检测基于KVM 的云环境的网络攻击∗
2020-12-23许峰赫
王 忠 许峰赫
(火箭军工程大学 西安 710000)
1 引言
分布式系统在信息技术基础设施方面进行了巨大的改造。他们的延续是云计算。尽管存在现代趋势和新的经济模式,但云计算已将其声明转变为大多数大公司和组织用于促进其日常需求的技术模型。众所周知,尽管提供了许多优点,但每一个新颖性都带来了一些缺点。它们可以分类为与服务提供商或基础架构或云系统主机相关。
本文介绍了一种在云基础架构中识别基于网络的攻击的新方法。在这方面,已经采用了基于KVM 的系统,其主机OS Dom0 可以直接访问系统的所有I/O 功能。通过监视由Dom0 操作系统的内核进行的系统调用来实现此访问。所提出的方法利用Smith-Waterman 算法[1]来证明通过监视系统调用,可以检测潜在云内部人员的恶意行为。
2 相关工作和网络攻击
Spring 表示,阻止麻烦数据包的云边界的防火墙可以限制但不能消除对已知恶意实体的访问[2]。Alzain 等人建议,从单一云迁移到“多云”将大大减少恶意内部人员的威胁[3]。Magklaras,Furnell 和Papadaki[4]提出了一种审计引擎,用于记录关系模式下的用户操作(LUARM),试图解决内部IT 滥用域的两个基本问题。Tripathi和Mishra[5]坚持认为,云提供商应该为客户提供控制,这可以检测和防止恶意内部人员的威胁。“雾计算”[6]提出了一种与其他方法完全不同的方法。监视每个云用户的访问操作,实现对每个用户的一种分析。该分析有助于检测异常行为。当怀疑未经授权的访问然后进行验证时,该方法通过向恶意内部人员返回大量诱饵信息来使用虚假信息攻击,从而保持真实用户数据的隐私。另一种方法是Cuong Hoang H. Lee[7],它通过捕获超级调用来实现基于Xen 的管理程序的安全性,因为它们比系统调用少。Kollam 和Sunnyvale[8]特别关注访问控制机制,提出了一种机制,可以为客户生成不可变的安全策略,并在提供商的基础架构中传播和实施它们。这是针对恶意内部人员,尤其是系统管理员的少数几种方法之一。Ristenpart[9]介绍了对最大的云基础设施之一Amazon EC2的“共驻”潜在攻击。
通过采用入侵检测系统(IDS),有许多尝试来保护云基础架构,不仅来自“共驻”攻击,还来自其他网络压力攻击。他们中的大多数使用安装在不同虚拟机中的多个代理,并将数据收集到一个集中点。缺点是它们会给云基础架构带来相当大的开销,因为它们消耗了大量资源[10~15]。
在“共驻”攻击的情况下,攻击者在获得其虚拟机的IP地址后,正在寻找域名系统(DNS)地址。这可以通过命令“nslookup”,然后是虚拟机(VM)的IP地址轻松检索。在Kali Linux内核中执行的此命令将返回DNS 地址。获取DNS 地址后,攻击者可以使用“nmap”命令获取利用特定DNS 的所有虚拟机(包括主机)的IP 地址。具体来说,执行的命令是“nmap-sP DNS_Adress/24”。拥有使用相同DNS的所有虚拟机的IP 地址,攻击者可以通过执行命令“nmap-v-O Ip_address”来识别主机或其他虚拟机的操作系统。通过上述三个不同的步骤,可以识别所有共驻以及有关其操作系统的其他信息,这些信息可以允许攻击者发起进一步的攻击,从而损害云基础设施。
通过在特殊配置的虚拟网络上启动smurf攻击来执行网络压力。为了执行smurf 攻击,攻击者需要受害者的IPv6 地址。受害者可以是同一网络上的主机或任何其他虚拟机。他的IPv6 地址可以使用两种方法获得。第一个是通过ifconfig 命令,可以在主机上执行。第二种方法是通过ping6命令检测同一网络上的IPv6 活动主机。攻击者可以通过执行命令“ping6-I<interface>ff02::1”轻松地从任何虚拟机ping 链路本地全节点多播地址ff02::1。获取IPv6地址后,攻击者可以使用smurf6工具执行攻击,执行命令“smurf6 <interface>victim_ipv6_address”。通过这种方法,攻击者VM(或主机)将使用欺骗性ICMPv6 回应请求数据包泛洪虚拟网络,其源地址是受害者计算机的IPv6地址,目标地址是链路本地全节点多播地址ff02::1。然后,同一网络上的其余计算机将使用ICMPv6回应回复来充斥受害者,从而对虚拟网络造成更大压力。
3 检测方法
所提出的检测方案采用了标准的Smith-Waterman 算法,该算法最初是在分子序列分析的背景下引入的[16]。这是可能的,因为所研究的数据流包括从有限离散字母表中提取的符号。引入的微小修改与两个参数有关,这两个参数指的是允许扫描的水平和垂直前驱的数量,以便确定相似网格的每个节点处的累积成本。换句话说,这两个参数定义了水平和垂直的最大允许间隙长度。这种类型的微小修改导致响应时间的显著改善,并且还与处理的数据的性质一致。这两个参数的值以及间隙罚分是广泛实验的结果。接下来介绍采用的Smith-Waterman算法。
首先,必须定义两个符号序列的各个元素之间的成对(局部)相似性。为此,让A 和B 为两个符号序列,A(i),i=1,…M,B(j),j=1,…N,是A 和j 的第i个符号B 的符号,分别。然后将A(i)和B(j)之间的局部相似性S(i,j)定义为

其中Gp 是不相似性的惩罚(我们的方法的参数)。
然后创建相似性网格H,其第一行和列被初始化为零,即,
H(0,j)=0,j=0,…N和H(i,0)=0,i=0,…,M
结果,相似网格的维度是(M+1)×(N+1),其行被索引为0,…,M并且其列被索引为0,…N。
对于网格的每个节点(i,j),i ≥1,j ≥1,根据以下等式计算累积的相似性成本:

其中Pv 和Ph 分别是允许的最大垂直和水平间隙(以符号数量表示),Gp 是先前引入的相异性惩罚(在这种情况下也用作间隙罚分)。对于网格的所有节点重复上述等式,从最低行(i=1)开始并从左向右移动(增加索引j)。可以看出,垂直和水平过渡(等式的第三和第四分支)引入间隙罚分,即,将累积的相似度减少一个量,该量与被跳过的节点的数量成比例(间隙的长度)。
另外,如果累积的相似度H(i,j)为负,则将其设置为零(等式的第一分支),并且虚拟节点(0,0)变为(i,j)的前趋。另一方面,如果累积的相似性是正的,则(i,j)的前导是使H(i,j)最大化的节点。每个节点的最佳前驱者的坐标存储在单独的矩阵中。关于网格的第一行和第一列,前一个始终是虚拟节点(0,0)。
在为所有节点计算累积成本之后,选择对应于最大检测值的节点,并且遵循前导链,直到遇到(0,0)节点。此过程称为回溯,并且得到的节点链是最佳(最佳对齐)路径。
在所进行的实验中,已经使用了参数Pv,Ph 和Gp 的不同值,并且最终选择了提供最令人满意的性能的值。
在执行“nslookup”命令(“共同驻留”攻击的第一步),“nmap-sP DNS_Adress/24”命令(“共同驻留”攻击的第二步),“nmap”期间,系统调用。-v-OIp_address“(”共存“攻击的第三步)和smurf6<interface>victim_ipv6_address(smurf 攻 击)被捕获。
●捕获在正常系统操作(未发起攻击)的同一时间段内进行的系统调用。
●上述日志文件已使用正则表达式和“sed”命令进行处理,只留下每个系统调用的ID。
●最后,使用Smith-Waterman 算法来比较日志(算法将每个系统调用ID用作DNA元素)。
●最初,使用自动化系统计算每个攻击步骤在不同时间段的多次执行之间的相似性,该系统由于人类的响应性而减少了错误。然后导出攻击步骤与正常操作的相应时间段之间的相似性。理想情况下,这种方法有助于识别将形成攻击特征的特定系统调用模式。
为了启动攻击并监控系统日志,使用一台具有以下配置的Dell PowerEdge T410 服务器构建了最小的云基础架构:Intel Xeon E5607 作为中央处理单元,8 GB 内存运行在1333 MHz 和300 GB SAS 硬盘@10000rpms。服务器运行的是OpenSuse Linux 12.1。还安装了Linux audit 工具;此工具有一个配置文件,用于存储规则列表,指定将记录哪种类型的系统调用。为避免在实验过程中丢失有价值的信息,所有系统调用都被捕获。具体来说,使用的规则是“-a entry,always-s all”。最后,在服务器上设置了两个使用Kali Linux 的虚拟机,其中包含用于渗透测试和攻击的大多数工具(参见图1)。

图1 试验台环境
在我们努力自动化攻击和系统调用审计程序期间,在Expect 中编写了一个脚本。Expect 是Tcl脚本语言的扩展,它用于自动化与公开文本终端接口的程序的交互。可以通过expect 包安装此功能。我们的脚本侧重于使用“expect”命令等待预期输出,使用“send”命令发送正确的输入,并最终使用“system”命令执行必要的bash 命令。最初,创建了将保存系统调用的目录。接下来,执行“spawn”命令以打开Virsh控制台并通过配置的串行控制台连接到虚拟机。 Virsh 是一个命令行界面工具,用于管理访客和虚拟机管理程序。然后启用Linux审核系统,并将攻击命令发送到将要执行的虚拟机。通过等待“expect”命令的特定输出来获取关于何时完成攻击的知识。最后,禁用Linux审核系统,并提取保存的系统调用。
设置环境后,“共同驻留”攻击的三个步骤中的每一步(“nslookup”,“nmap”和“nmap-v-OIp_address”命令;请参阅建议的方法部分)和smurf 攻击的步骤(smurf6 <interface>victim_ipv6_address)被执行了六次,每次捕获系统调用。
在每次执行一个命令(攻击步骤)之后,系统在正常状态下工作一段时间,该时间段等于命令的执行时间,再次捕获在该时间段内所有系统调用。攻击的时间段和各个正常状态时段在图2 和3 中描述。
然后通过在Matlab 中使用Smith Waterman 实现(参见章节算法),使用等于1/3和1/5的Gp,Pv和Ph等于5,在它们之间比较以下对数集:
●第一个攻击步骤的六个日志文件(每个执行轮次一个);“nslookup”命令。
●第二个攻击步骤的六个日志文件(每个执行轮次一个);“nmap-sP DNS_address/24”命令。
●第三个攻击步骤的六个日志文件(每个执行轮次一个);“nmap-v-O Ip_address”命令。
●smurf 攻击步骤的六个日志文件(每个执行轮次一个)。
●攻击的二十四个日志文件(每个攻击步骤和smurf 攻击的所有执行的六个日志文件)以及用于正常系统操作的相应日志文件。

图2 执行三个攻击步骤的时间段和系统保持正常状态的各个时间段
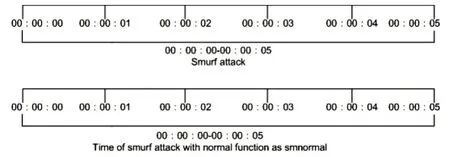
图3 执行smurf攻击的时间段以及系统保持正常状态的相应时间段
如下一节所示,结果符合我们的初步假设。在与攻击步骤对应的日志文件之间,而不是在攻击日志与正常系统状态的日志之间,发现了更大的相似性。
日志文件比较的结果显示在下面的表1~9中。如图2 和图3 所示,第一个攻击步骤的日志称为firststep,第二次攻击步骤的日志为secondstep,第三次攻击的日志为thirdstep,smurf攻击的日志为smurfstep。此外,对应于正常系统操作的时间段等于第一次攻击步骤的日志被称为fnormal,第二次攻击步骤被称为snormal,第三次攻击步骤被称为tnormal 和smurf 攻击如同常见。出现在Gp 列中的估计相似性数字表示使用Smith Waterman 算法发现的类似系统调用的最长子系列。从训练过程中可以预期,在比较攻击步骤的日志时相似度值会更大,而在比较攻击步骤的日志和正常系统操作的相应日志时,相似值会更小;即,对于相同的Gp,预计第一步1-2 将与firstep1-fnormal1 的相似性具有更大的相似性。表9 的结果加强了这一假设,我们将攻击的每个步骤的执行日志与执行大量网络操作的系统的日志进行比较,这大大增加了系统调用的数量。所有结果都在图4中可视化。

表1 Gp的第一个攻击步骤的六个日志文件(每个执行轮次一个)的比较等于1/3和1/5
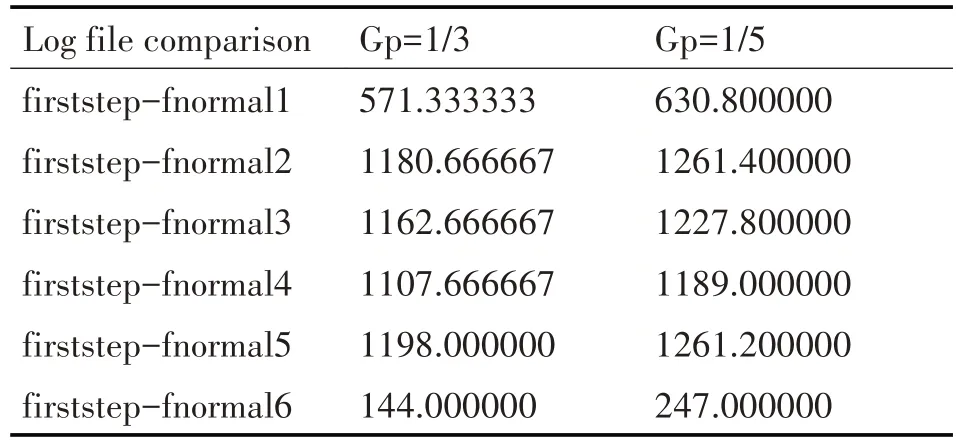
表2 Gp的第一个攻击步骤的六个日志文件(每个执行轮次一个)的比较等于1/3和1/5

表3 Gp的第一个攻击步骤的六个日志文件(每个执行轮次一个)的比较等于1/3和1/5

表5 Gp的第一个攻击步骤的六个日志文件(每个执行轮次一个)的比较等于1/3和1/5

表6 Gp的第一个攻击步骤的六个日志文件(每个执行轮次一个)的比较等于1/3和1/5
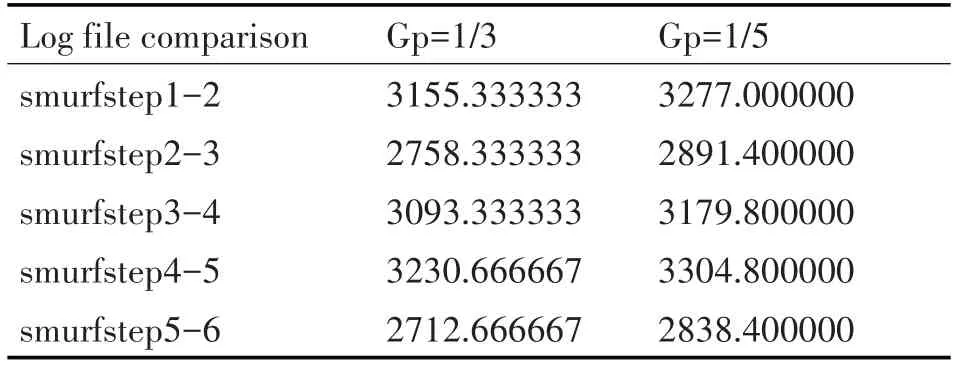
表7 Gp的第一个攻击步骤的六个日志文件(每个执行轮次一个)的比较等于1/3和1/5
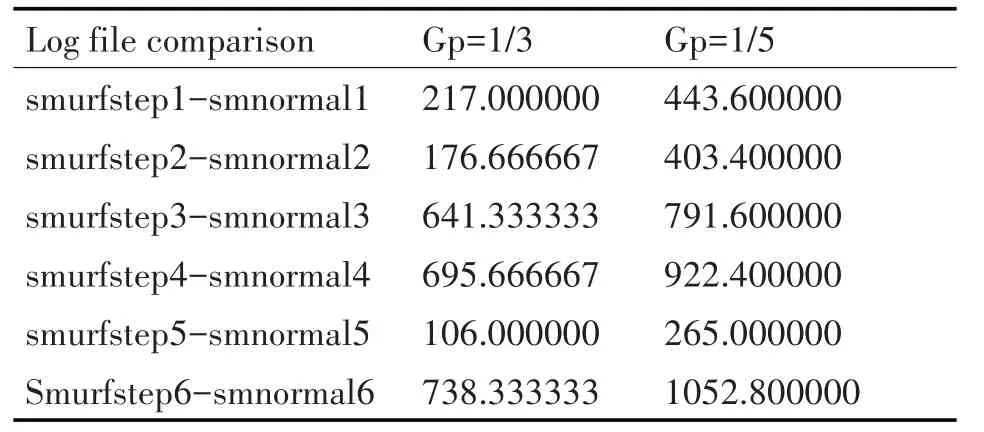
表8 Gp的第一个攻击步骤的六个日志文件(每个执行轮次一个)的比较等于1/3和1/5

表9 Gp的第一个攻击步骤的六个日志文件(每个执行轮次一个)的比较等于1/3和1/5

图4 图表描绘了攻击之间以及攻击之间的相似性以及分别为Gp 1/3和1/5的正常系统状态。较低的Gp提供更大的相似性
4 结语
回顾我们的主要目标,即通过系统调用序列识别攻击的存在。上一节中介绍的结果验证了这种方法,因为在攻击步骤中触发的系统调用的比较表现出比在比较某些攻击步骤和相应日志的日志时产生的相似性更大的相似性。正常的系统操作对于“共驻”攻击和smurf攻击的所有三个步骤都实现了这一假设。
结果是否准确是一个常见的问题,我们如何验证它们的正确性。通过使用的错误参数Gp可以很容易地回答这个问题。具体而言,Gp 是一个变量,它为算法提供了灵活性,并定义了算法在比较数据集时的容忍程度。如果我们使用1/3 的误差值,我们的算法比使用1/5值的算法要差。这个假设导致产生更大的相似性数字,其Gp 为1/5,而Gp 为1/3。当然,我们的结果证明了这一点,这些结果已在前一节中介绍过。
除此之外,我们必须注意这样一个事实,即算法越宽容,我们在攻击步骤的日志中获得的相似性越好。然而,对于在攻击步骤期间产生的日志与相应的正常操作的比较不是这种情况;具体地说,即使较大的Gp值的相似性更好,但缩放也不相同。
应该考虑的另一个重要问题是系统的工作量。在我们的实验中,我们使用了三台虚拟机,除了与攻击步骤相对应的任何虚拟机之外,它们都没有任何永久性工作。在虚拟机上有额外负载的实时环境中,系统调用的数量会大得多,其结果是处理日志文件所需的时间(如本文前面所述)。此外,由于算法比较身份而不能识别特定元素是否有用,因此跟踪此工作负载中的攻击将更加困难。然而,在增加的工作量下进行的初始实验集表明所提出的检测方法的准确性和有效性保持不变。
