类数k=7 时,出现第二个峰值。为精细刻画各功能区的不同特征,本文选取k=7时的基于LB_Hust 距离的聚类结果进行功能区识别以及人流特征分析。
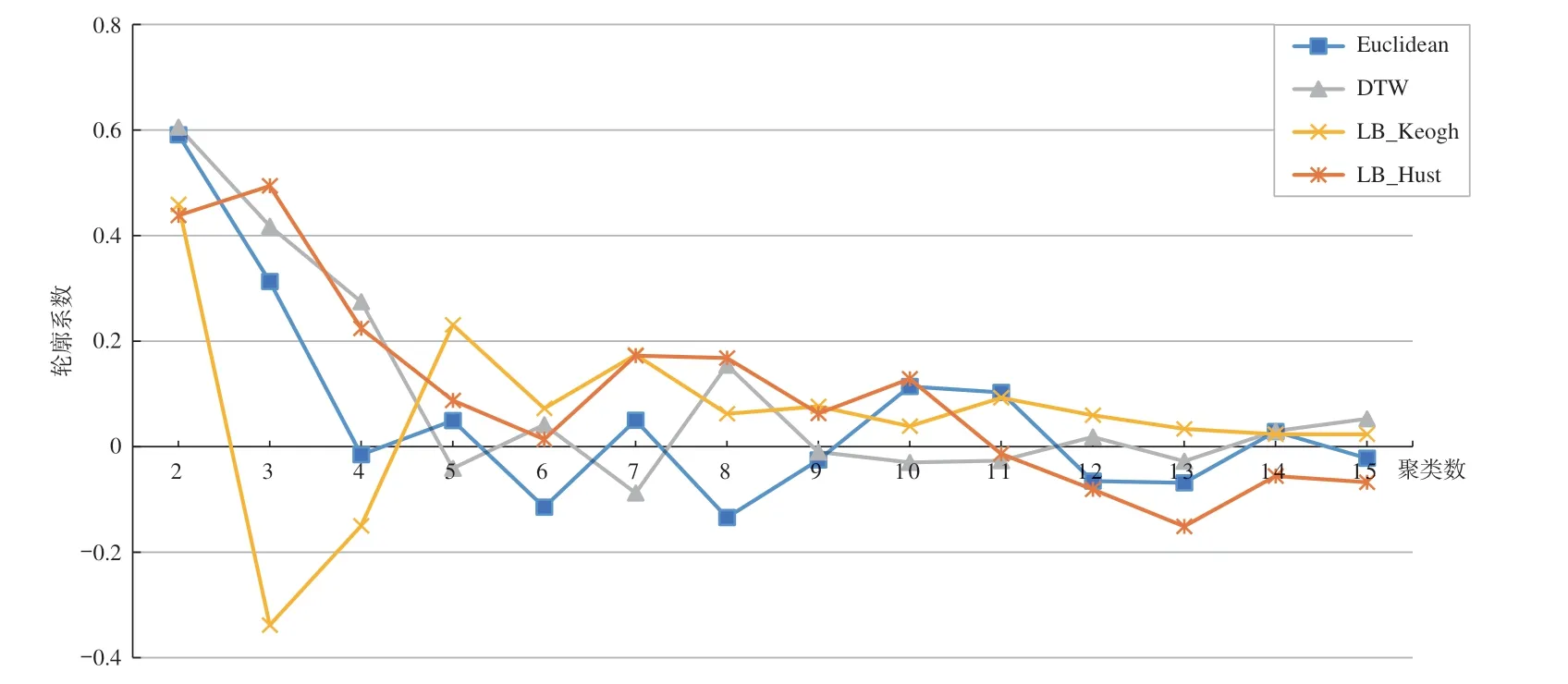
图3 不同聚类数下的轮廓系数评分图
另外,本文将基于时间相似度的PAM 算法与传统的K-means 算法进行了比较,选取聚类数k=7,10 的结果进行可视化(图4),结果表明,在聚类数增加的情况下,K-means 算法并没有识别出更多的特征区域,仅识别出中心区域的特征,而基于LB_Hust 的PAM 算法的区域划分则具有更好的分布性。
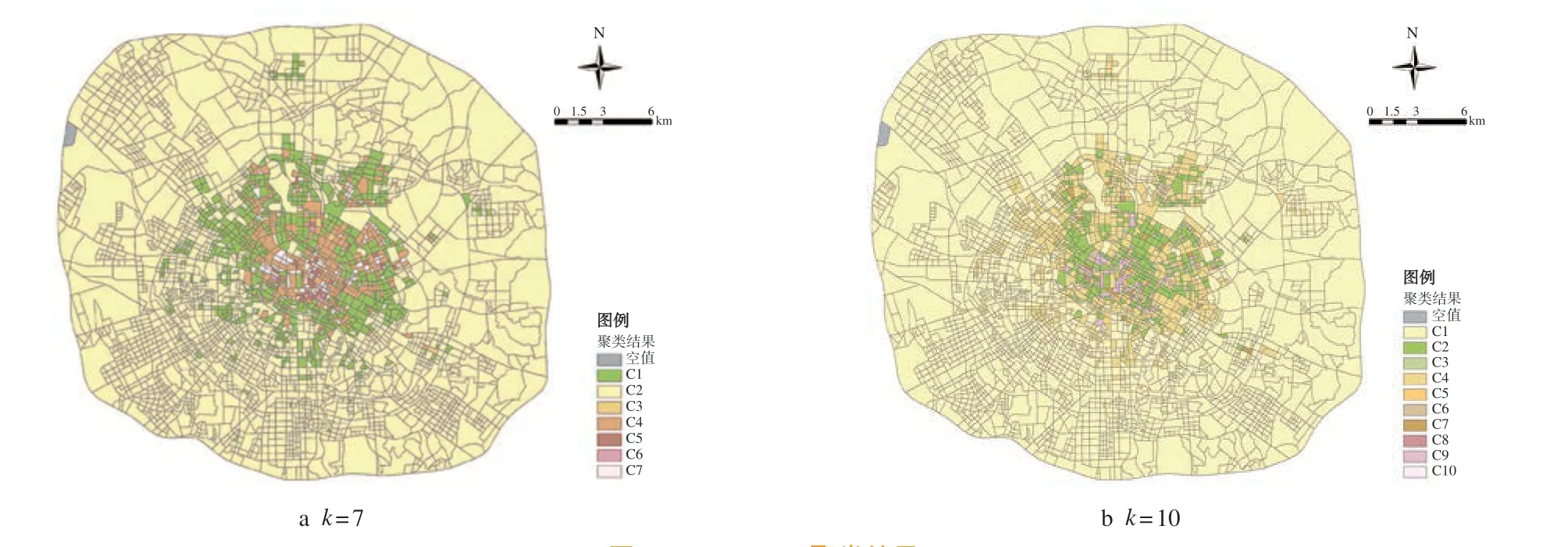
图4 K-means 聚类结果
为验证结果的准确性,本文将聚类结果进行空间化展示,随机挑选100 个街区进行精度验证(图5),结合遥感影像图、各种来源的信息(如新闻、评论、图片、广告等)推断实际情况,并与聚类结果进行比对,得到各类别识别的准确度(图6),识别准确度最高达到86%,平均值超过70%,表明基于该方法的功能区识别具有一定的可行性。
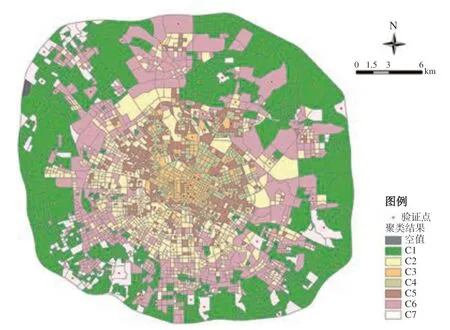
图5 聚类结果与验证点的空间分布图
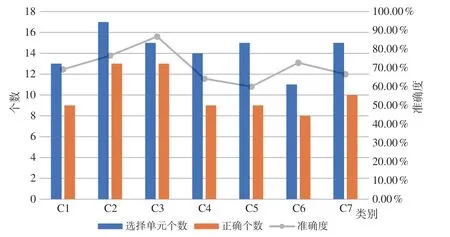
图6 功能区识别吻合度
3.2 功能区识别结果分析
根据上述方法划分得到7 类结果,本文统计了每个类簇包含的单元个数(表5)、POI 的FD和富集指数(表6),以及各类簇的人口活动密度(图7)和人口流入密度(图8)。总体来看,成都市四环区域内呈从中心区域向外围扩张发展的趋势,以天府广场为中心呈环状向外扩散。尽管各功能区的人流特征不同,但POI的分布密度有相似之处,购物类、餐饮类、交通类、商业类名列前茅,表明成都市四环区域内的购物、餐饮业、交通较为发达,商业要素发展较好,零售业居多,且生活服务、医院等基本设施服务分布较多,较为完善。
C1 是以文化景观和自然要素为主的功能区,与成都市中心城区的环城生态圈相符。各类POI 的FD最低,人口活动密度和人口流入密度也最低,人口聚集在9:00-17:00,主要位于城区外围,包括一些文化景点、自然景观为主的公园以及周边区域,成都新阵地高尔夫球场、凤凰山公园、成都植物园、皇恩寺陵园、四川丝绸博物馆、香地丝绸生态公园、明蜀王陵博物馆、锦城公园等囊括其中。
C2 是以居住为主的功能区,数量最多,包括学校宿舍区、居住小区和员工宿舍等。人口活动密度在9:00-20:00 较为密集,6:00-20:00 人口流出较多,峰值在7:00、9:00、13:00,居民在这3 个时间点乘车上班;在20:00 之后,人口流入密度达到正值,在这个时间段,居民下班或休闲娱乐后,回到居住区,包括西南民族大学学生公寓、四川师范大学电影电视学院、普天小区、紫薇社区、蓝天小区。
C3 主要是以商业为主、市政居住混合的区域,交通发达,位于成都市四环中心区域。人口活动密度量级最大,集中在8:00-18:00,极值出现在14:00;人口流入密度在8:00-10:00 为正值,人们在这个时间点到达商业区办公。同时,在其周边还有一些公寓、社区和职工宿舍,位于中心的人民广场及其周边的商业区也划分在内;成都火车北站、成都石羊客运站、天府广场、春熙路商圈、天府广场购物中心、四川省版权局、四川省公务员局、四川省扶贫和移民工作局等也囊括其中。
C4 与C5 具有相似的特征,但商业均不及C3 集中,是以居住为主、商业为辅的区域,其中商业以零售业居多,夹杂着医院、大学,位于成都市四环中心区域周边。C4 的规模大于C5,但都不及C3,C4 偏向金融,而C5 偏向娱乐生活,两类人口活动密度量级均很大,集中在18:00-21:00;同时,人口流出密度也较大,集中在8:00-16:00,四川省政府采购中心、鑫源公寓、憩园公寓、雅典国际社区、成都社区大学、成都权健医院和幸福商城等囊括其中。
C6 主要是居住、休闲娱乐的功能中心,人流聚集在8:00-21:00,人口流入密度不高,峰值在9:00-13:00;20:00 之后有人口流入,居民在进行休闲娱乐活动后回到居住区;周一至周日人口分布差别不大,包括熊猫生态公园、鲁能精品生活馆、东锦城购物中心、万科广场等。
C7 主要是一些人口密度很低的工业区域,主要位于中心城区外围,人口活动密度和人口流入密度均很低,8:00-18:00 的人口活动密度相对集中,13:00左右达到峰值,人口流入密度与其他类不同,包括睿建建筑工程机械有限责任公司、蛟龙工业港高新区、四川省新洲园艺有限公司、成都直升机博物馆、交通工程驾校训练基地等。
表5 各类簇单元个数统计
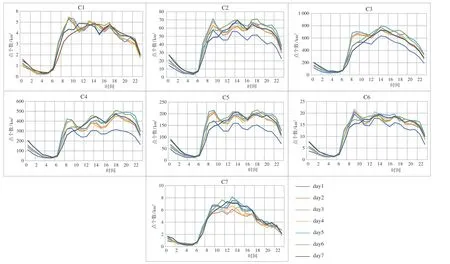
图7 各类簇人口活动密度图
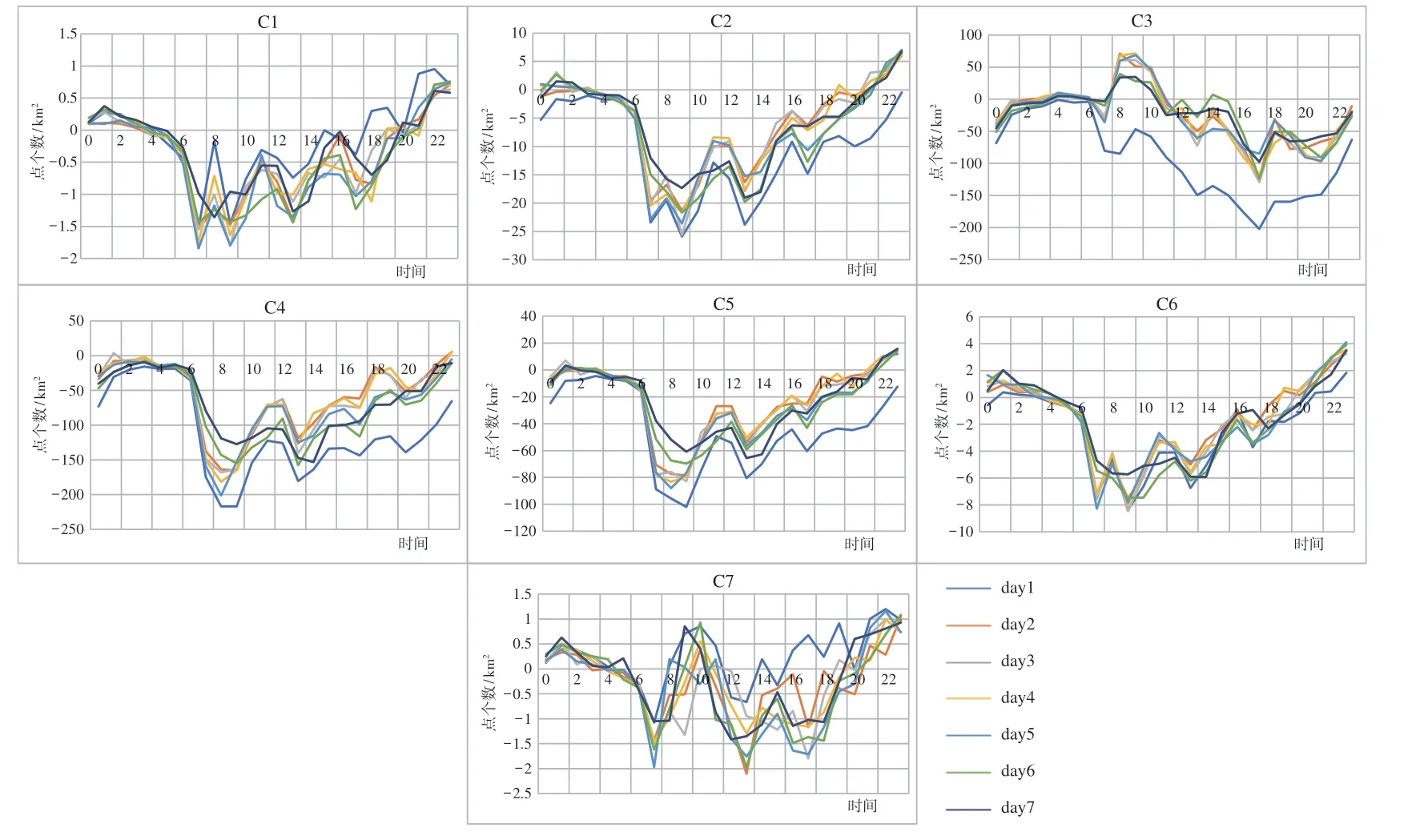
图8 各类簇人口流入密度图
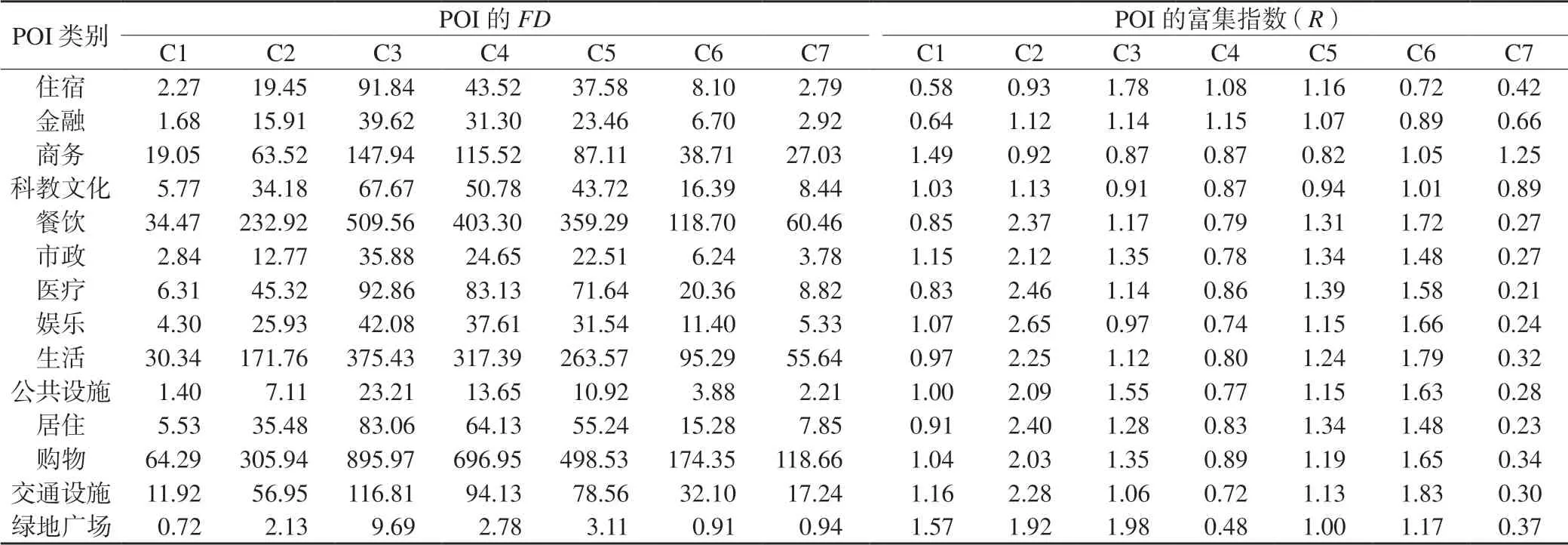
表6 功能区内POI 的FD 和富集指数
4 结 语
本文基于OSM 路网数据划分研究单元,利用出租车订单数据提取了乘客上下车的时间序列,采用DTW距离以及其泛化的LB_Keogh 距离、LB_Hust 距离代替欧氏距离作为相似度,运用PAM 聚类算法,结合POI 数据进行功能区识别。结果表明,在数据维度较高、考虑时间序列上的偏移时,传统的欧氏距离不再具有优势,采用基于LB_Hust 距离的PAM 算法,结合POI 数据进行城市功能区识别,能有效识别城市的空间结构,具有可行性。
相较于CHEN Y[22]等提出的方法,本文采用的基于时间相似度的研究方法在进行相似度计算时,降低了时间复杂度,不存在相似度矩阵不对称的问题,当数据量较大时,优势更加突出;相较于GAO Q[24]等的研究,细化了商住混合区域的特征,并验证了结果的准确性。本文验证了利用聚类分析对时间序列数据进行功能区识别的可行性,但还存在一些问题:在数据来源方面,出租车只能表征一部分有收入人群的出行特征,未来研究中,可结合定位数据以及其他交通大数据进行研究;另外,PAM 聚类算法受初始点选择影响较大,由于采取贪婪迭代的思想,在数据量较大时,计算的复杂度会更大,而高维数据包含大量分布复杂的噪声,如何将高维数据和聚类算法更好地结合起来,提高稳定性,还有待进一步研究。
