基于三线互连应用交换系统的设计与实现
2020-12-28邹昀辛王晓光谢红亮
邹昀辛,王晓光,杨 帆,谢红亮
(中国航天科工集团第二研究院 七〇六所,北京 100854)
0 引 言
随着集群和云计算等互联网技术的蓬勃发展,应用交换产品已成为数据中心应用中的一种常见的网络交换设备[1,2]。这种设备需要实现2-7层数据交换的功能,有两种常见的实现方式:
第一种是在计算主板上集成专用网卡或高速以太网卡,通过软件方式完成2-7层的数据交换[3,4],底层内核与操作系统上层应用软件共同处理网络交换请求,网络数据需要在空间栈中被频繁拷贝与调用。该方案的缺陷是:缺少交换芯片,数据处理完全依赖于软件实现,性能受限于计算CPU的性能,满足不了高吞吐量网络的负载需求。
第二种是将计算主板和交换主板通过网络相连,计算主板实现4-7层数据交换,交换主板实现2-3层的数据交换,从而增加网络数据的处理能力[5]。但这种方案也存在一定的缺陷:需要由两个电路主板来实现2-7层的数据交换,增加了功耗和成本;两主板间的数据通信经过多次信号转换,增加了延迟;多电路板的实现方式降低了设备的可靠性。
此外还有基于弹性扩展的云交换架构、基于分布式的交换卸载架构,都是通过软件技术实现的2-7层数据交换,由于是基于集群方式实现,并非单一设备实现方案,所以不在本文的讨论范围内。
本文研究一种计算芯片和交换芯片三线互连的主板设计方案,通过一个电路主板实现2-7层的网络交换,降低了网络部署成本和复杂度,降低了网络延迟,增加了网络带宽,提升了网络处理性能。
1 应用交换技术介绍
根据OSI七层网络标准,传统的网络交换设备通常只工作在二三层,对网络中的MAC数据包和IP数据包进行转发或广播,应用交换设备除了处理二三层的网络数据包外,还能对数据包中四七层数据进行识别和转发,从而提升整个应用系统的并发能力,也称应用交付网关。由于四七层的网络数据应用场景多,硬件解析难度大,所以一般是通过CPU来辅助进行数据处理,常见的应用交换架构有两种:
计算板独立实现的应用交换架构如图1所示,其中NIC指的是网卡,如1G/10G等以太网卡,Intel PCH桥片上集成多个以太网卡,CPU与Intel PCH桥片通过高速PCIe信号相连[6]。在这种架构中,缺少交换芯片,二至七层的网络数据都得通过CPU来进行计算处理,性能受限,满足不了高吞吐量网络的负载需求。
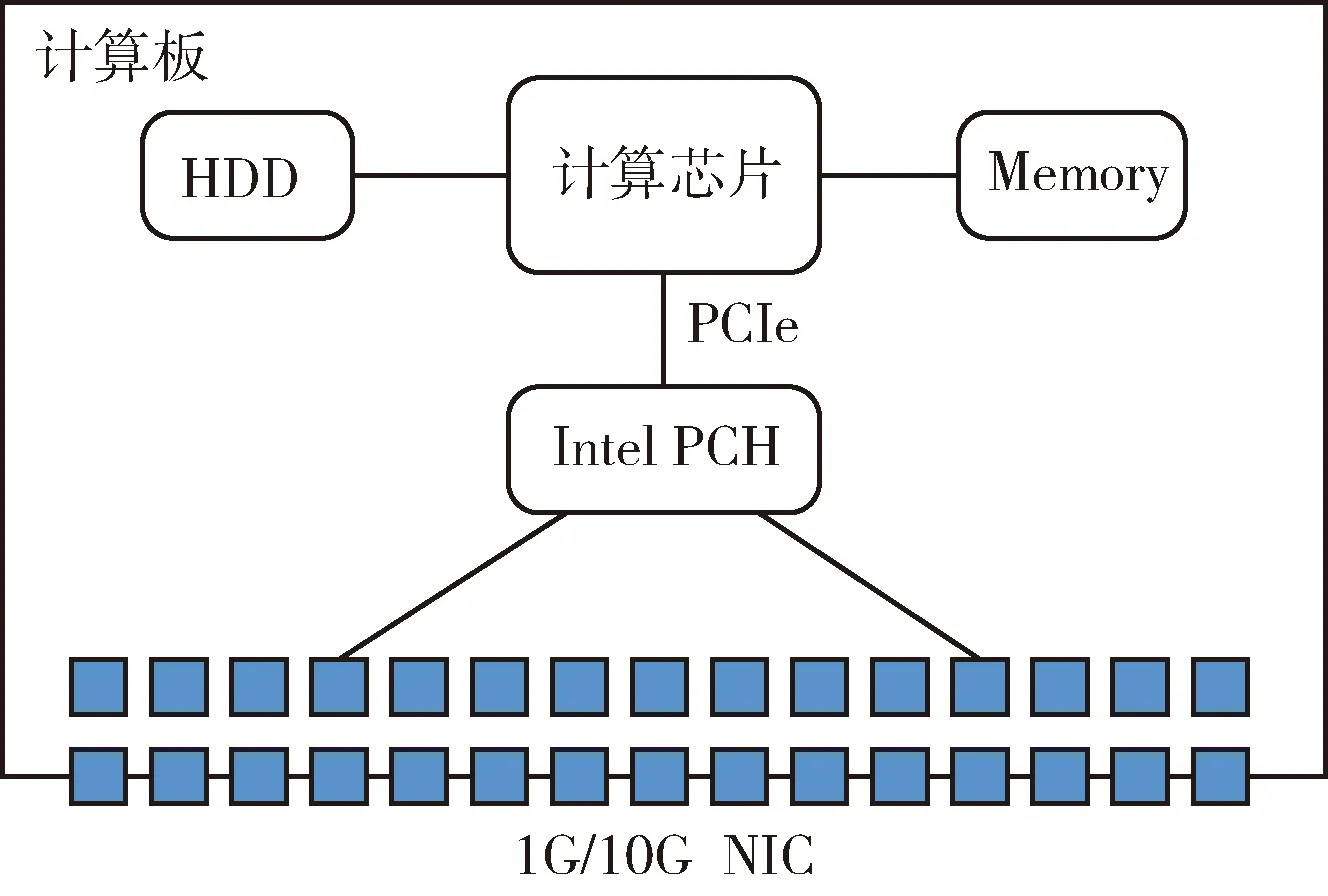
图1 计算板实现的应用交换架构
计算板与交换板组合实现的应用交换架构如图2所示,计算板上CPU通过高速PCIe信号直连两个网络芯片,交换板通过交换芯片引出多个网络接口,两板卡之间通过网络信号互连[7]。在这种架构中,交换板处理二三层网络数据,计算板处理四七层网络数据,从而实现高吞吐量网络的负载需求。

图2 计算板与交换板组合实现的应用交换架构
2 计算与交换芯片三线互连的应用交换技术
2.1 芯片三线互连架构
计算与交换芯片三线互连的架构如图3所示,计算芯片通过直连的PCIe信号控制交换芯片的启动,并通过两网络芯片与交换芯片互连。相比于传统的互连方式,该架构将交换芯片模块移至计算板内部,而计算芯片从交换芯片直取网络数据的方式,不存在额外的转换延迟,提高了网络处理效率。

图3 计算与交换芯片三线互连架构
二三层的网络数据完全由交换芯片来进行处理,不占用计算芯片的处理资源。四七层网络数据通过板级PCIe信号直接传输给计算芯片,具有更高的稳定性和传输速率,同时采用两PCIe通道传输数据的方式,是综合考虑了四七层应用数据内外转发的特点,实现了两个网络隔离子域,从而满足更多应用交换场景的需求。
图4是该技术方案的系统硬件结构,主板上主要包括计算电路和交换电路两部分。
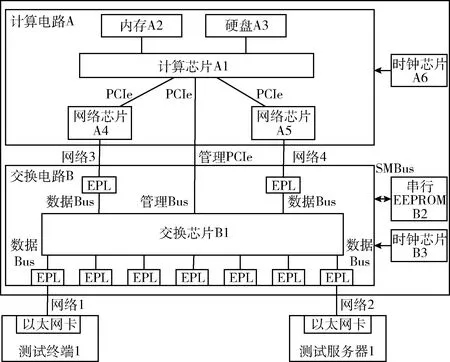
图4 系统硬件结构
在计算电路A中,内存A2与计算芯片A1直连,硬盘A3与计算芯片A1直连,网络芯片A4与计算芯片A1连接,网络芯片A5与计算芯片A1连接,时钟芯片A6的输出端与计算芯片A1的输入端连接;在交换电路B中,串行EEPROM B2通过SMBus与交换芯片B1双向连接,时钟芯片B3的输出端与交换芯片B1的输入端连接;计算芯片A1与交换芯片B1通过管理PCIe总线双向连接,网络芯片A3连接交换芯片的一个EPL,网络芯片A4连接交换芯片的一个EPL。
主板电路主要包括计算电路A和交换电路B两部分,计算电路A主要由计算芯片、内存、硬盘、网络芯片和时钟芯片组成,交换电路B主要由交换芯片、串行EEPROM、时钟芯片和若干EPL组成。各部件的功能如下:计算芯片A1实现4-7层的网络数据转发,并对交换芯片B1进行初始化、配置、监控和管理;内存和硬盘辅助实现计算芯片A1上操作系统的运行;网络芯片A4和A5用于与交换芯片B1间的以太网络通信;时钟芯片A6和B3分别用于计算芯片A1和交换芯片B1的时钟频率初始化;交换芯片B1是核心的网络处理模块,实现2-3层的网络数据的转发和处理;EPL即Ethernet Port Logic,用于与外部以太网连接,完成以太网与交换芯片间的数据转发;控制板用于对交换芯片进行初始化、配置、监控和管理;串行EEPROM用于保存交换芯片的配置信息。系统初始化过程如下:① 计算芯片A1启动,时钟芯片A6复位,读取硬盘A3信息,初始化内存A2和网络芯片A4,并扫描各PCIe总线上的设备;② 交换芯片B1复位,其中包括:时钟芯片B3复位、以太网端口EPL复位、读取串行EEPROM B2的配置信息;③ 计算芯片A1进入操作系统,并驱动管理PCIe控制交换芯片B1,完成交换芯片B1的配置文件导入和端口的初始化;④ 网络芯片A4和A5分别与交换芯片B1进行速率协商,完成握手,开始网络通信。
计算芯片一般具有丰富的PCIe接口,可以通过扩展多个网口的形式增加计算芯片的处理带宽,所以在计算电路设计时,网络芯片的理论吞吐量应与计算芯片的吞吐性能相一致,才能最大限度地提高整体的四七层处理性能。以上的电路设计是两类传统应用交换技术的综合,兼具高性能、高吞吐、低功耗、低成本的特点。
2.2 交换数据分离设计
为了增加四七层网络数据的处理能力,将二三层网络数据的处理进行卸载,网络数据的流入流出分两种情况进行处理,过程步骤详见图5(硬件结构名请参考图4)。
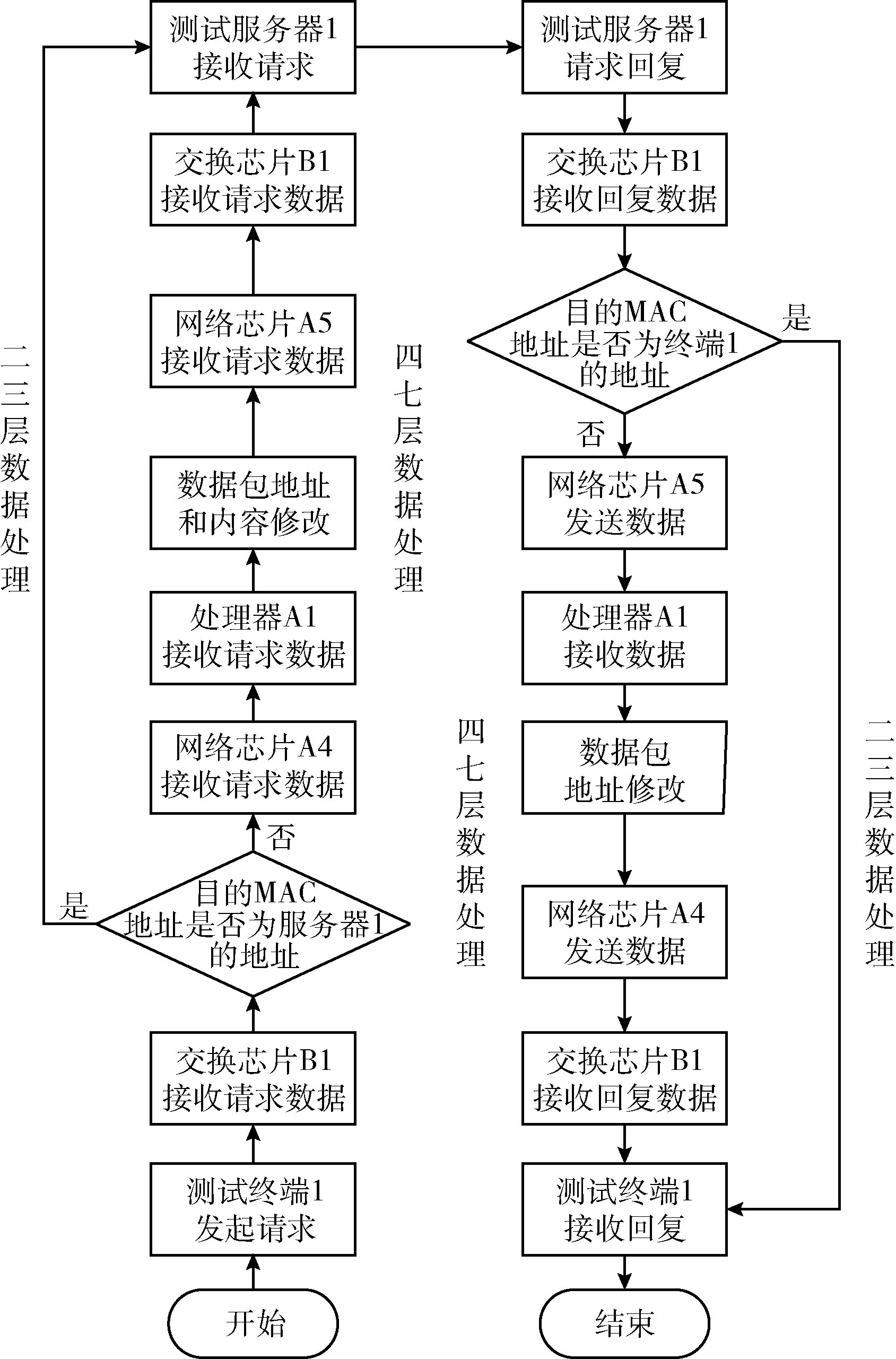
图5 系统七层数据交换流程
(1)交换芯片处理二三层交换数据
①测试终端1通过网络1发起一个请求数据包;②交换芯片B1检测到从网络1接收的一个数据包,交换芯片B1对数据包进行校验,其中包括IPV4头部、TCP/UDP头部和VLAN头部等,如果数据校验错误则将被丢弃,否则进行下一步;③交换芯片B1对数据包进行2-3层头部解析,获取目的MAC和目的IP地址等信息;④交换芯片B1对数据包目的MAC和IP地址的解析结果,与测试服务器1的MAC或IP对应,则将数据通过网络2转发给测试服务器1;⑤测试服务器对请求的数据响应,并将回复的数据包经过交换芯片发送给测试客户端1,完成2-3层的数据响应。
(2)计算芯片处理四七层交换数据
①测试终端1通过网络1发起一个请求数据包;②交换芯片B1检测到从网络1接收的一个数据包。交换芯片B1对数据包进行校验,其中包括IPV4头部、TCP/UDP头部和VLAN头部等,如果数据校验错误则将被丢弃,否则进行下一步;③交换芯片B1对数据包进行2-3层头部解析,获取目的MAC和目的IP地址等信息;④交换芯片B1对数据包目的MAC和IP地址的解析结果,如果与网络芯片A4的MAC或IP对应,则将数据通过网络3转发给网络芯片A4;⑤计算芯片A1接收到网络芯片A4的数据,进行四七层的网络报文解析,修改地址、端口或内容字段等信息后,将处理后的数据通过网络芯片A5转发到网络4;⑥交换芯片B1接收网络4的数据,并对数据包进行校验,其中包括IPV4头部、TCP/UDP头部和VLAN头部等;⑦交换芯片B1对数据包进行二三层头部解析,获取目的MAC和目的IP地址等信息;⑧交换芯片B1对数据包目的MAC和IP地址的解析结果,与网络芯片A4的MAC或IP对应,则将数据通过网络2转发给测试服务器1;⑨测试服务器对请求的数据响应,并将回复的数据包依次经过交换芯片B1、网络芯片A5、计算芯片A1、网络芯片A4、交换芯片B1,最后发送回测试客户端1,完成4-7层的数据响应。
2.3 跨内核网络直取技术
主机间的数据通信通常会涉及网卡、驱动、协议栈的处理,其处理动作会包括:网卡设备接收网络数据、网卡触发中断唤醒计算芯片、驱动程序填充内核空间读写缓冲区、数据报文经过内核协议栈解包、数据从内核空间复制到用户空间、应用程序调用Socket库获取并处理数据,该过程涉及到数据在内核空间和用户空间的两次拷贝[8]。随着硬件带宽的不断扩容,作为一个部署在数据中心的应用交换系统,其四七层的网络吞吐带宽也通常在万兆以上,如果采用传统的计算芯片中断和内核协议栈的复制来处理数据,当吞吐量较大时,计算芯片中断和网络转发延迟将越发明显[9]。故此,本文基于DPDK库实现了一种跨内核的网络数据直取技术,将网卡队列数据直接映射到用户空间,实现数据包零拷贝的收发处理,实现数据高速交换。
如图6所示,左侧是基于内核协议栈的网络数据包收发流程,右侧是本文基于跨内核数据直取技术实现的网络数据包收发流程,底层网卡采用的是一种加速网卡,该网卡可以实现与计算芯片间的多核多队列绑定。UIO即Userspace I/O,是基于DPDK实现的通用网卡驱动[10,11],它辅助用户程序直接访问硬件IO的数据。MMAP即内存共享映射,将内核空间映射到用户空间,避免内核空间与用户空间频繁拷贝带来的计算芯片开销。PMD即Poll Mode Driver轮询驱动,通过轮询和中断服务历程的方式实现,避免了频繁的中断上下文切换所带来计算芯片资源消耗,适用于高吞吐量的网络场景,兼具高性能、低能耗的特点。Fast TCP是运行于用户空间的四层网络数据包协议,适用于FTP、EMAIL等网络服务的数据转发。Fast HTTP是运行于用户空间的七层网络数据包协议,适用于WEB等网络服务的数据转发。Fast TCP和Fast HTTP是自主研发的高速数据接口协议,是专用的虚拟服务进行转发的接口,与通用的基于内核转发的数据协议不同,该协议在DPDK模块的协助下,能快速直取网卡缓冲区队列的数据,在一定程度上加快了数据的收发速度,降低了数据包延迟,提高了系统性能。
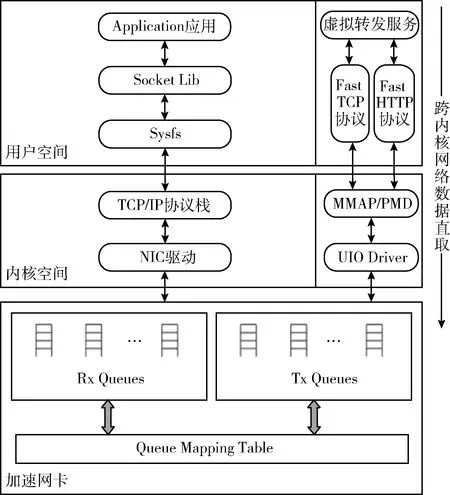
图6 跨内核网络数据直取机制
3 性能测试与分析
采用LoadRunner压力测试机和国产化应用系统搭建性能测试环境,从四层和七层交换性能两个方面对文中涉及到的3种应用交换系统(见前文第1节和第2节)进行比较。LoadRunner是最为常用的应用系统测试软件,可以对系统的吞吐量、TPS(transactions per second)、CPS(connections per second)和RPS(responses per second)等指标进行专业的评估[12,13],其结果具有较强的参考性。
3.1 测试环境
测试时主要采用国产化的WEB应用环境,原因如下:应用交换系统主要采用的是国产化的软硬件架构,适用于国产化应用系统环境;测试主要针对四七层的应用交换能力测试,需要搭建四七层的应用环境,所以采用最为常见的WEB应用系统。主要测试环境拓扑如图7所示,主要分压力机、应用交换、WEB应用3部分,其中,环境配置参数见表1。
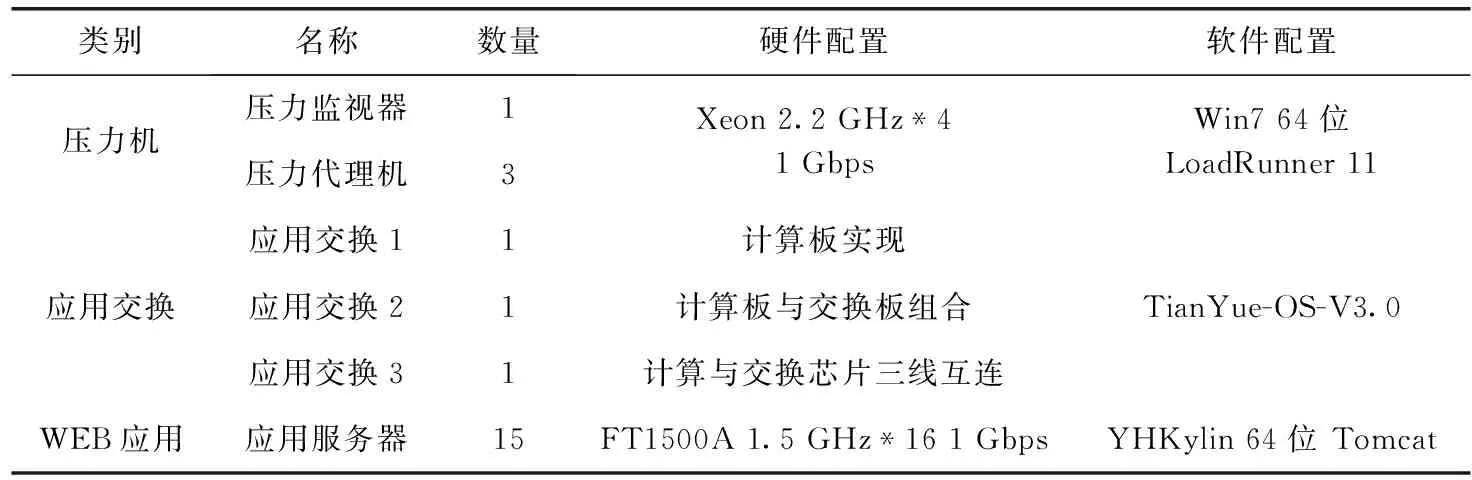
表1 测试环境配置
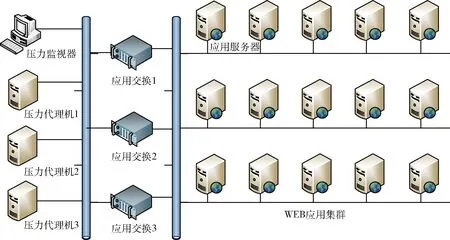
图7 测试环境拓扑
应用交换1代表以计算板独立实现的应用交换设备,应用交换2代表将计算板与交换板组合实现的应用交换设备,应用交换3代表基于计算芯片与交换芯片三线互连技术实现的应用交换设备。3种应用交换设备上都部署了同一个负载均衡软件TianYue-LB-3.0,该软件能提供二三层的网络端口管理、四层TCP协议数据转发、七层HTTP协议数据转发,并且支持普通轮询、加权轮询、源地址绑定和最少连接等多种负载均衡策略,为国产自主研发软件。3种应用交换设备单独分开测试,客户端或压力机通过识别应用交换设备的IP来区分不同的设备。当客户端或压力机向应用交换设备的一侧端口发送http请求时,应用交换设备将该请求通过另一侧端口分发到相应的Web应用服务器上,经过Web应用服务器处理后的响应数据包再返回给应用交换设备,最后达到客户端。该过程有点类似于代理服务器的NAT功能。压力测试过程中,为了避免端口的网络带宽瓶颈,通常也会将多个网卡绑定起来,从而增加带宽。
WEB应用集群提供应用服务。本文作者在上面部署了一个性能较优的国产中间件“东方通”和一个运行较为稳定的邮件应用服务。15台应用服务器具有相同的Web处理能力,能提供邮件系统的用户登陆、邮件查询、邮件发送和用户登出等功能。为了避免数据库和磁盘阵列对集群性能的影响,应用服务器采用访问本地数据库和磁盘的方式。从理论上讲,15台应用服务同时运行时,其吞吐量应该是单台应用服务的15倍,但是通常会受到分发策略、网络吞吐能力的限制,实验结果验证了该结论,请看结果分析。
3.2 测试方法
仿真测试采用一个专业的测试工具Loadrunner。该软件可以模拟几千个用户进行自动负载测试和实时性能监测。该软件具有用户脚本、场景模拟和结果分析3大功能模块。
首先,监控机上创建Web测试脚本,该脚本具有用户登陆、邮件查询、邮件发送和用户登出的4个功能,基本满足模拟环境的测试要求。其次,应用交换和WEB应用共同构成一个应用集群系统,当压力场景运行时,监控机将该脚本发送到压力代理机上执行,并通过调整模拟用户的数目来增减并发量和吞吐量,从而测试该应用集群系统的性能上限。场景运行时,监控机实时监控整个系统的吞吐量和TPS,并在运行结束后收集数据并进行分析,生成统计分析结果。
测试主要从吞吐量、TPS、CPS和RPS这4种数据来对比分析交换设备的性能:
吞吐量是测量网络性能的一个重要指标,它可以测出应用系统的总带宽。与网络带宽不同,它不仅与链路传输速度有关,还受到网卡收发速度、cpu处理能力、交换机和应用程序性能等多种因素的影响。实验中的所有服务器的网卡性能都接近于1000 M,而实测中的总吞吐量在500 M左右,所以基本上可以排除网卡对集群吞吐量的影响。
TPS(transactions per second),也就是事务响应数,它可以测出应用系统的每秒能处理的事务数。不同的事务(如登录、查询等)会消耗不同的系统资源,就会有不同的响应时间。压力测试时,采用的是混合场景,通过TPS指标,我们可以清楚地了解集群系统的服务能力。
CPS(connections per second),指四层每秒新建TCP连接数;RPS(responses per second),指服务端每秒回复的http请求的数目。通过这两个指标,可以窥探出该应用系统的并发用户数(也就是允许多少个用户同时在线)。
3.3 结果分析
四七层的网络交换能力,分别是指TCP和HTTP数据包的转发能力。如果数据转发的能力强,网络中的请求和响应的速度就快,应用系统在单位时间内的数据处理能力就强。所以,可以从整个应用集群系统的吞吐量、TPS、CPS和RPS数据来比较3种应用交换系统性能。
(1)四层交换性能
四层交换能力,主要指根据网络数据报文的IP或端口进行改写并转发的能力。由图8的结果分析可知,3种应用交换下,应用系统的最大吞吐量分别为:30 MBps,62 Mbps,71 Mbps。最大TPS分别为:49 tps,71 tps,83 tps。最大CPS分别为:26 cps,36 cps,43 cps。最大RPS分别为:1721 rps,2510 rps,2987 rps。随着并发数的增加,应用交换3(计算与交换芯片三线互连架构)的吞吐量、TPS、CPS和RPS的性能均有显著提高。当并发数达到最大80时,应用交换3相比其它两种应用交换架构可提升12%以上吞吐量。可见,应用交换3(即基于计算芯片与交换芯片三线互连技术实现的应用交换)适用于高带宽高并发的应用集群领域。
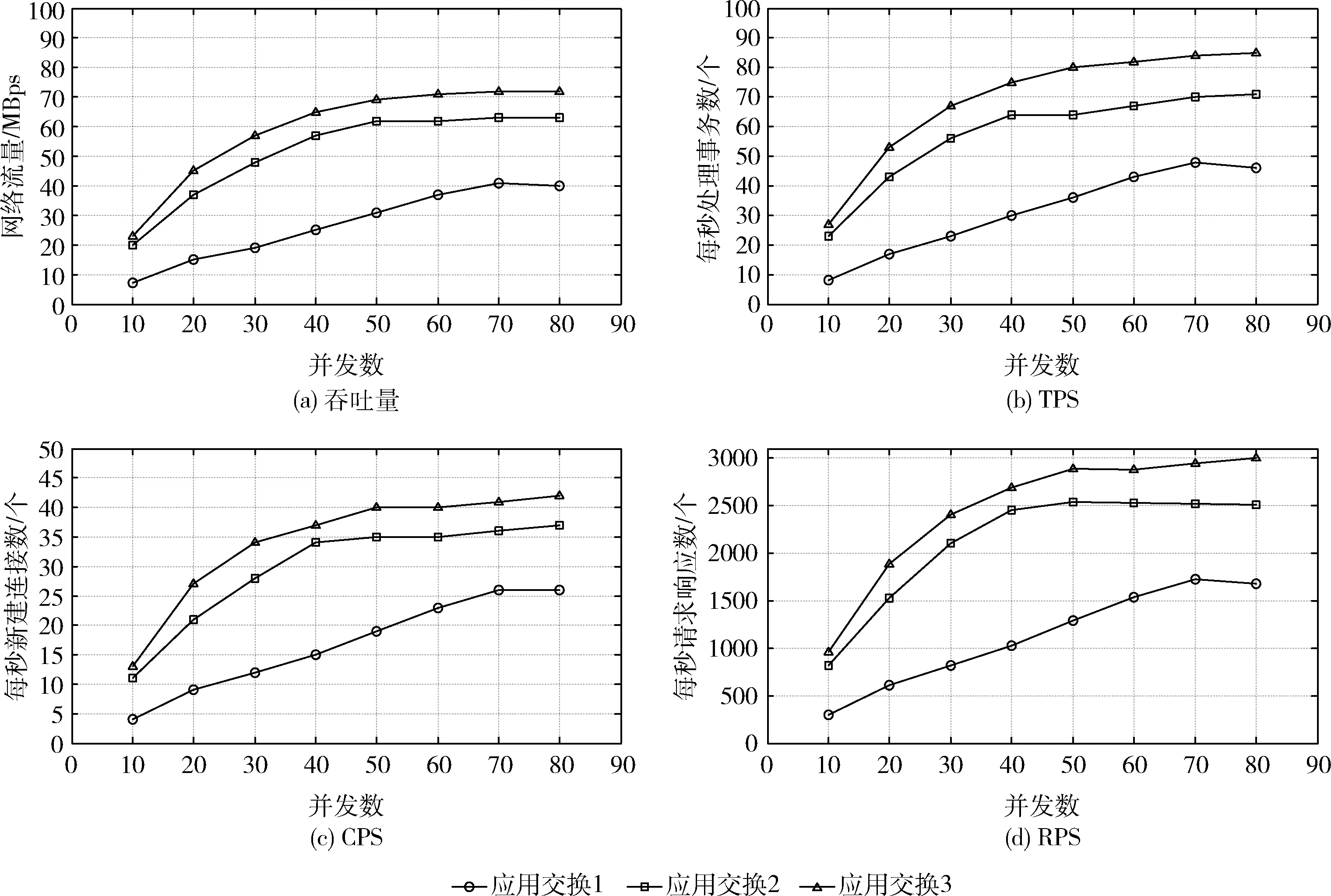
图8 四层交换性能测试
(2)七层交换性能
七层交换能力,主要指根据网络数据报文的HTTP头或Session进行改写并转发的能力。由图9的结果分析可知,3种应用交换下,应用系统的最大吞吐量分别为:30 MBps,52 Mbps,61 Mbps。最大TPS分别为:40 tps,60 tps,71 tps。最大CPS分别为:17 cps,26 cps,38 cps。最大RPS分别为:1427 rps,2211 rps,2547 rps。随着并发数的增加,应用交换3(计算与交换芯片三线互连架构)的吞吐量、TPS、CPS和RPS的性能均有显著提高。当并发数达到最大80时,应用交换3相比其它两种应用交换架构可提升15%以上吞吐量。可见,应用交换3(即基于计算芯片与交换芯片三线互连技术实现的应用交换)系统适用于高带宽高并发的应用集群领域。
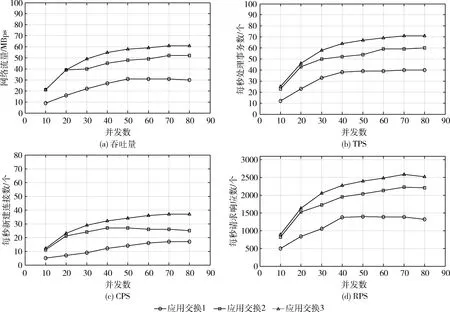
图9 七层交换性能测试
此外,从理论上分析,相比于四层交换处理,七层交换处理的解析层次更深入,对数据转发的要求更高,对应用系统的资源消耗更多,其性能普遍比四层交换性能弱。由实验结果看,对于同一种应用交换系统,当吞吐量增大时,四层和七层的数据转发的性能差距会变大,当并发数达到最大80时,四层转发的性能会比七层数据转发的性能高10%-20%,符合理论预期值。
4 结束语
针对应用交换系统对吞吐量和转发处理能力的要求,本文在传统应用交换技术架构的基础上,提出了一个芯片三线互连的交换体系架构,从测试结果可以看出,该系统能充分利用四七层的网络带宽,对应用集群系统在网络吞吐能力和事务处理能力等性能的提升尤为突出,相比传统的两种应用交换技术架构,四层交换性能可提升约12%以上,七层交换性能可提升约15%以上,适用于高带宽高并发的应用集群领域。
