基于时空融合图网络学习的视频异常事件检测
2021-01-15詹永照毛启容
周 航 詹永照 毛启容
(江苏大学计算机科学与通信工程学院 江苏镇江 212013)(henrryzh@qq.com)
随着大数据时代的发展,各类视频数据呈井喷之势,抖音之类的短视频和设备监控类的长视频成为大众了解社会的快捷通道,因此对视频数据的分析成为热点研究问题.其中视频异常事件分析成为维护社会治安与人民安全的安防领域的迫切需求.目前长视频中异常事件发现与定位技术还不成熟,大多还采用人工判别,无法应对当今数据量暴增的趋势.因此研究利用弱监督或者无监督信息,快速有效发现视频中异常事件发生的时间,成为了目前视频异常事件分析需要解决的关键问题.
由于正常模式的视频易于收集,视频异常事件检测[1]最普遍的方法为单分类法,在正常数据集下进行训练[2],使模型能够较好地拟合正常模式,在异常发生时会有较强的响应.但是此类方法局限特定场景,应对外界干扰能力差,易产生误报与漏报.以正常与异常联合参与训练能够给予模型一定的异常判别能力,但是异常视频在人工收集与标记时耗费时力且存在一定的主观性,因此收集的视频数据只含有视频标签,无异常发生的详细时间段标记,利用此类数据实现有效的视频异常事件模型建立和异常事件的发现与定位,成为了目前视频异常事件分析研究的关注点.
基于弱监督学习的异常事件检测与定位方法是一种有效解决上述问题的方法.很多人将弱监督的视频异常事件检测问题视为多示例学习[3]问题,但只考虑了视频特征片段自身的特点,没有将其与其他视频特征片段进行联系,一般能够检测显著性异常(如爆炸等),对于偷窃等联系性较强的事件则检测失效,对于有遮挡的异常事件也会发生漏报.Zhou等人[4]提出多示例学习中各个示例并不是独立同分布的,他们之间存在一定的联系.学习并利用这种联系将更好地表达视频的动态性特征,更适合于多样性视频的异常事件检测,但如何更合理考虑视频片段的时空关联关系并进行更有效融合,进而实现快速有效的视频异常事件检测与定位,还需深入研究.
为了应对以上挑战,本文结合视频特征具有的时间连续特性以及空间上的相似性,提出基于时空融合图网络学习的视频异常事件检测方法.该方法引入多示例的图结构去构建视频中各个片段之间的联系,对时间角度和空间角度的构图方式进行自适应融合得到时空融合图,采用时空融合图卷积网络学习视频特征,引入多示例注意力网络对各个片段进行注意力的分配,并实现整个视频的异常检测,以期获取更好的多样性视频中异常事件检测与定位性能.本文的主要贡献有3个方面:
1) 考虑视频段之间的时空关联关系,提出时空融合图模型,动态构建节点近邻的空间相似和时间连续图,利用注意力引导的权重矩阵加权2种图,进行自适应学习融合,实现了视频段时空特征内在关系的更有效学习表达;
2) 提出了时空融合图卷积网络学习视频段时空特征并进行分类预测,在排序损失中加入图的稀疏项约束,更有效地提高视频异常事件检测性能;
3) 引入多示例注意力机制学习各个片段对整个视频的贡献度,实现对视频的异常判断并建立视频级异常分类损失进一步提升检测性能.
1 相关工作
1.1 视频异常事件检测
视频异常事件检测是一个具有挑战的研究问题,经过多年的探索与研究,取得了大量成果.传统方法主要以手工特征为训练样本,采用概率密度估计的统计学方法[5],判断事件服从正常或者异常的分布,或者利用高斯混合模型与马尔可夫模型[6]对异常特征进行推断,效果更好的有采用稀疏学习[7]对正常模式进行字典学习.这些方法都存在着依赖特征的选择,只适用于特定场景和检测准确率及定位精准度不足等问题.
深度学习方法实现视频特征的自动学习与提取,可根据环境自动获取视频特征,有效实现视频语义概念的检测分析.基于深度学习的视频异常事件检测已成为研究热点.在生成模型迅速发展的趋势下,大多数异常检测以自动编码器[8-10]为主体方法,对正常视频[11-14]进行无监督学习,通过生成模型对视频进行重构,在测试时模型对于异常帧会有一个较强的响应,但是此类模型局限于异常模式较少且时序短的视频,对于固定类型视频任务的检测有较强的泛化能力;相对较长的视频以时空模型为基本方法,对视频进行时间和空间上的分析,如Zhao等人[15]利用3D卷积自动编码器方法对视频进行重构,考虑了视频的时空上的信息,但是只是利用局部信息且生成模型对于异常事件多样性泛化能力较弱.
应对于异常视频数据的场景复杂化,采用弱监督的方法更能满足对异常检测的需求.Sultani等人[16]为弱监督的视频异常事件检测带来新的解决方案与挑战,他们提供了新的数据集UCF-Crime,通过采用正常与异常数据进行训练更好地发现异常,结合多示例学习的方法,为该数据集提供了一种有效的基准方法;Zhu等人[17]考虑到运动信息对异常的影响,采用光流金字塔模型做特征提取,引入注意力机制对异常视特征段作显著性突出,整体上仍然将示例之间看作是独立同分布的,没有利用示例之间的潜在关联关系;Zhang等人[18]利用多示例学习中正负包内的各个示例的差异,提出包内损失,并利用时序卷积神经网络(temporal convolutional network, TCN)进行时序上的关联,该方法只是促进了正常与异常的差异分化,对于内部其他趋向于中性的视频段没有显著的分化;Zhong等人[19]将弱监督数据采用全监督的方法去处理,所采取的策略是利用图卷积的传递信息的能力对异常视频中的正常片段进行去噪,将得到伪标签训练3D卷积神经网络(3D convolutional network, C3D)[20]进行有效的异常识别,在进行正常视频段去噪的过程中,训练过程较为复杂,去噪过程可能将异常清理,造成信息丢失,可能引起异常事件识别与定位不够准确.
1.2 图神经网络与视频分析
图神经网络[21-26]正处于发展阶段,并广泛应用于社交关系网络、生物分子结构以及视觉等方向.Wang等人[27]利用图卷积网络对视频进行分析时,考虑目标之间的时间以及空间的联系[28],大幅提高了复杂环境下的视频动作识别的性能.Feng等人[28]将时空图应用到视频追踪中,也获得了优异的结果.因此建立完备的关系拓扑结构,可以有效地提高视频分析能力.我们结合异常视频内在时空联系去动态构建关系结构图,为了表达视频内在联系,我们提出了时空融合图卷积网络,更好地实现对视频异常事件的分析.
2 对于视频异常事件检测的时空融合图网络
问题描述:本文将弱监督的视频异常事件检测视为多示例学习问题.对于一个视频V={c1,c2,…,cN}以及视频标签y∈{0,1},其中ci为切分的视频片段,我们需要判断出是每段ci是否为异常段即异常概率P(ci)=1,并将其分配到每一帧上实现对帧的判断,同时也需要预测整个视频是否为异常视频.
针对视频中各个片段之间存在时空上的联系,提出对于视频异常事件检测的时空融合图网络学习方法.图1为整体网络结构,主要分为3个部分:1)成对输入正常与异常视频并分段,以预训练的膨胀3D卷积神经网络(inflated 3D convolutional network, I3D)[30]为骨架,提取视频段的特征,利用多示例学习机制对提取的视频特征段进行正负包和示例的划分,考虑到视频具有时间连续特性以及视频片段的1维空间特性,利用时间连续关系与空间相似性构建2种角度的多示例图结构;2)对2种图做自适应融合得到具有2种图优势的融合图,采用图神经网络,对异常视频特征段进行分类预测;3)利用各个片段的注意力关系加权得到视频异常预测.
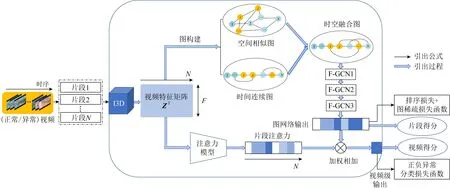
Fig. 1 Framework of spatio-temporal fusion graph network learning
2.1 多示例图结构构造
考虑到视频段之间隐含着时间连续关系以及空间相似关系,同时图结构具有优异的拓扑推断能力,因此将每个视频段视为图中的一个节点,利用I3D作为特征提取器,提取每个视频段的特征作为节点的嵌入向量,考虑视频段之间的联系,从而构造2种属性的多示例图.
2.1.1 空间相似图构造
视频段之间存在空间上的相似性联系,将这种联系用图结构表示可以很好地推断相似视频段.由于采用I3D提取的特征粒度较大,若直接用特征的欧氏距离度量视频段相似度,且相近片段相似度均较大,难以突出其差异性.同时异常段在视频中的出现显现出稀疏性,为了防止图卷积网络在训练时发生过拟合,因此采用k近邻思想用来度量各节点的相似度作为构图方法.B={s1,s2,…,sN}为整个视频经过特征提取后的特征表示,其中si∈RF为第i段视频的特征表示,将其设置为相应节点集合V={vi|vi=si,si∈B}.以欧氏距离为判断准则,计算节点vi与其他各节点的相似度:
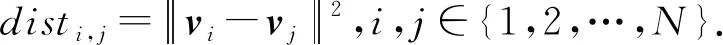
(1)
对节点vi与其他节点的相似度进行升序排序:sort({disti,j|i,j∈{1,2,…,N}}),形成节点vi的前k个最相似的节点集合:
simi={vm|m=rankl(sort({disti,j|i,j∈{1,2,…,N}}))},
(2)
其中rankl为返回第l∈[1,k]个最相似的节点号.对各个节点之间赋予边上的权重,权重计算公式为
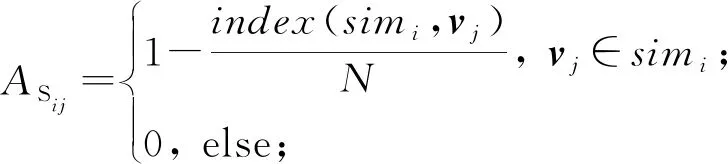
(3)
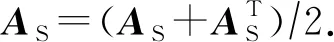
2.1.2 时间连续图构造
视频中一个事件的发生除了有视频片段空间特征上的相似性外,主要是还有相邻片段时间连续特征上的联系.对于大部分异常视频数据而言,并不是所有异常段类似于爆炸事件产生得那么剧烈,大部分需要一个起伏波动的过程,因此对于一个视频片段与其他片段的时间连续相似度,采用类似事件发展的k连续性度量,以时间连续相似度进行时间连续图节点的连接.对于任意节点vi与vj,以节点序号距离作为其是否连接的判断准则.对于节点vi,其相近时间连续节点集合为timei={vj||j-i|≤k},连接节点vi与集合timei中的节点,2节点间的边权重定义为
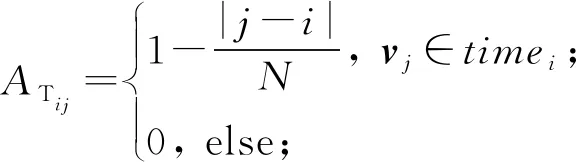
(4)
即与第i个片段越近的片段所分配的权重越大,能更好地反映它对第i个片段的影响因素,由此构成k近邻图GT=(V,ET),V为与GS相同的节点集合,ET为时间连续图的边集合,对应邻接矩阵为AT.
2.2 时空融合图卷积网络
视频片段的异常事件检测不仅要检测出明显的事件片段,还要能更精确地定位出事件的起止片段,时间连续相似图GT=(V,ET)能刻画一个事件发生的平滑起伏区间的特征内在关联关系,而空间相似图GS=(V,ES)能更好地表达出有明确异常事件视频片段特征的内在关联关系,因而单一的时间连续相似图卷积网络不利于片段异常事件准确检测,单一空间相似图卷积网络又不利于更准确的异常事件边界的检测定位.
为了更好地利用时间连续图与空间相似图所刻画的内在关联关系,本文将时间连续图与空间相似图进行融合,构建一个自适应的时空融合图网络进行异常事件的时空特征学习.首先对2种图进行非线性融合,通过训练学习得到一个最契合两者的权重参数.具体融合方法为:给定邻接矩阵AS,AT∈RN×N,分别为GS与GT的邻接矩阵,对于各个邻接矩阵给予一个待学习的权重WS∈RN×N与WT∈RN×N,利用注意力引导2个邻接矩阵加权.学习形成融合邻接矩阵,其形式化表达为
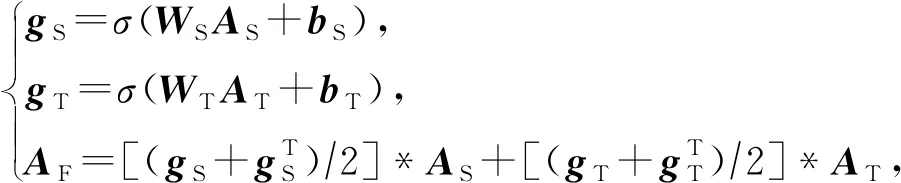
(5)
其中,bS∈RN×N,bT∈RN×N为偏置参数,*为哈达玛积,gS∈RN×N,gT∈RN×N分别为得到2个邻接矩阵的概率矩阵,σ为sigmoid激活函数,得到一个[0,1]之间的选中概率值,最后的融合图成为无向图.通过学习得到各自选中边的概率矩阵,2个概率矩阵与邻接矩阵作点积并相加,得到融合图即GF=(V,EF),V为与GS和GT相同的节点集合,边集合以邻接矩阵AF∈RN×N表示,对AF进行归一化,得到矩阵:

(6)
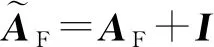
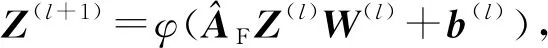
(7)
其中,Z为当前层的节点特征表示,W为待学习的权重参数,φ为relu激活函数.最后分类层采用sigmoid函数P=σ(Z(3))=(P1,P2,…,PN),Pi∈[0,1],i∈{1,2,…,N},P即为所有片段的得分值.
2.3 注意力模块
由于正常异常区域未知,利用注意力突出异常区域,同时也能通过加权操作得到视频级的得分,降低时空融合图网络层带来的过平滑影响.整个注意力模块通过2层全连接层以及softmax函数对各个片段实现权重分配,并对图网络层的片段得分加权获得整段视频的异常得分.
(8)
其中,vid∈[0,1]为加权后的整个视频异常得分,atti∈[0,1]为各片段的注意力权值,Pi为各片段得分值,Z∈RN×F为初始的提取好的视频特征,W,b为注意力网络层待学习的参数.
2.4 损失函数
网络最后输出为视频片段异常预测和视频异常预测,利用排序损失与图稀疏约束优化网络对于视频片段的学习,采用交叉熵损失优化网络对视频以及视频段的异常预测.
1) 排序损失(ranking loss).由于没有细粒度的帧级别监督信息优化模型,采用粗粒度的视频级标签作为监督信息.在进行训练时将正常异常视频成对一起送入网络训练,要促使异常事件检测更加准确,应使得异常段的得分值远大于正常段,而具体异常段与正常段未知,因此利用异常视频段中最高得分与正常视频段中最高得分去增大两者间距,利用排序损失实现约束:

(9)
其中,Pa;i表示一个异常视频Ba中第i个异常视频段的异常概率值,Pn;i表示一个正常视频Bn中第i个视频段的异常值概率.
2) 图稀疏约束(L1 graph loss).考虑到异常事件的稀疏性,在时空融合图网络层得到的所有片段的得分值应具有稀疏特性,同时对于时空融合图中的边在构图时也应满足其稀疏性,用L1损失来构造图稀疏约束:
(10)
其中,AF=(AFij)N×N为时空融合图的邻接矩阵,Pi为各个片段最后得分值.
因此对于视频片段损失函数为
Lsegment=l(Ba,Bn)+λ1lsparse,
(11)
其中λ1为超参数.
3) 视频异常分类损失.弱监督的视频异常事件检测是一个多示例问题,最后实现对于视频级标签的类别判断也是必要的,先前研究没有完全使用视频监督信息,我们利用注意力模块得到的视频级真实标签对网络进行优化.采用2分类交叉熵损失:

(12)
其中,λ2为超参数,M为训练输入视频的批量数,yi∈{0,1}为第i个视频的标签,vidi为第i个视频的预测值,W为模型参数即网络参数惩罚项.
3 实验与分析
3.1 数据集
实验数据集采用中佛罗里达大学犯罪数据集UCF-Crime与上海科技大学发布的ShanghaiTech Campus数据集.UCF-Crime数据集由正常与13类异常(虐待、追捕、纵火、袭击、盗窃、爆炸、打架、道路交通事故、抢劫、射击、商店偷窃、偷盗、破坏公物)共1 900个视频构成,其中异常视频中只包含少数异常片段,我们需要分辨出哪些片段发生异常哪些片段是正常,训练集包含810个异常与800个正常视频,测试集包括正常视频150个与异常视频140个;ShanghaiTech包含13种场景类型的视频,具有不同的光照与拍摄角度,其中异常视频130个,其异常主要表现在人行道的机动车闯入、道路上的打闹以及行人的突然加速等.图2为数据集的部分关键帧.

Fig. 2 Part of keyframes from two datasets
3.2 在UCF-Crime数据集上的实验
3.2.1 实验设置
实验环境:实验服务器配置为Intel CoreTMi9-9720K CPU@2.90 GHz,GPU采用GeForce RTX208 0Ti显存12 GB,内存64 GB.服务器采用Ubuntu18.04系统,编程环境为python3.6,CUDA9.0,Pytorch1.0.0.
参数设置:对视频进行重新调整,每帧大小为224×224.由于不同视频时间尺度差异性较大,对视频进行分段处理,对整个视频划分成无重复区域的32段.利用在ImageNet数据集预训练好的I3D网络模型,对每段视频进行连续16帧RGB图像的特征提取,得到多个1 024维特征块,对片段内得到的所有特征块进行平均处理,即每个视频可以由X∈R32×1 024的特征矩阵表示.将视频特征矩阵送入时空融合图卷积网络,其中设置空间相似图中kS=3,时间连续图kT=2;采用3层图卷积网络,每层维度分别为512,128,1,注意力模块中2层全连接层维度分别为512和1,dropout设置为0.6;采用adagrad优化算法,学习率设置为0.001,学习率衰减为0.000 1,λ1=0.000 08,λ2=0.001.在输入训练样本时每次迭代的批量数为60,其中正包即异常视频为30个,负包即正常视频为30个,共500个epoch.上述实验参数设置与文献[16]保持一致,保证了实验的公平性.
3.2.2 实验结果与分析
评价指标:参照先前研究方案[7-8,16-19],采用帧级标签作为评价标准,得到误报率与召回率度绘制接收者操作曲线(receiver operating characteristic curve, ROC),计算曲线下面积(area under curve, AUC)值,以AUC值和ROC曲线作为最终实验结果的对比参照,AUC值越高模型的判别效果越好.为了判断检测效果,以视频级别标签的误报率以及准确率来检验视频异常检测的性能.
1)k取值分析
为了实现对k取值的选择,按照表1对不同k值进行了选取实验,其中kS为空间相似k值,kT为时间连续性k值.同时考虑到利用高斯核与本文所用方法计算权重是否存在较大差异,作相关实验对比.实验结果在图3中展示,其中折线图展示了本文所用方法在不同情况下的实验结果,在合适的k值上有很大的提升,在kS=3,kT=2时,AUC值最高,但随着k值增加,性能降低.柱状图为采用高斯核的实验结果,高斯核稳定性较强,不随着k值改变发生较大变化.产生此类情况的原因:在利用本文方法构造时,通过固定缩放各个片段之间的联系,增强了相邻的联系,同时也会增强噪声(正常片段)对异常片段的影响,在寻找到合适的k值时这些影响会降到最低,得到的效果最优.使用高斯核时,各个片段之间的联系相对较弱,且高斯核对于k值改变有一定的平滑性,所以改变k值对其影响较小.

Table 1 Different Values of k in 5 cases
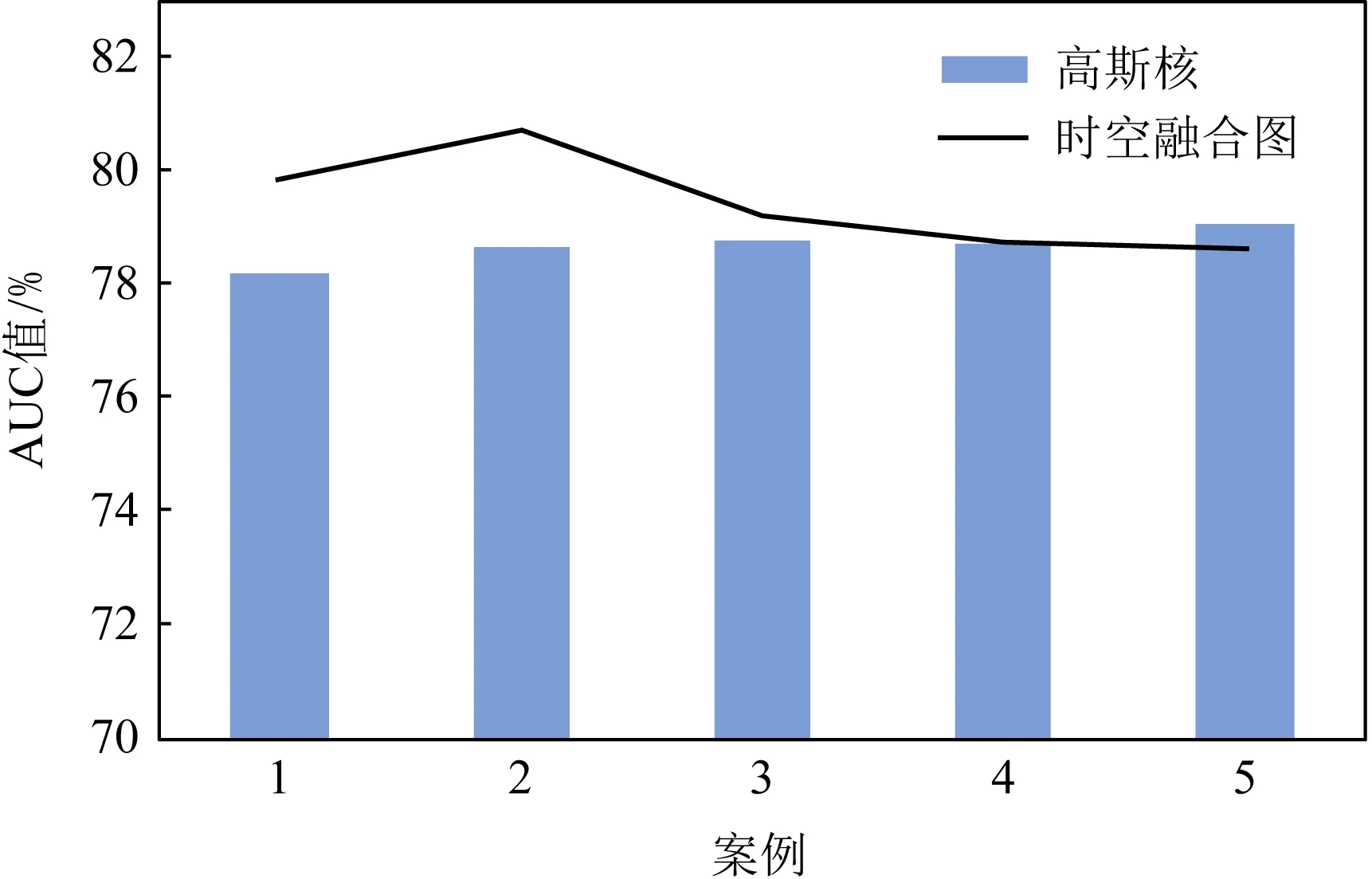
Fig. 3 Result in 5 cases
2) 方法的纵向分析
为了进一步证明采用融合策略的效果以及添加注意力模块得到的视频级异常分类损失(video classification loss, VCL)是否具有提升,进行相关对比实验.表2中详细列举了7种方法的结果.表2中空间相似图只考虑了视频中各个片段的相似性关系,时间连续图为只考虑到时间上的连续关系,平均融合为文献[19]的融合方式,时空融合图为我们的融合方法,实验结果表明单一考虑视频段的联系并不能完整地表达出异常,对两者进行结果的平均在检测鲁棒性上也低于本文采取自适应融合的方法,由此可以证明我们方法的优势.
表2也展示了视频级异常分类损失带来的性能提升.添加该损失后,自适应融合方法提升1.44%;为了进一步证明其有效性,利用提取的I3D特征对基准方法[16]进行了验证,该损失也可以在基准方法上提升2.31%.
同时进一步进行了视频处理速度的实验测试,我们的模型从加载视频数据到获得异常检测结果的处理速率达到68.87 fps,可实现实时异常事件检测.但视频的处理效率依据环境不同会有不同.
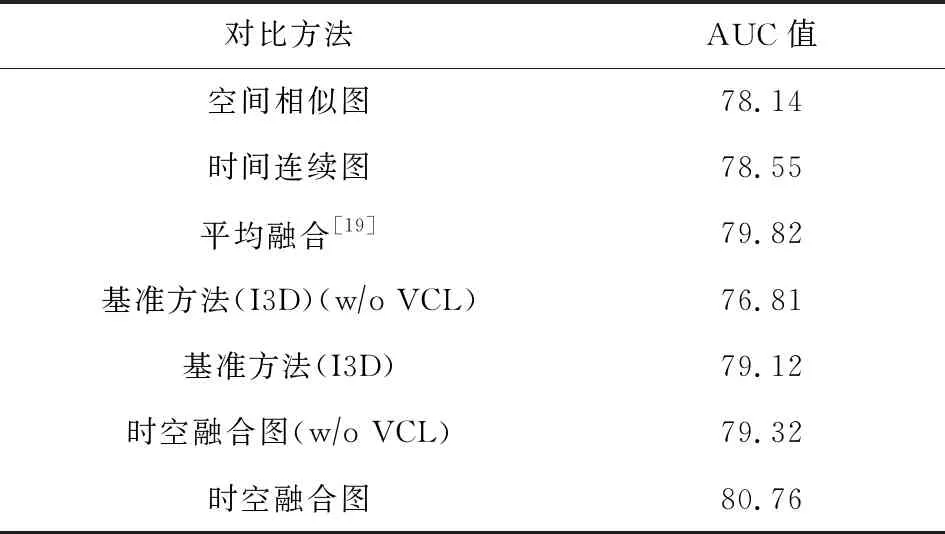
Table 2 Fusion Model Verification on UCF-Crime
3) 与相关方法对比分析
① ROC与AUC值对比.实验与目前针对于UCF-Crime数据集的主流研究方法作对比.图4给出了能够获取到的数据实验结果的ROC曲线,可以看出时空融合图方法(星状形曲线)在帧级的误报率与召回率综合上表现更优.

Fig. 4 ROC comparison on UCF-Crime
表3中给出了对比方法的AUC结果.可以看出,文献[7-8]这2种基于无监督的方法在进行异常检测时AUC较低;文献[16]中利用部分异常信息可以达到75.41%的AUC值,基于时空融合图模型可以取得高于基准方法[16]5.35%的结果,也优于目前遵循基准模型的网络架构的其他方法[14-15];虽然相比于目前最好的算法[19]差1.36%,但我们的方法在特征提取以及训练阶段共用时为30.23 h,文献[19]需要交叉清理训练,进行一次交叉清理训练(包括特征提取与训练阶段)用时为34.56 h.其原因是我们的方法在参数量上更少约为1.1 M,较文献[19]少约1 M的参数个数,同时无须交叉清理训练,故我们的方法训练更简便、快速.

Table 3 Result Comparison on UCF-Crime
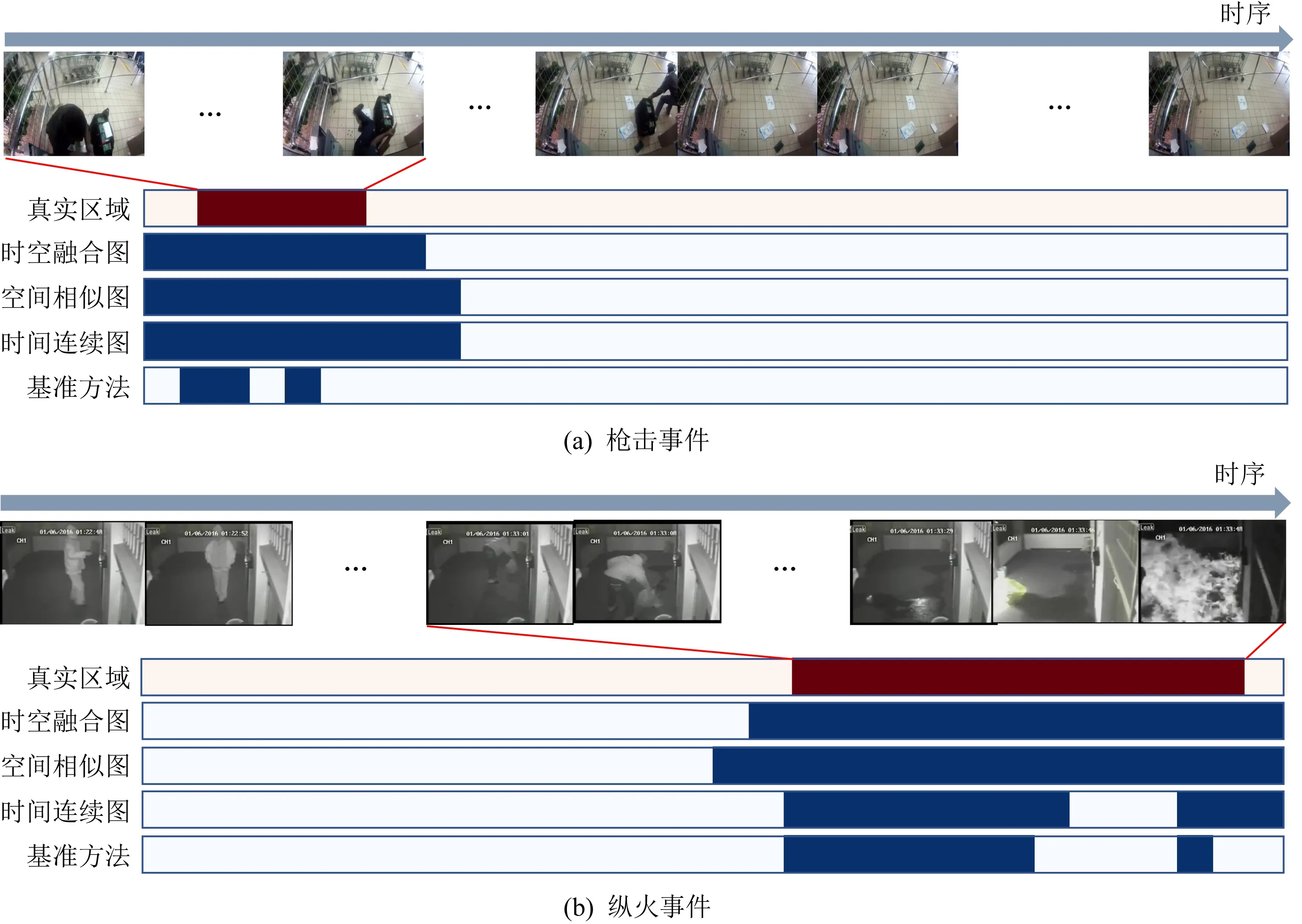
Fig. 5 Results of a few test videos on UCF-Crime
② 误报率与准确率对比.在视频异常检测中,视频级别的异常事件误报率以及准确率性能指标也尤为重要,我们对误报率以及准确率采用视频级别的标签进行评估,取阈值为0.5时得出其混淆矩阵.与所能获取实验结果的方法进行对比,如表4所示,在150个正常测试视频中基准方法误报率为12%,我们方法误报率为8.67%,可以看出所提方法在误报率及准确率方面更优.
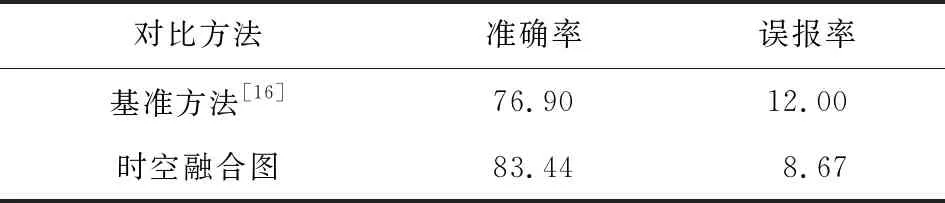
Table 4 Comparation of Accuracy and False Alarm
4) 异常事件检测可视化对比分析
为了更清晰地展现所提出的方法在视频异常事件检测上的效果,利用测试视频作可视化对比分析,均采用每帧异常得分超过0.5作为异常标注.图5展现了采用数据集中枪击案例与纵火案例视频相关方法检测结果的可视化.图5(a)以及图5(b)中真实区域为测试视频中标注的异常帧信息,深色区域为标记的真实异常区域,其下4个深色区域为4种方法检测出的异常区间.时空融合图为本文提出的方法,时间连续图与空间相似图为只考虑单一情况的方法,基准方法为文献[16]所提出的方法.
从图5(a)的枪击案例中可以看出,我们的方法在对异常事件检测时,所检测出的区域能够比较好地覆盖异常区域,而基准方法覆盖度较小且会出现异常事件检测区域的碎片化.从图5(b)的纵火案例中可以看出,在空间相似图和基准方法上,倒汽油与点火之间有部分漏报,而考虑时间连续上的关联则检测得比较全面.较以上方法,我们的方法同样能够比较好地覆盖异常区域,并且体现了能够结合时间连续图与空间相似图的优势,在视频最后阶段由于出现火灾场景而数据集中并没有对其进行异常标记,但是我们的方法给出了预警.由此可看出,由于我们的方法考虑到了片段之间的时空内在关联关系,检测出的区域能更好地覆盖异常事件区域,不会出现异常事件检测区域的碎片化,更符合视频异常事件的检测需求.
3.3 在ShanghaiTech数据集上的实验
该数据集一般用作无监督学习,为了实现弱监督的视频异常事件检测,对数据集重新进行了划分.采用与文献[19]相同的划分方式,从整个数据集采样238个视频作为训练集,其中正常视频175个、异常视频63个;测试集包括199个视频,正常视频155个、异常视频44个,训练集与测试集无重复视频.
3.3.1 实验设置
与UCF-Crime数据集的处理方式相同,将视频上每一帧的大小调整为224×224并对视频做分段处理.利用ImageNet上预训练好的3D卷积神经网络(I3D)提取连续16帧的信息,对一个视频的所有片段作分段并取平均值的处理.将视频特征送入时空融合图网络模型进行训练,在构建图网络时,空间相似图kS=10,时间连续图kT=7,每次迭代的批量数设置为20,其他参数设置与在UCF-Crime上实验保持一致.
3.3.2 实验结果与分析
本节分别与相关方法[12-14,16,19]进行了检测实验的AUC、误报率与准确率的统计以及ROC曲线绘制.
1) ROC与AUC值对比.图6给出了所能获取实验结果的方法的ROC对比图,在ROC指标上我们方法(星状形曲线)具有最优的效果.表5给出了在该数据集上典型的无监督和弱监督的对比方法实验的AUC值,文献[12-14]采用无监督的方式,此类方法由于缺少异常信息的辅助其AUC值最高仅73.20%,检测性能有待提高.文献[16]中方法常作为弱监督方式的基准方法,只对单个片段进行识别导致识别效果不高;文献[19]对异常视频中的正常片段进行了清理,使弱监督演变为全监督的方式,实现了较好的检测效果,但ShanghaiTech数据集异常模式没有UCF-Crime显著,在噪声清理时可能会将异常片段进行清理;在通过控制各个片段之间关联度的条件下,使用时空融合图卷积网络比只考虑单一联系的鲁棒性更强,较基准方法高9.30%,比目前最优方法[19]高5.44%,实现了在此数据集下的最好的检测效果.
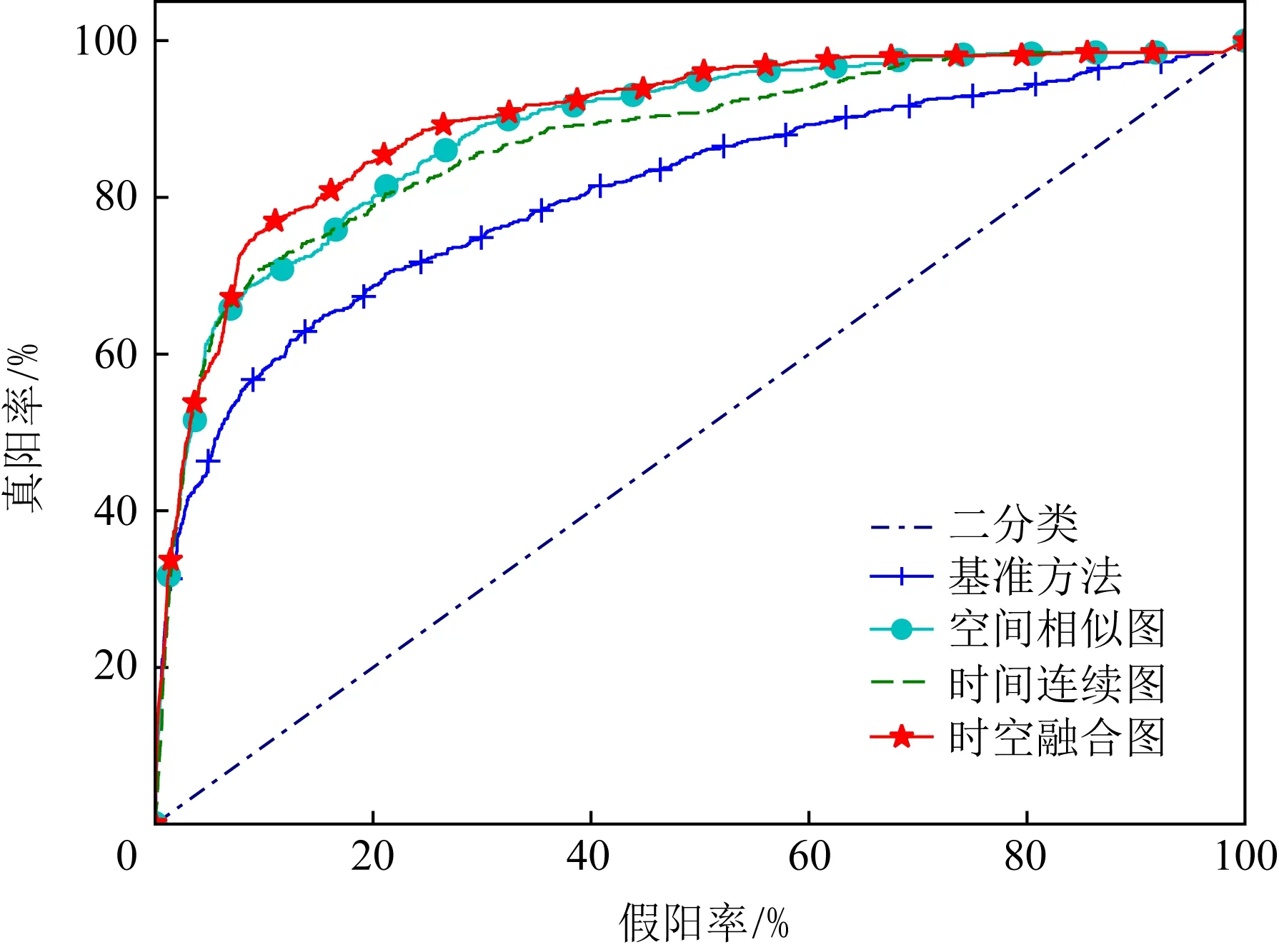
Fig. 6 ROC comparison on ShanghaiTech
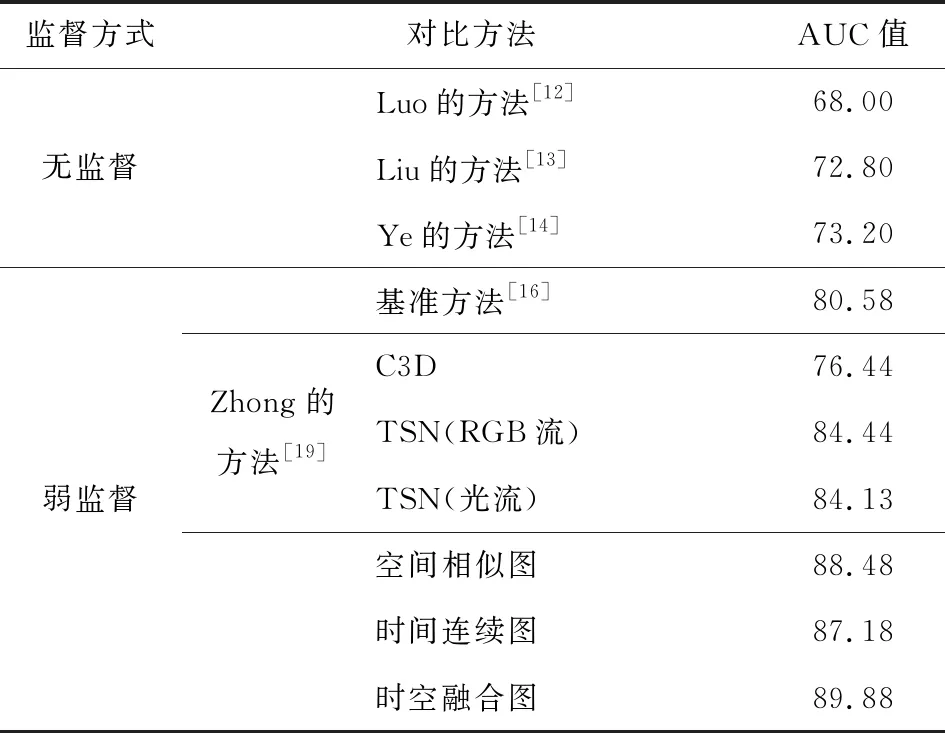
Table 5 AUC Score Comparison on ShanghaiTech
2) 误报率与准确率对比.表6给出了根据视频级的预测值统计的准确率与误报率,在所能获取实验结果的方法对比中可以看出:在基础方法之上,只考虑单一构图增强事件之间的联系情况,模型检测性能有所提升,但相差不大;以本文方法进行时空融合图操作后,在准确率与误报率上均能获得较大提升,也是此数据集下最好的结果.
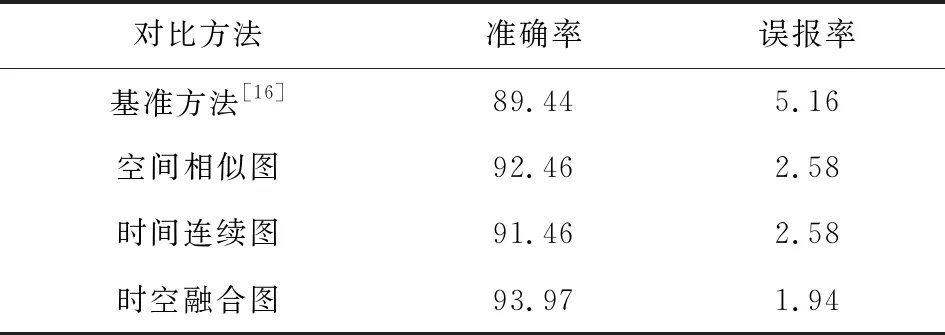
Table 6 Comparation of Accuracy and False Alarm on ShanghaiTech
3.4 性能泛化分析
为了考察模型在真实环境下异常模式多样化的泛化能力,对在一个数据集上训练好的模型进行未知数据集下的测试.我们引入新的暴力检测数据集RWF2000[31]作为未知的数据集,该数据集为暴力斗殴数据集,由2 000个视频构成,组成打架视频与正常视频,每个视频时长均为5 s,帧率为30 fps.取其中400个视频作为测试集(200个打架视频与200个正常视频).表7展示了3个数据集的不同划分方式.UCF-Crime,ShanghaiTech,RWF2000均保持原数据集划分.Mixed-Set为UCF-Crime与ShanghaiTech按照表中数据分布混合构成的数据集,训练集为两者训练集的混合,测试集保持两者的原始划分.
训练策略分为独立训练和混合训练,测试时在3个测试集上分别测试,实验方案如表8所示.ModelU为在UCF-Crime上训练的模型,ModelSH为在ShanghaiTech上训练的模型,ModelM为混合数据集Mixed-Set上训练的模型.
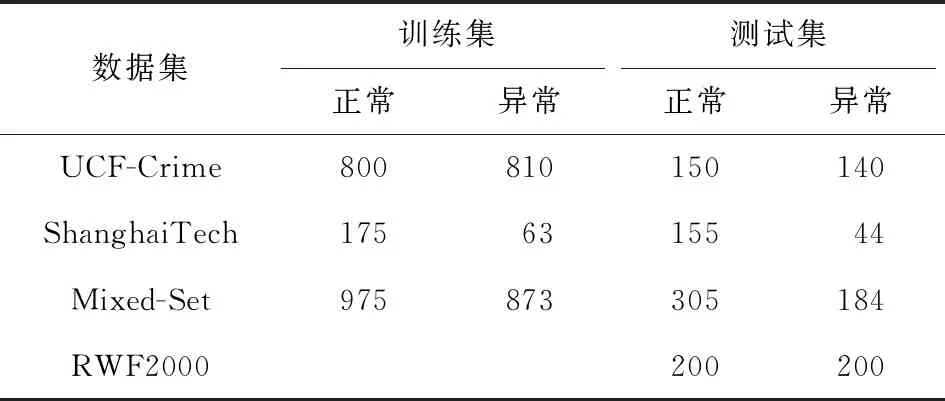
Table 7 Dataset Partition

Table 8 The AUC Score and Accuracy of Different Test Sets
1) 独立训练.如表8中,在ModelU→UCF-Crime (UCF-Crime上训练,UCF-Crime上测试),模型对于同类异常的判别能力具有优势,AUC与准确率相对较高,达到80.76%与83.44%.在未知数据集上测试,ModelU→ShanghaiTech时,AUC值与准确率分别为43.01%与73.37%,在ModelU→RWF2000下测试时准确率为76.19%(此数据集没有帧级标注只取准确率).可以看出:以训练好的ModelU和ModelSH分别在UCF-Crime和ShanghaiTech数据集测试的泛化能力不显著,在RWF2000数据集上有一定的泛化能力.因此对未知数据集进行测试时,模型的泛化能力还有待于提高,其主要原因是不同数据集中异常模式差异较大,UCF-Crime更偏向于宏观的异常;而ShanghaiTech数据集则局限于人的行为上异常,更符合一种微观的异常;RWF2000数据集中的打架斗殴类型和UCF-Crime数据集有相似之处,故ModelU→RWF2000有更好的泛化能力.
2) 混合训练.为了考察数据集混合训练能否达到较理想的测试性能,表8中以ModelM进行了实验测试.在原数据集UCF-Crime与ShanghaiTech上均有较好的泛化能力,在RWF2000上达到71.05%的检测准确率,也具有一定的泛化能力.
4 结 论
针对视频中事件发生的时间特征和空间特征的内在关联性问题,本文将视频片段的特征对应为图中的节点,根据其特征的相似程度和时间差异性分别构建了空间相似性图和时间连续性图.将空间相似性图和时间连续性图进行自适应加权融合,形成时空融合图卷积网络学习生成视频特征,提出了基于时空融合图网络学习的视频异常事件检测方法.在UCF-Crime和ShanghaiTech这2个典型的数据集上进行了充分的实验,实验结果表明:所提出的方法在视频异常事件检测帧级的AUC,ROC和视频级别的准确率、误报率等性能指标方面均达到较高水平.所提出的方法可方便、有效地应用于视频异常事件的检测.由于本文采用预训练的3D卷积神经网络进行特征提取,提取的信息粒度较大,同时在对有镜头切换和运动对象遮挡的问题未深入考虑.下一步将对特征提取网络以及容忍遮挡的关联性度量进行研究,以进一步提升定位精度和检测准确率.此外,对未知数据集的异常事件检测的泛化性能提升还有待于进一步研究.
