面向标签恢复的子集划分迭代投影集成
2021-01-12应晓清袁文野杨正成
应晓清,刘 浩,2*,袁文野,杨正成
(1. 东华大学 信息科学与技术学院,上海201620;2. 人工智能教育部重点实验室,上海200240)
1 引 言
图像特征提取是机器视觉领域的研究热点之一,近年来已有众多的特征提取算法相继被提出,并根据是否标记输入数据可大致分为三类:无监督、监督及半监督学习[1-6]。其中,无监督学习因其可自主探寻数据潜在模式与联系而备受瞩目。 在无监督特征提取中,典型的主成分分析(Principal Component Analysis,PCA)[7]旨 在 线 性 降 维 的 同 时投影数据至由主成分向量所跨越的线性子空间内,以最小的重构误差保留全局方差[8];另一具有代表性的局部保持投影(Locality Preserving Projection,LPP)[9]则可通过恢复原始空间固有的非线性流形结构以保持数据的局部邻域关系,但LPP 技术忽视了全局视角且对噪声数据尤为敏感。 因此,低秩表示(Low-Rank Representation,LRR)[10]因 其 既 对 噪 声 干扰具有强鲁棒性,又可揭示数据全局结构信息,而受到广泛关注[11-16]。为了高效地综合各种技术以使得图像分类稳健而准确,Lu 等人[17]提出一种低秩保留投影(Low-Rank Preserving Projections,LRPP)的图像归类框架,LRPP 框架虽然具有一定的代表性,但执行效果很大程度上取决于样本标签的质量,在噪声环境下分类性能下降明显,导致其在实际应用中可能受到诸多限制[18-20]。 因此,图像特征提取的去噪问题亟待解决。
图像噪声分为标签噪声与特征噪声,其中标签噪声通常更难以学习与推广[21]。针对含噪标签,在不同图像归类框架下已经提出了较多恢复算法可供参考,大致分为标签噪声容忍与标签噪声净化[22-26]。标签噪声容忍仅针对某些特定分类器,缺乏通用性与可扩展性;而标签噪声净化则为一种用于清除或修正部分噪声标签的预处理步骤,具备良好的普遍性[27]。鉴于直接去除含噪样本图像可能导致模型欠拟合或低识别率,因此本文提出一种基于子集划分迭代投影集成(Subset-divided Iterative Projection Bagging,SIPB)的标签恢复算法,可实现在确保样本数据完整性的同时整体提升其标签可信度。首先,该算法随机多次地提取多个小规模子集信息,其次,结合PCA 降维、邻域图正则化等技术确定样本各成分权重并保留数据局部结构,从而构建更为准确合理的低秩投影矩阵,然后,通过K-近邻算法(KNearest Neighbor,KNN)快速预估其余样本标签,并存储各次迭代结果,最后,根据多数投票原则实现类别标签的恢复。基于训练集主要由带有真实标签的样本主导这一先验,本文算法能以此部分可靠信息为基准,进而修正多数错误标签,以高效提升分类器的鲁棒性能,且该算法可灵活运用于各种图像归类框架,具备一定可扩展性与较大实用价值。多次实验表明,本文算法能有效抵抗噪声干扰,较其他标签恢复算法有一定优势。
2 相关工作
2.1 典型的图像归类框架
如前所述,低秩保留投影LRPP 图像归类框架将局部保持投影LPP、稀疏约束及低秩表示LRR 等技术进行高效的集成,实现了图学习与投影学习的有机融合,可在数据整体及局部性间取得较好的平衡,同时具备减弱投影子空间噪声干扰等潜能。尽管已有实验表明该框架面向特征提取表现较为出色,但其忽视标签含噪这一普遍现象,因而在模拟噪声环境下的分类性能并不理想。

图1 标签含噪的LRPP 图像归类框架Fig. 1 LRPP image classification framework with noisy labels
图1 为标签含噪的LRPP 图像归类框架,该框架首先将样本图像划分为训练集与测试集,并依据比例ρ随机替换部分训练集类别标签,以生成训练样本含噪标签集。参数ρ为某样本对应标签被误认作另一类标签的概率,称作标签噪声水平(也可称作丢失率或含噪率),因此ρjk数学形式如式(1)所示:
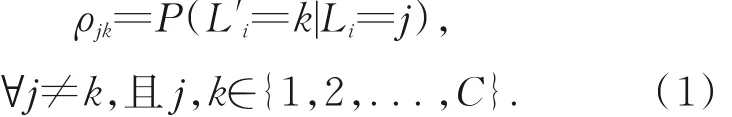
具体地,当ρ=0. 3 时,代表某标记为j的图像xi,有30% 的概率被认定属于另一标记k(k≠j);然后,在LRPP 图像归类框架下依次使用K-近邻准则预估测试集的标签信息,并将预估结果与其真实类别标签比对,进而统计出该归类框架的总体 分 类 精 度(Overall Accuracy,OA)与 卡 帕(Kappa)系数,其中Kappa 系数的计算基于混淆矩阵,其值越大,则代表该归类框架的分类精度越高。
2.2 标签含噪下的分类精度
为排除实验结果偶然性,本节分别选用来自两个基准数据库(即Yale B 与AR 数据库,其详细说明见4. 1 节)的图像样本进行综合分析,且涉及LRPP 图像归类框架的相关参数取值均与文献[17]一致。表1 体现含噪率对图1 所述图像归类框架总体分类精度的影响程度,图2 则展示不同噪声水平下该归类框架的Kappa 系数变化趋势及整体均值,其中含噪率ρ取值区间为[0. 05,0. 4],sele_num为各类样本内所取训练样本数。显然,随着噪声比例逐步增加,该图像归类框架的总体分类精度及Kappa 系数均呈明显下降趋势,当含噪率ρ达0. 4 时,其总体分类精度便已大致由90% 跌落至50%,Kappa 系数也由0. 9 下行至0. 6 左右。由此可见,现有算法对噪声数据较为敏感,需要提出新的样本图像标签去噪算法,以提升图像归类框架的鲁棒性与可靠性。

表1 LRPP 图像归类框架下不同含噪率对总体分类精度的影响Tab. 1 Overall accuracies of LRPP image classification framework with different noise rates (%)
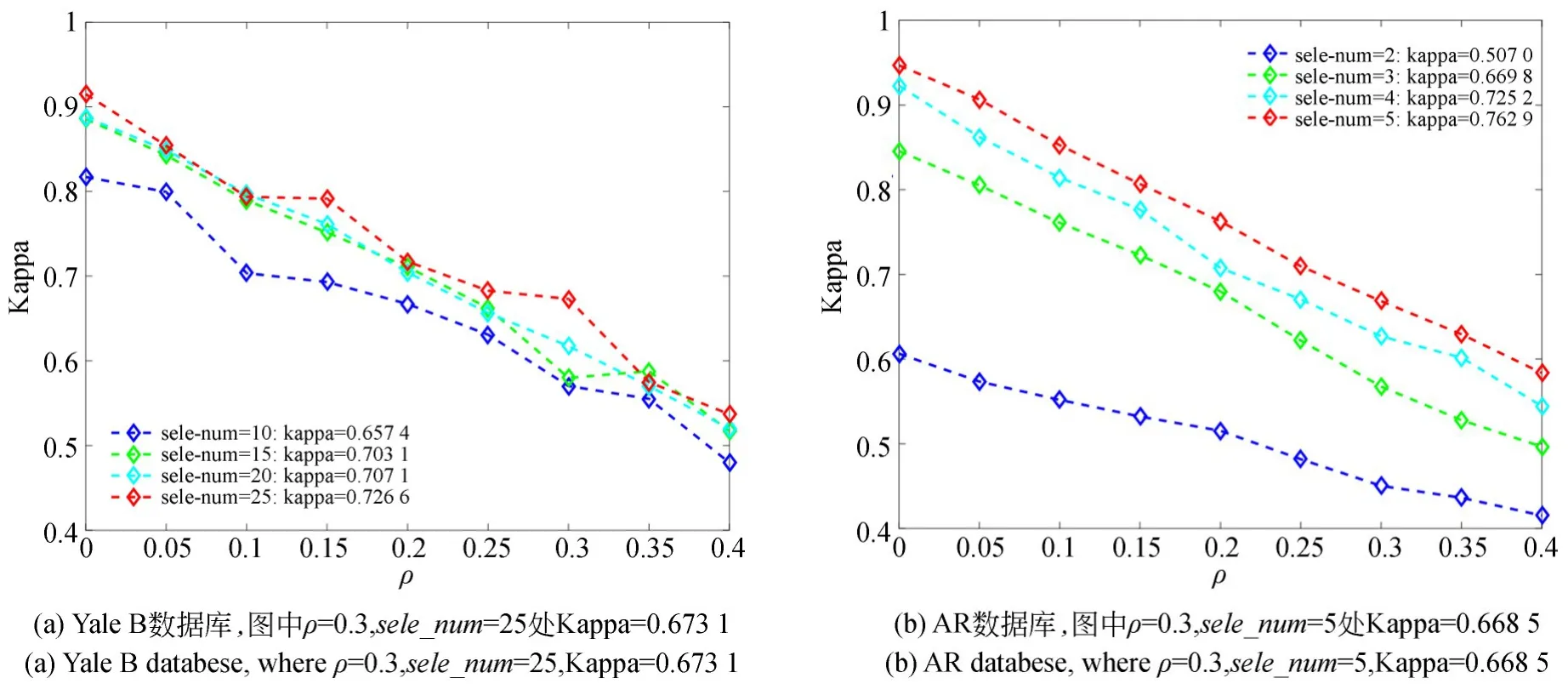
图2 LRPP 图像归类框架下不同含噪率对Kappa 系数的影响Fig. 2 Kappa coefficients of LRPP image classification framework with different noise rates
3 本文算法
为解决上述问题,本文提出一种基于子集划分迭代投影集成的SIPB 标签恢复算法。
给定标签含噪的图像集X,共C类样本标签,其中各幅图像均为N维,共M幅图像,其对应标签分别为L1,L2,. . . ,LM∈{1,2,. . . ,C},将该图像集随机划分为训练集X1与测试集X2。图3 为本文算法具体流程图,说明如下:
Step 1:获 取 样 本 集X1m×N及 其 含 噪 标 签 集L1m×1,初始化当前迭代次数t=1。
Step 2:根据自定义训练集划分比例q,将数据集X1划分为训练集X11与测试集X12,并执行归一化处理。
Step 3:对训练集X11进行PCA 可靠降维,生成其低秩特征向量矩阵P,PCA 可靠降维的具体处理流程如图4 所示。
Step 4:构造训练集X11的最近邻图矩阵W,矩阵W各元素wij可简单定义为:
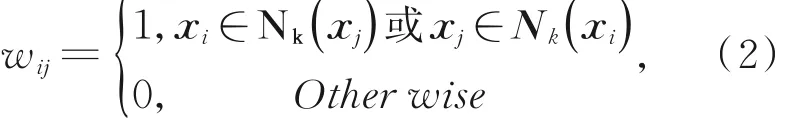
其中:Nk(xj)表示样本xj的k个最近邻域样本,那么wij=1 即表示样本xi在数据分布中位于样本xj的最近邻域,可认为两样本相似且具较大可能性属于同一标签。因此,最近邻图矩阵W获取了样本数据局部信息,可作为构建低秩投影矩阵的基准之一。

图3 SIPB 算法流程图Fig. 3 Flow chart of proposed SIPB method

图4 PCA 可靠降维处理Fig. 4 Flow chart of PCA dimensionality reduction processing
Step 5:构造低秩投影矩阵Q,公式如下:
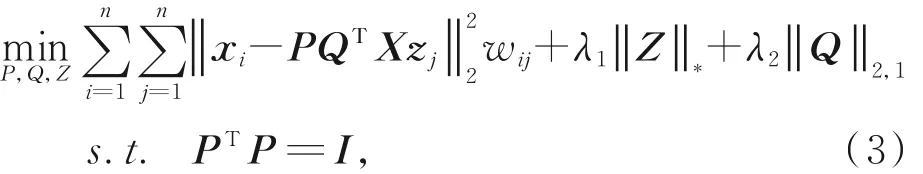
此公式的详细解法请参考文献[28],其中wij为矩阵W的第(i,j)个元素,zj即矩阵Z第j列向量,且此处取Z=W,矩阵P即训练集X11经PCA可靠降维所得的低秩特征向量矩阵,PQTXzj可视作原始样本xj的重构样本,表示两样本间的欧氏距 离。‖Z‖*即矩阵Z核范 数,为矩 阵Z的奇异 值 总和 。‖Q‖2,1为 低 秩 投 影 矩 阵Q的l2,1范 数 ,通过施加l2,1范数约束,矩阵Q可自主提取出样本的首要特征,并具有高可解释性。λ1,λ2为用于平衡相应项重要性的正则化参数,可于候选集{10-5,10-4,10-3,10-2,10-1,1,101,102,103,104,105}内择优选取。矩阵Q构造完毕后,通过X′11=QTX11,X′12=QTX12得出训练集、测试集的低秩表示矩阵。
Step 6:计算并归一化训练集、测试集的低秩表示矩阵,再将其与训练集含噪标签共同输入K-近邻分类器,预估测试集的样本标签。
Step 7:重复上述Step 2~Step 6,直至当前迭代次数t=te(te为预设的迭代阈值)。 构建矩阵Yte×m,将各次迭代所得的各样本标签信息均逐个按位存入该矩阵,表示形式为若经第t次迭代得出第i个样本对应标签为j,则Yt,i=j;最后,分析矩阵Y内各样本的te个标签,根据多数投票原则可输出训练样本的标签恢复矩阵L′1。
本文所提标签恢复算法作为一种数据预处理手段,可灵活运用于各种图像归类框架,以最大限度确保分类结果不为错误标签所误导,高效再利用含噪样本,相较于其他标签恢复算法更能提升系统的鲁棒性与可靠性。
4 实验与分析
4.1 实验说明
本文仿真实验平台如下:Intel i5-6200U CPU、8 GB 内存、Windows 10 操作系统、MATLAB R2016a。实验数据集选择广泛应用于图像检测与识别的Yale B 及AR 人脸数据库。Yale B数据库包含来自38 个对象的2 414 张面部图像,各对象提供约59~64 个样本。AR 数据库包含来自120 个对象的1 680 张面部图像,各对象提供14 个样本。实验前对上述图像集均进行裁切及灰度处理,并使用PCA 降维处理保留98% 的能量以提升算法运算速率。实验过程中随机从各类样本内提取sele_num数量样本作为训练集,其余样本作为测试集,并选用在同一图像归类框架(即LRPP 图像归类框架)下各算法的总体分类精度OA 及Kappa 系数作为评价指标,以便更为简单直观的衡量算法性能,且其中涉及LRPP 图像归类框架的相关参数均参照文献[17]进行设置。为模拟样本标签含噪的真实场景,本文选取各种典型丢失率(5%~40%),并采用含噪标签随机生成算法预处理训练数据,随机数生成器使用同一种子,以便针对不同情况产生重复的随机突发或随机丢失,保证实验更加公平有效。
4.2 实验结果与分析
本文SIPB 算法实验参数包括各类样本内所取训练样本数sele_num、训练集划分比例q及迭代阈值te。各参数默认值为sele_num=25(Yale B)或5(AR),q=0. 3,te=50。为探求本文算法的最优参数取值区间,下述实验1~3 分别以上述各参数为唯一影响因子,在LRPP 图像归类框架下将本文算法与LRPP 缺省算法进行对比分析,其中丢失率均取ρ=0. 3;实验4 则在各种典型丢失率下对不同标签恢复算法进行综合比较,以客观评估本文算法性能优劣。
4.2.1 本文算法最优参数取值分析
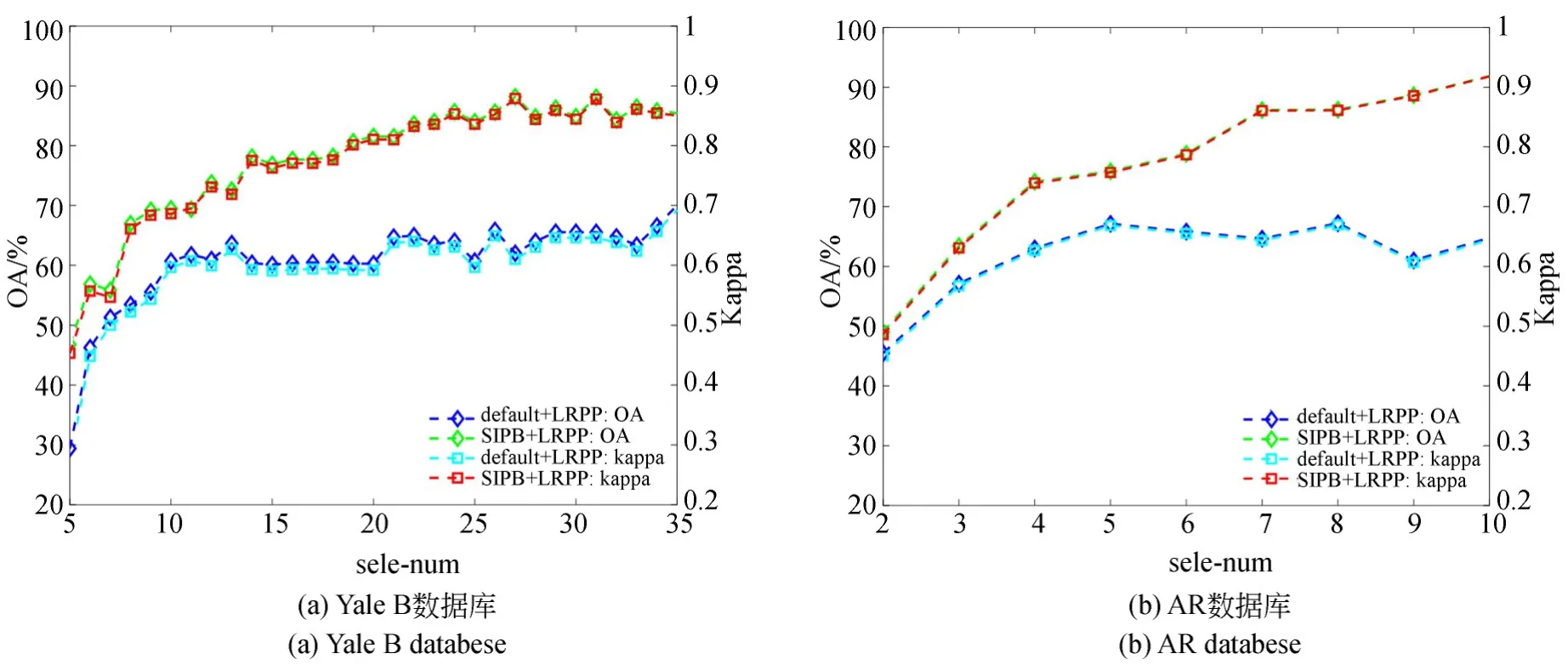
图5 各类样本内所取训练样本数sele_num 不同时各算法性能对比曲线Fig. 5 Performance comparison of different methods under different sele_num values
实验1:本实验以各类样本内所取训练样本数sele_num为唯一变量,其余参数均设默认值。各算法总体分类精度OA 及Kappa 系数变化对比曲线如图5 所示,由图可知,在sele_num的各取值范围内,本文算法均优于LRPP 缺省算法,且随着该参数数值增加,二者差异始终较为显著。这表明输入含噪训练样本集的规模在较大范围内变动时,本文算法性能相较于LRPP 缺省算法均占据一定优势。
实验2:表2 列出各训练集划分比例q下本文算法的总体分类精度OA 及Kappa 系数,而LRPP 缺省算法的实验结果可分别于2. 2 节表1、图2 内获得。比较结果可知,q∈[0. 2,0. 25]时 本文算法表现最为出色,相较于缺省算法,其分类精度分别提升20. 423 5% 与10. 926 0%,Kappa 数值分别增加0. 179 6 与0. 110 2。且即使q取值较大或较小,本文SIPB 算法亦大多能够有效缓解噪声对图像归类框架的干扰,达到较好的分类效果。
实验3:表3 体现预设不同迭代阈值te对本文算法性能的影响,而LRPP 缺省算法的实验结果与实验2 相同,可分别于2. 2 节表1、图2 内获得。由实验数据可得,少次迭代时本文算法效果平平,而随着迭代阈值te增加,该算法的总体分类精度OA 及Kappa 系数迅速提升,且相较于缺省算法表现出更好性能。迭代阈值取值较大时,本文算法各指标增长速度虽有所放缓,但总体走向仍保持不变,呈上升趋势。

表2 各训练集划分比例下本文算法性能对比Tab. 2 Performance comparison of the proposed method under different q values
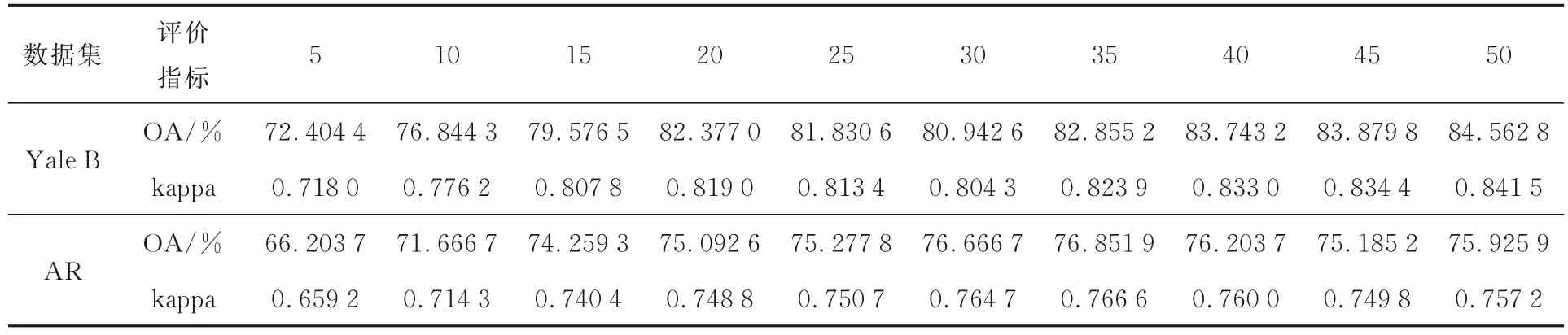
表3 各迭代阈值下本文算法性能对比Tab. 3 Performance comparison of the proposed method under different t values
4.2.2 本文算法性能评估
本节在LRPP 图像归类框架下对四种典型的标签恢复算法,即LRPP 缺省算法、图正则重建(Graph Regularized Reconstruction,GRR)算法[28]、稳 健 图 构 造(Robust Graph Construction,RGC)算法[29]及本文SIPB 算法,于不同丢失率下对噪声数据的鲁棒性能进行比较。其中,GRR 算法引入具有正交约束的数据重构项,增强了模型局部特征的保留能力及样本辨别力;RGC 算法则能改善由损坏数据集所获的低阶恢复,为近年所提的一种鲁棒图学习方法。综合实验1~实验3的结论,选定本文算法各参数值为sele_num=25(Yale B)或5(AR),q=0. 23,te=50。
表4 和表5 对各算法的总体分类精度做出比较,可看出,在各种丢失率下本文算法均明显优于缺省算法,其分类精度增益最高分别为27. 732 3% 与9. 907 4%,平均增益分别为16. 939 8% 与8. 136 5%;本文算法相较于GRR算法也优势明显,其分类精度增益最高分别为25. 273 3% 与7. 406 4%,平均增益分别为14. 856 5% 与6. 111 0%;对比RGC 算法,本文算法分类精度至多提升7. 035 5% 与6. 481 4%,均值提升4. 320 3% 与4. 687 5%。图6 则展示不同丢失率下各算法Kappa 系数的变化趋势及整体均值。由图可知,随着丢失率上升,各算法Kappa系数虽均有所下降,但本文算法性能表现始终更为出众,其Kappa 均值分别为0. 866 3 与0. 822 0。

表4 在Yale B 数据库内不同丢失率下总体分类精度对比Tab. 4 Overall accuracies of different methods on the Yale B database (%)

表5 在AR 数据库内不同丢失率下总体分类精度对比Tab. 5 Overall accuracies of different methods on the AR database (%)
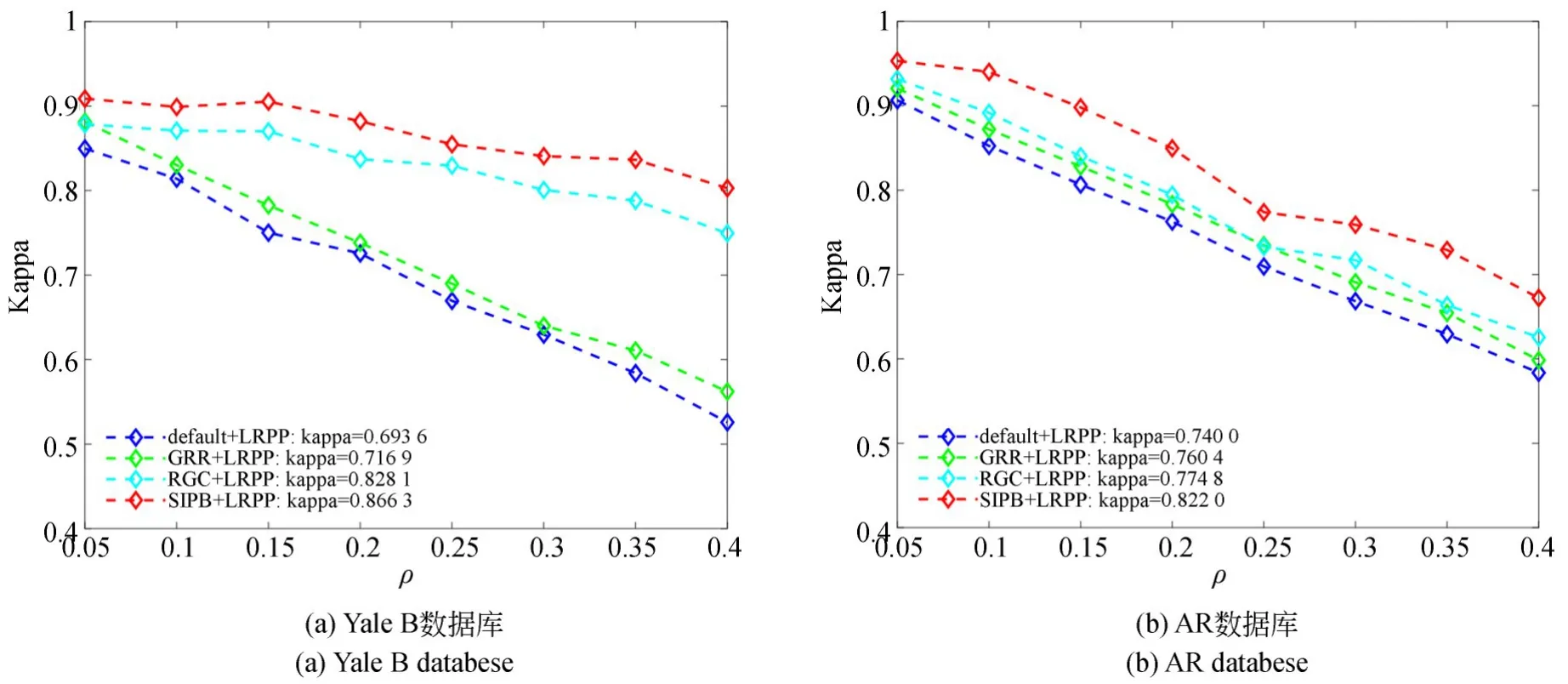
图6 在两大数据库内不同丢失率下kappa 系数变化的对比曲线Fig. 6 Kappa coefficients under different noise rates on the two databases
综上所述,在同一归类框架下本文SIPB 算法的整体降噪性能更优,可有效提升数据标签可信度,改善系统的鲁棒性与可靠性。值得一提的是,本文算法在AR 数据库内的实验性能略低于在Yale B 数据库内的实验性能,其原因在于本文所选AR 数据库样本总数较少而标签种类较多,使得算法执行过程中可供参考的真实信息相对不足,较易产生错误识别,导致最终的标签恢复效果相对不显著。
5 结 论
本文提出了一种基于子集划分迭代投影集成的标签恢复算法。该算法首先通过随机多次地提取小规模子集信息,并结合主成分分析、邻域图正则化等技术构建准确可靠的低秩投影矩阵,随后通过K-近邻算法进行标签预估与迭代集成,最后根据多数投票原则实现类别标签的有效复原。多次不同数据集下的实验表明:本文算法可有效缓解噪声干扰,在同一图像归类框架下针对Yale B 与AR 数据库分别使分类精度提升了16. 9% 与8. 1%;相较于目前最好的标签恢复算法,本文算法可提升4. 3%~4. 7% 的分类精度,能够在确保样本数据完整性的同时改善系统的鲁棒性与可靠性。此外,本文算法还可直接嵌套于现有各种图像归类框架,具备一定可扩展性与较大实用价值。由于真实标签噪声的形式与数量或许难以预知,甚至具有对抗性,后续研究中还需进一步探索如何处理此类噪声。子集划分及迭代运算带来了计算复杂度的提升,后续工作也需要探究子集与迭代阈值的自适应选取机制。
