基于矩阵画像的金融时序数据预测方法
2021-01-21高世乐李海林万校基
高世乐,王 滢,李海林,2*,万校基
(1.华侨大学工商管理学院,福建泉州 362021;2.华侨大学应用统计与大数据研究中心,福建厦门 361021)
0 引言
机构投资使股市环境产生了多元化的投资者结构,对股市具有一定的冲击影响,同时也可以帮助稳定金融市场。目前大部分股票交易都有机构投资者的参与,其行为对股价波动的影响较大。研究机构交易行为对股价波动的影响有利于帮助散户进行股票投资,本文将从股票总体市场出发找出机构交易行为,分析机构交易行为对个股价格波动的影响,预测个股股价波动趋势,识别机构投资者操纵股票的行为,进而降低散户投资风险和提高投资回报。
机构投资者的交易行为对股价波动是否具有一定的影响,部分学者对其进行了研究。何佳等[1]对机构投资者能否稳定股市进行了实证研究,得出了机构投资者对股价波动的影响并不是确定的;王咏梅等[2]从机构投资者与市场信息效率的关系出发,对深市A股的上市公司数据进行实证研究,得出机构投资者的过度交易行为会损害信息效率,加剧股市的不稳定性,造成股价波动;刘京军等[3]根据换手率特点将机构投资者分为长期投资者与短期机会主义者,经过实证分析得出较长期机构投资者而言,短期机构投资者的交易行为加剧了股市的不稳定性,加剧了市场波动,长期机构投资者在稳定市场方面具有一定的作用;史永东等[4]通过得分匹配模型验证了机构投资者的频繁交易会加剧市场的不稳定性,产生股价波动。因此,机构投资者的短期交易行为会加剧市场的不稳定性,进而导致股价波动,以机构投资者的短期交易行为为出发点,研究个股价格波动趋势是可行的。
在股票价格和趋势等预测方面,学者们也进行了大量研究[5-12],提出了各种不同且有效的预测方法,例如自回归滑动平均(Auto-Regressive Moving Average,ARMA)模型、支持向量机和神经网络等。许多学者又在传统方法的基础上进行了改进,以取得更好的预测效果。张贵生等[6]在ARMA-GARCH(Auto-Regressive Moving Average-Generalized Auto-Regressive Conditional Heteroskedasticity)模型的基础上引入因变量滞后项的微分信息,提出了ARMAD-GARCH 模型,较之原模型取得了更准确的预测结果。吴少聪[7]通过对具有代表性的13支A 股股票建立混合模型进行股票趋势预测,并据此建立了股票信息服务平台,且验证了它比长短时记忆(Long Short Term Memory,LSTM)网络模型和差分整合移动平均自回归(Auto-Regressive Integrated Moving Average,ARIMA)模型的预测准确率高。宋刚等[8]提出了基于自适应粒子群优化的LSTM 股票价格预测模型,对LSTM 模型进行了改进,提高了准确率且具有普适性。石浩[9]通过建立基于递归神经网络的股票预测模型,并与传统的神经网络模型进行比较,突出其所建模型的价值。谢琪等[10]建立了一种基于长短记忆神经网络集成学习的金融时间序列预测模型,并使用准确率、精确率、召回率、F1值与曲线下面积(Area Under Curve,AUC)这5 个评价分类算法的指标对传统神经网络模型与该模型的预测结果进行评价,从而验证该模型优于其他传统神经网络模型。Nakagawa等[11]对股票价格波动模式进行了k-medoids 聚类,并利用索引动态时间规整法[12]提取了代表性波动模式作为预测的特征值,并据此对股价进行预测。
目前在机构交易行为对于个股趋势影响以及通过机构交易行为来预测股价波动等方面的研究甚少,学者们更多的是从股票市场的总体范围来研究机构投资行为对股市稳定性以及股价波动的影响,在预测股价波动方面更多的是基于收盘价序列数据进行预测。相对而言,机构对股票的操纵行为通常是间断性的且时间持续性不长,使得股票时间序列数据的局部性信息显得更为重要。然而,传统的时间序列预测方法是基于数据的整体信息考虑,缺乏对局部性数据的重视。鉴于传统模型和方法对数据具有研究假设前提的要求以及局部性时间片段的重要性,使用时间序列数据挖掘的相关技术和方法对其进行研究显得尤为重要。且矩阵画像算法在时间序列的局部性研究上具有一定的优越性。因此,本文借助时间序列矩阵画像算法对深市A股主要股票历史换手率数据建立基于机构交易行为的序列片段知识库codeDB,利用知识库codeDB 可从单支股票出发对个股价格波动趋势进行预测。与传统ARMA 回归模型和LSTM 网络等预测方法相比,新方法不仅从新的视角对股票时间序列数据进行预测,还对个股价格波动分析具有更好的预测效果。
1 矩阵画像相关理论
矩阵画像(Matrix Profile,MP)[13-24]是一种用于时间序列数据挖掘的数据结构,可用于主题发现、密度估计、异常检测、规则发现、分割和聚类等。
定义1时间序列数据是按时间顺序排列的实数值数据,用序列T表示,且T=t1,t2,…,tn,其中n是T的长度。
定义2子序列表示在原始序列T中截取长度为m的一段序列,用Ti,m表示,即是从T中第i个位置开始的长度为m的连续子集。形式上表示为Ti,m=ti,ti+1,…,ti+m-1,其中1 ≤i≤n-m+1。
定义3距离画像D是时间序列T中不同的子序列间的距离矩阵。给定一个时间序列T,子序列长度为m,从Ti,m(i=1,2,…)开始计算其与其他子序列片段的距离,得到一个距离矩阵D,即Di是给定查询子序列与时间序列中的每个子序列之间的距离向量。
形式上表现为Di=[di,1,di,2,…,di,n-m+1],其中di,j是Ti,m和Tj,m之间的距离,计算子序列片段间的距离公式为:

其中:m表示子序列长度,µi表示子序列Ti,m的均值,σi表示子序列Ti,m的标准差,QTi,j表示子序列Ti,m与子序列Tj,m的点积[14]。特别地,当子序列数据经过zscore标准化后,即μ=0,σ=1时,式(1)转变成:

即标准化后的序列在计算距离画像时,只要计算好子序列间的点积便可快速得到该序列的距离画像。
定义4时间序列数据A=[a1,a2,…,an] 和B=[b1,b2,…,bn],则A与B之间的点积QT计算公式为:

点积是在实现矩阵画像算法过程中会用到的重要公式,是用于计算矩阵画像中距离画像的重要部分。一个子序列与一条时间序列中所有子序列的点积的具体算法见文献[15],该算法时间复杂度为O(nlogn),与传统的计算过程相比,计算效率显著提高。
定义5矩阵画像MP是时间序列T中每个子序列Ti,m与其最相似片段(即距离最小值)之间的距离值组成的向量。距离画像相当于是每个子序列片段与其他所有子序列片段中的距离最小值。形式上,MP=[min(D1),min(D2),…,min(Dn-m+1)],其中Di(1 ≤i≤n-m+1)是由子序列Ti,m与其他所有子序列片段之间的距离所构成的向量。
定义6兴趣模式(motif)是指一条或多条时间序列中最相似的子序列片段,即在每个子序列片段所对应的已是其最近距离值(即子序列的MP值)的情况下,再寻找MP中的极小值。在寻找兴趣模式之前,需先计算出要寻找模式的MP值,再从MP中获得极小值对应的模式,进而找到兴趣模式。
定义7矩阵画像索引是用来记录每个子序列片段的最近子序列片段所在位置的,记为MPI,其为整数向量,即表示距离向量Di中的第j个距离元素。
当子序列片段的MP值相同时,通过MPI可以快速简便地定位到MP相同的值,从而快速寻找序列的兴趣模式。计算矩阵画像的算法目前有stamp[14]、stomp[15]和scrimp[21]等。本文使用的算法是stomp,其具体过程见文献[15]。它与stamp 最主要的区别在于子序列片段间点积的计算效率上。stomp 算法在点积处理上,遵循了以下思路,降低了算法的时间复杂度,使算法更加高效。由于

因此可得下面公式:

使用式(4)可在时间复杂度为O(n)的情况下完成QT的更新,提高了算法的计算效率,使矩阵画像算法更加高效。
矩阵画像的演算过程如图1 所示,该示意图体现了求解一条长度为n时间序列T的MP值的过程。图中Δ指的是计算子序列片段Ti,m与时间序列中其他所有长度为m的子序列片段的距离向量Di,接着对每个距离向量Di求最小值,即MPi=,便可得到所有子序列片段的距离画像MP=[MP1,MP2,…,MPn-m+1]。需要说明的是,由于相邻两条子序列片段重叠太多,会造成时间相近的序列片段互为最相似片段,不利于兴趣模式的发现。故在排除与Ti,m重复长度超过m/2 的子序列的距离后,取距离向量Di的最小值作为Ti,m的MP值。
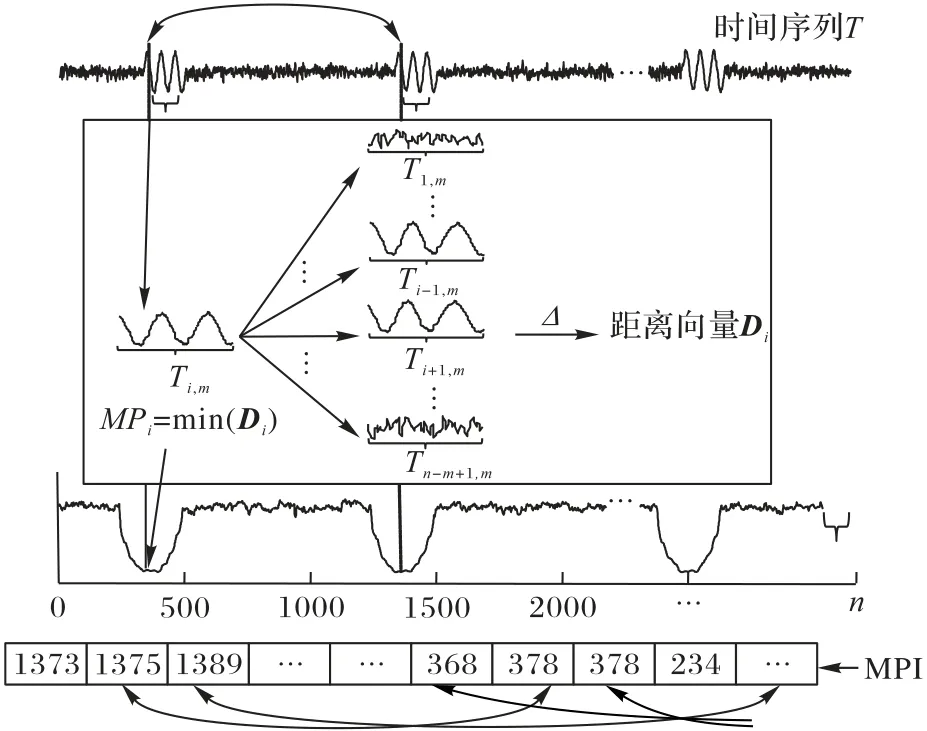
图1 矩阵画像演算过程Fig.1 Calculation process of matrix profile
2 股票价格波动趋势预测方法
首先,使用矩阵画像方法,以金融股票的换手率数据为切入点,分别构建不同兴趣模式长度下的基于机构交易行为影响的换手率波动知识库;其次,确定待预测股票在兴趣模式长度取何值时,预测结果精确度高;最后,基于该兴趣模式长度下的知识库,预测在机构交易行为影响下的单支股票价格波动趋势。
2.1 机构交易行为知识库
换手率也称“周转率”,指在一定时间内股票市场中股票转手交易的频率,体现了股票的流通性强弱。换手率公式为:

其中:H表示换手率,V表示成交量,TN表示发行总股数。
选择使用换手率数据代替使用成交量的主要原因是,在表示机构交易行为时,换手率数据能够反映交易的频率和交易情况,相对更能说明机构和股民在一定时期内的交易行为。一般情况下,在股票市场中针对某一支股票的散户交易量并不大,若没有机构投资者的介入,其换手率一般不高。就一般经验来说,换手率具有以下特征:1)H<3%表示股票交易行为主要是散户参与;2)H>7%表示股票交易行为主要是机构投资者参与。因此,本文主要根据换手率的高低来定义机构交易行为(Institutional Trading Behavior,ITB),且将存在换手率大于8%的股票序列片段定义为存在机构交易行为。
2.1.1 构建知识库
根据交易数据,可以构建反映机构主要交易行为的知识库,其为包含了具有典型代表意义的机构交易行为的数据库,为散户们提供有关机构交易行为的相关信息和知识,构建知识库的算法如算法1所示。
算法1 BuildDB(TS,m)。
输入 股票换手率序列集合TS,兴趣模式长度m。
输出 知识库codeDB。

算法1中1)~2)行是将处理好的股票数据用Matrix Profile算法找出motif;3)~7)行是剔除不存在机构交易行为的motif,并将剩余的motif前期片段、motif片段与motif后续片段分别存入知识库中。
2.1.2 补充库
由于在预测过程中有可能会出现一些情况,即此时的股票数据序列是存在机构交易行为的,但其与知识库中的兴趣模式的匹配度并不高。若强行进行预测,预测结果有极大的概率会偏离实际结果,因此这种情况是不进行预测的。然而,存在机构交易行为的片段是值得注意的,其处理方式是先将该片段暂保存在其他数据库中,称该数据库为补充库(supDB)。补充库是将当前存在机构交易行为但与知识库中的兴趣模式匹配度不高的子序列片段进行保存,以备在完备知识库中使用。具体算法如算法2所示。
算法2 BuildsupDB(QS,codeDB,ε)。
输入 70 支股票中新出现且codeDB未包含的换手率序列集QS,知识库codeDB,匹配程度的阈值ε。
输出 补充库supDB。

算法2 中2)~8)行表示将存在机构交易行为且其与知识库中所有motif 序列的相似性程度都不高的序列片段存入补充库中。
2.1.3 完备知识库
补充库中的子序列片段即是知识库的完备项。当能在补充库找到兴趣模式时,说明该片段具有一定的代表性,则将该兴趣模式所对应的片段扩充到知识库中,具体算法如算法3所示。
算法3 perfectDB(supDB,m)。
输入 补充库supDB,子序列长度m。
输出 知识库codeDB。

算法3 中:第1)~2)行中是从supDB中的序列集合中寻找到兴趣模式;第3)行便是将找到的兴趣模式存入知识库codeDB中。
2.2 最佳模式匹配
对某支股票进行预测时,兴趣模式的长度不同,拟合的效果也会不同。确定兴趣模式长度与预测天数二者满足何种关系时预测效果较好是提高预测效果的手段之一,即寻找兴趣模式长度与预测天数的最佳模式匹配。本文采取的方法主要是使用历史数据进行多次训练,找出已知预测天数下拟合效果好的兴趣模式长度。首先,提出已知预测天数和兴趣模式长度下的趋势预测算法,如算法4所示。
算法4 PredictTrend(Q,TP,m,t,TS,ε)。
输入 待预测片段Q,对应的股票收盘价TP,兴趣模式长度m,预测天数t,70支股票换手率序列集合TS,匹配程度的阈值ε。
输出 预测出的价格趋势PT。

算法4 中第1)行是构建知识库的过程,2)~12)行表示待预测片段存在机构交易行为时的具体做法,第2)~4)行是选取知识库中与待预测片段相似度最高的兴趣模式对应片段,第5)~7)行对二者是否相似度高进行判断。若相似度高则获取未来股价波动趋势;反之,将待预测片段存入补充库中。第13)~23)行表示待预测片段不存在机构交易行为时的具体做法;第14)~15)行是选取知识库中与待预测片段相似度最高的兴趣模式前序对应的片段。若相似度高,则获取未来股价波动趋势;反之,则不可预测。
其次,寻找兴趣模式长度与预测天数最佳模式匹配的算法,如算法5所示。
算法5 DeterLen(T,TP,t,num,TS,ε)。
输入 待预测片段所在股票的换手率序列T,对应的股票收盘价TP,预测天数t,实验次数num,70 支股票换手率序列集合TS,匹配程度的阈值ε。
输出 预测效果最佳的子序列片段长度m。

算法5 的目的是在已知预测天数的情况下获取基于历史数据训练下的最佳兴趣模式长度,其前提在于已知待预测片段及其所在的股票序列。第2)行定义的是训练时兴趣模式的取值范围,本文使用实验验证的方法来确定最佳兴趣模式长度,故在训练实验中会尽量扩大长度的取值范围;第3)~5)行是随机选取一定长度的待预测片段所在股票历史数据,进行预测训练,并计算RMSE 值来判断预测拟合程度的好坏;第8)~9)行是对之前做过的多次实验进行整理计算,综合选出最优的兴趣模式长度与预测天数的匹配模式。
2.3 预测算法
本文主要研究的是在机构交易行为影响下的个股价格波动,但这并不是意味着在没有存在机构交易行为的情况下,新方法就不能进行预测。由图2 即可看出若待预测片段不具有机构行为,可以与知识库中保存的兴趣模式前期序列进行匹配。若匹配度高,则有很大概率认为待预测片段可能即将迎来机构交易行为;若匹配度不高时,则表示无法预测。若存在机构交易行为,则与知识库中的兴趣模式(motif)进行匹配,匹配度高则返回未来可能的股价波动,匹配度不高则将该预测片段存入补充库中。其具体过程如图2所示。
在机构交易行为的影响下对股价波动进行预测(MP based Prediction,MPP)的具体算法如算法6所示。
算法6 MPP(Q,T,TP,t,TS,ε)。
输入 待预测片段Q,Q所在股票的换手率序列T,对应的股票收盘价TP,预测天数t,70 支股票换手率序列集合TS,匹配程度的阈值ε。
输出 预测出的价格趋势PT。

算法6 中:第1)行是对Q所在的股票序列的历史数据进行训练,找出预测效果最佳的兴趣模式长度;第2)行是在确定的兴趣模式长度下对Q的后续股价趋势进行预测。

图2 基于矩阵画像的预测过程Fig.2 Prediction process based on matrix profile
3 实验分析
3.1 数据收集与处理
选取2014—2018 年我国深市A 股股票作为研究对象,并对这些数据进行整理:1)剔除已经停市的股票;2)剔除2014—2018 年连续5 天停止交易的股票;3)剔除2014—2018 年每年交易日期不足180 的股票。整理得到70 支股票样本数据,具体股票代码如表1。

表1 70只深市A股股票代码表Tab.1 Stock code table of 70 A-shares in Shenzhen stock exchange
实验主要任务是将70 支股票从2014 年1 月2 日到2018年2 月1 日为止共70 万条换手率数据用于创建知识库codeDB,预测这70支股票2018年4月10日以后的股价趋势波动。在兴趣模式长度与预测天数的模式匹配中,模拟预测用到的训练数据均从对应待预测股票中随机选取。所使用的数据主要是股票的换手率数据与收盘价数据,实验之前要对股票的收盘价数据根据以下公式进行标准化处理:

其中:TPi指的是第i个收盘价,μTP指的是整条收盘价序列的均值,σTP指的是整条收盘价序列的标准差。
3.2 预测结果评测标准
为了对不同方法的预测结果进行比较,引入了均方根误差与平均绝对百分比误差来对预测结果进行评估,从而比较不同预测方法之间的优劣性。
1)均方根误差(Root-Mean-Square Error,RMSE)。
均方根误差是用来衡量实际值与预测值之间的偏差。具体公式为:

其中:xpredict,i指的是第i个预测值,xreal,i指的是第i个真实值,n指的是预测值或真实值的个数。RMSE 的值越小,说明预测效果越好,预测值与实际值之间的偏差越小。
2)平均绝对百分误差(Mean Absolute Percentage Error,MAPE)。
平均绝对百分误差可以用来衡量一个模型预测结果的好坏,通过比较不同方法的MAPE 值才能知道对应模型和方法预测的准确性或者优劣性,MAPE 值越小,说明模型预测的准确性较高。具体公式为:

其中:xpredict,i指的是第i个预测值,xreal,i指的是第i个真实值,n指的是预测值或真实值的个数。
3.3 实例分析
在使用MPP 方法时,需先确定兴趣模式motif 的长度,即m值。由于不同的m值会造成不同的预测结果,其拟合效果差异性较大,故选好合适的m值有利于得出拟合效果好的预测结果。为了确定兴趣模式的长度,根据不同motif 长度设定对待预测片段所在股票的历史数据进行训练,选择对应预测效果最佳的长度为兴趣模式的长度。如图3 所示,在不同m值下进行多次训练得到的RMSE值所构成的盒图。
根据算法5 来确定motif 长度,以股票代码为000027、000419、000637 和000702 的换手率和收盘价数据为例,通过预测得到了如图3所示的RMSE值分布,通过误差分析可以获得对应股票片段进行MPP 预测时可选取的合适的兴趣模式长度。为验证本文提出方法MPP 的性能,将MPP 与ARMA 模型和LSTM 网络预测方法作对比,同时预测70 支股票自2018年4 月10 日起未来5 个交易日的股价趋势波动。根据代码为000027、000419、000637 和000702 的股票的换手率数据和收盘价数据,由图3中盒图的中位数可选得4只股票较好的兴趣模式长度分别为20、31、33和21。使用算法4预测自2018年4月10 日起未来5 个交易日的趋势波动,预测所得的价格波动与实际价格波动的拟合情况具体如图4所示。

图4 MPP预测效果Fig.4 Prediction effect of MPP
图4 中带*的点线部分表示实际的价格波动,带×的虚线部分表示预测的价格波动,从图4 可以看出这4 支股票未来5个交易日的股价波动涨幅趋势基本相同,且涨幅程度差异不大,预测的效果较好。
自回归滑动平均(ARMA)模型是研究时间序列的重要方法,是目前常用的用于拟合平稳序列的模型。它可以细分为自回归(Auto-Regressive,AR)模型、移动平均(Moving Average,MA)模型和ARMA 模型。在ARMA 模型进行对时间序列数据进行建模分析时,通常用AIC(Akaike Information Criterion)与BIC(Bayesian Information Criterion)信息准则对模型的优劣进行评估。AIC 与BIC 的具体公式如下:AIC=-2 ln(MLV)+2NUP和BIC=-2 ln(MLV)+ln(n) ×NUP,其中:MLV表示模型的极大似然函数值,n表示时间序列的长度,NUP表示模型中未知参数的个数。当AIC 与BIC 的值最小时,认为此时的模型达到最优。
使用AIC 与BIC 确定ARMA 模型中的参数,构建好模型后,通过实验可以得到四支股票000027、000419、000637 和000702 从2018 年4 月10 日起未来5 个交易日的价格趋势波动预测与实际的个股价格波动趋势的拟合效果,如图5所示。
图5 中带*的点线部分表示实际的价格波动,带×的虚线部分表示预测的价格波动,由图5中4幅图可以看出ARMA模型的预测效果不太理想,预测结果的拟合效果并不好。
长短时记忆(LSTM)网络是一种特殊的循环网络(Recurrent Neural Network,RNN)类型,解决了RNN 存在的长期依赖问题,对传统的RNN 进行了隐层中结构上的改进,具有长期记忆能力,LSTM引入“门”的结构来去除或者增加信息到细胞状态的能力,LSTM网络中有输入门、输出门和遗忘门。通过利用LSTM 模型预测相同股票的价格趋势波动,其价格趋势波动预测与实际的个股价格波动趋势的拟合效果程度如图6所示。

图5 ARMA预测效果Fig.5 Prediction effect of ARMA

图6 LSTM网络预测效果Fig.6 Prediction effect of LSTM network
图6(a)~(c)三幅图的涨幅趋势的预测效果不太理想,从(d)中可看出预测到的涨幅趋势与实际的涨幅趋势大致相同,只是涨幅程度差异较大。
3.4 实验评估
使用ARMA 模型和LSTM 网络以及基于机构交易行为下的趋势预测MPP 这三种方法对70支深圳A 股进行预测分析,即预测自2018年4月10日起未来5天(A 时间段)的股价趋势波动,且使用RMSE 和MAPE 这两种评价指标对三种方法的预测结果进行评价。
在使用基于机构交易行为下的趋势预测方法MPP 进行价格波动预测,所定的匹配程度的阈值ε=1.2,在预测过程中000014(沙河股份)和000554(泰山石油)这两支股票的匹配程度不够,将其剔除,终预测数据是68 支股票。由于000632(三木集团)、000767(漳泽电力)和000809(铁岭新城)这三支股票在2018年4月10日至4月16日中5个交易日的收盘价经过标准化处理后存在0 值,MAPE 值无法计算。因此,进行预测结果RMSE 评价指标比较的股票总数为68 支,MAPE 评价指标比较的股票总数为65 支,3 种方法对不同股票A 时段的预测误差如表2 所示(所有数据均保留小数点后两位)。表2中黑体的数值表示股票在RMSE 与MAPE 评价下的预测误差最小值,可以得出共有62支股票的RMSE 最小值与56支股票MAPE 最小值来自基于机构交易行为下的趋势预测方法MPP,且RMSE与MAPE评价下的均值最小值和标准差小值均来自MPP,由此可知MPP 方法的拟合结果优于其他两种方法。

表2 3种方法的预测误差Tab.2 Prediction error of three methods

续表
图7是将表2数据可视化后的结果,图7(a)表示基于机构交易行为下的趋势预测方法MPP 与ARMA 模型的RMSE 值比较,其中纵轴表示ARMA方法的RMSE值且记为Ra,横轴表示MPP 方法的RMSE 值且记为Rm。由散点图易知只有3 个点在下三角区域,即Ra<Rm,说明ARMA 模型只有3支股票的预测结果优于MPP。相反,MPP 方法在65 支股票数据中取得比ARMA 更好的预测结果。图7(b)表示MPP 与ARMA 模型的MAPE 值比较,由于MAPE 值是百分后的数值,为了使图像直观好看且坐标轴不用设置太大,故将MAPE 值均除以100后再将其可视化,其中纵轴表示ARMA 方法的MAPE 值且记为Ma,横轴表示MPP 方法的MAPE 值且记为Mm。图7(b)中共有8 个点在下三角区域,即Ma<Mm,说明ARMA 模型在8支股票数据中的MAPE 指标优于MPP,而MPP 在57 支股票中取得比ARMA 更好的预测结果。图7(c)和(d)分别表示了MPP 与LSTM 网络RMSE 值和MAPE 值的比较。图7(c)中表示通过RMSE 评价指标得出MPP 的趋势预测方法共有65 支股票的预测结果优于LSTM 网络。图7(d)中表示通过MAPE评价指标得出MPP 的趋势预测方法共有59 支股票的预测结果优于LSTM网络。

图7 3种方法对A时间段的预测结果比较Fig.7 Comparison of results predicted by three methods in time period A
为保证上述比较时间段不具有偶然性,另选取了B 时间段(预测自2018年4月24日起未来5个交易日的股价波动)进行相同的实验步骤,同样使用RMSE 和MAPE 这两种评价指标评价MPP、ARMA、LSTM 这三种方法拟合结果。如图8所示。
由于在预测过程中000014(沙河股份)、000151(中成股份)、000532(华金资本)、000789(万年青)、000819(岳阳兴长)、000830(鲁西化工)和000886(海南高速)这7支股票的匹配程度不够导致不可以预测,故最终进行预测结果比较的总共是63 支股票。图8(a)中表示通过RMSE 评价指标得出基于MPP 方法获得的预测结果优于ARMA 模型的股票共有58支;图8(b)中表示通过MAPE 评价指标得出基于MPP 方法获得的预测结果优于ARMA 模型的共有59支。同理,图8(c)中MPP的趋势预测方法共有59支股票的预测结果优于LSTM 网络;图8(d)中MPP的趋势预测方法共有58支股票的预测结果优于LSTM网络。

图8 3种方法对B时间段的预测结果比较Fig.8 Comparison of results predicted by three methods in time period B
4 结语
根据深市A股股票的换手率数据,使用stomp算法获取具有机构交易行为的兴趣模式片段,构建完备知识库,进而提出基于知识库中兴趣模式的单支股票的金融股票价格趋势波动预测方法。针对某支股票,根据股票的历史换手率数据,收盘价数据以及待预测天数,筛选出基于历史数据具有最佳预测效果的兴趣模式长度,从而进行未来几天的股价趋势预测。在时间效率方面,由于前期要对70 支股票数据使用Matrix Profile 算法建立不同兴趣模式长度的知识库,数据量大,算法的时间复杂度也不低,且后期预测时需进行多次的模拟训练,故耗费时间较长。在应用方面,在已构建好知识库的情况下,对在构建知识库的过程中应用到的所有股票都可使用MPP方法进行股价趋势预测,说明该方法具有相对的普遍应用价值。新方法MPP 与ARMA 模型和LSTM 网络的预测结果相比较,实验结果表明,基于矩阵画像的金融股价波动预测效果较好。本研究中获得的贡献性表现为:1)使用了矩阵画像算法与股票预测相结合,利用矩阵画像算法,构建了基于机构交易行为下的知识库,并根据该知识库可对股票的未来趋势进行较为准确的预测。2)将待预测股票的历史数据作为训练集,测试在确定预测时间内兴趣模式序列长度为何值时最佳,进一步优化了预测模型,提高了预测方法的拟合效果。另外,通过研究获得的信息和知识可以降低机构交易行为对散户的影响,帮助散户们在市场中获取较稳定的收益。同时,帮助金融市场监管部门对股价进行监控预测,防范可能出现的股价波动异常。此外,在确定兴趣模式的最佳长度时,主要通过进行多次模拟预测实验,取多次预测结果拟合值的最小均值所对应的兴趣模式长度。该过程并不能保证每次所取的兴趣模式长度是最佳的,故针对兴趣模式长度的分析是未来值得研究的问题。
