基于色彩的车牌识别研究
2021-01-18唐愉顺张生果牛潞崔泽宇
唐愉顺,张生果,2,牛潞,崔泽宇
(1.甘肃省民族语言智能处理重点实验室,西北民族大学,兰州 730030;2.西北民族大学电气工程系,兰州730030)
0 引言
伴随着我国车辆数目的快速增长,截至2020上半年,我国汽车保有量已超过3亿,通过人工对汽车进行管理显然工作量太大,效率太低。如何对汽车进行高效的管理是一个很大的问题,现如今图像处理和识别等技术已经日益成熟,利用图像处理有效提取车牌关键信息进而自动识别的技术提升了车辆管理的效率,在汽车的停车管理、交通违章、布控巡查等方面都有着广泛的应用[1]。对车牌自动化且实时识别的关键环节便是车牌定位、字符切割、字符识别以及后续处理。常见的车牌识别技术主要是依据灰度图像处理的图像识别技术,判别车牌图像的有效信息区域,进而对字符进行识别。但在实际车牌识别过程中,此类方法往往因为少量车牌边缘特征无法被捕捉而产生的识别率不高和识别速度不快等缺点造成车牌有效信息提取不完整或提取失败等问题。本文提出的基于色彩的车牌识别方法针对目前国内常见的家用小轿车车牌的蓝色背景、7个白色字符、矩形边框等特点在MATLAB平台设计出智能车牌识别系统。能够对车牌信息进行有效、精准且实时的识别,系统工作的流程图如图1所示。
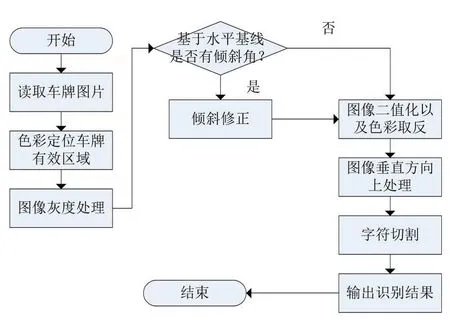
图1 系统工作流程图
该系统主要依赖于对彩色图像的RGB比例定位来判定车牌的有效位置,紧接着在图像处理阶段利用了Radon算法进行倾斜角度计算,并对倾斜图片进行修正。利用Radon算法对图片进行倾斜角的判定以及倾斜修正的优点是:①时间和空间复杂度都不算高在车牌的实时识别过程中有着良好的响应表现。②能够在车牌有效信息区域存在缺失和受污染的情况下稳定有效地对图片倾斜角进行判定并校正。通过修正后的图片有利于后期的图片分割及图像识别。
1 研究方法
1.1 车牌的定位
本环节是车牌识别的关键步骤,本文提出的是一种基于对色彩特征的提取分析定位算法,其成功率直接关系到整张车牌图片识别的成功率。因为车牌识别的第一步就是找到、定位并且提取车牌的有效区域信息,即蓝底白字的矩形车牌边框区域。基于色彩对图像进行分析,找到图片中符合目标蓝底白字的矩形边框区域,不需要对整张图像的边缘进行检测。其原理是:当识别目标带有明显的某一类颜色时,在图片中表现为某一类颜色的像素,可以通过R、G、B三颜色通道定位出一个大概的范围,无需进行大量复杂的边缘特征计算,省时省力。具体操作步骤为:首先在分割开的区域中统计每一行的蓝色像素点,通过找到最多蓝色像素点积累所在行确定为车牌矩形边框的边界上限,即Y方向上的最大值。接着同样的方法确定每一列中最多蓝色像素点积累所在列为车牌边框的边界上限,即X方向最大值,即可确定车牌边框位置,随后统计白色像素点即字符所在行列数的位置数目由边框向中间依次扫描,多次统计综合判断并成功定位车牌所在位置。如图2所示。

图2 车牌定位展示图
1.2 车牌图像灰度处理
对成功定位好的车牌图像进行灰度处理是提取车牌有效信息的重要步骤。对于已经成功定位提取的车牌图像只包含有字符和背景信息,然而此时的背景信息对后续的处理是无用的[2],因此通过灰度处理后彩色图片失去色彩值同时保留下了关键的字符信息,方便后续进行信息的提取。灰度处理后图像如图3所示。

图3 图像灰度处理
1.3 倾斜判定以及修正
在车牌的识别过程中,字符的分割是关键环节,由于图片的拍摄角度和基于色彩的有效区域提取操作后车牌图像或多或少都会存在一定范围的倾斜,如果不加以校正处理将直接影响到后续的字符分割和识别过程。所以将车牌图像修正为水平显得尤为重要。本文主要以Radon变换(拉东变换),来对车牌图像进行倾斜角度计算以及倾斜修正。Radon变换可以在数字图像矩阵在某一指定角度射线方向上做投影变换。这就是说可以沿着任意角度theta来做Radon变换[3]。本文选择在X方向(图像最下边界)和Y方向(图像最左边界)两个方向投影,统计黑点数,以获取在X和Y方向上突出的特性。最终利用算法计算出倾斜角度,并对图像进行修正处理,如图4所示。

图4 倾斜修正
1.4 图像的2值化以及擦除干扰信息
为了进一步方便对后续的字符识别,为了方便字符分割,需要对图像进行二值化处理。通过二值化处理后图像变得简单,数据量减少,并且能够突出字符主要特征。但是将图像二值化后无论用什么方法都会无可避免的产生一些干扰噪点,如图5所示为二值化后的车牌图像。

图5 二值化后车牌图像
为了提升后续7个字符分割的成功率,需要对二值化后的图像做进一步处理,尽可能保留有效信息而擦除干扰值。本文对二值化的图像像素值取反使得有效信息和干扰信息最大限度分离如图6所示为图像取反结果,紧接着为了去除车牌边框定位了字符的高度,截取掉了高于和低于字符在Y方向上的部分图片。

图6 颜色取反后车牌图像
这个时候图像中仍然保留有大量的无关干扰特征例如:固定车牌的铆钉(在图像中显示为圆形斑秃),矩形车牌边界外的区域(在图像中显示为大量黑色区域)。想要成功进行后续字符分割和字符识别操作必须对这些干扰因素加以剔除。本文所采用的方法是:将图像在X方向上进行投影,得到图像在垂直方向上的像素分布信息,统计出黑白像素值,当像素值出现大量跳变时在其范围内界定一个上下界,截去上下界之外的图像,如图7所示为在垂直方向上截取后的图像。

图7 垂直方向上处理结果
1.5 字符分割
本文所采用的字符分割主要还是传统意义上的字符分割算法,针对上述处理好的图像结果,将图像进行水平、竖直两个方向的投影进而分割每一个字符。此方法对分割阈值的依赖性比较大,阈值的选取恰当关系到字符分割的成功率。由于在车牌图像中每一个字符的尺寸都大体相同,所以只要选择恰当的阈值就可以成功进行字符分割。具体操作是将图像先进行X方向上的投影得到图像在垂直方向上的像素点分布信息,有像素点的区域即是字符区域,将有像素点的区域切割开来,同理将图像在Y方向上进行投影,得到水平方向上的像素点信息,同样有像素点的区域为字符区域,将其切割。如图8所示为操作结果。
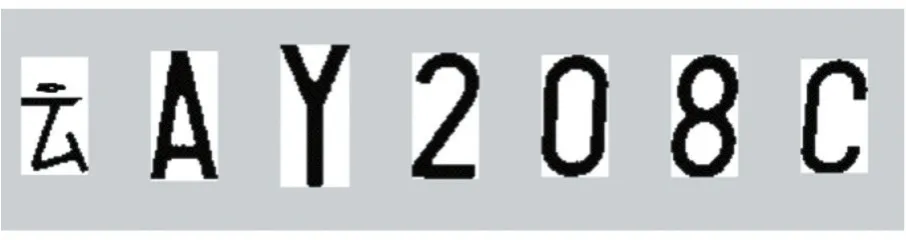
图8 字符分割结果
1.6 模式匹配识别
本文采用模式匹配算法来对切割好的字符进行识别,模式的核心思想是将字符图片从左上角开始从左向右进行像素扫描与图片库里的图片进行相似度计算,匹配出最相近的结果。其中相似度计算的方法采用的是MAD算法,由于前期干扰信息的擦除处理和字符分割的成功,模式匹配所要识别的图片中不含或者含有极少量噪声,对识别结果不会产生什么影响。MAD算法的具体操作是将目标图片扫描后与图片库里的图片对应位置像素值相减,其结果累加后取平均值。数值越小代表两张图片越接近也就越相似,即为匹配对象。如图9所示为输出结果,其结果准确无误为云AY208C。
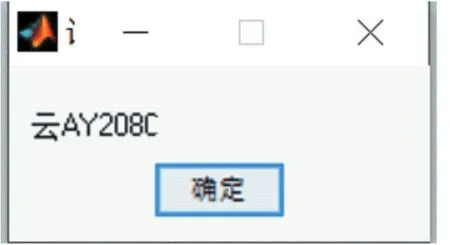
图9 识别结果
2 实验结果
目前模式匹配图片库中录入了10个省份的汉字简称、26个英文字母和10个数字。通过对10个省份总共100张车牌图像进行识别实验,结果表明:对于倾斜角度较小的车牌色彩定位成功率为97%,而部分倾斜角度过大的车牌图片识别率也高达80%。字符识别中由于部分数字和字母在形态上过于相似对于这一类字符的识别,成功率只有70%左右。除部分数字和字母外其余识别成功率高达95%,表1列出部分容易混淆难以识别出的字符:
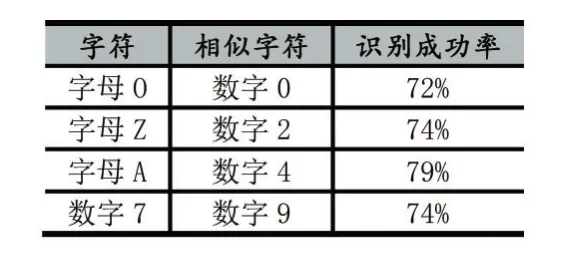
表1 容易混淆难以识别的字符
3 结语
车牌的识别过程中车牌有效区域的定位和提取是识别的第一步也是最关键的一步,本文所设计车牌识别系统针对国内常见的家用小轿车蓝底白字特征的车牌基于色彩进行定位,在进行字符分割和模式匹配前,将车牌图像灰度、二值化处理,最大化限度突出了车牌特征并擦除干扰信息。这样做可以提高字符分割和最后识别的成功率。实验结果表明此方法对于倾斜角度不大的蓝底白字小轿车车牌识别成功率较高,识别速度快,算法时间空间复杂度都比较低。但是本文提出的车牌识别方法是基于色彩的识别方法,此方法虽然对于蓝底白字的小轿车车牌识别有极高的准确率可是也有致命的缺点:无法识别汽车为蓝色背景的小轿车车牌,并且对于识别的车牌图片像素要求不能太低,不然会无法提取特征信息导致识别失败。同时在模式识别过程中依然存在着部分字符由于形态上过于相似导致识别结果混淆经常难以区分的问题。针对色彩定位问题可以增强对图片色彩的敏感度以达到区分不同蓝色背景和车牌有效区域的目的,字符识别想要提高识别成功率有效区分容易混淆的字符可以采用神经网络的算法提前将各个省份的汉字简称、26个英文字母和10个数字训练好提高识别效率。
