基于StarGAN和子空间学习的缺失多视图聚类
2021-01-05刘小兰叶泽慧
刘小兰 叶泽慧
(华南理工大学 数学学院,广东 广州 510640)
现实世界中的许多数据集由不同的表示或视图组成。对于同一个数据,可以根据该数据的不同特征进行划分,每种特征代表一种视图数据。例如,网页可通过文本或网页链接的形式获取数据,从而构成两个视图的多视图数据;同一个故事可以在不同的新闻中被讲述,一份文件可以被翻译成多种不同的语言等等。通常,多视图为语义相同的数据提供兼容和互补信息,因此将它们集成在一起能获得比单视图更好的性能[1]。多视图聚类的目的是基于对象的多个表示将对象划分为若干个簇。近年来利用多视图数据的互补性和一致性,研究者们提出了很多多视图聚类算法。现有的多视图聚类算法大致可分为4类。第1类方法是基于子空间的方法[2- 6],这些方法学习一个潜在空间,将不同视图的数据都投影到这个潜在空间。第2类方法是基于协同训练的方法[7- 9],这些方法用迭代聚类的方式获得聚类结果。第3类称为后期融合[10- 12],它通过投票或其他融合策略将不同视图的聚类结果结合起来。最后一类方法是在多视图数据之间学习一个一致的、可用于最终聚类的相似矩阵[13]。
应该指出的是,以前的多视图聚类方法通常假定所有视图都具有完整的信息,即数据库中的每个视图都具有完整的特征集。然而,在实际应用中,经常会出现一些视图缺少信息的情况。例如,一份损坏的文件有英语和中文两个版本,即英语和中文分别为文件的两个视图,并且这两个视图都存在信息缺失,现在需要对文件里的内容进行聚类,由此产生了缺失多视图聚类问题。针对缺失多视图聚类问题,常见的方法可分为两大类。第1类是基于核的方法。RAI等[14]和Shao等[15]提出补全不完全多视图核矩阵的方法,然后使用基于内核的聚类方法进行聚类。然而,这些方法只能处理基于核的多视图聚类算法,这极大地限制了它们扩展到更广泛的多视图聚类方法。第2类是基于非负矩阵分解(NMF)的方法。Li等[16]提出了一种基于非负矩阵分解的缺失多视图聚类方法PVC,但它只能处理两个视图的问题。Shao等[17]提出了一种鲁棒的带l2,1正则化的加权非负矩阵分解的缺失多视图聚类算法MIC。Rai等[18]探索每个视图中数据分布的内在几何结构,将PVC方法扩展到两个视图以上的情况,并考虑了各个视图的图拉普拉斯正则化,提出了GPMVC算法。Zhao等[19]考虑了多视图数据的紧凑全局结构,通过拉普拉斯项将不同视图缺失的样本数据连接起来。Yin等[1]对缺失多视图数据学习统一的潜在表示和投影矩阵,所学的潜在表示即为归一化指标矩阵的一个近似。Xu等[20]提出了一种同时进行潜在表示学习和子空间聚类的统一框架。然而,这些方法都有一些局限性,限制了其应用:
(1)利用非负矩阵分解来学习数据的潜在表示,它不能很好地处理带有负特征表示的数据。
(2)非负矩阵分解方法利用了正则化方法来约束新表示,因此在每个视图中没有显式地补全丢失的数据。
针对上述问题,受到文献[21]提出的生成式方法的启发,考虑先补全各视图缺失的数据,然后再用完整的多视图聚类方法对多视图数据进行聚类。也就是说,通过直接补全缺失的样本,缺失多视图聚类问题可以转化为完整的多视图聚类问题,这使得在进行聚类任务时,对于聚类模型的选择可以更广泛。极大似然估计法、近似法、马尔科夫链法等都是传统的生成式方法。最近,基于深度神经网络(DNN)构建的生成式模型在图像合成、图像转换、超分辨率成像和人脸图像合成等方面都获得了成功,典型的网络结构包括循环神经网络(RNN)[22]、卷积神经网络(CNN)[23]、变分自编码器(VAE)[24]和生成对抗网络(GAN)[25- 28]等。其中,GAN避免了马尔科夫链式的学习机制的缺点,当真实数据样本概率密度不可计算时,模型依然可以应用[29]。它在结构上受博弈论中二人零和博弈启发,通过构建生成模型和判别模型捕捉真实数据样本的潜在分布并生成新的数据样本。例如,Isola等[26]利用配对训练数据的条件生成对抗网络[28]将图像从一种分布转移到另一种分布,并发展了Pix2Pix生成对抗网络,在图像成对转换工作中取得了不错的结果。可是,Pix2Pix只适用于成对的图像。为了解决这个问题,Zhu等[27]提出了循环生成对抗网络,它利用循环一致性损失保存输入和转换后的图像之间的关键属性来训练未配对图像,具有比Pix2Pix生成对抗网络更好的性能。但无论是 Pix2Pix生成对抗网络还是循环生成对抗网络,都只解决了从一个域到另一个域的图像转换问题。当有很多域需要转换时,对于每一对域转换,都需要重新训练一个模型去解决。也就是说,对于含有K个域的转换问题,循环生成对抗网络等需要学习K*(K-1)个生成模型。最近,Choi等[30]提出的星型生成对抗网络(StarGAN),通过加入一个域的控制信息,解决了多域间的转换问题,它仅需要学习一个模型,并且具有更好的效果。
文献[21]中基于循环生成对抗网络提出了一种缺失多视图聚类方法CGPMVC。CGPMVC不仅可以捕获良好的聚类结构,还推断出缺失的视图数据。然而,CGPMVC存在两个缺陷。第一,CGPMVC是基于循环生成对抗网络提出的,所以它继承了循环生成对抗网络的缺点,即当有很多域需要转换时,对于每一对域转换,都需要重新训练一个模型去解决,这可能导致模型难以训练且过于复杂。第二,CGPMVC没有充分利用视图的信息,对于3个及以上的缺失多视图,它没有考虑到不同视图对对应的生成模型生成的数据之间的联系,即它的每对生成模型是割裂的。对于3个及以上的缺失多视图聚类问题,考虑到StarGAN仅需要学习一个生成模型,通过加入一个控制信息就能指导各缺失视图数据的生成,并建立各个视图的联系,文中提出了一种基于StarGAN和子空间学习的缺失多视图聚类模型SSPMVC。SSPMVC首先构建基于DNN的编码模型将多视图数据映射至同一表征空间,然后将编码后的多视图数据通过基于StarGAN的生成模型生成其它视图缺失的数据。这里的生成模型仅要学习一个生成器就可以生成多个视图缺失的数据,并且充分考虑了各视图数据之间的完整性与一致性。接着构建一个基于子空间的聚类模型,该聚类模型利用各视图数据的互补性学习了一个具有良好聚类性质的潜在子空间结构。它将学习的各个视图的低维相似矩阵进行融合,得到包含所有视图信息的相似矩阵,最后进行谱聚类。在几个多视图数据库上的实验验证了本文中提出算法的有效性。
1 相关工作

1.1 多视图子空间聚类

近年来,许多论文[34- 38]致力于利用输入数据的自表示和对自表示矩阵添加约束得到一个良好的相似矩阵。更具体地说,对数据M∈Rd×n(每列为一个数据),通过求解下面的优化问题来得到相似矩阵C:
(1)
式中,d表示数据的维数,n表示数据的个数,C∈Rn×n对应M的自表示矩阵,||·||F表示Frobenius范数,R(C)表示正则化条件。这些方法的主要区别在于R(C)的选择。例如,稀疏子空间聚类(SSC)[39]中的C用“l1-范数”使C成为稀疏的,而低秩表示(LRR)[34]的C则采用核范数作为R(·),使C成为低秩的。求得C后,通过A=|C|+|CT|建立一个亲和矩阵,然后对A进行谱聚类,最终得到数据的聚类结果。
文献[2- 6,13,38- 39]中将上述单视图子空间聚类算法推广到了多视图子空间聚类算法。多视图子空间聚类模型的一般描述如下:
(2)
式中,Xi,Ci分别表示第i个视图的原数据和其对应的子空间表示,R(Ci)为正则项。根据正则项R(Ci)的不同,这些多视图子空间聚类方法可分为3类。第1类方法学习不同视图间的互补信息[13,38]。第2类方法学习不同视图间的共享结构,保证视图间聚类结果的一致性[5- 6]。第3类方法是前面两种方法的结合,它同时学习视图间的互补性和一致性,更全面地描述多视图数据[39]。
1.2 星型生成对抗网络(StarGAN)
近年来,生成对抗网络在图像生成、图像转换、超分辨率成像以及人脸图像合成等计算机视觉任务中取得了不错的效果[25- 26,30,40]。典型的生成对抗模型由两个模块组成:鉴别器和生成器。生成器G的主要作用是生成图片,即输入一个随机编码z,生成假样本G(z)。判别器D的主要作用是判断输入是否为真实图片并提供反馈机制。
由于很多图像转换工作在处理多个域的图像转换任务时,效率都比较低,因为必须为每对域训练不同的模型。这就导致它们没有充分利用训练数据,影响了生成的图像的质量。星型生成对抗网络StarGAN[30]的提出解决了这些问题,它仅用一个模型就实现了多个域的转换。StarGAN的网络结构如图1所示。假定x为输入的图片,b′为原域,b为目标域。训练生成器G时,StarGAN将(x,b)作为生成器的输入,生成假图片x′,再将(x′,b′)输入生成器G,用它重构图片x。训练鉴别器D时,将(x,b′)和(x′,b)作为鉴别器的输入,鉴别器要学会判断图片是否真实以及将图片分类到其对应的域中。StarGAN的主要工作如下:
(1)为了指导各个域图像的生成,在生成器G的输入中添加目标领域信息b,得到对抗损失Ladv:
Ladv=Ex[logDsrc(x)]+
Ex,c[log(1-Dsrc(G(x,b)))]
(3)
式中,Dsrc(x)为鉴别器D给出的数据的概率分布。

(4)
(5)
式中,Dcls(b′|x)代表由D计算的原域b′上的概率分布。
(3)为了保证图像转换过程中图像内容的保存,只改变域差异的部分信息,引入图像重构。图像重构是指图像从原始域转换到目标域,再将转化后的目标域中的图像转换回原域,要保证转换后的图像与原图像一致,于是得到循环一致性损失Lrec:
Lrec=Ex,b,b′[||x-G(G(x,b),b′)||1]
(6)

图1 StarGAN框架
2 基于StarGAN和子空间学习的缺失多视图聚类
基于神经网络的缺失多视图聚类方法CGPMVC[21],虽然利用已有的数据信息推断出了缺失的视图信息,但对于每一对视图,都需要训练一个模型去生成缺失的数据,并且没有考虑到不同生成模型生成的数据之间的关系。考虑到StarGAN能有效处理多于两个视图的缺失视图的生成问题,基于自表示的多视图子空间聚类算法能很好学习不同视图间的互补信息,提出了一种基于StarGAN和子空间学习的缺失多视图聚类方法SSPMVC。SSPMVC算法的网络框架如图2所示。SSPMVC算法将数据生成过程和子空间学习过程结合,充分利用已有的数据信息。首先补全缺失的数据,生成完整的多视图数据,然后学习各个完整视图的子空间表示,并将它们的信息融合,得到包含所有视图信息的相似矩阵,再将该矩阵用于谱聚,以获得更好的聚类结果。

图2 模型框架
2.1 基于StarGAN的多视图数据生成模型

(7)
将多视图数据映射到同一潜在空间后,接下来就要用得到的表征向量来生成各个缺失视图的数据。传统的对抗网络只以随机变量z作为模型的输入,无法指定生成器生成某一特定视图对应的数据。为此采用StarGAN的思想,在生成器和鉴别器引入条件变量b,来指导各个视图数据的生成,得到对抗损失如下:
(8)

下面以三视图缺失数据的生成为例加以说明。三视图数据的缺失情况如图3所示,包括6种情况。对于图3中间的3种情况,每个实例仅在一个视图上有数据,可以由该已知视图上的数据去生成缺失视图对应的数据。对于最后一列的3种情况,也可以由已知视图上的数据去生成缺失视图对应的数据,不过这时每个实例在多个视图上存在样本。对每个实例,每次随机挑选两个视图上的样本,用这两个样本分别生成缺失视图上的样本,这时要保证它们生成的样本是一致的,于是得到如下的生成损失:
(9)
式中,ak∈Xk、al∈Xl为同一实例在视图k、l上对应的样本,且该实例在视图j不存在对应的样本。生成损失充分考虑了视图间的兼容性和互补性,利用已有的视图信息,保证了生成数据的一致性。

图3 多视图的缺失情况

(10)
(11)
式中,Dcls(b|xi)代表由D计算的域标签上的概率分布。
通过最小化自编码损失、对抗损失和分类损失,训练生成器G可以生成真实且被分类到其正确目标域的数据。然而,生成模型仅被训练成将输入数据映射到目标域中的任意样本。这说明了仅靠这三个目标损失不能保证视图间的数据一一对应。对于每一个样本,在通过周期循环后,应该被重构回本身,即生成器应该将给定样本映射到期望的输出。为此,引入StarGAN的循环一致性损失:
(12)
2.2 基于子空间学习的多视图聚类模型
通过上一小节,已经训练了生成器和鉴别器,以生成多视图缺失的数据。这一小节主要是构造一个用于实现聚类的模型。
子空间聚类利用原始数据的自表示特性,即每个数据点可以通过数据本身的有效组合来重建,来探索潜在子空间结构。受到文献[2- 6,9- 13,34- 38]的启发,尝试构建一个基于子空间的多视图聚类模型。首先学习各个视图的自表示,目标函数如下:
(13)

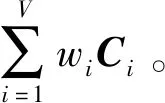
(14)
注意到引入权重向量W∈RV的l2范数作为正则项,是为了避免平凡解,即W中仅有一个wi等于1,其它的都为0。这意味着只有一个视图起作用,而其它视图没有贡献。
综上所述,得到聚类模型的损失函数:
(15)
2.3 模型求解
综合2.1和2.2节,可以得到SSPMVC的优化模型如下:
LG=λAE×LAE+λadv×Ladv+λgen×Lgen+
λcls×Lcls+λrec×Lrec
(16)
LGC=LG+λC×LC
(17)
(18)
式中:LG是生成器的损失函数;LGC是生成损失和聚类损失函数;LD是鉴别器的损失函数;λAE、λadv、λgen、λcls、λrec、λc是用于平衡自编码损失、对抗损失、生成损失、分类损失、循环一致损失和聚类损失的超参数。
为了使生成模型和聚类模型互相促进,SSPMVC交替优化生成模型和聚类模型的参数。其中,LGC优化学习编码器、解码器、生成器和聚类模型的参数,LD优化学习鉴别器的参数,并且每优化4或5次模型的其它参数,再优化1次鉴别器的参数。
同时,为了使生成器也能更好地捕捉各个视图的特征,还将自编码损失LAE修改为
(19)
SSPMVC算法的具体步骤和过程见算法1。

算法1 #SSPMVC算法
输入:缺失多视图数据集合X={X1,…,Xi,…,Xv},参数λAE、λadv、λgen、λcls、λrec、λc、λ1、λ2、λ3迭代次数Max,批处理数S。
步骤1 训练星型生成对抗网络
1.for epoch=1 to Max:
2.从V个视图各挑选S个对应相同的样本,若存在视图不存在某个样本,从该视图随机挑选一个样本代替;
3.计算式(16);
4.更新鉴别器D的参数;
5.if epoch%5==0:
6.计算式(18);
8.end if
9.end for
步骤2 训练完整网络
10.for epoch=1 to Max:
11.从V个视图各挑选S个对应相同的样本,若存在视图不存在某个样本,从该视图随机挑选一个样本代替;
12.计算式(16);
13.更新鉴别器D的参数;
14.if epoch%5==0:
15.计算式(18);
17.end if
18.end for
输出:C*
3 实验分析
本节中将本文提出的算法SSPMVC在4个数据库(3Sources、COIL20、UCI Digit、MNIST)上与一些先进的缺失多视图聚类方法,包括传统的缺失多视图聚类方法PVC[16]、MIC[17]、GPMVC[18]以及基于神经网络的多视图聚类方法CGPMVC[21]进行了比较。
3.1 数据库
实验采用的4个数据库:3Sources,COIL20,UCI Digit和MNIST的详细信息如表1所示。
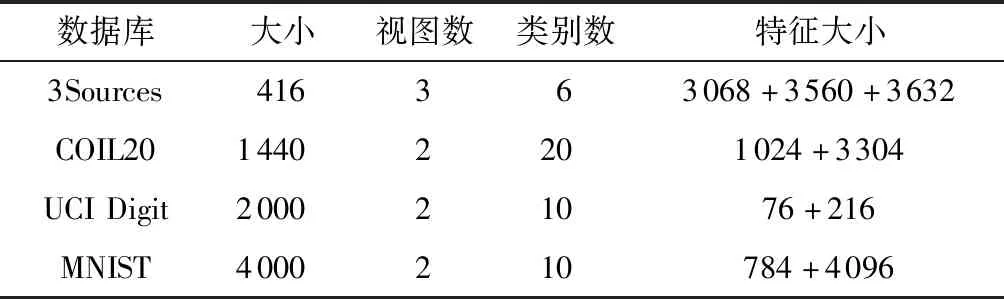
表1 数据集描述
3Sources:它来自3个在线新闻源:BBC,Reuters和Guardian,每个新闻源都可以看作是新闻报道的一个视图。总共有948篇报道,包含416个不同的新闻报道。在这些不同的故事中,有169个在所有3个新闻源中均有报告,194个在两个新闻源中有报告,53个出现在单一新闻源中。每个故事都有6个主题标签之一:商业、娱乐、健康、政治、体育、科技。其中,BBC、Reuters和Guardian新闻源的缺失率分别为15.38%、29.33%、27.40%。用IF-TDF对这3个视图进行预处理,得到3 068维的BBC特征,3 560维的Guardian特征和3 632维的Reuters特征。
COIL20:由1 440幅图像组成,有20个类别,每个类别有72个角度。同样的,实验提取它的两个不同的特征:1 024维的Intensity特征和3 304维的LBP特征,构成两个视图的数据。
UCI Digit:由从0到9的10个类组成的包含 2 000 幅图像的手写数字数据库。每个类包含200个样本,一共有5个特征。在实验中,选取其中两个特征:76维的Fourier coefficients和216维的Profile coefficients,构成两个视图的数据。
MNIST:它是一个手写数字图像数据集,每个图像裁剪为28×28像素。类似于论文[21]的实验设置,随机选择4 000个图像作为一个子集。论文用VGG网络提取了它的两个特征:784维的Intensity特征和4 096维的Edge特征。
3.2 实现细节
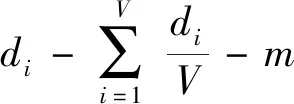
由于3Sources数据库本身是缺失的数据库,BBC、Reuters和Guardian新闻源的缺失率分别为15.38%、29.33%、 27.40%,直接使用该数据库。而数据库COIL20和UCI Digit为完整数据库,所以在每个缺失率下随机挑选数据形成缺失的多视图数据。缺失率(PER)设置为0.1、0.3、0.5、0.7和0.9。缺失率为0.1表示每个视图的完整度为90%。
3.3 实验结果
使用聚类精确度(ACC)和归一化互信息(NMI)这两个指标来对聚类结果进行评价。为了保证结果的稳定性和准确性,SSPMVC和其他4个比较的算法都进行10次试验,取10次的平均值作为最终结果,结果见表2、表3、表4和表5,黑体表示最佳结果。从表2-5可以看出:

表2 3Sources上的聚类结果

表3 COIL20(Intensity-LBP)上的聚类结果
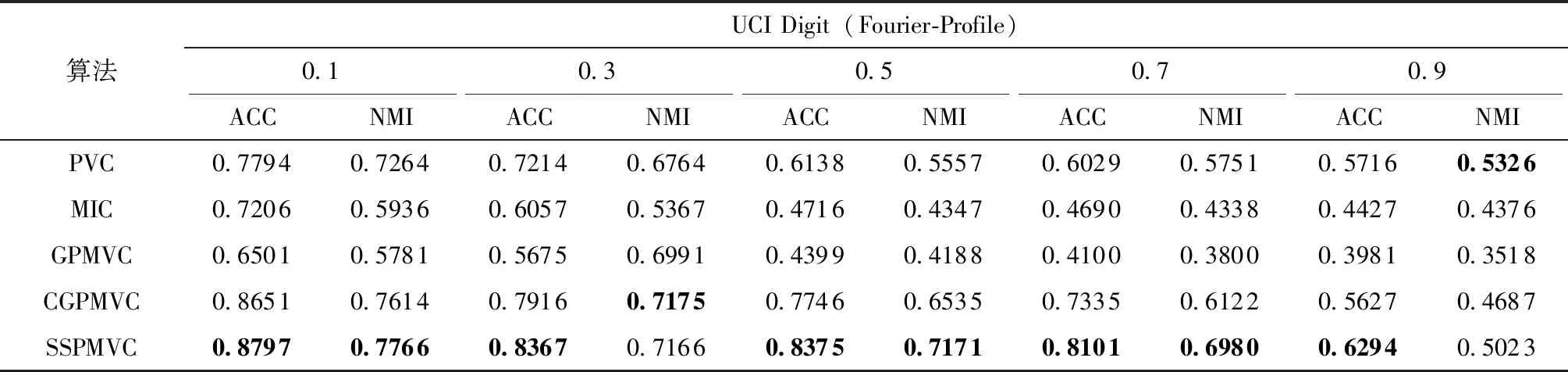
表4 UCI Digit(Fourier-Profile)上的聚类结果
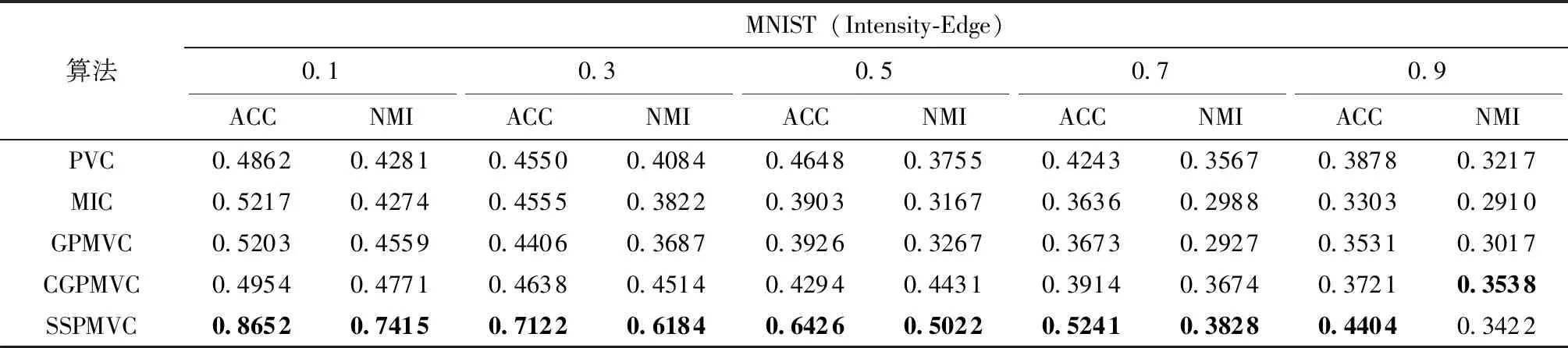
表5 MNIST(Intensity-Edge)上的聚类结果
(1)与已有的4个算法相比,除了COIL20数据集和MNIST数据集上缺失率0.9的NMI,以及UCI Digit数据集上缺失率0.3、0.9的NMI外,SSPMVC在4个数据库上的ACC和NMI都是最高的。与传统多视图聚类方法PVC、MIC和GPMVC相比,对于3Sources数据库,SSPMVC在ACC和NMI指标上分别相对获得超过至少28%和18%以上的聚类质量;对于COIL20数据库中的多视图Intensity-LBP,SSPMVC在ACC指标上相对获得超过至少8%以上的聚类质量,在NMI指标上,除缺失率为0.9的情况,可以相对获得超过至少3%以上的聚类质量;对于UCI Digit数据库中的多视图Fourier-Profile,SSPMVC在ACC指标上可以相对获得超过至少10%以上的聚类质量,在NMI指标上,
除缺失率为0.9的情况,可以相对获得超过至少6%以上的聚类质量;对于MNIST数据库中的多视图Intensity-Edge,SSPMVC在ACC指标上可以相对获得超过至少13%以上的聚类质量,在NMI指标上,可以相对获得超过至少6%以上的聚类质量。与基于神经网络的多视图聚类方法CGPMVC相比,对于3Sources数据库,SSPMVC在ACC和NMI指标上分别相对获得超过至少86%和76%以上的聚类质量,对于COIL20数据库中的多视图Intensity-LBP,SSPMVC在ACC指标上可以相对获得超过至少4%以上的聚类质量,在NMI指标上基本可以相对获得超过至少1%以上的聚类质量;对于UCI Digit数据库中的多视图Fourier-Profile,SSPMVC在ACC指标上可以相对获得超过至少1%以上的聚类质量,在NMI指标上,除缺失率为0.3的情况,基本可以相对获得超过至少1%以上的聚类质量;对于MNIST数据库中的多视图Intensity-Edge,SSPMVC在ACC指标上可以相对获得超过至少18%以上的聚类质量,在NMI指标上,除缺失率为0.9的情况,可以相对获得超过至少4%以上的聚类质量。
(2)图4的两幅图分别展示了5个算法在UCIDigit和COIL20数据集不同缺失率的聚类精确度。从图4可以看出,由于缺失数据会降低多视图聚类方法的性能,所以随着缺失率越来越大,所有方法的聚类性能基本都会下降,但是文中的方法SSPMVC相对而言下降较小,说明SSPMVC是比较鲁棒的。当缺失率由0.9减小到0.7或由0.7减小到0.5时,SSPMVC的聚类性能迅速上升,这说明在缺失率为0.7或者0.5时,生成模型已经能够较好的生成缺失的数据,使得聚类模型能够获得较好的聚类结果。
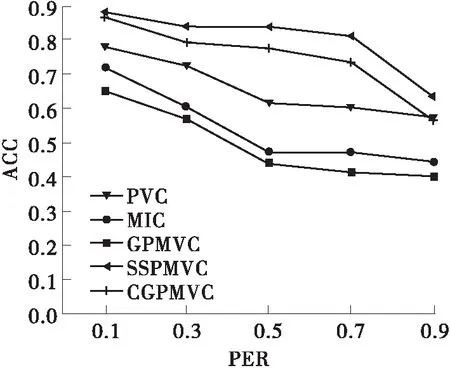
(a)UCI Digit

(b) COIL20
(3)SSPMVC之所以能获得好的性能是因为它不仅生成了各视图缺失的数据,保证了各视图的完整性和一致性,同时还学习了各个视图的潜在子空间表示,揭示了嵌入在原始数据中的潜在子空间结构。
3.4 收敛性分析
本节中给出SSMPVC算法的收敛性分析。其中,图5分别展示了SSMPVC算法在3Sources数据库中BBC-Guardian和两对多视图以及数据库COIL20和UCI Digit在缺失率为0.5时在SSMPVC算法上ACC和NMI上的收敛性情况。图6展示了生成器和鉴别器的目标函数在缺失率为0.1的MNIST数据库的收敛情况,其中g_loss为生成器损失,d_loss为鉴别损失,real_loss为鉴别器对真实图像的预测值,fake_loss为鉴别器对生成图像的预测值。从图中可以看出,最终生成器判别器的损失函数趋于平稳,real_loss和fake_loss在一条水平线上波动,即判别器最终对于真假图像已经没有判别能力,而是进行随机判断。可以看出,本文中的算法SSMPVC在这4个数据库上都具有不错的稳定性。

(a)3Sources(BBC-Guardian)

(b)UCI Digit(PER=0.5)

(c) COIL20(PER=0.5)

(a)生成器损失

(b)鉴别器损失
4 结论
提出了一种适用于缺失多视图聚类任务的算法SSPMVC。SSPMVC利用生成对抗网络生成视图缺失的数据,将补全的多视图在子空间进行聚类,将生成网络和聚类模型联合训练。SSPMVC学习了良好的聚类结构,并对不完全视图的缺失数据进行了推断。实验结果表明,论文中提出的算法优于与之比较的经典的多视图聚类方法。接下来的研究方向是如何将生成模型和聚类模型更好的结合起来,以取得更好的效果。
