改进的地图制图点注记配置探测信息模型
2021-01-18胡冯伟乔俊军陈张健龚丽芳李爱勤
胡冯伟,乔俊军,陈张健,龚丽芳,李爱勤
1. 武汉大学测绘学院,湖北 武汉 430079; 2. 浙江省测绘科学技术研究院,浙江 杭州 311100
在制图自动化的研究过程中,制图设计[1]、数据更新[2]、符号化[3- 4]、图廓整饰[5]等工艺得到了一定程度的自动化实现。而点注记配置尚未得到有效解决,主要原因是随着对问题认识的深入,其配置过程中存在着诸多复杂性、多变性以及较难获得满意成果的困难性等因素,在一定程度上制约了地图生产的效率。目前已有不少的研究成果,主要体现在注记配置规则和配置方法两方面。
在注记配置规则方面,文献[6]提出了注记配置的一般性原则。文献[7]总结了注记配置的本质性原则——注记必须清晰、易读,并保证美学平衡。文献[8]为点、线、面注记优先级、冲突避让优先级、压盖避让优先级给出了一个综合的考虑。文献[9]对注记与点要素紧密关联性规则给出了更为精确的描述。目前所见文献对注记规则描述很全面,但处于自然语言描述阶段,对人工配置而言可快速理解执行,但缺乏到机器语言的转译。
在点注记配置方法方面,主要分为全局最优和局部最优两大方向。就局部最优算法而言,模拟退火方法[10-11]在压盖、冲突、位置优先级、位置关联性4个方面对备选位置进行综合评价,从而获得最优注记位置。文献[12]提出基于Voronoi图的点注记自动配置,对备选位置所压盖的背景要素进行打分,并根据各备选位置的总量化指标确定最优注记位置。文献[13]提出一种自主探测算法,顾及了背景要素压盖、注记的指代明确、配置均匀等原则,能够提高注记质量。
就全局最优算法而言,文献[14]将遗传算法运用于地图注记配置中,其算法具有并行计算的优势,且能获得全局最优解。文献[15]利用蚁群算法,基本解决了注记的冲突问题。文献[16]对基于遗传的点注记配置方法所涉及的关键性问题给出了明确的思路。文献[17]将粒子群与遗传算法相结合,避免了局部收敛和粒子搜索能力的下降。文献[18]提出了一种顾及道路影响的点状要素注记自动配置模型,并基于禁忌搜索策略的启发式算法,较好地平衡了注记位置压盖与位置歧义。文献[19]提出了一种注记候选区域模型,以要素邻域内所有无冲突压盖的候选区域作为注记配置基础,完成点注记配置。文献[20]顾及了点要素与道路间的关系,提出了一种顾及道路要素影响的遗传禁忌搜索算法,精度和稳健性均有所提高。
目前研究成果还有以下不足:
(1) 大部分算法缺乏对注记清晰性规则的考虑。
(2) 部分算法考虑了“清晰性”,但浅层的压盖较难提高注记质量。
(3) 通过注记与点要素最小距离来体现“注记与相应点要素应紧密关联规则”并不精准。因为数学上绝对指标难以反映视觉效果,如数学上相差0.01 mm,视觉上其实相差无几,难以分辨注记的指代性。
(4) 对于注记美学平衡性规则,尚未找到效果显著的方法。
为此,本文提出一种改进的探测信息模型,顾及了要素本身的拓扑关系、数据结构、视觉位置、行政区划4个层面所导致的探测信息量的差异性,并利用多组数据验证其有效性。
1 点注记规则量化
目前所见文献的点注记规则,可归纳为3类基本规则:清晰性、均匀平衡性、指代明确性。清晰性减少注记与背景要素压盖;均匀平衡性减少注记与注记压盖;指代明确性减少注记与点要素压盖,并加强注记与所属要素的关联性。本质上这3类规则可统一看成为地图压盖的问题。
本文直接利用探测区来描述这3个基本规则,定义如下:
在点P的某一个备选位置上,存在3个探测区A、B、C,见图1,也可称为第1、第2、第3探测区,其中第1探测区探测点要素和背景要素;第2探测区探测注记要素;第3探测区探测点要素。各探测区的尺寸与注记尺寸、点符号大小有关。

图1 备选位置探测区Fig.1 Detection zone of candidate label position
1.1 注记清晰性描述
点注记的清晰性,本质上可描述为与背景要素的压盖问题,见图2的“马贵”注记。图(a)中的注记没有压盖背景要素,图(b)中的注记压盖了背景要素,显然图(a)注记效果优于图(b)。

图2 清晰性决定注记位置Fig.2 Clarity determines the label position
因此,点注记的清晰性规则可用如下模型描述
(1)
式中,DIj,clear为待注记点第j备选位置上的清晰信息量,越小越清晰;mF1,i为第1探测区内第i类背景要素数量;KF,1为第1探测区内背景要素种类;Wi为相应要素的压盖权重。
就图2而言,假设线要素的压盖权重为5,根据式(1),图2(b)注记的探测信息量为DI1,clear=5×1+0=5,而图2(a)为0,显然图2(a)注记位置优于图2(b),与图2的实际注记结果一致。
1.2 指代明确性描述
假设一个注记与点要素的距离为0.1 mm,另一注记与点要素的距离为0.11 mm。在数学上,可以认为前一个注记隶属于该点要素,因为它与点要素的距离最近,而在视觉上,肉眼难以区分这0.01 mm的差距,无法分辨注记所属。因此,指代明确性可描述为:注记不能压盖点要素,且注记与相应点要素的距离应明显近于该注记与其他点要素的距离,见图3。
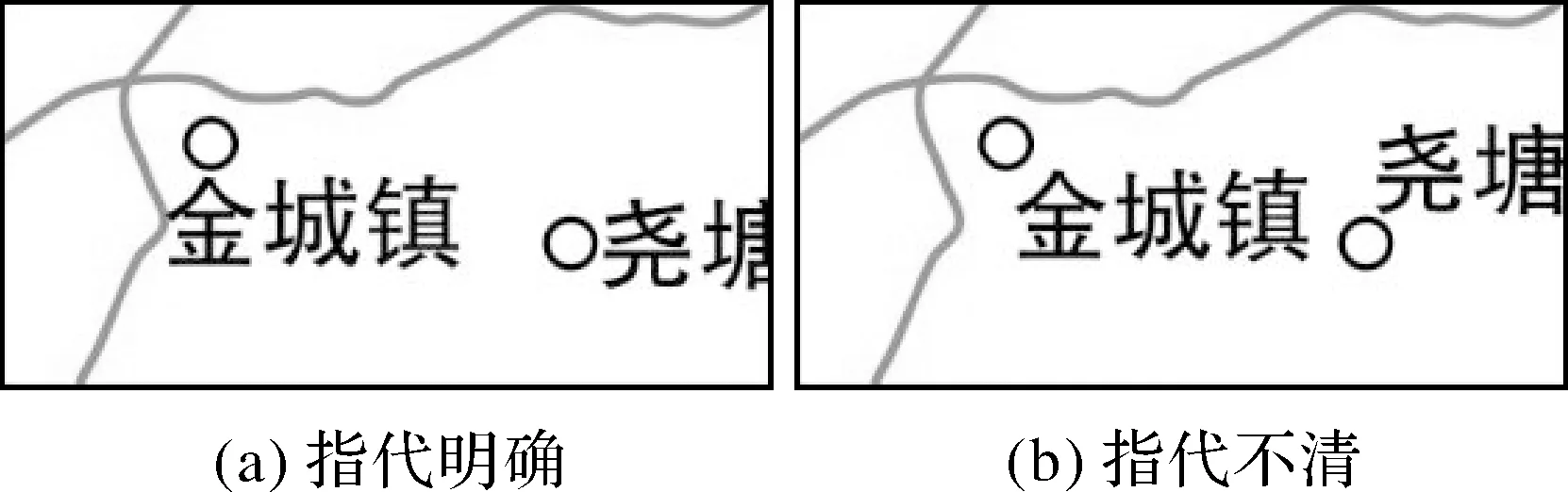
图3 指定明确性决定注记位置Fig.3 Explicitness determines the label position
显然,在清晰性相差无几的条件下,图3中图(a)注记指代性要优于图(b)。假设图中“金城镇”能够探测到其右下角存在其他点要素,那么就会避免图(b)的注记位置,保证注记的指代性。因此,指代明确性规则可用如下模型描述
(2)
式中,DIj,explicit为待注记点要素第j备选位置指代明确信息量,越小越好;mp1,i为第1探测区内第i类点要素数量;KP,1为第1探测区内点要素种类;mp3,i为第3探测区内第i类点要素的数量;KP,3为第3探测区内点要素的种类;Wi为相应要素的压盖权重;d为降权系数[13]。
假设点要素的压盖权重20,降权系数为2。图3中,图(a)“金城镇”注记的第1、第3探测区内无点要素,图(b)第1探测区内无点要素,第3探测区内右下角有一个点要素。根据式(2),图(a)注记位置的指代明确信息量DI3,explicit=0,图(b)注记位置的指代明确信息量DI3,explicit=(1-0)×20÷2=10,图(b)的信息量大于图(a),这与图3的实际配置结果一致。
1.3 配置均匀性描述
注记配置的均匀性可逆向理解为注记与注记之间不过度拥挤,如图4所示,若注记备选位置探测到周边已配置了注记,可避免配置在该备选位置上,确保相互之间不拥挤。

图4 均匀性决定的注记位置Fig.4 Explicitness determines the label position
因此,可以将注记配置的均匀性看成一种压盖,模型描述如下
(3)
式中,DIj,uniform为待注记点要素第j备选位置第2探测区的均匀信息量;KA,2为第2探测区内注记种类,mA2,i为第2探测区内第i类注记的数量;Wi为相应要素的压盖权重。
图4中,就图(b)而言,若“延陵镇”的第二探测区探测到其上方较近距离存在“宝埝镇”注记,可避免配置到图(b)的位置,这就为“宝埝镇”提供了足够的注记空间,从而能够实现图(a)的注记效果。
1.4 归属正确性描述
对于某些特殊要求的地图,例如行政区划类的地图,需要注记尽量配置到所属的行政区划内,也可描述为注记本身大部分位于其所属的行政区划内。因此,本文利用第1探测区和行政区划相交的面积与第1探测区面积的比值来反映注记与行政区划归属程度。模型如下
(4)
式中,DIj,area为待注记点要素第j备选位置上归属信息量,越小越好;Warea为行政区划的压盖权重;Sj,1为第j备选位置上的第1探测区与所属行政区划相交的面积;w、h分别为第1探测区的宽和高。
2 探测信息模型
2.1 基于要素压盖的探测信息模型
综上所述,以要素压盖为基础,将清晰性、指代明确性、配置均匀性、归属性等注记规则进行融合,形成了基于地图要素压盖的探测信息模型[13]。某一备选位置上的探测信息量为
DIj=DIj,clear+DIj,explicit+DIj,uniform+[DIj,area]=
(5)
式中,DIj表示第j备选位置的探测信息量;[]表示可选。
2.2 基于压盖结构的探测信息模型
基于要素压盖的探测信息模型将众多点注记规则抽象成为清晰性、指代明确性、配置均匀性3种本质规则。该模型能够获得较好的注记效果,但在实际应用中会受到一系列客观因素的影响,较难把控最终的注记质量。主要有两个方面原因:一是基础地理信息数据本身的拓扑关系会导致压盖差异性;二是数据结构上的差异性会导致压盖差异性。
2.2.1 压盖结构与压盖差异性分析
2.2.1.1 拓扑关系与压盖差异性
基础地理信息数据库中部分线要素会在两线相交处断开成两段,如图5所示。“红、绿”线要素为实际地理数据库中的数据,理论上这两条线要素应连接起来,见图(b)中的“红”色线要素。这种特殊的拓扑关系,在利用式(5)计算探测信息量时,图(a)会探测到两条线要素,图(b)只探测到一条,致使图(a)探测信息量增大一倍,实际上,两备选位置的注记效果是一样的。

图5 拓扑关系影响注记质量Fig.5 Topological relation influenced the annotation quality
2.2.1.2 数据结构与压盖差异性
即使要素本身拓扑关系正确,单纯的压盖仍不能获得很好的注记结果。主要原因在于同一探测区探测同等重要的要素,位于探测区内的要素结构不同,视觉上注记的质量也不同,见图6。
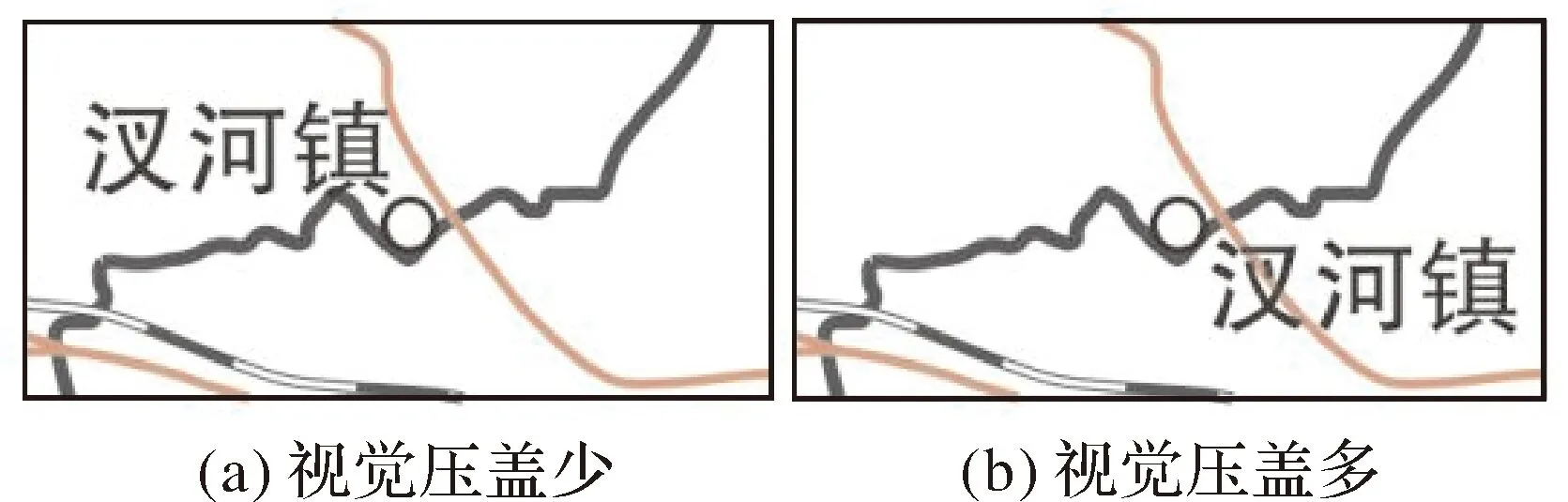
图6 数据结构影响注记质量Fig.6 Data structure influenced the annotation quality
图6中红色线要素为公路,黑色线要素为行政界线。其中图(a)“汊河镇”探测到一条公路和行政界线,图(b)探测到一条公路。根据式(5),图(a)的探测信息量大于图(b),致使图(b)为最终注记位置。实际上,图(a)注记更清晰,主要是因为背景要素在(a)、(b)两图注记中的结构不同。为此本文提出了基于压盖结构的探测信息模型,该模型有压盖长度和压盖面积两种表现方式。
2.2.2 压盖结构模型
2.2.2.1 基于压盖长度的探测信息模型
本文利用第1探测区内线要素或面要素轮廓线的横坐标分量之和与第1探测区宽度的比值,以及纵坐标分量之和与第1探测区高度的比值来反映有效的压盖长度。因此,点注记的清晰性规则可改进为如下模型描述
(6)
式中,n为第1探测区内线要素或面要素轮廓线的节点数;Pi,x、Pi,y分别为第1探测区内相应要素第i个节点x、y坐标。
由式(6)可知,对于相同字数注记而言,当Lx或Ly越大,DIj,clear就越大,要素对注记的影响越大,越不适合放置注记;对于不同字数的注记,当Lx和Ly保持不变时,注记字数越多,w越大,DIj,clear就越小,要素对注记的影响就越小,表明备选位置越适合放置注记。这符合人们的视觉感受,因为在压盖同一背景要素的前提下,注记字数越多,背景要素对注记的影响越小。因此,基于压盖长度的探测信息模型为
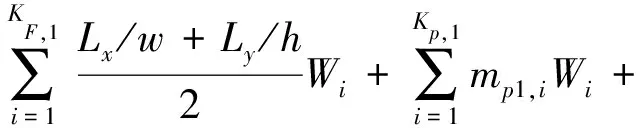
(7)
2.2.2.2 基于压盖面积的探测信息模型
除了线长以外,也可用压盖面积来反映结构。本文利用要素线宽×线长=压盖面积,并与第1探测区的面积相比来反映有效的压盖面积,见如下模型描述
(8)
式中,wi为第1探测区内第i类线要素或面要素轮廓线宽度;li为第1探测区内第i类线要素或面要素轮廓线长度。
根据式(8),当注记字数保持不变时,即第1探测区面积不变,线宽越宽,DIj,clear越大,要素对注记的影响越大,越不适合放置注记。
因此,基于压盖面积的探测信息模型为

(9)
式中,各变量的含义同前。
2.3 基于压盖位置的探测信息模型
在注记配置过程中,背景要素的压盖位置也会影响注记视觉效果。见图7,(a)、(b)两图注记的压盖结构并无明显区别,但在视觉上图(a)注记给读图者的感觉是压盖少,完整性强,图(b)则反之。视觉上背景要素越位于注记中间就越破坏注记的完整性;越位于注记边缘,就越能保持注记完整性。

图7 压盖位置影响注记质量Fig.7 Overlap position influenced the annotation quality
因此,为了体现因压盖位置的不同而导致的视觉差异性,在原模型的基础上,需要叠加压盖位置模型。该模型利用被压盖要素与第1探测区中心最短距离的x、y方向分量分别与第1探测区宽度的一半以及长度的一半的比值来反映压盖位置。具体模型如下
(10)
式中,DIj,position为第j备选位置第1探测区的探测信息量,越小越好;KF,1为第1探测区内背景要素种类,Ni为第1探测区内第i类背景要素个数;dxj、dyj分别为第1探测区内第i类要素的第j个图形到第1探测区中心最短距离的x、y方向分量;其他变量的含义同前。
由式(10)可知,在注记大小不变的条件下,备选位置上被压盖的要素越远离第1探测区中心,即dxj、dyj越大,那么DIj,position越小,被压盖要素对注记的影响越小,备选位置就越适合放置注记。反之,越不适合放置注记。
因此,待注记点要素某一备选位置上的探测信息量为
2.3.1 基于压盖长度+位置的探测信息模型
(11)
2.3.2 基于压盖面积+位置的探测信息模型

(12)
式中,各变量的含义同前。
3 试验结果与分析
本节重点对比各探测信息模型试验结果。
3.1 试验环境与数据
(1) 试验环境:利用GeoDatabase数据库作为制图数据存储媒介,开发语言为C#语言,注记流程为二次配置加一次检测[13]。
(2) 试验数据:国家1∶100万基础地理数据库,选择省、市、县、乡镇级行政中心作为点要素、省、地、县行政界线、高速路、国道、一般道路、铁路,高铁、经纬格网、一级河流、二级河流、三级河流、图廓、海岸线、湖泊等要素作为试验的数据。
(3) 注记配置策略:根据注记重要程度从高到低依次注记。
因幅面关系,试验结果截图只截取部分。文中的地图仅用于注记结果展示,不作为划界依据。
3.2 探测信息模型的对比
地图比例尺为1∶64万,区域范围经度118°20′E—119°40′E,纬度31°40′N—32°40′N,各点要素及注记信息见表1。

表1 点注记信息
3.2.1 要素压盖与压盖长度模型对比
此试验目的是为证实顾及了要素压盖结构后,是否会提高注记质量,结果见图8。

图8 要素压盖与压盖长度模型注记Fig.8 Annotation of feature overlap model and overlap length model
由图8可知,顾及了要素压盖结构后,注记质量明显得到提高,见图中椭圆框出的注记。以图中左上角的“六合县”为例。“六合”二字均压盖了背景要素,但图(b)中仅“县”字压盖了背景要素,图(b)注记更清晰,质量更高。
3.2.2 压盖长度与压盖位置模型对比
此试验目的是为证实在要素压盖结构的基础上,顾及了要素压盖位置是否会提高注记质量,试验结果见图9。

图9 压盖长度与压盖位置模型注记Fig.9 Annotation of overlap length model and overlap length with position model
由图9可知,顾及要素压盖位置后,注记质量进一步提高,见图中椭圆圈框出的注记。以图中右下角“珥陵镇”为例,图(b)中被压盖的要素位于“珥陵镇”最边缘,图(a)中位于注记近乎中间的位置,视觉上图(b)中的“珥陵镇”注记完整性较好。
3.3 顾及行政区划的注记配置
为了验证注记的归属性,且保证注记清晰、配置均匀、指代明确。本文对湖北省的注记进行了配置试验。地图比例尺为1∶210万,区域范围经度108°06′E—116°24′E,纬度28°39′N—33°40′N,点要素及注记信息见表2,注记结果见图10。

表2 点注记信息

图10 压盖长度+位置模型Fig.10 Overlap length with position model
图10中,点注记基本配置到所属的行政区划内,并尽量避免了与背景要素压盖,注记清晰、指代明确,配置也较为均匀。
3.4 与Maplex智能标注系统的对比
为了对比压盖长度+位置探测信息模型与Maplex智能标注系统的注记质量,本文进行了如下试验:比例尺1∶80万,区域经度109°30′E—117°00′E,纬度20°30′N—25°30′N。,试验结果见图11。
总体上,就注记的清晰性、指代明确性、均匀性而言,试验中图(a)的注记质量高于图(b)(见两图中用椭圆圈框出的注记)。以图11的中下方“新兴县”及周边注记为例,图(a)虽有压盖,但是视觉效果分布均匀、合理,明显优于图(b)。
3.5 压盖权重对比
本研究对点注记压盖权重的适用性进行了对比试验,第1组压盖权重根据制图要素的重要程度结合专家知识进行设置。最高权重可任意设置,但要与最低权重有明显差别,其目的是保证注记不压盖点符号和点注记。本试验最高权重设置为20,最低权重统一设置为1。
第1组压盖权重见表3—表5。

图11 第2批数据注记质量对比Fig.11 Annotation quality comparison on second batch data

表3 图8要素压盖权重

表4 图10要素压盖权重

表5 图11要素压盖权重
第2组压盖权重中最高与最低压盖权重保持相同,不考虑底图要素的重要程度,即压盖权重都一样,本文设置为8。最终对比结果见表6。
根据表6的试验结果可知,若无视地图要素的重要程度,模型会影响最终的点注记效果,其中不可接受的注记占比5%以内。试验表明,掩盖权重设置会影响注记质量,但是可控制在5%以内,能够减弱对专家知识的依赖。但是,在实际制图过程中,想获得最优结果,仍需要结合专家知识给地图要素的重要程度进行合理量化(这种量化允许一定的容差,并无绝对单一数值)。

表6 压盖权重对点注记的影响
4 结论与展望
相对于点注记自动配置质量不高的问题,本文提出了一种改进的探测信息模型,模型对点注记的清晰性、指代明确性、配置均匀性等规则进行了量化描述,并顾及了要素本身拓扑关系、数据结构、行政区划、视觉位置4个层面所导致的探测信息量差异性。多组试验结果表明,本文模型能够进一步提高注记质量。本文研究尚有不足之处待进一步解决:①目前注记质量以主观判断为主,还缺乏定量分析;②模型虽能获得较高的注记质量,但在复杂地图环境中任可能出现不合理注记,离全局最优解还有很大的差距,旨在给后续的研究者提供借鉴和思考。
