基于PCA-SVM的红枣缺陷识别方法
2021-01-25楚松峰赵凤霞吴振华
楚松峰 赵凤霞 方 双 吴振华
(郑州大学机械与动力工程学院,河南 郑州 450001)
红枣受到外部自然环境和采收运输的影响,表面会受到一定程度的损伤,产生黑斑、干条、破头等缺陷,这些缺陷影响着红枣的品质和等级。因而,红枣缺陷检测是红枣深精加工过程中的一个重要环节。随着种植面积和产量的提升,单纯依靠传统的人工分级,工作量大、产能低、成本高,已经不能满足实际生产的需要。
近年来国内外许多学者针对红枣缺陷检测进行了相应研究,且取得了一定的进展。赵杰文等[1]以河北金丝小枣为研究对象,利用红枣色调H的均值和方差特征,通过支持向量机对红枣油头、浆头和霉烂枣进行分类。由于提取的特征较少,只对霉烂果进行了分类,无法对干条、鸟啄等缺陷进行分类,分选的种类不足以满足实际生产需要。曾窕俊等[2]对裂纹枣进行了分类,通过帧间路径搜索的方法获得图像中单个枣的位置坐标并构建数据集,再通过集成卷积神经网络的方式,构建多个卷积神经网络分别进行分类,最终根据分类结果选择最优解。海潮等[3]根据红枣及其表面缺陷特征,提出在颜色空间中采用BLOB分析算法实现图像的分割及红枣缺陷的识别。该方法对干条缺陷识别率较低且速度较慢。
支持向量机(Support Vector Machine,SVM)在模式识别中有许多优势[4],针对红枣缺陷类别较多,多种多分类思想能够对红枣所有缺陷进行同时分类。缺陷类别多也决定了必须采集较多特征来反映红枣的整个表面信息,如何准确选择区分度较高的输入特征是SVM研究运用中的一个重点。主成分分析法[5](Principle Component Analysis,PCA)能够对提取的多维特征进行降维,找出描述原始目标对象的特征。基于以上分析,试验拟从实际工况下采集测试集,建立PCA-SVM的红枣缺陷检测模型,对红枣图像进行缺陷识别,能够在实际应用中保证高识别率的同时提高红枣缺陷识别效率,满足产能需求。
1 材料与试验平台
1.1 试验材料
新疆若羌干制红枣:以红枣表面是否存在黑斑、破头和干条缺陷进行筛选作为研究对象。
1.2 试验平台
红枣缺陷自动检测系统实验台如图1所示,包括输送装置和图像采集装置,其中图像采集装置由MER-503-36U3C型工业相机、日本Computer公司M0814-MP型工业镜头、LED条形光源等组成。调节光圈大小为2.0,快门速度设定为0.1 s,一次采集多个红枣进行处理。图2为采集的一个样本图像,该图像中包括了无缺陷枣和黑斑、破头、干条3类缺陷枣。得到图像后,首先需要进行背景去除,从图像中提取出单个枣,然后对单个枣进行特征提取、优化及分类识别。
2 红枣表面特征的提取及优化
2.1 特征提取
图像特征提取是数字图像处理的关键步骤之一,关系到分类器的效率与准确度[6]。常见的特征以属性不同分为形状特征、颜色特征和纹理特征,并称为图像的三大底层特征[7]。
通过分析红枣各类缺陷图像可知,形状特征对于红枣分类识别意义并不大,而具有平移、旋转不变性的颜色特征和描述了图像中灰度排列规则,能够体现图像灰度变化的纹理特征来表示红枣表面信息较为理想。
基于颜色矩提取红枣图像RGB 3个颜色通道下的均值、方差颜色特征分量,共3×2个特征分量;基于灰度共生矩阵(Gray Level Co-occurrence Matrix,GLCM)计算色调H、饱和度S下的能量、对比度、相关性和熵纹理特征分量,共2×4个特征分量。即提取的特征分量总计为14个。

1.上料机构 2.下料及排序机构 3.鼓型输送轴 4.上检测机构 5.下检测机构 6.分类箱 7.喷吹机构 8.收集箱图1 红枣缺陷自动检测系统试验台Figure 1 Jujube automatic defect detection system test bench

图2 红枣图像样本Figure 2 Jujube image samples
颜色矩是一种能够有效表示图像颜色分布的颜色特征[8]。包括一阶矩(均值μi)、二阶矩(方差σi)和三阶矩(偏斜度si),其数学定义:
(1)
(2)
(3)
式中:
μi——灰度均值;
σi——灰度方差;
si——灰度偏斜度;
N——像素个数;
Pij——第i个颜色通道中第j个像素的值。
GLCM算法由Haralick等提出来描述物品的纹理状况,反映的是图像灰度关于方向、相邻间隔、变化幅度的综合信息[9]。常用的有以下4个纹理特征:
(1) 能量:矩阵各元素的平方和。反映了图像灰度分布均匀程度和纹理粗细程度。
(4)
式中:
f1——能量;
L——灰度级数。
(2) 对比度:矩阵主对角线附近的惯性矩。反映了图像的清晰度和纹理沟纹的深浅。
(5)
式中:
f2——对比度。
(3) 熵:体现了图像纹理的随机性。
(6)
式中:
f3——熵。
(4) 相关性:反映了图像局部灰度相关性。
(7)
式中:
f4——相关性;
P(i,j)——灰度共生矩阵的第i行、第j列的元素。
2.2 特征优化
在提取红枣特征时,尽可能多地提取了不同空间下的颜色和纹理特征,以期提高分类器的识别率,但这些特征会存在一定的信息交叉,同时特征数量过多,加重分类器设计时的复杂性,影响分类器的性能。
采用PCA算法对提取的14维颜色和纹理特征进行优化降维[10],选取能够有效描述原始目标对象的特征,在保证高识别率的前提下,提高缺陷识别效率。具体过程:
(1) 初始指标数据的标准化:采集样本,构造样本阵,对样本阵元进行标准化变换:
(8)
式中:
Z——标准化矩阵;
n——样本个数;
Xij——第i个样本的第j维特征。
得到标准化矩阵Z。
(2) 对Z求相关系数矩阵:
(9)
式中:
R——相关系数矩阵。
(3) 解样本相关矩阵R的特征方程|R-λIP|=0得p个特征根,确定主成分。
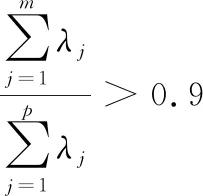
(4) 将指标变量转换为主成分。
(10)
式中:
Uj——第j主成分。
(5) 对主成分进行综合评价:对m个主成分进行加权求和,即得最终评价值,从预选特征中求得主成分作为新的特征代入算法,用于模型的训练及分类。
3 基于SVM的缺陷识别
以支持向量机作为分类模型,将优化降维后的特征作为支持向量机输入特征。高斯核函数是一种对应非线性映射的核函数,可以处理非线性可分问题,因此采用高斯核函数、最优核函数参数g以及惩罚系数c对模型进行训练,用训练后的模型对红枣进行缺陷识别,提高缺陷识别准确率。
3.1 支持向量机
SVM是一类按监督学习方式对数据进行二元分类的广义线性分类器[11]。以学习样本求解的最大边距超平面为决策边界,得到以下优化目标:
(11)
式中:
n——样本个数;
i——样本索引;
xi——训练样本;
yi——样本类别,yi∈{-1,1};
ω、b——主问题参数;
C——惩罚因子;
ξi——松弛变量。
针对目标求解最优化问题,构造拉格朗日函数:
(12)
式中:
λi、μi——拉格朗日乘子。
分别对主问题参数求偏导,得:
(13)
将式(13)代入拉格朗日函数[式(12)]中,得到:
(14)
得到决策函数为:
(15)
对于样本点线性不可分的情况,需要将二维线性不可分样本映射到高维空间中[12]。映射高维空间后维度增加,加重计算的复杂度,因而引入核函数,在原始样本映射之前计算其内积。选取高斯核函数作为SVM核函数进行训练识别,其计算公式:
(16)
式中:
‖xj-xi‖——向量间的距离;
β——给常数。
3.2 多类分类思想
红枣缺陷识别,需要对其黑斑、破头、干条以及正常枣同时分类,涵盖类别较多,因而需要构造多分类SVM,对4类枣进行准确高效的划分。多分类SVM是在二分类模型的基础上推广到M类的分类思想[13]。针对红枣缺陷类别较多,选用一对一法[14]进行多分类模型的构造。具体步骤:
对于给定含N个样本、M个类的训练集X。通过找到决策函数y=f(x),用于预测测试样本的类别。对于第i类和第j类数据,训练一个二分类SVM求解二次规划问题:
(17)
式中:
K——i类和j类样本数之和;
t——i类和j类并集中样本的索引;
yt——样本类别,yt∈{i,j};
ωij、bij——主问题参数;
C——惩罚因子;
ξtij——松弛变量;
Ф(X)——输入空间到特征空间的非线性映射。
然后求解式(17)的对偶问题。

(18)
式中:
xt——训练样本;
xnew——待预测样本;
K(xt,xnew)——核函数。
式(18)用于判断数据是属于i类还是j类。
对于新数据,采用投票策略进行分类,每个二分类SVM都会对测试样本进行预测,通过预测的结果对所属类别进行投票,票数最多的类别即对测试样本的决策。
3.3 交叉算法寻优
将原始样本分为n份,依次取每一份作为测试样本,剩余n-1份样本作为训练样本训练分类器对测试样本进行分类,一次循环后,对于某一组给定的参数对(c,g),共得到n个识别率,求取n个识别率的平均值,作为该参数对应的性能指标,当遍历了所有可能的参数对后,比较相邻参数对的性能指标,由此得到最优惩罚系数c和核函数参数g,作为SVM的参数。
4 试验结果和分析
构造支持向量机分类器,首先需要提取训练集的特征,作为支持向量机的输入对模型进行训练。以黑斑、破头、干条和无缺陷枣4类干制红枣作为试验对象,每类采集15个作为训练集样本。图3为无缺陷红枣训练集样本图像。
特征提取前,对图像进行预处理,去除输送带背景,并分离出每个红枣。首先将训练集样本图像转换至HSV颜色空间,得到图像的S分量图像(如图4所示);对S分量图像运用直方图进行阈值分割,将背景区域与红枣区域分割开,然后进行腐蚀、膨胀、填充和形态转化等处理,消除背景干扰;最后进行连通域分析和特征提取,得到去除输送带背景的红枣区域图像,如图5所示。
分离得到每个红枣区域后,对红枣进行特征提取。按2.1所述,分别基于颜色矩和灰度共生矩阵提取RGB 3个颜色通道下的均值、方差共6个颜色特征分量;色调H、饱和度S下的能量、对比度、相关性和熵共8个纹理特征分量,总计14个特征。
为了在14个原始特征集中初步确定能够保持样本分类能力的特征子集,对训练集样本分别提取4类红枣在每一维特征下的特征值,得到每个特征下每一类红枣的特征值范围,并进行排列,结果如图6所示。在同一特征下,假设A类枣的特征值范围和其他类枣的特征值范围没有重叠,说明该特征对于A类枣具有较好的区分度,将其选为支持向量机的输入特征。由图6可知:图像R通道下的均值和方差特征,色度H分量下的能量、熵和对比度特征;饱和度S分量下的能量、相关性和对比度特征,共有8个特征组成了最优特征子集X。

图3 无缺陷红枣训练集样本图像Figure 3 Sample image of the defect-free jujube training set

图4 HSV空间内的S分量图像Figure 4 S-component image in HSV space

图5 去除背景后的红枣区域图像Figure 5 The complete jujube region image without background
运用SPSS软件对红枣特征子集X进行PCA分析,计算结果如图7所示。由图7可以看出,P=4时,特征值对应的累计贡献率已达93.26%,能够代表原始数据具有的信息。因此,取前4个主成分组成向量Y作为红枣图像的特征向量代替原特征向量X,作为支持向量机的输入特征。
利用PCA对训练集样本特征矩阵降维处理后,得到了4个主成分,将其转化为PC4数组矩阵,归一化处理后作为支持向量机的输入。支持向量机内核选用高斯核函数,分类方法选用一对一法,惩罚参数c=0.05,核函数参数g=0.05作为支持向量机模型参数对测试集进行识别。
测试集:无缺陷枣90个,黑斑、破头和干条枣各30个,共180个测试样本混合后,放置于试验台中,在同一环境下采集5幅图像,每幅图像包含36个枣,得到的测试结果见表1。图8为对一幅红枣图像样本缺陷识别的结果。
由表1可以看出,运用PCA对提取到的红枣表面特征进行优化处理,将降维后的特征矩阵应用到支持向量机分类器的训练中,通过调整支持向量机各项参数,能够得到综合识别率为97.2%的分类结果。其中,破头枣和干条枣的识别率较高,可以达到100.0%和96.6%。与文献[3]提出的采用BLOB分析算法进行红枣缺陷识别得到的破头枣准确率98.3%、黑斑枣准确率92.5%相比,文中提出的方法缺陷识别准确度高,同时对目前现有文献鲜有研究的红枣干条缺陷进行了研究。

1、2、3、4分别表示色度H分量下的对比度、熵、能量和相关性;5、6、7、8分别表示饱和度S分量下的对比度、熵、能量和相关性;9、10、11、12、13、14分别表示RGB三通道下的方差和均值图6 4类红枣不同特征的对比图Figure 6 Comparison chart of different characteristics of four types of red dates

图7 贡献率与累计贡献率图Figure 7 Contribution rate and cumulative contribution rate graph
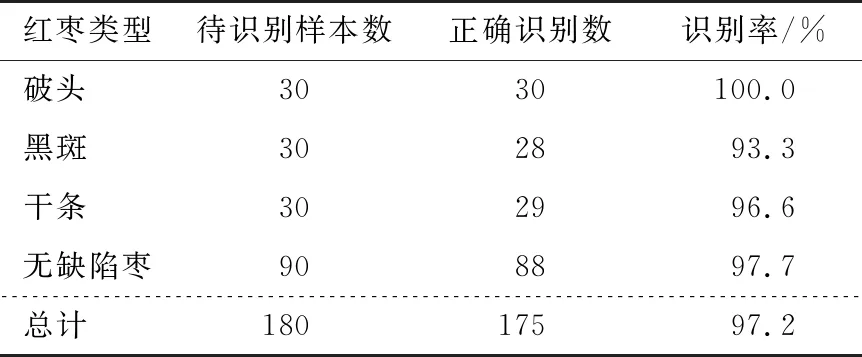
表1 PC=4的SVM模型测试集识别结果Table 1 PC=4 SVM model test set recognition result

图8 缺陷识别结果图Figure 8 Defect recognition result image
在缺陷识别效率方面,采用PCA进行了特征降维处理,减轻了分类器的计算复杂度,缩短了缺陷识别时间,平均一个枣识别用时15 ms(运行环境是Intel酷睿i5 8G处理器的计算机硬件平台)。
由表1可知,该模型对黑斑枣的识别率只有93.3%,其主要原因是由光照导致处于边缘部位的红枣颜色较深,黑斑枣表面的黑色病害区域不明显,从而产生一定的误差,后续将从光源的布置等方面对其采集装置进行改进。
5 结束语
为了提高红枣缺陷识别的准确率和效率,提出了一种基于PCA与SVM的红枣缺陷分类方法,利用PCA来对多维特征矩阵进行优化降维以获取低维特征矩阵。然后通过将降维后的优化特征矩阵应用于SVM分类器来实现对红枣4类缺陷的分类训练。结果表明,通过运用PCA对SVM输入特征进行优化处理,能够在保证红枣缺陷识别准确率高的同时,提高模型识别效率。但模型对黑斑枣的识别率较低,后续将针对黑斑缺陷对图像采集装置和算法模型进行优化改进。
