研究客户声音反映问题溯源分析效率提升的新方法
2021-01-21黎伟健叶天宽胡莉琼朱凯亮
黎伟健,叶天宽,彭 涛,胡莉琼,朱凯亮
1 研究背景
1.1 背景介绍
互联网的高速发展引领我们进入了一个信息量爆炸性增长的大数据时代,特点是数据量大、速度快、类型多,一些已经较为成熟的数据分析处理技术。运用这些技术对行业数据进行分析,实现海量的数据中,高效筛选和定位关键信息,并对此进行深入分析,对提高行业的整体运行效率以及增加行业利润都起到极大的推动作用。
1.2 提出问题
1)数据源渠道单一。获取客户反馈的声音主要是热线客服渠道。
2)数据存在滞后性。客户投诉由各子公司处理,处理后统一上传至集团客服系统,客服系统T+1天再传送至专业公司,因此数据存在滞后性。
3)依靠传统的分析方法。目前对于客户投诉的分析依靠传统人工分析,耗时约7.6分钟/件投诉。2019年1月—3月日均投诉量8 336件,按照30%对投诉分析有价值的有效单量计算,日均2 501件有效详单,单凭人工分析需花费19 006分钟(相当于40个人天工作量),通过逐一查看投诉详单内容,总结客户投诉要点。如连续2~3天对于同一问题的客户投诉量持续较高,才能触发投诉预警,引起业务侧关注并着手解决。
1.3 技术查新
目前在移动通信行业通过客户评论或投诉分析挖掘客户关注热点的应用研究较少,客户评论或投诉分析较多应用在电商、新闻行业,因此可借鉴其他行业的分析方法开展。
2 设定目标
为满足实际需要,将目标定为:客户声音反映问题溯源分析效率提升至60分钟/千件。
3 提出方案并确定最佳方案
3.1 提出可行方案
对历史客户声音的内容及分析环节进行梳理,并将解决方法绘制成亲和图,如图1所示:
方案一:基于正则表达式的分析方法。正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。该方案通过预先准备好的业务相关关键词清单,利用正则表达式获取相关客户声音信息,并结合业务特点得出原因分析结果。
方案二:基于关键词模型的分析方法。在自然语言处理领域,处理海量的文本文件最关键的是要把用户最关心的问题提取出来。不管是基于文本的推荐还是基于文本的搜索,对于文本关键词的依赖也很大,关键词提取的准确程度直接关系到推荐系统或者搜索系统的最终效果。利用NLP技术构建关键词模型,并根据算法自动提炼出客户声音的关键词内容,结合业务特点得出原因分析结果。
3.2 方案评估
从分析效果、维护成本方面进行评估,最终选择了关键词模型方案。
3.2.1 分析效果
对于两个方案的分析效果,对离线数据进行模拟实验。
结果显示,对同样的客户投诉内容,方案二的分析效率更高(见表1)。
3.2.2 开发维护工作量
对于开发维护成本,对两个方案进行预估。
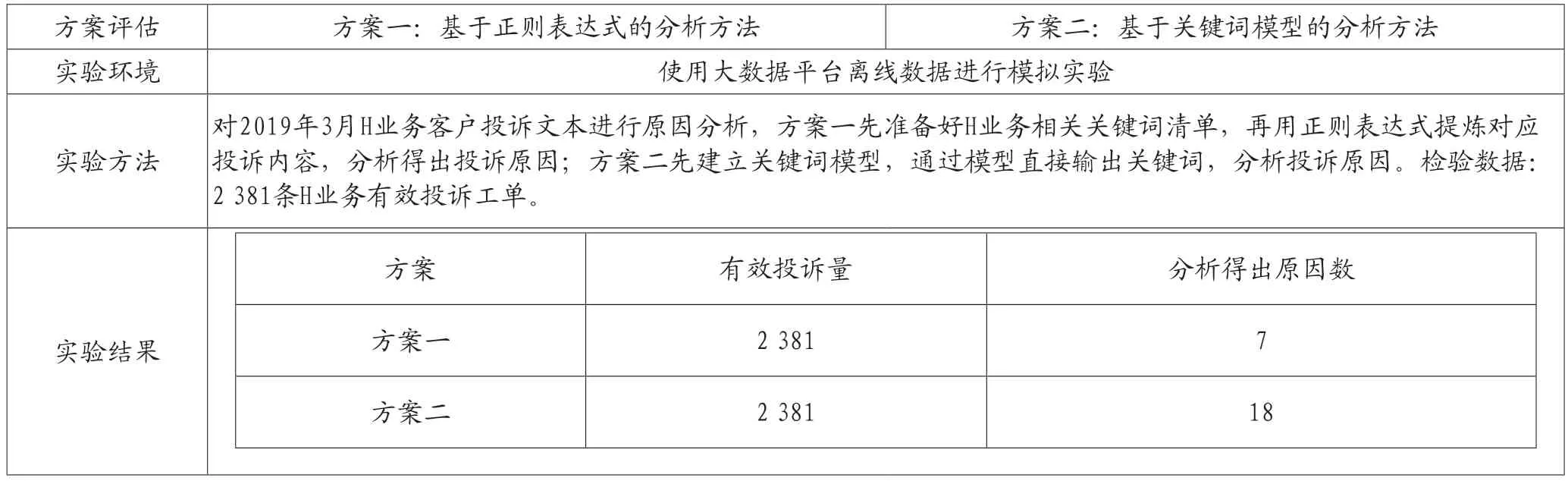
表1 两方案的离线模拟实验

表2 两方案的成本预估结果
根据成本预估结果(见表2),方案二开发维护工作量较小,对应的人力成本较少。
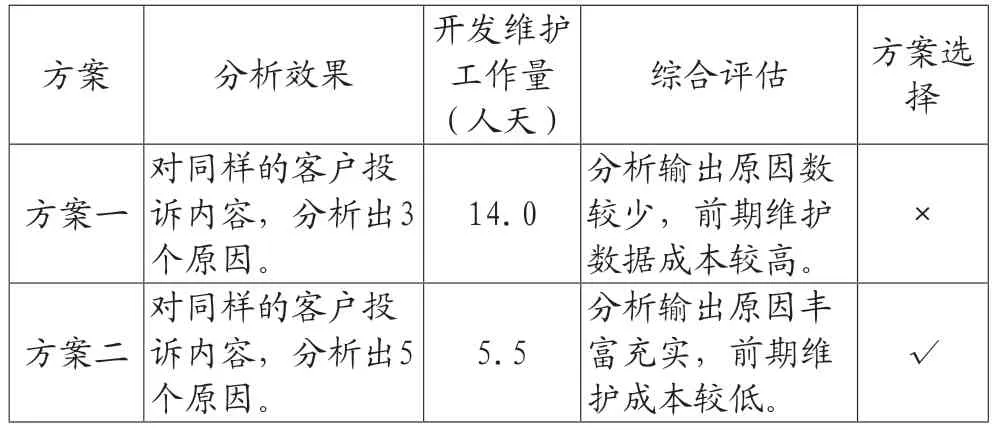
表3 可行性方案评估
由可行性方案评估表(见表3),客户声音分析效率提升的最佳方案是方案二:基于关键词模型的分析方法。
3.3 方案选择
3.3.1 分析数据源选择
参评方案:
客户在使用产品过程中,使用意见可以通过热线传统渠道反馈、互联网渠道反馈,这些客户声音是客户主动参与,内容真实度可靠、留言量大,评论涵盖面更广,既有负面批评,也有正面肯定,甚至是改进建议,对提升产品品质和服务质量具有较大参考意义。因此传统渠道、网络渠道是客户声音反馈的主要渠道,两者应同时纳入分析源考虑范围。
方案评比:
1)热线传统渠道:目前主要为全网投诉工单、在线交互文本、热线语音(见表4)。
2)创新探索网络渠道:主要有论坛、应用商城、微博等渠道,这些渠道数据需主动开发网络检索代码获取所有用户评论(见表5)。
因此对比之下,传统热线渠道选择全网投诉工单,互联网渠道的客户声音选择论坛。
3.3.2 数据库类型选择
参评方案:
当前数据库分为关系型数据库和非关系型数据库。
方案评比:

表4 传统热线渠道

表5 创新互联网渠道
Microsoft SQL Server数据库是关系型数据库,它的二维表结构是非常贴近逻辑世界的一个概念,关系模型相对网状、层次等其他模型来说更容易理解,通用的SQL语言使得操作关系型数据库非常方便,同时具备丰富的完整性大大减低了数据冗余和数据不一致的概率,易于维护。因此,选择Microsoft SQL Server作为数据库对象(见表6)。

表6 数据库对比
3.3.3 分析算法选择
参评方案:
文本分析算法有TextRank、TF-IDF等算法,使用不同方法对最后分析效率有直接的影响,衡量好坏的标准是关键词重复率。为此,利用2种算法分析投诉工单、论坛评论,对比关键词重复率。
方案评比:
分别对两个算法进行试验(见表7)。

表7 TextRank与TF-IDF算法对比
3.3.4 输出形式选择
参评方案:作为模型输出结果,关键词的输出形式对分析原因有重要影响,针对词云和关键词清单这两种输出形式进行对比(见表8)。
方案评比:
1)词云:“词云”就是通过形成“关键词云层”,对系列文本中出现频率较高的“关键词”的视觉上的突出。
2)关键词清单:这是一种将一系列关键词按一定规则排序的词汇列表,一般以电子表格形式呈现。

表8 词云与关键词清单对比
3.3.5 确定最佳方案
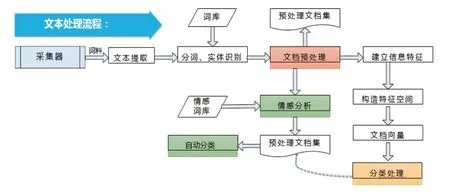
图2 文本处理流程
4 实施对策
制定实施对策表,如表9。
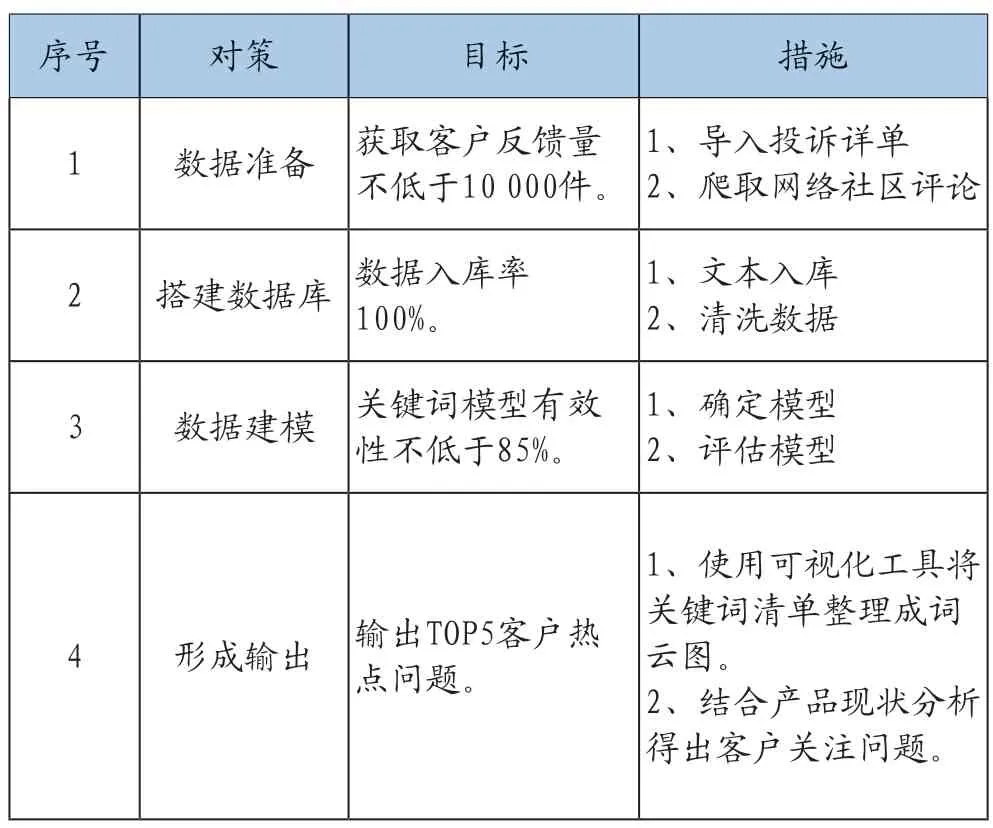
表9 制定实施对策表
5 按照对策表实施
5.1 实施一:数据准备
实施项目:通过数据平台下载客户投诉详单、编写脚本检索网络社区用户评论。
实施情况:
1)投诉详单获取。从数据平台下载1-8月H业务投诉数据,共768 292单。
2)论坛评论检索。使用Python编写H业务百度贴吧等网络检索脚本,对H产品1-8月客户评论文本信息进行批量检索,共获取1 214 467条评论。
目标确认:
共获取1 982 759件投诉详单和网络社区的评论,达成分目标。
5.2 实施二:搭建数据库
实施项目:将数据导入数据库,实现100%入库。
实施情况:
1)数据入库。开启Microsoft SQL Server服务,创建数据库YEW****_7002,并在数据库下新建2张表,分别是客户投诉表HL****XY91_DTL和网络社区评论表H****XY3_comm,表结构分别如下:为保证分析有效性,筛选有效投诉工单内容(剔除空白值)和网络社区客户评论(剔除字符数<15的评论),使用SQL Server数据导入接口将两张表导入到数据库中,成功导入行数分别是498 821、912 034。
2)清洗数据。通过Python从SQL Server读取两张表文本,使用jieba工具包对中文文本自动切词,拆分成独立词汇,再使用停用词表进行无效词过滤,实现文本清洗。
目标确认:对两张表入库情况进行统计,情况如表10。
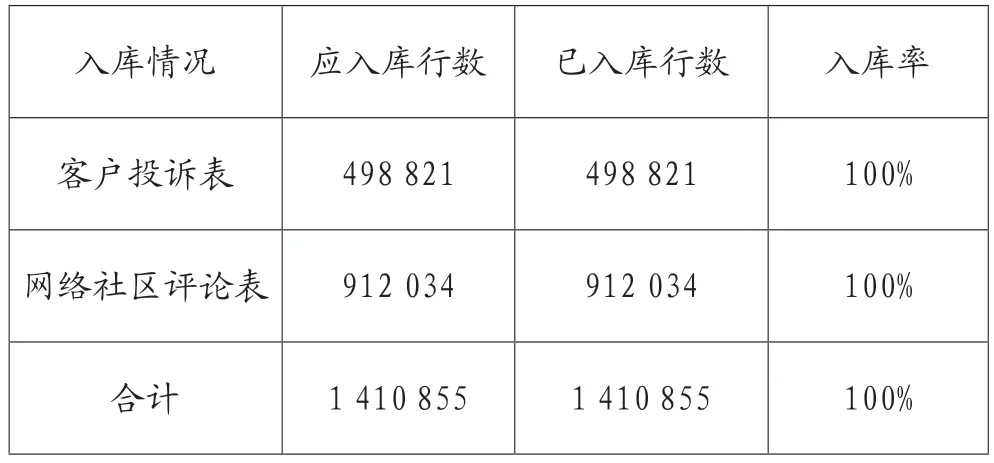
表10 入库情况统计
本次客户声音数据入库率达100%,达到目标值,对策目标达成。
5.3 实施三:进行数据建模
实施项目:对清洗好的文本数据进行关键词模型训练,提炼出客户声音的关键词。
实施情况:
1)训练模型。利用Python搭建关键词模型,本次实施采用jieba工具包的TextRank算法,通过词之间的相邻关系构建网络,迭代计算每个节点的rank值,排序rank值得到关键词。
对每一条文本进行上述操作,提取每一条文本的TOP5关键词,直到遍历全部文本数据,输出全部关键词,保存为csv文档。
2)评估模型。检查每一条文本对应的5个关键词,如果发现关键词不足5个的情况,属于训练异常或样本文本较短,可判断为该条文本模型训练效果不佳。
经统计,本次共训练1 410 855条文本,其中1 219 259条文本所输出的关键词大于等于3个。
目标确认:关键词模型有效性为86.4%,对策目标达成。
5.4 实施四:形成输出
实施项目:使用可视化工具将关键词清单整理成词云图,并结合产品现状分析得出客户投诉原因。
实施情况:
1)生成词云图。使用Python读取关键词csv文档,准备好数据源,用词云工具包整理关键词,并按关键词出现频次大小输出凸显效果不同的词云效果,生成词云图,如图3所示。

图3 词云图
2)分析客户关注焦点问题。从词云图选取最突出的关键词,结合产品业务特点和现状,以及实际客户投诉内容,分析总结出客户关注焦点问题(见表11)。
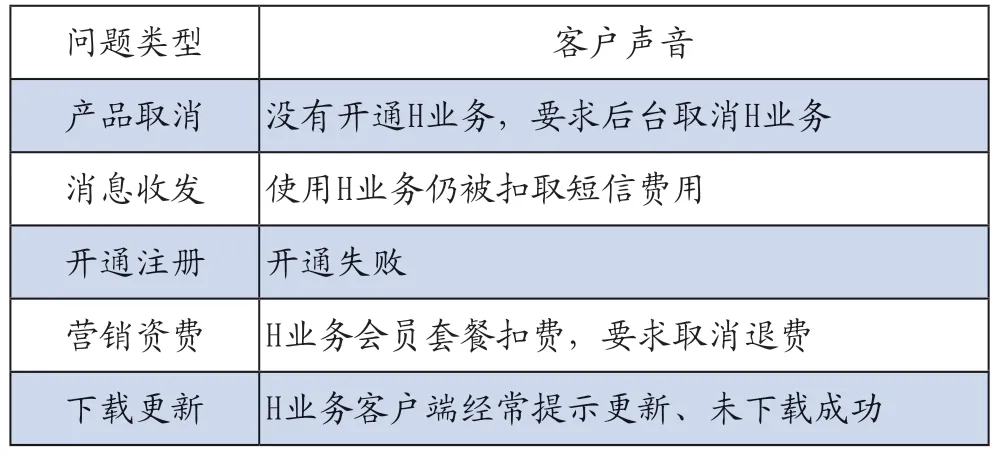
表11 客户关注的焦点问题
目标确认:输出TOP5客户热点问题,达到目标期望,对策目标达成。
6 确认效果
对策实施以后,客户声音分析效率平均值为55.2分钟/千件,达到60分钟/千件的目标值。
