基于YOLOv3的教室人数检测
2020-12-24陈涛谢宁宁张曦张玉婵史新增李攀
陈涛 谢宁宁 张曦 张玉婵 史新增 李攀

摘 要:为了提高教室人数检测精度识别出教室的正确状态,克服学生上课姿态,座位远近、面部遮挡、尺度较小等因素而造成传统人脸检测技术识别精度较低,无法满足实际需求的问题。实验采用了如今热门的实时目标检测算法——YOLOv3(YOU ONLY LOOK ONCE v3),并根据教室这一特定场景采集大量图像信息样本,对其进行标注制成训练集。通过多次训练并不断调整参数,得出最佳的教室人数检测模型.实验结果表明,在1000张测试集图片样本中能得到90%以上的准确率,可以识别出教室人数并准确判断出教室状态,验证了基于YOLOv3的教室人数检测方法的有效性。
关键词:人数统计;目标检测;YOLO;图像识别
中图分类号:TP18 文献标志码:A 文章编号:2095-2945(2020)27-0030-04
Abstract: In order to improve the detection accuracy of the number of students in the classroom and recognize the correct state of the classroom, overcome the problems of students' classroom postures, seat distances, face occlusions, small scales and other factors which easily result in the low-accuracy recognition of traditional face detection technology, thereby can not meet the actual needs. In the experiment, we used the popular real-time target detection algorithm - YOLOv3 (YOU ONLY LOOK ONCE v3). A large number of image information samples are collected according to the specific scene of the classroom and labeled to make a training set. By training many times and adjusting the parameters continuously, we got the best number detection model of classroom. The experimental results show that the accuracy rate of more than 90% can be obtained in 1000 test set picture samples, and the number of students in the classroom can be identified and the state of classroom can be accurately determined, which verifies the effectiveness of the number detection method based on YOLOv3.
Keywords: number of students; target detection; YOLO; image recognition
引言
目前CNN(Convolutional Neural Networks)已经广泛应用于机器学习、语音识别、图像识别等多个领域[1-3]。以CNN为基础的目标检测算法、人群计数算法的发展也趋于稳定,在大部分场景中已有实际运用[4-5]。在课余时间,在校大学生往往有上自习的需求,而图书馆和自习室存在无座、拥挤等问题,因此教学楼中空闲的教室就为想上自习的学生提供了一个不错的选择。根据实际体验,因教室的课程安排或临时课程安排等诸多因素,同学将会花费大量时间寻找一个没有安排课程的教室。此外,找到的空闲教室中也存在不久就会上课的问题,存在频繁更换教室的问题。因此以神经网络为基础,通过识别教室人数判断教室状态并匹配课程表过滤有课教室,为同学推荐人数最少、可自习时间最长的教室具有重要意义,可极大的为在校生的学习生活提供便捷。
在传统的人群计数方法中常用的有基于检测的方法和基于回归的方法。基于检测的方法通常会利用SVM和随机森林等传统机器学习方法训练一个分类器[6],利用人体的整体或部分结构,如头部、肩膀等提取HOG(Histograms of Oriented Gradients)、边缘等特征来检测并统计人数[7]。但该方法并不适用于人群遮挡的场景,针对不同尺度大小目标的检测效果并不理想。基于回归的方法,其思想是学习一种特征到人群数量的映射,通常是学习一个回归模型来估计人群的数量。
相较于传统机器学习的方法,深度学习在计算机视觉的识别、检测方面取得了很大的进步,识别精度有了很大的提高[9]。无论是使用目標检测的方法还是基于回归的方法在CNN上都能得到优于传统机器学习方法的结果,随着深度学习的不断发展,在目标检测等多领域体现出明显优势已经逐渐开始取代传统的机器学习方法。
针对高密度人群场景,Zhang等人在2016年提出了MCNN(Multi-column Convolutional Neural Network)[8]利用卷积神经网络提取密度图,通过回归密度图的方式估计人群密度,该算法在SHT A得到了110.2的MAE和173.2的MSE[9]。而对于低密度人群、人群无遮挡的场景,采用目标检测的方法进行人群计数其准确度明显优于采用密度图回归的方法。
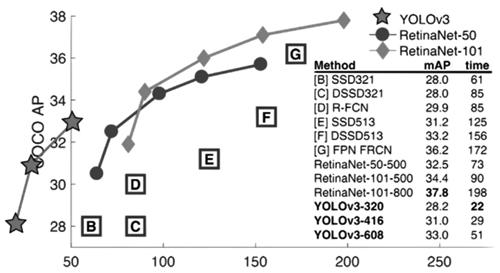
因此根据教室这一特定场景具有人群低密度、遮挡少等特点采用目标检测的方法进行人数统计。YOLO(You Only Look Once)[9]是Joseph Redmon等人于2015年提出的目标检测算法,最初的版本最多只能检测49个目标。当前,已有YOLOv1、YOLOv2[10]和YOLOv3[11]等多个版本。在最新的版本中YOLOv3调整了网络结构,利用多尺度特征进行对象检测并且借鉴了残差网络[12]结构,形成更深的网络层次。相较于前两个版本YOLOv3可分类的目标更多、检测的目标更多、检测速度更快并且检测精度也更高[11]。在精确度相当的情况下,YOLOv3的速度是其它目标检测模型的3、4倍[11]。
本文将YOLOv3目标检测算法应用于教室人数识别中,在采集的教室监控样本中训练目标检测模型,利用训练得到的模型对测试集进行测试,具有较高的准确性。
1 YOLOv3网络结构
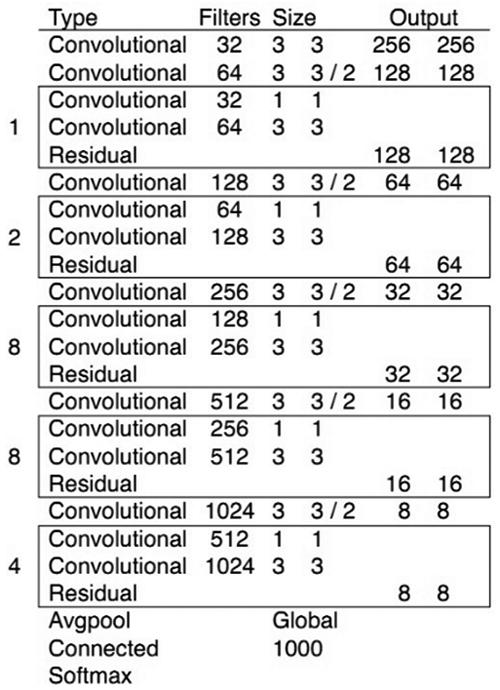
YOLOv3以darknet-53作为基础网络,整个网络使用了全卷积层,由一系列1x1、3x3的卷积层组成。并且采用了三种先验框13x13、26x26、52x52,可在特征图上进行不同尺度的检测,提高了小尺度目标检测识别的能力。图2说明了YOLOv3的网络结构[11]。
2 实验过程
2.1 数据集制作
实验数据集取自教学楼各个教室视频监控,为了提高识别系统在不同时间段针对不同人数的检测能力,因此实验数据集包含多张不同时间段、不同光照和不同人数的教室视频监控截图。在这样的数据集上进行模型训练更具有代表性,可更加准确的反映出教室的准确状态。将获取到的教室监控截图使用LabelImg进行标注,产生训练需要的xml文件,xml文件中包含目标分类名称以及目标所在位置的坐标信息。为了应对更多复杂的光线环境、进一步扩充数据集的数量,因此采用了随机参数设置的方法调整原始图像的亮度、对比度和饱和度,训练样本及标注后的训练样本如图3所示。最终得到的实验数据集包含3000张教室监控截图样本训练集,1000张测试集以及1000张验证集。各个数据集中的数据均不重复,如表1所示。
2.2 训练模型过程
本文使用的是基于Pytorch[13]深度学习框架实现的YOLOv3进行训练和测试。采用darknet53.conv.74预训练权重以及使用数据增强方法扩充后得到的3000张图像的训练集进行训练。
模型在训练过程中可分为3个步骤:
(1)根据损失函数计算预测框的误差
YOLO的损失由4部分组成:对预测的中心坐标做损失、对预测边界框的宽高做损失、对预测的类别做损失、对预测的置信度做损失。
对预测的中心坐标做损失公式为:
(1)
式中λcoord表示网格内没有目标的系数;l■■表示网格单元i的j网格是否负责obj目标;(x,y)为预测边界框的位置,(■,■)为训练数据中的实际位置。
对预测边界框的宽高做损失公式为:
(2)
式中(w,h)为预测框的尺寸,(■,■)为训练数据中的实际尺寸。
对预测类别做损失的公式为:
(3)
式中p■■(c)为预测结果为c类的概率,■■■(c)表示单元格i为c类的真实概率。
对预测的置信度做损失的公式为:
(4)
式中C是置信度得分,■是预测边界框基本事实的交叉部分。当在一个单元格中有对象时, 等于1,否则取值为0。
(2)根据误差计算卷积核中每个权重的梯度。
(3)通过基于梯度的优化算法更新权重。
在训练过程中保存模型,在训练结束后选出最优的教室人数检测模型。
3 实验结果
本次实验仅需对一类目标进行识别,故采用精确率(Precision)和召回率(Recall)作为模型的评价标准,精确率反应出在识别的测试集中,预测出的样本与实际正样本的比值;召回率反应出所有正样本比例中被正确识别为正样本的比例。
式中:tp为正样本被正确识别为正样本;fp为负样本被错误识别为正样本;fn为正样本被错误识别为负样本;n为样本总数。
网络模型完成训练后,得到最终的教室人数检测模型,将教室监控数据帧数据输入模型中,即可完成对教室人数进行检测,测试结果如图4所示。
在训练好的模型上,使用1000张图像的测试集进行验证。基于YOLOv3的教室人数检测模型的精确率和召回率如表2所示
表2 重要指标
通过表2和图4可以看到基于YOLOv3网络训练的教室人数检测方法,其精确率和召回率都达到90%以上。对一些存在遮挡问题的目标也能进行有效识别。在实际应用中,可以准确判断教室状态,满足实验需求。
4 结束语
为了解决传统目标检测算法带来的识别精度低、鲁棒性差等问题,本文基于YOLOv3目标检测算法实现了教室人数实时检测与统计功能,结果表明基于YOLOv3的人数检测方法无论是在测试精度和还是检测统计速度上都取得了良好的效果。在1000张测试集上进行评估,达到了92%的準确率。本研究的结果意味着,使用YOLOv3进行教室人数检测切实可行,能够准确的检测出教室状态,为同学们推荐符合要求的教室。下一步,将通过优化网络结构、优化参数,进一步提高教室人数检测算法的识别速度和识别精度。
参考文献:
[1]武阳,余综.基于CNN的扩展混合端到端中文语音识别模型[J].青岛科技大学学报(自然科学版),2020,41(01):104-109+118.
[2]朱超平,杨艺.基于YOLO2和ResNet算法的监控视频中的人脸检测与识别[J].重庆理工大学学报(自然科学),2018,32(08):170-175.
[3]Engineering. Studies from Civil Aviation University of China Further Understanding of Engineering (A Light Cnn for End-to-end Car License Plates Detection and Recognition)[J]. Journal of Technology & Science,2020.
[4]Gao, J., Lin, W., Zhao, B., Wang, D., Gao, C., & Wen, J. (2019). C^3 Framework: An Open-source PyTorch Code for Crowd Counting[J]. ArXiv, abs/1907.02724.
[5]Xingjiao Wu, Baohan Xu, Yingbin Zheng, et al. Fast video crowd counting with a Temporal Aware Network[J]. arXiv,2020, 403:13-20.
[6]江中华.人群密度估计综述[J].轻工科技,2018,34(10):80-81+87.
[7]Li M, Zhang Z, Huang K, et al. Estimating the number of people in crowded scenes by mid based foreground segmentation and head-shoulder detection[C]. International Conference on Pattern Recognition. New York, NY, USA: IEEE, 2008: 1-4.
[8]Zhang Y, Zhou D, Chen S, et al. Single-Image Crowd Counting via Multi-Column Convolutional Neural Network[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2016.
[9]Redmon, J., Divvala, S.K., Girshick, R.B., & Farhadi, A. (2015). You Only Look Once: Unified, Real-Time Object Detection[J]. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 779-788.
[10]Redmon, J., & Farhadi, A.(2016). YOLO9000: Better, Faster, Stronger[J]. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 6517-6525.
[11]Redmon, J., & Farhadi, A.(2018). YOLOv3: An Incremental Improvement[J]. ArXiv, abs/1804.02767.
[12]He, K., Zhang, X., Ren, S., & Sun, J.(2016). Deep Residual Learning for Image Recognition[J]. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR),770-778.
[13]本刊訊.Facebook发布深度学习框架PyTorch 1.3[J].数据分析与知识发现,2019,3(10):65.
