基于混合分类器的AMR-WB 语音隐写分析方法*
2020-12-23吴彦鹏陈明辉曹荣鑫
吴彦鹏,陈明辉,曹荣鑫,孙 奕
(厦门市美亚柏科信息股份有限公司,福建 厦门 361008)
0 引言
信息隐藏是一种通过各种信息载体进行隐蔽通信的安全技术,常见的信息载体有图像[1]、语音[2]以及视频[3]等。近年来,随着移动网络和终端的不断发展,网络语音通信(Voice over IP,VoIP)已经广泛应用于网络电话和即时通信领域。相较于传统的隐写载体,它具备较高的隐藏容量和较强的实时性,能够轻易实现高速且实时的隐蔽通信,因此涌现了一批基于VoIP 的信息隐藏方法。
总的来说,基于VoIP 的信息隐藏可以分为两类:一类是通过修改VoIP 的网络协议来实现信息隐藏[4-5];另一类则是通过修改语音载体中的参数来达到信息嵌入的目的[6-10]。由于压缩语音本身具有一定的冗余性,对参数细微的修改并不会引起语音质量的大幅下降,因此基于载体参数的修改是比较常见的信息隐藏方法。
基于量化索引调制(Quantization Index Modulation,QIM)的方法是压缩语音编码中最常见的信息隐藏方法。通过将搜索码本划分为两个子空间,可根据不同的嵌入信息,在搜索码字时选择不同的子空间进行搜索,以达到嵌入隐秘信息的目的。例如,Xiao 等人[6]设计了一种名为互补邻居顶点(Complementary Neighbor Vertices,CNV)的算法,将码本空间分为两个部分实现了用于线性预测参数(Liner Prediction Coefficient,LPC)的信息隐藏方法。为了加强CNV-QIM 算法的安全性,Tian 等人[7]提出了一种基于随机位置选择和矩阵编码的信息隐藏方法。实验表明,该方法相较于Xiao 等人[6]的方法对隐写分析有更强的抵抗能力。Liu 等人[8]则通过引入矩阵嵌入的方法进一步提升了QIM 算法的隐蔽性和安全性。之后,Huang 等人[9]通过使用秘钥控制码本的划分,再次加强了QIM 算法的鲁棒性和安全性。
作为一种重要的语音压缩编码,自适应多速率宽带语音编码(Adaptive Multi-Rate Wideband,AMR-WB)被广泛应用于多种移动通信系统。针对AMR-WB 编码,He 等人[10]设计了一种名为直径-近邻法(Diameter-Neighbor,DN)的码本划分方法。该方法通过设定一定的规则,在不断的迭代中将多个近邻的码字合并为簇,实现了码本空间的划分。实验表明,通过对AMR-WB 中导谱频率(Immittance Spectral Frequencies,ISF)量化索引的修改,该方法相较现有方法具有更强的灵活性和明显的抗检测能力。
信息隐藏方法在提供安全通信的同时,也可能被不法分子利用,用于各种犯罪活动。因此,针对信息隐藏技术的对抗技术——隐写分析技术在近年也受到多方关注。为了检测基于QIM 的信息隐藏,Li 等人[11]基于索引序列分析提出了一种基于机器学习的隐写分析方法。通过索引分布特性(Index Distribution Characteristics,IDC)特征,该方法可以在某些情况下检测基于CNV-QIM算法的信息隐藏。Tian 等人[7]和Liu 等人[8]分别对CNV-QIM 进行修改,使基于IDC 特征的隐写分析方法难以对其进行检测。后来,Li 等人[12]又提出了一种基于码书关联网络(Quantization Codeword Correlation Network,QCCN)的检测方法。即使在隐写的过程中采用矩阵编码,该方法也能较为准确地检测出基于CNVQIM 算法的信息隐藏。但是,He 等人[10]指出,该方法在使用了DN-QIM 的AMR-WB 上表现不佳。
此外,Lin 等人[13]首次在VoIP 的隐写分析上使用循环神经网络(Recurrent Neural Network,RNN)设计了一种基于RNN 的隐写分析模型(RNN-based Steganalysis Model,RNN-SM)。该模型包含两层长短期记忆模型(Long-Short Term Memory,LSTM),通过对大量数据进行训练和迭代,可以在极短的时间内以较高的正确率检测出载密语音的存在。
由于He 等人[10]提出的DN-QIM 方法具有较强的抗检测能力,因此本文利用LSTM 进行特征提取,并使用支持向量机(Support Vector Machine,SVM)对特征进行训练,设计了一种基于混合分类器的隐写分析方法,能够在多种条件下对AMRWB 上的DN-QIM 方法进行有效检测。
1 AMR-WB 语音编码
AMR-WB 是由3GPP 制定的压缩语音标准。在2002 年,ITU 也将其选为宽带语音编码标准G.722.2[14]。AMR-WB 支持从6.6 kb/s 到23.85 kb/s的9 种速率。相较于自适应多速率窄带语音编码(Adaptive Multi-Rate Narrow Band,AMR-NB),AMR-WB 拥有更高的带宽和采样率,因此可获得更高的语音质量,能更广泛地应用于网络电话、电视会议以及无线通信系统等领域。
AMR-WB 语音使用16 kHz 的语音作为输入,以20 ms 作为帧长,在每帧内执行一次线性预测。在线性预测过程中,编码器对16 维ISF 参数进行了二级分裂矢量量化(Split-Multistage Vector Quantization,S-MSVQ),获得了7 个量化索引。
图1 展示了AMR-WB 编码器在除6.6 kb/s 速率以外的8 种速率中进行S-MSVQ 的流程。在第一级量化中,编码器将16 维输入矢量的残差矢量分裂为9 维和7 维矢量分别量化,得到了两个均为8 bit的量化索引Q11和Q12。在第二级量化中,编码器又将第一级量化后的两个残差矢量分别分裂为3 个和2 个矢量进行量化,得到了5 个量化索引Q21、Q22、Q23、Q24、Q25。表1 展示了23.85 kb/s 速率下各量化索引的大小,其中Q22和Q23均为7 bit 的量化索引。由于这两个索引在帧间和帧内的关联性均不强,因此He 等人[10]选用了这两个量化索引进行QIM 隐写。实验结果表明,Li 等人[12]提出的QCCN算法无法有效对He 等人[10]的方法进行检测。
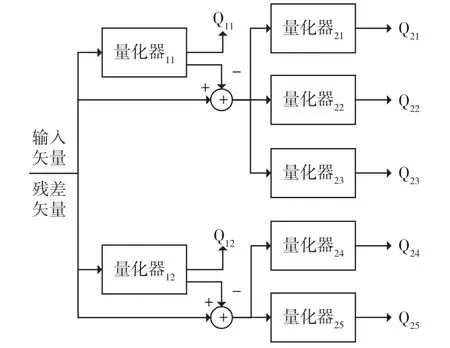
图1 S-MSVQ 原理

表1 23.85 kb/s 速率下各级矢量索引及其大小
2 隐写分析方法
通过分析语音的相关特性,本文有两类特征被选作训练特征:第一类特征为索引长时分布特征;第二类特征则是借助LSTM 模型提取的ISF 参数关联性特征。通过校准技术处理,这两类特征能够更好地表征ISF 在信息隐藏前后的变化。
2.1 基于校准技术的索引分布特征
音素是语音的最小单位。各种类型的语言在发音时,其音素通常具备一定的分布特性[11]。这样的特性导致压缩语音的相关参数在较长的一段时间内也具备类似的分布。基于这个原理,Li 等人[11]设计了一种基于码字直方分布的隐写分析特征。以Q22为例,假设在一段长度为T帧的语音中,量化索引Q22在第i帧中的索引值为Q22,i,则可计算Q22的任一索引值q在这段语音中的分布概率P22,q:
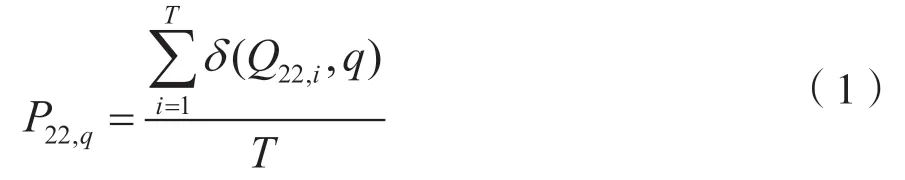
其中,δ(Q22,i,q)根据输入索引值的不同输出0或者1,即:
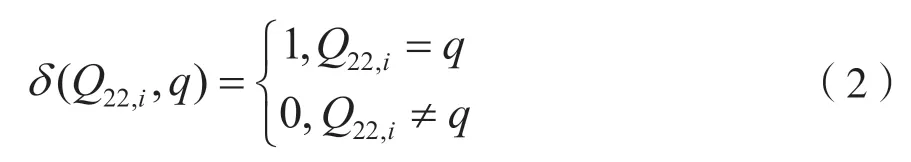
通过式(1)可得,Q22的码字直方分布特征为{P22,0,P22,1,…,P22,127}共128 维。图2 展示了量化索引Q22在大量样本统计下获得的概率分布,不难看出,信息隐藏确实改变了量化索引的统计概率分布,但差距并不明显,因此本文还引入了校准技术进一步提升该类特征的分类性能。
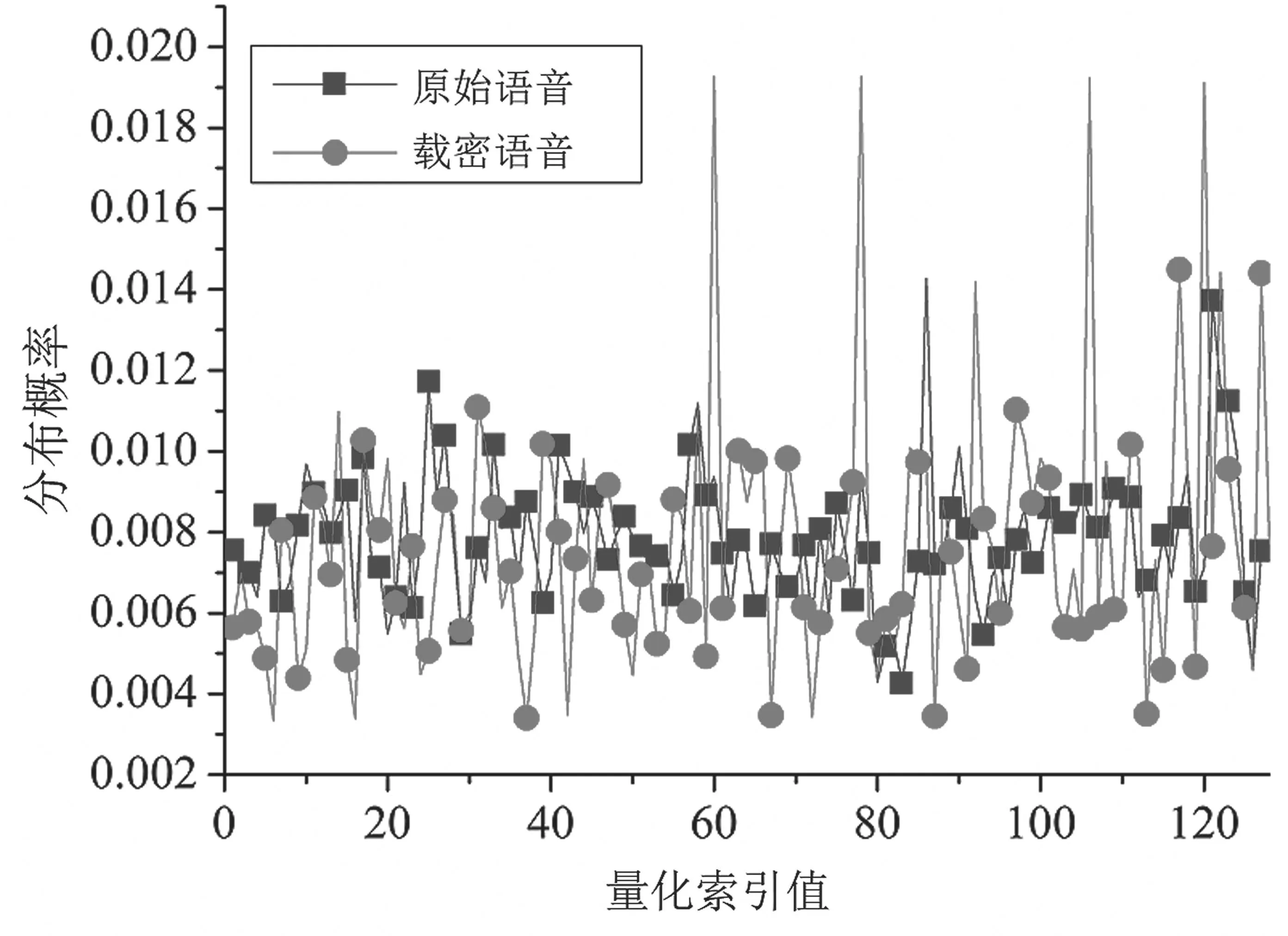
图2 Q22 的量化索引分布概率
校准技术在隐写分析中常被用于估计原始样本的特征[15]。在不同的载体和隐藏方法中,具体的使用方法也有所不同[16]。例如,本文中发现,将待检语音解压到PCM 后再次进行AMR-WB 压缩,无论是载密语音还是原始语音,其ISF 的量化索引分布均出现了一定程度上的相似性。图3 展示了原始语音和载密语音的量化索引Q22在进行重压缩后的分布概率。可以看出,可以使用重压缩后的量化索引分布概率作为校准来估计原始语音的统计分布,从而进一步提升特征的分类性能。
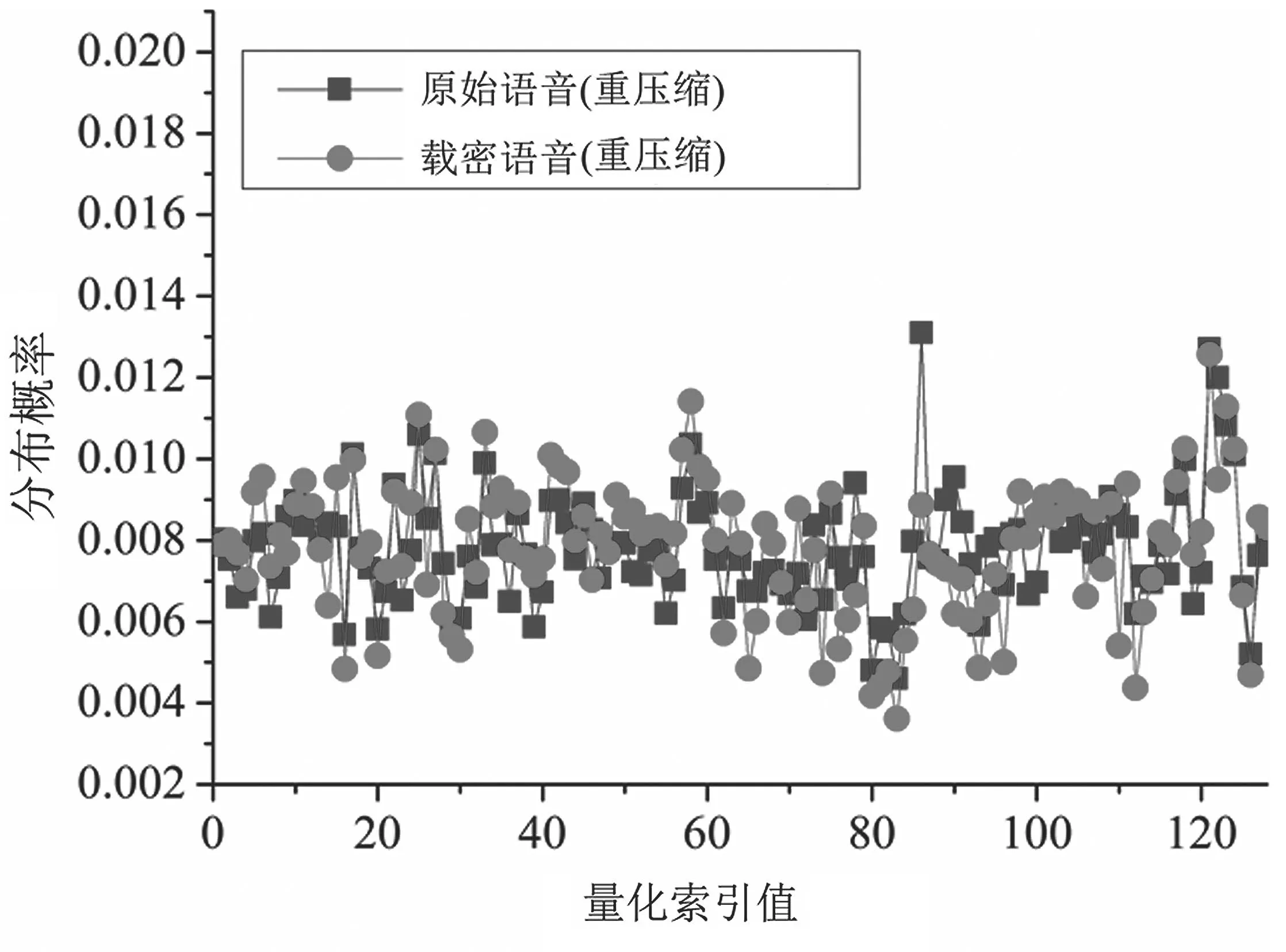
图3 重压缩后Q22 的量化索引分布概率
如前文所述,假设量化索引Q22的任一索引值q在一段语音中的分布概率为P22,q,将这段语音进行重压缩后的分布概率为P´22,q,则可以利用P´22,q作为校准构建校准值C22,q:

其中,C22,q为分布概率P22,q和P´22,q的差值。
通过对大量样本进行统计计算,图4 展示了Q22在不同索引值下的平均校准值分布。不难看出,原始语音的校准值普遍接近于0,而载密语音的校准值则明显偏离于0。可见,将再压缩语音的量化索引分布概率作为校准可以明显提升该特征的分类性能。
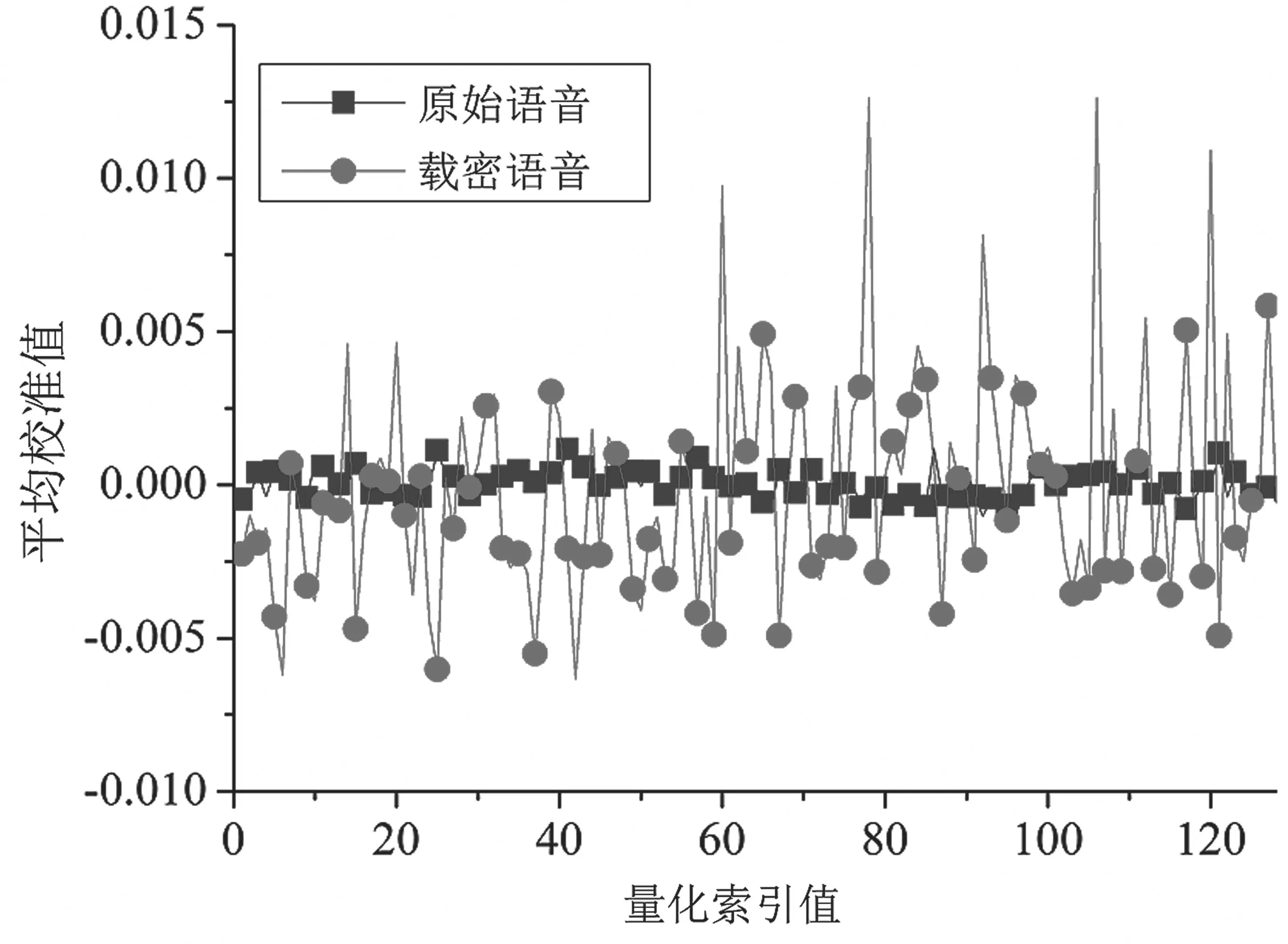
图4 Q22 的平均校准值分布
实验表明,校准技术对特征分类能力的提升有很大作用,本文选择C22=[C22,0,C22,1,…,C22,127]作为索引分布特征用于分类器的训练和测试。由于Q23与Q22具备类似的分布特性,因此最终送入分类器的索引分布特征为C22和C23的合集共计256 维。
2.2 基于LSTM 的特征提取方法
LSTM 是RNN 的一种特殊形式,能够在较长的时间序列中学习到长期依赖关系[17],因此Lin等人[13]使用双层LSTM 设计了一种隐写分析模型,并将其命名为RNN-SM。
通过实验发现,简单地将AMR-WB 中的几个量化索引序列送入到RNN-SM 中进行训练并不能很好地发挥LSTM 的优势,主要原因在于Q22和Q23这两个量化索引序列的关联性较弱,导致Li 等人[12]提出的QCCN 隐写分析方法并不能很好地对其进行检测。这在He 等人[10]的文章中做过详细说明,也是这两个量化索引被他们选作隐藏载体的原因。
通过压缩语音的原理可知,ISF 参数在时序上应当具备较强的关联性。Q22和Q23这两个量化索引未能表现出明显的关联性的原因主要在于它们都只含有ISF 参数分裂出来的一小部分信息,因此将量化索引重构为ISF 参数后能更明显地表现出其在时序上的关联特性。从前文可知,Q22和Q23这两个量化索引是在前9 维的ISF 参数下进行量化的,因此在本文构建的LSTM 模型中也仅使用前9 维的重构ISF 参数序列进行分类器训练。需要指出的是,在AMR-WB 编码器中,解码端重构16 维ISF 参数时采用的也是索引加偏移的方式存储ISF 参数,因此本文中也只选取前9维ISF参数的前9比特(即索引)作为特征提取模型的输入参数来对LSTM 网络进行训练。
图5 展示了在本文中利用LSTM 网络构建特征提取模型的方法。为了能够更好地在高层抽象表达特征,提高分类效果,选用三层LSTM 网络和Sigmoid 激活函数对9 维重构ISF 参数序列进行训练,并将最后一层神经层输出的矩阵作为输出特征用于后续的训练和测试。
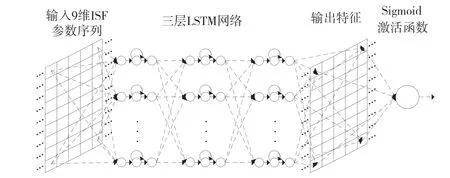
图5 三层LSTM 特征提取模型
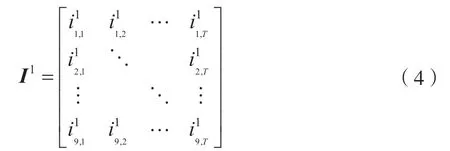
假设送入LSTM 特征提取模型的AMR-WB 语音长度为T帧,则其第1 层神经层中的输入参数为9×T维的矩阵I1:
假设模型各层中LSTM 单元的个数分别为n1、n2、n3,第k层神经层的输出为nk×T的矩阵Ok,除第一层的输入为I1以外,第k层神经层的输入即为上一层神经层的输出:

LSTM 单元在计算某一时序的输出时,输入包含了过去时序中的信息。以第t帧为例,假设第k层第j个LSTM 单元的输出为,其输出结果受前t帧的输入影响:
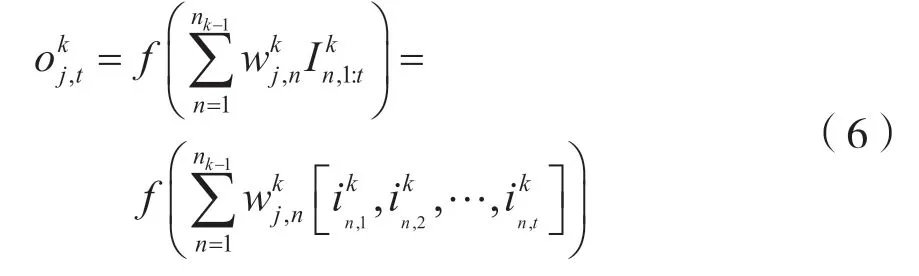
其中,y=f(x)是LSTM 单元的输出函数,x为输入的向量,y为输出值。表示取矩阵Ik中第n行中第1 至第t列组成的向量。为输入权重,当k=1 时,n0=9。
由此可得,第k层的输出矩阵O k为:
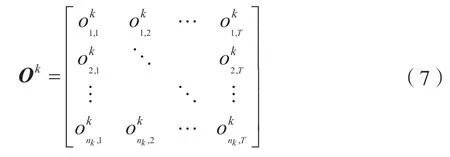
与量化索引分布特征类似,通过LSTM 网络模型提取的特征在经过校准技术处理后,也能够提高其分类性能。本文中,第三层LSTM 的输出矩阵在经过校准处理后被当做提取特征用于后续的训练和测试。从这里看出,整个特征提取模型最终输出的矩阵大小为n3×T。因此,输出的特征维度与输入语音的长度成正比。特征维度的不稳定性会导致分类器的复杂化,不仅会增加模型训练的计算量和工作量,也会影响实际应用中的检测效率。
2.3 基于混合分类器的隐写分析方法
为解决特征维度的不稳定性,本文采用变长窗口来统一特征维度。检测前对分类器设置最小检测窗口长度W,对帧数为W整数倍的语音进行检测。图6 展示了如何对一段长度为NW帧的语音进行特征提取。在进行特征提取的过程中,语音被分为N段分别提取特征。假设第k段语音中提取出的索引分布特征和LSTM 网络模型中提取的特征合集为Fk,则Fk的维度为256+n3×W维。为使每次输入分类器中的特征维度一致,在各段语音的特征输出后,对每段语音的特征进行算术平均计算,则可得到维度相同的平均特征F用于后续的训练和分类。
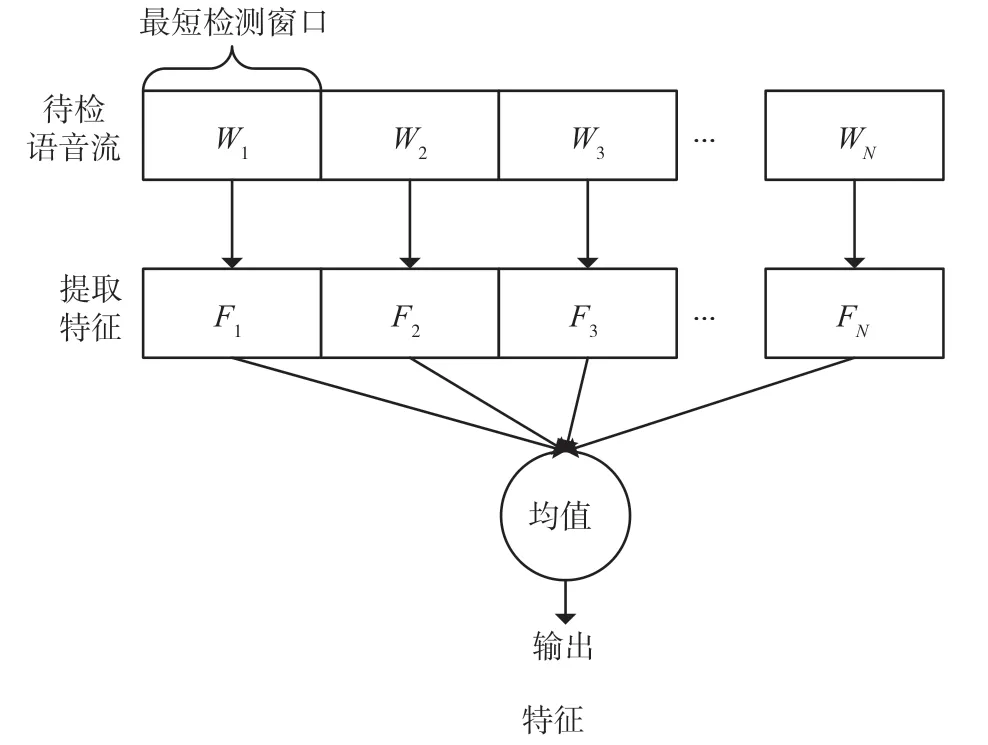
图6 基于变长窗口的特征提取方法
图7 展示了基于混合分类器的隐写分析方法流程。本方法分为训练和测试两个部分。训练又分为LSTM 网络的训练和SVM 的训练。
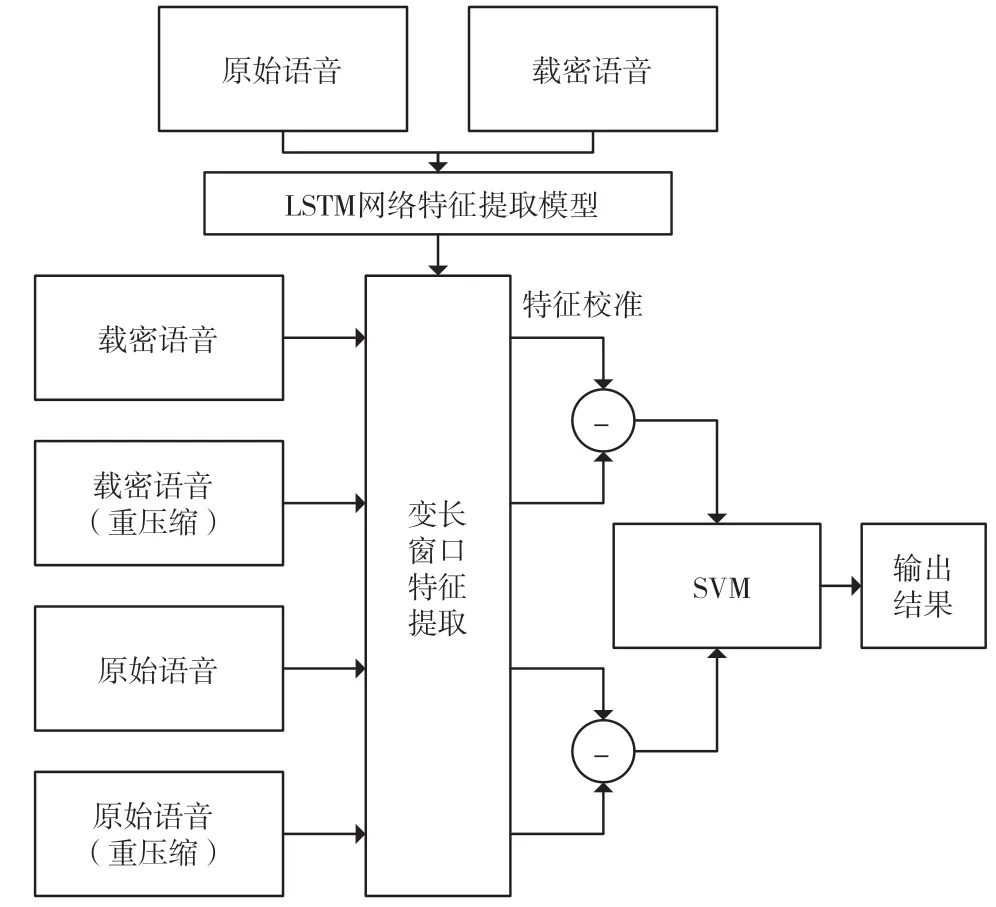
图7 基于混合分类器的隐写分析方法
LSTM 网络的训练过程如下。
(1)收集大量的训练样本,通过He 等人[10]提出的算法以100%嵌入率对语音进行信息隐藏处理。
(2)确定最小检测窗口长度W,将所有的语音裁剪成W帧的语音片段,并对原始语音和载密语音分别进行标注,随后送入LSTM 网络特征提取模型中进行训练,获得特征提取模块。
SVM 分类器的训练过程如下。
(1)根据实验设置的目标语音长度,将训练样本库中的语音均剪裁为NW帧的语音片段,并进行信息隐藏处理,之后对原始语音和载密语音分别进行重压缩,因此最终送入SVM 分类器的每个样本的长度均为NW帧。
(2)根据最短检测窗口长度W将待训练的原始语音、载密语音、重压缩后的原始语音以及重压缩后的载密语音4 类语音分别裁剪为N段。
(3)分别提取各段长度为W帧的语音的索引分布特征,并将各段语音中对应的ISF 参数序列送入已经训练好的LSTM 特征提取模型进行特征提取,获得ISF 参数的关联性特征。
(4)对同一个样本中各小分段提取的特征进行算术平均计算,即可得到每个样本最终的输出特征,共计256+n3×W维。
(5)通过重压缩语音中提取的特征对未重压缩语音中提取的特征进行校准。
(6)根据语音是否进行隐写对每段语音的特征进行标注,送入SVM 中进行训练。
测试过程中无需再重新训练LSTM 特征提取模型,直接对待检语音进行特征提取即可。
(1)确定待检语音的长度,对待检语音进行重压缩;
(2)根据变长窗口提取待检语音及其重压缩语音的量化索引分布特征,并利用LSTM 特征提取模型提取对应的关联性特征;
(3)对提取的特征集合进行校准处理;
(4)将特征送入SVM 中进行计算,获得判定结果。
3 实验结果及分析
为了验证本文提出的方法在不同嵌入率和样本长度下的检测效果,实验中收集了大量样本进行训练和测试,并和Lin 等人[13]提出的RNN-SM 以及Li 等人[11]提出的IDC 特征进行了比较。He 等人[10]的文章中已通过实验证明了QCCN 隐写分析方法[12]难以正确地检测Q22和Q23这两个量化索引的修改,因此本文中未选择QCCN 方法作为参照方法进行对比实验。
实验样本库中共计3 000段语音,每段语音10 s,包含中英两种语言。在不同的实验设置中,这些语音还会被裁剪成不同长度的样本。实验中随机抽取其中1 500 段语音作为训练集,剩下的1 500 段语音作为测试集。在编码过程中,选用23.85 kb/s 模式下的AMR-WB 编码器对样本集进行编码和重压缩。在信息隐藏过程中使用随机数,根据DN-QIM的方法[10]对所有语音中的Q22及Q23索引进行不同嵌入率的修改。
通常来说,针对VoIP 的隐写分析需要在实时的环境下对通信进行检测,检测窗口越短,越能在短时间内发现隐蔽通信的存在。因此,本次实验中将最小检测窗口长度W 设置为1 s,即50 帧。对基于LSTM 网络的特征提取模型进行训练时,训练集中的1 500 段语音被裁剪为15 000 段1 s 的语音用于训练。模型各层LSTM 单元的个数分别为50、25和10,因此LSTM 网络特征提取模型最终输出的特征维度为50×10=500 维。由于迭代250 次后分类的测试结果就不再有明显提升,因此在训练过程中,LSTM 网络迭代次数被设定为250 次。分类器的其他参数均设定为默认参数。
表2 记录了针对10 s 的语音,多种方法在不同嵌入率下的检测正确率。可以看出,得益于多种分类器和多种特征混合,本方法在低嵌入率下的表现明显优于IDC[11]和RNN-SM[13]。当嵌入率为20%时,本方法的检测正确率相较IDC 高11%以上,相较RNN-SM 高30%以上,展现了较强的检测能力。
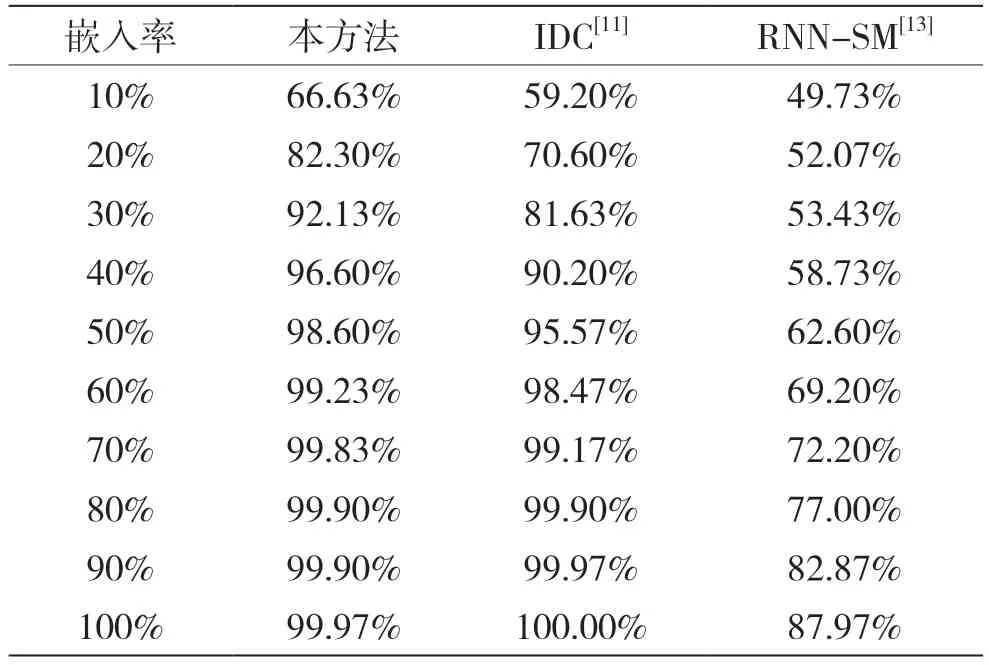
表2 针对10 s 语音在不同嵌入率下的检测正确率
表3 记录了在100%嵌入率下,多种方法对不同长度语音的检测正确率。在待检语音的长度为1 s时,本方法达到了95%以上的检测正确率,相较IDC[11]和RNN-SM[13]分别提升1.47%和30.8%。可见,本方法在短样本长度下依旧能够有效地对信息隐藏行为进行检测,在实际使用中能够在较短的时间内以较高的正确率对网络语音进行检测。
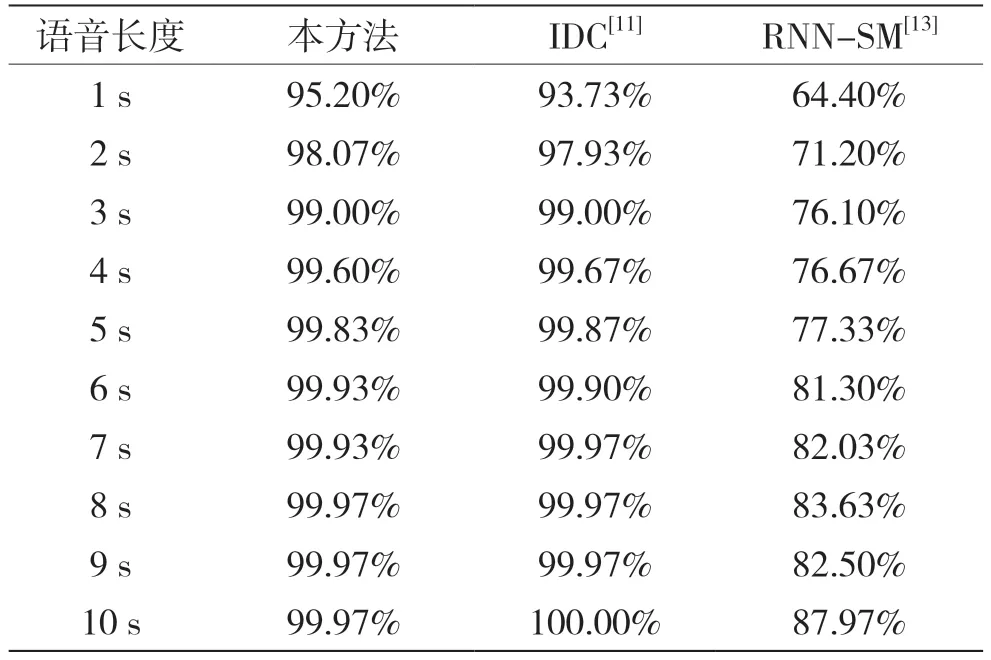
表3 在100%嵌入率下不同长度语音的检测正确率
4 结语
本文通过研究AMR-WB 上的DN-QIM 信息隐藏方法[10],设计了一种基于混合分类器的隐写分析方法。该方法中,有一套基于三层LSTM 网络的特征提取模型用于提取ISF 参数在时序上的关联性特征,同时量化索引序列的概率分布也被作为特征之一。在对特征进行校准后,特征被送入SVM 中训练。实验结果表明,相较于现有方法,本文提出的方法在低嵌入率下具有明显优势。校准技术不仅能够提升分类器的分类正确率,还能够作为未隐写语音的特征估计。后续工作将继续研究如何利用校准技术进行隐写嵌入率的估计和计算,进一步提升隐写分析的检测效果。
